基于K- means聚类的微博用户活跃度研究
高迎 闫绍山 侯小培
摘要:以新浪微博用户为例,分析用户的相关数据,根据用户的粉丝数量、关注数量、发博文数量三个基本属性,采用K- means聚类算法对用户进行聚类分析,构建出用户活跃度聚类模型,为进一步的如何提升用户活跃度研究及采取相应措施保持、提高用户活跃度提供依据。
关键词:微博 K- means聚类算法 用户活跃度 社交网络平台
中图分类号:TP311.1;F49 文献标识码:A
在现今的日常生活中,微博作为一种新型的社交网络平台以其简单易用的用户平台、普遍的用户群、海量的实时信息和爆发式的传播方式,越来越受到人们的欢迎,也日益成为绝大多数用户生活中必不可少的一部分[1]。微博最重要的特征和职能之一就是允许每一位用户更新、分享和传输丰富多彩的信息。如何激励用户发布新的内容,激励用户积极分享自己喜欢的内容,使得整个微博社区更加活跃、信息更加丰富多彩,构建更加良好的微博生态,对微博平台的不断发展起着至关重要的作用。针对这个问题,根据用户的粉丝数、关注数、博文数这三个基本属性,采用K-means聚类算法对用户进行聚类分析,构建用户活跃度聚类模型,为上述问题的解决提供依据。
对用户活跃度的定义:第一是分析用户在网站上会有什么行为;第二是分析用户在网站上具有哪些属性。以新浪微博用户为例,用户可以发微博文章、转发博文、评论博文、被其他用户关注、关注其他用户,用户有发布的微博文章数量、转发博文数、评论博文数、粉丝数、关注数。两个方面结合到一起就可以对活跃用户特征做出定义。
本文针对微博用户活跃度合理聚类问题,以新浪微博为例,运用K-means聚类算法构建合适的用户活跃度聚类模型,以期提高微博社区的活跃度及信息服务质量。
1 K- means聚类算法
1.1 K- means聚类算法简介
K-means聚类算法是由Steinhaus1995年、Llovd1957年、Ball & Hall1965年、McQueen1967年分别在各自的不同的科学研究领域独立的提出[2]。K-means聚类算法被提出来后,在不同的学科领域被广泛研究和应用,并发展出大量不同的改进算法,虽然K-means聚类算法被提出已经超过50年了,但目前仍然是应用最广泛的划分聚类算法之一[2]。
K-means聚类算法是在无监督的情况下,将研究对象分为相对同质的群组的统计分析技术。聚类分析与分类分析有较大差别,分类分析是有监督的学习,而聚类分析是无监督的学习。无监督学习需要由聚类学习算法自动确定标记,不依赖于带类标记或有预先定义的类的训练实例,是观察式学习,而分类学习的实例或数据对象有类别标记,是示例式的学习。
1.2 K- means聚类算法操作步骤
K-means聚类算法是把含有n个对象的集合划分成指定的K个簇,每个簇中的对象的平均值称为该簇的聚点(中心),两个簇的相似度就是根据两个聚点而计算出来的。其操作步骤如下。
输入:数据集X={xm|m=1,2,…,total},其中的数据样本只包括描述属性,没有类别属性,聚类的个数为K。输出:使误差平方和准则最小的K个聚类。
