关键词:数字图书馆;段落检索;性能评估;语义检索
摘要:文章利用目前已知的文件分段方式以及隐性语义检索技术,开发了一个文件分段检索系统,评估了文件结构分段、按文件人工语意分段以及取固定字数分段对段落检索结果的影响。通过对研究结果进行分析统计,得出了这3种分段方式的适用范围及优缺点。
中图分类号:G250文献标识码:A文章编号:1003-1588(2015)04-0074-03
收稿日期:2015-03-10
作者简介:王睿(1975—),海军工程大学图书馆馆员;曾斌(1970—),海军工程大学管理工程系信息管理研究室主任;陈抒(1983—),海军工程大学图书馆馆员。1背景
随着信息科技的进步,数字图书馆文献资料数量随之逐渐增加,而读者所面对的信息也就越来越多。若缺少某些帮助我们搜索信息的技术,数据的搜索将会相当困难。为了解决这个问题,产生了信息检索技术,同时也产生了许多不同的检索方法。但现在大部分的检索方法都没有考虑到文件内部的结构。因此,读者虽然找到了文件,但却无法找到真正对读者有意义的部分。如常用的模式匹配算法虽然可以对文件的一部分进行搜索,但在使用上有许多的限制,文件中必须含有和查询条件完全符合的文字才会被选择出来,而大部分的全文检索技术忽略了文件的结构。理想中,一个能够解决这种问题的系统应该是能和文件的结构相互配合的。如装备维护的检索系统,原始数据是各种不同装备的维修条例,如雷达、升降装置等,每一条例是检索系统中的一个文件。但读者在检索时并不希望系统传回整个条例文件,读者希望的是找到相关的维修条文。如找和“控制板接口”相关的维护条文,读者并不希望系统传回整个该型雷达的维护手册。在一般的文件中也可能有这样的需求,如搜索“信息管理的定义”,读者并不希望得到“信息管理导论”这样的结果。甚至系统若传回结果在某书的某章,可能对读者来说范围都太大了。最好是系统可以直接将定义“信息管理导论”的那一段文字直接找出,对读者的意义会比较大。
因此,本研究希望能将全文检索技术的应用范围由“全文”拓展到文件的某一部分,使得搜索时可以找出文件中关系最大的一个“段落”,也就是提供分辨率较高的搜索方式。为了达成这个目的,全文检索的技术必须修正以配合解决段落检索的问题。为了要进行段落式的全文检索,首先必须要探讨如何将文件分为不同的段落,而又能保持段落之间的意义独立。且利用段落检索时检索的单位增加许多,如何能在保障检索正确性的同时,又能维持时间上可以为读者所忍受,很可能必须修改全文检索的算法。为此,笔者主要研究包括:①利用目前已知的文件分段方式以及隐性语义检索技术,开发了文件分段系统。②研究这些分段方式对索引上的影响,探讨分段是否真正对检索有所帮助。
2文件段落检索方法的分析
在目前的全文检索环境中,存储的许多文件是相当长的,常常在同一篇文章中包含了许多不同的主题。在这样的情况下,搜寻一整篇文章变得没有意义,这会造成文件的利用率大幅降低。反而将大文章分开成不同的段落,再加以索引更能接近读者真正的需求[1]。
目前一般的分段方式可以归类为三种:按文件结构分段[2],按文件语意分段[3]以及取固定字数分段[4]。这三个方法各有其优缺点。
依文件原有的架构,如段、节等分段,一篇文章可以很自然地被分割成不同的部分。直觉上来说,这种方式是最有效率的方式,但这个假设在实际上并不一定正确。实际上,文件的概念在段与段之间是否能保持概念上的一致性,和作者写文章的方式有很大的关系。如果作者将相同的概念分在许多的段落,或是将许多不同的概念加以整理,集合在同一段中,对查询的效率都有负面的影响。
依文章的语意或主题,加以分析之后,将文章分为概念不同的段落。如 TextTiling[5]。它的原理是利用文件中用词的相似度来将文件分为不同的部分。利用统计方式,文件的不同部分可以找出不同的“相关段”,也就是表达概念相同的段落。但实验结果显示,这种方式和依文件结构分段并没有许多的改进。
依文件原有的段落或依文章所表达的语意分段两种方式中,都假设文件中存在一个唯一的、符合查询的信息架构。但对不同的查询,分段的方式可以不同。因此,以上的两种方式也许并不能符合所有的查询条件。对这种问题的解决方式是在文件上开一个固定大小的查询窗口,将分段的大小固定,并移动窗口的位置进行查询。实验结果显示,利用这种方式查询,精确度都有一定程度的进步。在某些实验中,甚至精确度提升了20.7%。
王睿1,曾斌2,陈抒1:电子文献段落检索算法性能评估研究王睿1,曾斌2,陈抒1:电子文献段落检索算法性能评估研究3文件段落检索系统的设计
