李冬云
摘 要:从数字挖掘的定义出发,分析利用关联规则挖掘技术实现数字图书馆个性化推荐服务的必要性,介绍关联规则的具体实现原理和求解过程。基于此,详细介绍了关联规则中的Apriori算法如何分析用户历史借阅记录,挖掘出潜在的有针对性的有用信息,选择出最适合推荐的图书推荐给读者,实现在数字图书馆环境下为读者提供个性化服务。
关键词:数字图书馆;数据挖掘;关联规则;Apriori算法;个性化服务
数字图书馆作为一个电子化信息的仓储,具有信息量大、更新速度快、信息存储和用户访问不受地域限制等特点,给人们带来了许多方便和快捷,但人们也深受其庞大且形式多样的信息资源的困扰。由于存储在计算机文件和数据库中的数据量不断增加,而用户却希望能够从庞大的数据中获得有针对性的有用信息,数据挖掘就应运而生了。近几年,数据挖掘技术逐渐应用于数字图书馆领域,提高了数字图书馆的服务功能。本文探讨了如何利用数据挖掘技术中的关联规则Apriori算法对读者的历史阅读情况进行分析,通过分析读者的信息行为以及他们的需求特征,得出读者的兴趣偏好,从而为读者提供个性化推荐服务。
一、关联规则挖掘的定义
数据挖掘最早由Gregory Piatetsky-Shapir提出,它是从大量的、不完整的、有噪声的、模糊的数据中,提取隐含在其中的,人们事先不知道的,但是又是可信的、潜在的和有价值的信息和知识的过程。数据挖掘是在统计学、人工智能和数据库技术的基础上发展起来的一门多学科交叉的新技术,本文主要是从数据库的观点来理解数据挖掘,指的是从存储在数据库、数据仓库或其它信息仓库中的大量数据中发现有用的知识的过程。数据挖掘主流的技术方法有很多,其中非常重要的方法之一就是关联规则,它是由R.Agrawal等人于1993年首先提出,通过从大量数据中的项集之间发现有趣的关联或相关,从而达到认识事物客观规律的技术方法。关联是指存在于两个或多个变量的取值之间的某种规律性,关联规则就是寻找在同一个事件中出现的不同项的相关性的技术方法。
二、利用关联规则挖掘技术实现数字图书馆个性化推荐服务的必要性
随着网络图书馆、数字图书馆等技术在图书馆中广泛应用,图书馆的管理理念和服务方式都发生了重大的变化。坚持“以人为本”的服务理念,更好地发挥图书馆的馆藏服务职能,努力提高读者的满意度等,仍然是图书馆新的发展方向和工作原则。1979年,美国学者舒曼提出“图书馆和信息提供者应该提供迎合个人需求的新服务”的观点,这就是个性化信息服务,也就是图书馆的服务方式不再是“图书馆提供什么,读者就接受什么”,而是更注重“读者需要什么,图书馆就提供什么”,重点考虑读者的兴趣和主动性这两个方面。
如今,数字图书馆虽然能为读者提供丰富的资源,但是也使读者面临着如何从这些海量信息资源中获得具有针对性的有用信息的困扰。不同读者的信息需求具有多样化的特点,单个用户不可能需要所有信息资源,信息也不能够满足所有读者的需求,错综复杂的信息之间存在着某种关系。借阅的图书与图书之间、读者和图书之间也可能存在一定的关系。现有的图书馆管理系统还无法找到图书馆大量统计数据之间的关系和规律,因此无法精准预测读者的信息需求,限制了读者顺利找到所需信息资源。这就需要我们利用数据挖掘的方法,来充分揭示这些数据背后所隐藏的关系。关联规则挖掘通过分析读者的历史借阅数据,发现读者的借阅模式,预测读者的阅读偏好情况,再及时主动地向读者提供符合读者需求的个性化推荐服务。
三、关联规则挖掘的原理
1.关联规则中涉及的重要概念
定义3-1? 设项的集合I={I1,I2,…,Im}(其中Ij称为项,包含k个项的项集称为k-项集)和事务集D={t1,t2,…,tm},其中ti={Ii1,Ii2,…,Iik}并且Iij∈I,即D中的每个事务都是I的子集。关联规则是形如A?B的蕴含式,其中A?I,B?I是两个项目集合,称为项目集,并且A∩B=?(即项集A和项集B不能相交)。
定义3-2? 项集A的支持度support(A)是事务D中支持A的事物数占库中所有事务的百分比。即support(A)=count(A)/D*100%.