第一步,从数据集X中随机地选择K个数据样本作为聚类的初始代表点,每一个代表点表示一个类别。第二步,对于X中的任一数据样本xm(1≤m≤total),计算它与K个初始代表点的距离,并且将它划分到距离最近的初始代表点所表示的类别中。第三步,完成数据样本的划分之后,对于每一个聚类,计算其中所有数据样本的均值,并且将其作为该聚类的新的代表点,由此得到K个均值代表点。第四步,对于X中的任一样本数据xm(1≤m≤total),计算它与K个均值代表点的距离,并且将它划分到距离最近的均值代表点所表示的类别中。
反复执行第三步和第四步直至各个聚类不再发生变化为止,即误差平方和准则函数的值达到最优。
2 微博用户活跃度聚类模型构建
2.1数据采集与预处理
本文用户数据来源于新浪微博,通过利用网络爬虫实现用户相关数据的获取,主要收集了2018年1月16日的一些用户数据,提取了用户的粉丝数、关注数、博文数属性,共得到17283条数据,得到的数据中有些数据的部分属性存在缺失,考虑到本文样本中每条数据属性值之间存在关联,常规的缺失值处理方法在此不太适用,并且存在缺失的数据量也不大,故直接将此类数据剔除,最终得到15518条数据,为对用户进行聚类分析做好准备。
2.2 K- means算法对用户活跃度分类的具体实现
本文使用WeKa工具中的K-means算法对预处理后的数据进行聚类分析,经过比较分析,聚类数量为4时聚类效果较好,最终得到的用户活跃度聚类模型如图1所示。
图1上半部分中列出了各个簇中心的位置,本文中用到的属性的值均为数值型,故簇中心就是它的均值,圖1的中部则给出了各个簇中的实例数及其占总体的比例,图1的下半部分则是各个簇的柱状图表示。
2.3结果分析及小结
从图1中可以看出,使用K-mean聚类算法最终将微博聚为了四个类,根据每个类的类中心位置将这四个类分别定义为极度活跃用户、活跃用户、中度活跃用户、普通活跃用户,其中极度活跃用户平均粉丝数量约为7945人、平均关注数量约为1415人、平均发博文数量约为1002篇,此类用户在微博中极度活跃,不仅粉丝众多、积极贡献信息,而且关注的信息也较多,约占整体用户的1%;活跃用户平均粉丝数量约为1188人、平均关注数量约为543人、平均发博文数量约为602篇,此类用户在微博中较为活跃,拥有一定的粉丝量并且比较频繁的发布信息,约占整体用户的3%;中度活跃用户的平均粉丝数量、平均关注数量及平均发博文数量则分别约为649人、187人、288篇,此类用户在整体用户中占比20%;在整体中占比最多的是普通活跃用户,此类用户的粉丝数、关注数、发博文数量都很少,潜在原因可能是他们更加习惯随意浏览信息,没有太多特意关注的领域或个人,也没有特意关注的信息,对于在整个社区分享信息、分享自己的想法也没有兴趣,此类用户占总体用户的76%。
3 结束语
从以上的分析可以看出,极度活跃用户、活跃用户甚至是中度活跃用户在总体用户中占比都很小,而粉丝数量、关注数量、发博文数量都少的普通活跃用户在总体用户中占比高达76%,可以得出结论:从总体上来看,微博用户的活跃度不足,激励用户积极分享,使得整个微博社区更加活跃、信息更加丰富多彩,构建更加良好的微博生态这个问题必须得到重视,而怎样激励普通活跃用户则是解决这个问题的关键。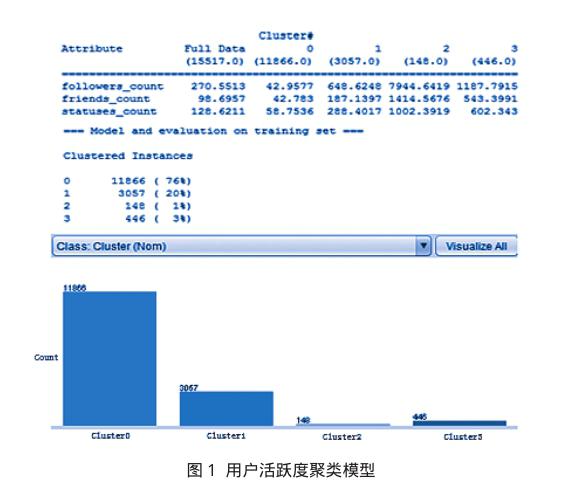
参考文献:
[1] Liu B,Chang K C C.Sepecial issue on web content mining[J].ACM SigKdd Explorations,2004,6(2):14.
