基于模糊测量函数的多标签图数据特征提取研究
李程文 刘波


摘要:如今,图数据分类变得越来越重要。最近几十年对它的研究也越来越多,并且得到了广泛应用。传统的图数据分类研究主要集中在单标签集,然而在很多应用中,每个图数据都会同时具有多个标签集。这篇文章研究了关于图数据的多标签特征提取问题,并提出基于模糊测量函数的多标签图数据特征提取算法,用于搜索最优子图集。算法采用模糊测量函数作为评估标准评估子图特征的重要性,然后通过边枝界定算法修剪子图搜索空间有效地搜索最优子图特征。实验证明,该方法在现实应用中有较高的精度。
关键词:图数据;模糊测量;多标签;特征选取;边枝界定
1.多标签图数据分类研究背景
传统分类方法主要研究单标签分类问题,使用的数据样本只拥有单个标签,如C4.5,SVM,K近邻算法等。然而在许多实际问题中,样本数据可能拥有多个标签。多标签分类就是针对多标签数据的特点,利用数据的多个标签获取相应的数学模型,并依此将一个实例准确地划分到某一个类别中。多标签分类算法广泛地应用于医疗诊断、音乐分类和场景分类中,在这些分类中每一个输入数据样本都拥有多个标签。就像音乐分类系统,一首音乐可能同时属于多个标签,如古典音乐,轻音乐,流行音乐,爵士乐,钢琴曲。对于多标签数据,传统的单标签分类方法已无法满足需求。
图是一种最常用的数据结构之一,用于表示事物之间复杂的关系。图广泛地应用于很多分類领域,用于表示复杂结构的物体。如文件分类和在线产品推荐。同时,图数据的复杂性也成为研究中的难点。一个有效的图数据应该能够提取或者找出这些图的一个适当的特征子集以用于分析或者预测。在现实应用中,训练图集的子图特征数量也许会呈指数倍增长,这些数据中包含大量的冗余数据和错误数据。所以多标签分类方法都将依赖于特征筛选程序以选择最重要的子图用来分类。
多标签图数据分类的一个基本挑战是确定训练图集的最优特征子图。图分类问题已经得到了广泛的研究。传统方法把主要研究方向放在单标签分类问题(二分类)上,它明确或模糊地假设每一个图只有一个标签。对于单标签分类问题,传统图数据挖掘方法可以扩展并用于找出单标签图数据集中的一个最具价值的子图特征。但是在多标签分类问题上,每一个图拥有多个标签,多个特征子图集需要挖掘。
特征选取就是根据某种评估标准,从原始的特征空间中选取最优的特征子图集,代替原始数据用于分类。评估标准在特征选取中起着至关重要的作用,因为他直接决定特征选取算法的性能和分类模型的准确率。目前,特征提取算法中的评估标准主要有距离准则、一致性准则、分类误差准则、信息准则和关联评估准则等。其中关联评估准则是一种应用广泛的评估准则,因为它能很好地度量特征之间的关联性。虽然特征提取算法在传统分类算法中得到了广泛应用,但在多标签图数据学习中并没有得到很好的应用。事实上,多标签图数据中包含大量冗余信息和分类信息量低的数据。因此,评估标准对于多标签图数据分类算法意义重大。
在这篇文章里,人们提出了一种全新的多标签分类框架。这个方法被称为基于模糊测量函数的多标签图数据特征提取。首先,利用基于模糊测量函数的特征子集评估标准评估特征子集,用于选取最优的特征子图。为了避免详细地列举所有的子图特征,这里使用一种名flqgSpan的边枝界定算法”,通过修剪子图搜索空间有效的搜索最优的子图特征。实验证明,特征选取算法对多标签分类性能有显著提高。
2.相关工作
由于关注的是基于图数据的多标签特征子图的挖掘,首先回顾多标签数据分类和子图特征挖掘。
2.1多标签数据分类
多标签学习算法用于处理每一个实例都同时具有多种不同的标签的数据。到目前为止主要有5种多标签学习算法,即数据分解策略、算法延伸策略、混合策略、整体策略和标签编码策略。