本系统包含两个部分。第一个部分为隐性语义检索的文件检索[6]。当文献所表达的概念相同的时候,由于文献作者可以选择的字汇有限,因此概念相同的文章通常会有相似的字汇出现。隐性语义检索利用数学上的奇异值分解将文件向量的维度缩小,去除某些因为字汇有限而产生的词汇与词汇之间的相关性。
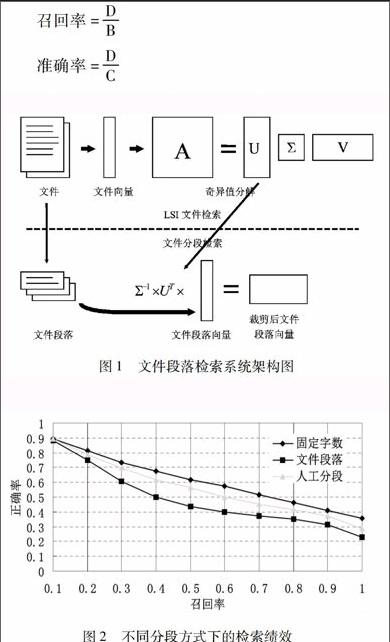
图1文件段落检索系统架构图段落检索系统利用隐性语义检索文件检索的结果,利用其所产生的奇异值矩阵及经奇异值分解过程所得到的缩减后词汇向量,经过无损压缩算法[7-8],计算各个文件段落的向量,并将这些向量与查询条件所得向量加以比较。整个过程可以由图1表示。
4查询效能的评估
本研究从大学图书馆文献库中选取27个相关的文件段落,利用查询条件在查询结果中的出现排名作为评估的重点。在此评估当中最重要的是了解系统为何产生错误的决定以及如何改进。实验重点关心的是原始文件的分段方式。不同的分段方式,影响读者如何接受查询出来的结果。如利用固定字数分段,系统极可能会将一个概念连贯的文章段落切成不同的段落,使读者无法得到最好的结果。本研究将针对字数以及原始文件的结构进行分段,并将结果加以比较。此外,本实验也将原始文件依照文件本身的意义,主观地将文件切割成意义较为一致的段落。利用这些段落,不分段地进行查询,以和本研究中的其他分段方式作为比较。
假设在A篇文件中,有B篇为相关文件。在经过系统处理查询之后,检索出C篇文件,其中有D篇相关。则:
召回率=DB
准确率=DC
在研究中固定召回率在某一水平,以计算的准确率作为比较的指标。
此外,在决定文件段落是否和查询条件相关时,完全凭借的是实验者的主观认定,这是本实验的一个缺陷。但是考虑到目前并没有一个评估全文查询系统的标准,况且,对于相同的查询条件以及文件来源,很可能因为分段的方式不同,造成结果也不同,所以难以事先找出一个判定相关与否的标准。为此本研究只能通过实验者本身的判定,决定检索结果是否相关。
在不同分段方式下进行系统效能的评估,本实验想要借此了解分段方式是否可以帮助检索提高准确率。以下是本次实验的结果(见图2)。
图2不同分段方式下的检索绩效 由此实验结果不难发现,固定长度的分段方式比人为分段的方式表现好,而人为分段比利用文件原有段落分段要好。为了更进一步验证两者之间的好坏关系,本研究利用T-检定判定这些方式的好坏。
固定长度对文件段落:H0:固定长度法比文件段落法差。利用P值法,p = 2.66125×10-5,小于0.05。所以否定假设,也就是固定长度法比文件段落法好。
文件段落对人为分段:H0:人为分段法比文件段落法差。利用P值法,p = 5.42802×10-5,小于0.05。所以否定假设,也就是人为分段法比文件段落法好。
人为分段对固定长度:H0:固定长度法比人为分段法差。利用P值法,p = 4.57476×10-5,小于0.05。所以否定假设,也就是固定长度法比人为分段法好。
观察上图召回率与准确率的关系可以发现,在召回率较低(0.1~0.2)时,三种方式准确率的差距不会太大。但随着召回率越来越高,利用文件段落分段与其他两种分段方式的差距越来越大。这代表了在所有相关的文件段落当中,排名较高的部分所检索出来的文件数目相差不多。但如果想要取得的相关文件越完整,所必须取得的总文件数也就越多,所花的代价也就越大。
对于这种情况,本研究的推断是由于利用固定长度进行分段时,为了避免分段时分开意义相连的段落,将固定长度的段落窗口加以重叠。使用此法进行查询,可能将真正的查询目标断成两段以上,造成系统得以查出许多有意义的段落,但这些段落依照和真正的查询目标的重叠程度而相关性随之下降。换句话说,相关的段落与全部段落的数目比率比另两者要高,造成在整个召回率曲线上,准确率随之均匀下降。
而利用文件段落进行分段,则有着相反的效果。由于相关的段落并没有被切开成为数段,造成真正相关的文件段落准确率很高,如同其他两种方式一般。在召回率为0.1~0.2的范围内,其实三种方式的准确率差距不大。但很明显的是,利用文件本身段落作分段的准确率降低极快。这可以说文件段落可以较精确地接近文件作者如何区分自己所要表达意义的不同。因此,对一个查询条件可以明确地找出含有这些意义的部分,但并不能提高系统认为排名较低的文件段落的排名。
在人为分段的部分,笔者发现这种分段的表现更好。但是在利用单一词汇进行查询时效果较差。因此,拖累了整体的表现。笔者认为这种方式比较适合隐性语义检索进行概念检索,尤其是在给定一段文字,在文献库中寻找相关文字段落的应用上更为适合。
5结语
本研究针对文件分段检索的问题,利用隐性语义检索技术,将可能出现的问题以及解决的方案进行探讨。在文件分段方式方面,笔者发现,利用文件本身结构进行分段比较能够接近作者对文件意义的表达。因此,利用文件本身结构进行分段效果较好。