[2] Anil K J.Data clustering:50 years beyond K - M eans[J ].Pattern R ecognition Letters,2010,31(8):651- 666.
[3] 廉捷,周欣,曹伟,等.新浪微博数据挖掘方案[J].清华大学学报:自然科学版,2005,51(10):1300- 1305.
[4] 吴夙慧,成颖,郑颜宁,等.K- means聚类算法研究综述[J].知识管理与知识组织:现代图书情报技术版,2011(5):28- 35.
[5] R adicchi F.Human activity in the web. Physical R eview E,2009,80(2):118- 120.
摘要:以新浪微博用户为例,分析用户的相关数据,根据用户的粉丝数量、关注数量、发博文数量三个基本属性,采用K- means聚类算法对用户进行聚类分析,构建出用户活跃度聚类模型,为进一步的如何提升用户活跃度研究及采取相应措施保持、提高用户活跃度提供依据。
关键词:微博 K- means聚类算法 用户活跃度 社交网络平台
中图分类号:TP311.1;F49 文献标识码:A
在现今的日常生活中,微博作为一种新型的社交网络平台以其简单易用的用户平台、普遍的用户群、海量的实时信息和爆发式的传播方式,越来越受到人们的欢迎,也日益成为绝大多数用户生活中必不可少的一部分[1]。微博最重要的特征和职能之一就是允许每一位用户更新、分享和传输丰富多彩的信息。如何激励用户发布新的内容,激励用户积极分享自己喜欢的内容,使得整个微博社区更加活跃、信息更加丰富多彩,构建更加良好的微博生态,对微博平台的不断发展起着至关重要的作用。针对这个问题,根据用户的粉丝数、关注数、博文数这三个基本属性,采用K-means聚类算法对用户进行聚类分析,构建用户活跃度聚类模型,为上述问题的解决提供依据。
对用户活跃度的定义:第一是分析用户在网站上会有什么行为;第二是分析用户在网站上具有哪些属性。以新浪微博用户为例,用户可以发微博文章、转发博文、评论博文、被其他用户关注、关注其他用户,用户有发布的微博文章数量、转发博文数、评论博文数、粉丝数、关注数。两个方面结合到一起就可以对活跃用户特征做出定义。
本文针对微博用户活跃度合理聚类问题,以新浪微博为例,运用K-means聚类算法构建合适的用户活跃度聚类模型,以期提高微博社区的活跃度及信息服务质量。
1 K- means聚类算法
1.1 K- means聚类算法简介
K-means聚类算法是由Steinhaus1995年、Llovd1957年、Ball & Hall1965年、McQueen1967年分别在各自的不同的科学研究领域独立的提出[2]。K-means聚类算法被提出来后,在不同的学科领域被广泛研究和应用,并发展出大量不同的改进算法,虽然K-means聚类算法被提出已经超过50年了,但目前仍然是应用最广泛的划分聚类算法之一[2]。
K-means聚类算法是在无监督的情况下,将研究对象分为相对同质的群组的统计分析技术。聚类分析与分类分析有较大差别,分类分析是有监督的学习,而聚类分析是无监督的学习。无监督学习需要由聚类学习算法自动确定标记,不依赖于带类标记或有预先定义的类的训练实例,是观察式学习,而分类学习的实例或数据对象有类别标记,是示例式的学习。
1.2 K- means聚类算法操作步骤
K-means聚类算法是把含有n个对象的集合划分成指定的K个簇,每个簇中的对象的平均值称为该簇的聚点(中心),两个簇的相似度就是根据两个聚点而计算出来的。其操作步骤如下。
输入:数据集X={xm|m=1,2,…,total},其中的数据样本只包括描述属性,没有类别属性,聚类的个数为K。输出:使误差平方和准则最小的K个聚类。