数据分解策略主要是通过不同的分解技巧将多标签数据分解成一个或多个单标签数据集。如x~多(One VersusRest,OVR),二元关联(Binary Relevance,BR),标签幂集(Label Powerset,LP)。由于存在各种各样的单标签分类器和免费软件,如二分类支持向量机OVR_SVM,可以非常方便地实现一个数据分解算法。数据延伸策略是同时考虑训练数据的全部标签信息,延伸一个多类算法以处理多标签数据集。这种类型的算法有,多标签支持向量机(Rank-SVM),多标签核向量机(Rank-CVM),多标签神经网络(BP-MLL),但是这些算法需要解决复杂的最优化问题。混合策略使用现有的单标签分类方法,并且还明确地或者模糊地将多标签数据集分解成一系列的子集。本质上这些算法是通过稍微牺牲分类性能以减少运算量。典型的方法有多标签K近邻算法(ML-kNN),延伸后的支持向量机(OVR-ESVM)。整体策略是延伸一个现有的多标签整体分类算法或者实现一个整合上述三种多标签分类方法的算法。基于著名的AdaBoosting算法构建了两种不同的整体策略架构,AdaBoost.MH和AdaBoost.MR。新的整体策略算法包括整体分类链算法(Entire Classification Chain,ECC),随机K标签集方法(RAkEL),预测聚类树的随机森林法(RF-PCT)。标签编码策略将二进制标签向量转化为离散的密码词和真正密码词,通过分类算法和回归模型以预测新实例的密码词,并且通过得到的有噪音的密码词还原二进制标签向量。有两种实现方法:标签扩展和压缩编码。这两种方法的区别在于得到的编码词是否比原二进制标签向量长。值得注意的是二进制标签向量和离散密码词分类性能相似,真实编码词分类性能较差。
2.2图数据挖掘
长期以来,图数据挖掘问题在机器学习领域得到了广泛关注。图数据挖掘问题主要包括图的匹配、图数据中的关键字查询、频繁子图挖掘、聚类以及分类等。其中频繁子图挖掘算法主要研究关于如何从图数据中提取最具信息价值的子图特征信息。常见的频繁子图挖掘算法可以分为4类:基于Apriori的算法、基于模式增长的算法、基于模式增长和模式归约算法和基于最小描述长度的近似算法。基于Apriori的频繁子图挖掘算法包括基于Apriori算法的图挖掘(Apriori-based Graph Mining,AGM)、Frequert子图发现(FrequertSubgraph Discovery,FSG)、路径连接算法等。基于模式增长的频繁结构挖掘算法,包括gSpan,快速频繁子图挖掘(Fast Frequent Subgraph Mining,FFSM)、CloseGraph等。基于模式增长和模式归约的精确稠密频繁子结构挖掘算法,包括CloseCut及Splat等。基于最小描述长度的近似频繁子结构挖掘算法,包括SUBDUE等。gSpan算法是一种由Yan~Han提出的基于深度优先搜索算法及最右路径扩展技术生成频繁子图的算法。
尽管多标签图数据分类算法得到了广泛的研究,但将模糊理论用于多标签图数据子图特征挖掘的研究相对较少。该算法引进模糊测量方法,根据子图和母图之间的隶属度关系,建立隶属度函数,然后通过隶属度函数评估子图的重要性。为了避免详细地列举所有的子图特征,使用频繁子图挖掘算法gSpan,通过修剪子图搜索空间有效地搜索最优的子图特征。
3.基于模糊适应度函数的图分类多标签特征选取