参考文献:
[1]王慧.基于Lucene语义检索优化数字图书馆信息服务研究[J].科技情报开发与经济, 2014(15):120-122.
[2]Alejandro Molina,Juan-Manuel Torres-Moreno,Eric SanJuan.Discourse Segmentation for Sentence Compression[J].Advances in Artificial Intelligence Lecture Notes in Computer Science,2011(5):316-327.
[3]Bing Wu,Chen Yan Zhang. Topic Research with Semantics[J].Advanced Materials Research,2013(2):763-767.
[4]Jing Zou,Ilmari Pyykk.Enhanced oval window and blocked round window passages for middle–inner ear transportation of gadolinium in guinea pigs with a perforated round window membrane[J].European Archives of Oto-Rhino-Laryngology, 2013(11):65-72.
[5]N.Swarna Jyothi,M. Sailaja.Enhanced TFIDF Algorithm for Text Categorization[J]. Asian Journal of Computer Science & Information Technology,2011(1):25-34.
[6]董慧,唐敏.语义检索在Web2.0环境下的应用探讨[J].中国图书馆学报,2011(2): 115-119.
[7]孙志飞.语义检索在专利文献检索中的应用及改进[J].信息技术,2014(5):127-129.
[8]张文萍,邓仲华.基于查询语法扩展的隐性语义关系查询研究[J].情报杂志,2013(4):99-101.
(编校:崔萌)
- 批判性思维的考查方式与备考
- 建构“整本书阅读与研讨”教学评价体系
- 新高考评价体系下中考写作核心价值取向的命题思考
- 语文学科思维认知的检讨与重构
- 徘徊在语文思维门口的批判性思维
- 弱化了的作文教学咋办
- 语文知识:中学语文教学的理性之翼
- 高中《语文》文本的规范性例谈
- 何必拔苗助长 多点耐心守望
- 在刀尖上行走:万险中何以保全
- 拾级而上终拿云
- 语文教学设计:如何确定“怎么教”
- 传记教学:篇性揭秘的四个着力点
- 回归美育的中学语文写作课程
- 作文盲点:基于逻辑学的纯粹评议
- 语文深度学习的语境教学策略
- 小说教学内容的聚焦和创新
- 阅读课教学内容的确定方式辨析
- 古人的二重对比说服法(4)
- 香雪形象探析
- 三“思”寻理路 议论有真“心”
- 基于文化理解与传承的文言文教学策略探究
- 教材例子生成学生佳作
- 古人的二重对比说服法(3)
- 徜徉在诗歌的芳草地
- invite along
- invite/ask
- invite/ask sb along
- invite back
- invited
- invite in
- invitement
- inviters
- invites
- invite sb along
- invite sb back
- invite sb in
- invite sb out
- invite sb over
- invite sb over/round
- invite sb to do sth
- invite sb (to/for sth)
- invite sb (to sth/to do sth)
- invite sth
- invite²
- invite¹
- grab
- grab at sth/sb
- grabbable
- grabbed
- 退牌
- 退相
- 退省
- 退神光
- 退票
- 退离
- 退离休
- 退离所任的职务
- 退租
- 退税
- 退稿
- 退立
- 退素
- 退红
- 退约
- 退给
- 退缩
- 退缩不前的样子
- 退缩不进
- 退缩屈服
- 退缩怠惰
- 退缩隐藏
- 退缩,躲闪后退
- 退缩,退避
- 退罢