第一步,从数据集X中随机地选择K个数据样本作为聚类的初始代表点,每一个代表点表示一个类别。第二步,对于X中的任一数据样本xm(1≤m≤total),计算它与K个初始代表点的距离,并且将它划分到距离最近的初始代表点所表示的类别中。第三步,完成数据样本的划分之后,对于每一个聚类,计算其中所有数据样本的均值,并且将其作为该聚类的新的代表点,由此得到K个均值代表点。第四步,对于X中的任一样本数据xm(1≤m≤total),计算它与K个均值代表点的距离,并且将它划分到距离最近的均值代表点所表示的类别中。
反复执行第三步和第四步直至各个聚类不再发生变化为止,即误差平方和准则函数的值达到最优。
2 微博用户活跃度聚类模型构建
2.1数据采集与预处理
本文用户数据来源于新浪微博,通过利用网络爬虫实现用户相关数据的获取,主要收集了2018年1月16日的一些用户数据,提取了用户的粉丝数、关注数、博文数属性,共得到17283条数据,得到的数据中有些数据的部分属性存在缺失,考虑到本文样本中每条数据属性值之间存在关联,常规的缺失值处理方法在此不太适用,并且存在缺失的数据量也不大,故直接将此类数据剔除,最终得到15518条数据,为对用户进行聚类分析做好准备。
2.2 K- means算法对用户活跃度分类的具体实现
本文使用WeKa工具中的K-means算法对预处理后的数据进行聚类分析,经过比较分析,聚类数量为4时聚类效果较好,最终得到的用户活跃度聚类模型如图1所示。
图1上半部分中列出了各个簇中心的位置,本文中用到的属性的值均为数值型,故簇中心就是它的均值,圖1的中部则给出了各个簇中的实例数及其占总体的比例,图1的下半部分则是各个簇的柱状图表示。
2.3结果分析及小结
从图1中可以看出,使用K-mean聚类算法最终将微博聚为了四个类,根据每个类的类中心位置将这四个类分别定义为极度活跃用户、活跃用户、中度活跃用户、普通活跃用户,其中极度活跃用户平均粉丝数量约为7945人、平均关注数量约为1415人、平均发博文数量约为1002篇,此类用户在微博中极度活跃,不仅粉丝众多、积极贡献信息,而且关注的信息也较多,约占整体用户的1%;活跃用户平均粉丝数量约为1188人、平均关注数量约为543人、平均发博文数量约为602篇,此类用户在微博中较为活跃,拥有一定的粉丝量并且比较频繁的发布信息,约占整体用户的3%;中度活跃用户的平均粉丝数量、平均关注数量及平均发博文数量则分别约为649人、187人、288篇,此类用户在整体用户中占比20%;在整体中占比最多的是普通活跃用户,此类用户的粉丝数、关注数、发博文数量都很少,潜在原因可能是他们更加习惯随意浏览信息,没有太多特意关注的领域或个人,也没有特意关注的信息,对于在整个社区分享信息、分享自己的想法也没有兴趣,此类用户占总体用户的76%。
3 结束语
从以上的分析可以看出,极度活跃用户、活跃用户甚至是中度活跃用户在总体用户中占比都很小,而粉丝数量、关注数量、发博文数量都少的普通活跃用户在总体用户中占比高达76%,可以得出结论:从总体上来看,微博用户的活跃度不足,激励用户积极分享,使得整个微博社区更加活跃、信息更加丰富多彩,构建更加良好的微博生态这个问题必须得到重视,而怎样激励普通活跃用户则是解决这个问题的关键。
参考文献:
[1] Liu B,Chang K C C.Sepecial issue on web content mining[J].ACM SigKdd Explorations,2004,6(2):14.
[2] Anil K J.Data clustering:50 years beyond K - M eans[J ].Pattern R ecognition Letters,2010,31(8):651- 666.
[3] 廉捷,周欣,曹伟,等.新浪微博数据挖掘方案[J].清华大学学报:自然科学版,2005,51(10):1300- 1305.
[4] 吴夙慧,成颖,郑颜宁,等.K- means聚类算法研究综述[J].知识管理与知识组织:现代图书情报技术版,2011(5):28- 35.
[5] R adicchi F.Human activity in the web. Physical R eview E,2009,80(2):118- 120.