这一节将详细介绍本文提出的基于模糊测量函数的多标签图数据特征提取方法。为了更好地阐述算法,首先介绍本文需要用到的相关概念,其次介绍多标签特征评估标准,最后介绍gSpan算法修剪子图搜索空间。
多标签图数据分类的特征选取的关键在于如何从多标签图数据中找出最具有信息量的子图。所以,本篇论文的研究问题可以描述为如下形式:为了训练一个有效的多标签图分类,如何从多标签图数据中有效地找出一个最优的子图特征集。挖掘多标签图数据的最优子图特征是一个非常有意义的任务,因为以下原因:(1)如何基于图的多种标签正确的评估子图特征集的有用性?(2)如何基于图的多种标签用合理的时间消耗确定最优子图特征,避免详细列举?图的子图的特征空间通常是非常巨大的,因為子图的数量随着图的大小呈指数倍增长。
3.2多标签特征子图评估
首先把集合A定义为子图和母图之间的模糊集。被称为模糊测量的模糊子集的评估标准被提出来评估模糊集A的模糊性的自由度。模糊性的自由度用于在全局水平中表示元素是否属于模糊集A的程度。在这里采用模糊熵为模糊性的自由度的测量方式。
其中H(QJ)表示由第Q个子图有第,个类标签的熵,Xi表示在模糊集中第q个子图的第价特征表示。关于FSE哽加详细的描述可以在文献中找到。
3.3子图空间搜索算法
为了能够列举图数据的全部子图,本文采用一种有效的算法,这是由Yan和Han提出的gSpan算法。他们首先在所有图的边界上建立一个词典序列,然后绘制每一幅图的独一无二的最小DFs编码作为图的标准标签。当且仅当两幅图形状完全相同时它们的最,JxDSP编码才相等。基于这个词典序列,利用深度优先搜索策略(DFs)有效地在DFS编码树上搜索所有子图。通过深度优先算法搜索DSF编码树的节点,可以在图的DFS编码序列中列举每一个图的所有子图,并且可以在树上直接修剪不是最小DFS的节点。下列详细介绍一TgSpan算法。
gspaJl算法思想:同一幅图可以生成多个不同的DFS树,gSpan算法就是按照DFS自动顺序选择其中一个作为基本的DFS树,然后对其进行最右扩展以寻找最优秀子图。具体过程如下:(1)扫描图数据集,去掉不符合的顶点和边。(2)将得到的包含k条边的子图作为种子图,根据最右路生长规则生成k+l条边的候选子图。如果该子图是最小DFs词典顺序,则计算(FSEI),不符合的进行修剪。(3)重复(2),直到没有新的候选子图生成为止。详细请见文献。
3.4基于模糊适应度函数的图分类多标签特征选取算法
受最近在图数据分类算法上研究的启发。这些算法把评估标准加到子图模式挖掘步骤中并且通过约束以修剪搜索空间,本文也采用相似的算法。主要有3个步骤:(1)采用一个标准的搜索空间,其中包含可以列举的所有子图模式。(2)搜索子图空间,通过FESI找出最优的子图特征。(3)提出一个FESI上界用于修剪搜索空间。
3.4.1子图列举
为了列举从图数据集中所有的子图,本文采用前文中提到的gspan算法。不同于列举子图和同构测试,gSpan首先建立一幅图的所有边的一个词典顺序,然后找出每一幅图的最小DFS编码作为独一无二的标签。基于这个词典顺序,通过深度优先策略可以有效地搜索DFS编码树中的所有子图。
3.4.2FSEI上界
通过上一步,本文已经可以列举图数据的所有的子图模式。现在本文将设定FSEI上界值以便可以修剪搜索子空间。
定理2(FSEI上界)对于任何两个子图g,g∈s,g是图g的母图(gg)。则g的FSEI值受到g的FSEI值约束,即(FSEI(g) 3.4.3修剪子图搜索空间 在这一步,本文通过FSEI上界有效的修剪子图搜索空间。在深度搜索DFS编码树时,在完全找出所有(FSEI)值时维持暂时的次优的FSEI值(用φ符号表示)。如果φ 4.实验 在这一部分,本文拿本文的方法和图数据的多标签分类方法进行对比性实验。本文使用现实生活中的多标签数据集,通过对这些图数据的实验验证本文算法的实用性与准确性。 4.1数据集 本文使用一组化合物抗癌活性性能数据集,NCI,作为实验用的基于图的多标签数据集。这组数据包含了化合物对于10种癌症(如:白血病,前列腺癌,乳腺癌)的抗癌活性性能的记录,将10种癌症中那些不完全的记录移除,最终得到812个被分配了10个标签的图。表2是关于NcI数据集中标签和癌症的简介。 每一个标签代表一种癌症的实验结果。“Pos(%)”表示每个实验的积极化合物的平均百分比。 4.2试验方法与参数设定 为了能体现出本文提出的算法的有效性与实用性,文章将实现以下方法进行对比。 (1)多标签特征选择+多标签分类(MLFS~SVM),本文首先采用本文的方法找出最优的子图特征集,然后用SVM—对多的训练每一个类并用于多标签分类。本文用SVMqight软件包训练多个SVM,其中的参数设置成默认模式。
(2)二元分解+单标签特征选择+二分类(BinarIG+SVM):本文和另外的一个将多标签问题分解成多个单标签问题的算法就行对比。对于每一个二分类任务,本文都用Information Gain(IG)作为一个熵,以从频繁子图中选择最具识别力的特征子集。使用SVM的二分类模式分别将图分类成多个二分类。
4.3实验结果评估
多标签分类比传统单标签分类问题需要不同的实验结果评估标准。在这里本文采用Ranking Loss和AveragePrecision以评估多标签分类性能。假设多标签图数据为D=(G1,y1),…,(Gn,yn)。其中图Gi被标记为yi∈(0,1)Qf(Gi,k
AvgPrec∈[0,1]值越大,性能越好。在这个实验中本文采用llAvgPrec~Average Precision。因此,所有的评估标准的值越小,性能越好。
4.4实验结果
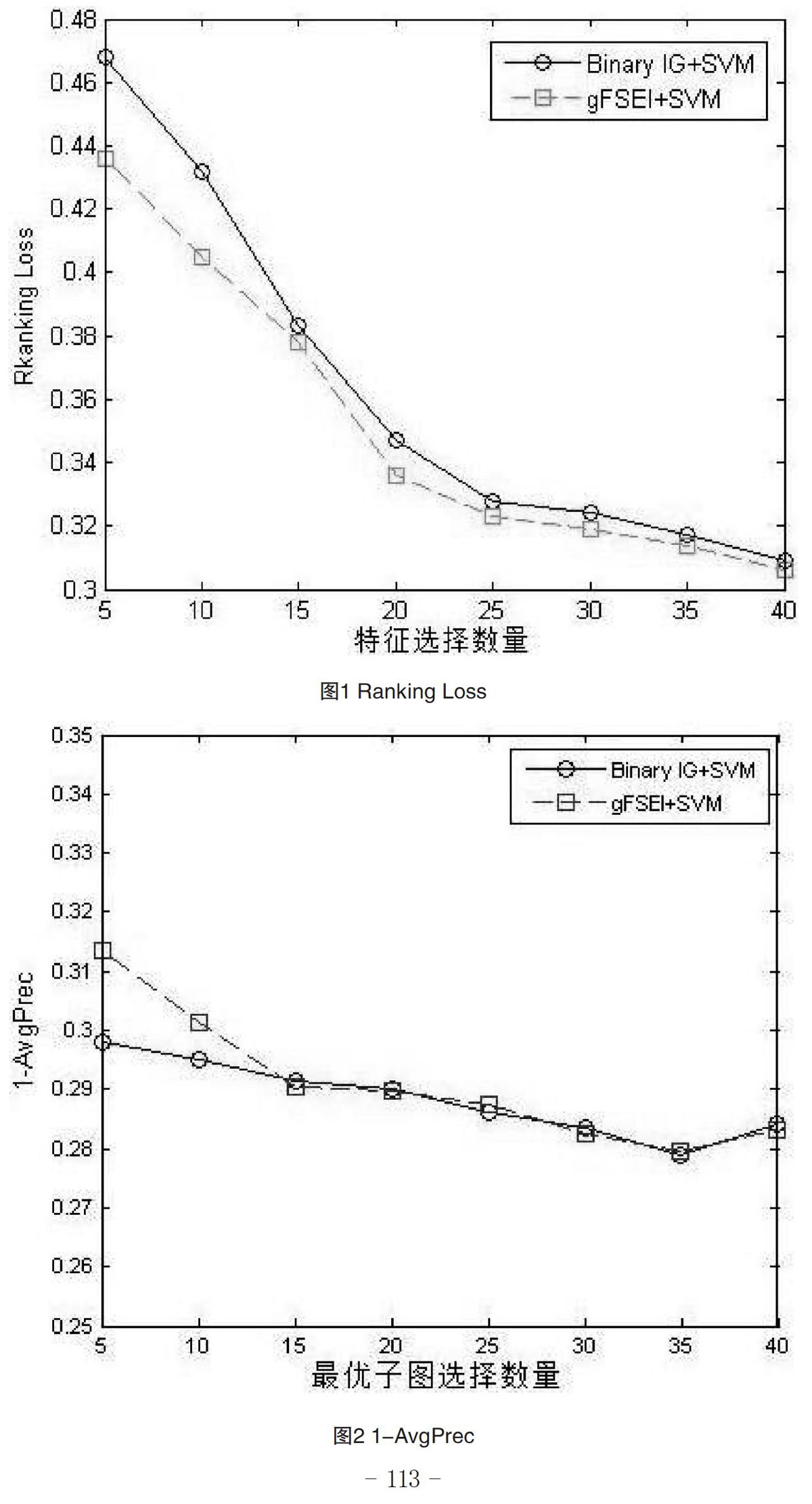
在本文的实验中,每一个图数据集都将其平均的分割成10个小的数据集。在这10个数据集中本文只采用其中的1个作为测试集,其他的9个数据集作为训练集。本文实验分别选择[5,10,15,20,25,30,35,40]个不同的最优子图进行对比实验。实验结果如图1-2所示。图1表示Ranking Loss的实验结果,图2表示1-AvgPrec的实验结果。
如图1-2所示,横坐标表示本文实验最终选取的最优子图数量,纵坐标则分别表示Ranking Loss和1-AvgPrec值。从图2曲线图可以知道,随着选取的标签节点数的增加,本文方法(MLFS+SVM)输出效果比(Binary IG+SVM)的输出效果略好。由图2本文可以看出,在最优子集选取数量少时本文的算法优于对比算法,但随着选取的子图数量增加,本文的算法输出效果和对比算法很接近。值得注意的是本文的算法是同时考虑多个标签的信息价值,将多个标签同时应用于图数据分类问题。而Binary IG+SVM算法则是单独选择每一个标签的特征集,这些特征集分别用于SVM进行图数据分类。所以本文的方法在实用性上有可取之处。
总之,文中的方法同时采用多个标签进行分類,在一定程度上对图数据的分类结果有较好的影响。
5.结语
在这篇文章中,笔者采用模糊测量方法对具有不同标签的子图进行评估,有效地结合了多个标签信息对图数据分类的作用;通过边枝界定算法对子图搜索空间进行修剪,避免了详细列举大量子图。在以后的研究工作中,本文将会继续完善本文的方法,并寻找更优秀的多标签图数据的子图选择算法。