定义3-3? 如果项集A的支持度support(A)不小于用户指定的最小支持度阈值minsup,则称A为频繁项集,否则称A为非频繁项集。
定理3-1? 假设X?I,Y?I是两个项目集合。
若X?Y,则support(X)≥support(Y);
若X?Y,如果X是非频繁项集,则Y也是非频繁
项集;
若X?Y,如果Y是频繁项集,则X也是频繁项集。
定义3-4? 关联规则A?B的支持度是数据库中包含A∪B的事务数占库中所有事务的百分比,记为:support(A?B)。即:support(A?B)=count(A∪B)/D*100%.
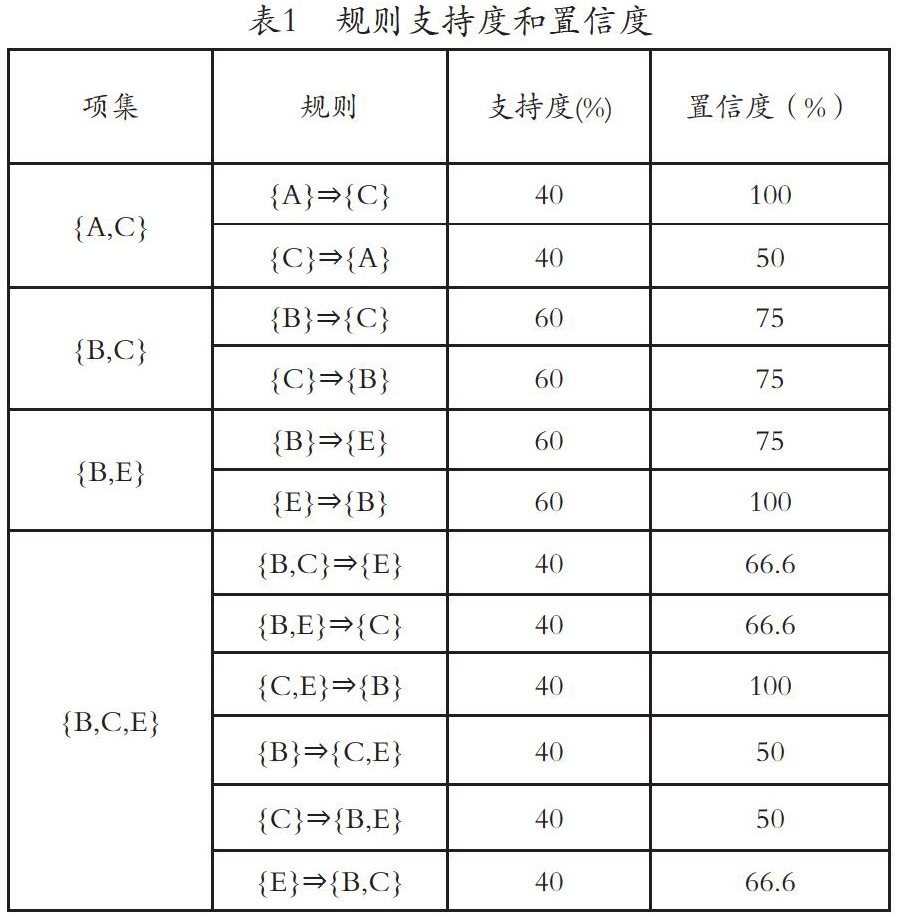
关联规则A?B的置信度(或强度)是包含A∪B的事务数和包含A的事务数的比值,记为:confidence(A?B)。即:confidence(A?B) =count(A∪B)/count(A)*100%.
定义3-5? 如果support(A?B)≥minsup且confidence(A?B)≥minconf,(其中minconf为用户指定的最小置信度阈值)。則称关联规则A?B为强关联规则,否则称关联规则A?B为弱关联规则。
2.关联规则挖掘求解过程
关联规则挖掘目的是发现强关联规则,也就是从数据库中挖掘出满足最小支持度minsup和最小置信度minconf的关联规则。其中,minsup和minconf是根据数据情况和用户需要设定。minsup表示项集在统计意义上需满足的最低程度,minconf反映关联规则需满足的最低可靠度。关联规则挖掘通过找出数据库中的所有频繁项集,再由频繁项集找出关联规则。
- 渗透化学反应机理的烯烃亲电加成教学设计
- 新媒体时代美育在高校思政教育中的应用探究
- 基于音乐核心素养的中学古琴创客课程设计与开发
- 基于慕课资源的小学科学双师课堂教学策略研究
- 财务管理慕课建设实践与反思
- 高职院校生物化学线上金课建设
- 基于互联网+的Scratch+物联云课堂教学实践
- 互联网+时代初中数学微课教学实践探索
- 基于在线作业平台的小学数学教学探究
- 教育技术装备发展传统与基石(续三)
- 基于微信公众号的高中数学教学实践研究
- 铁路企业智慧教室建设研究
- 基于电子白板的小学美术课堂教学设计
- 利用生活材料自制打击乐器的策略
- 研制膝跳反射模型 实现思维可视化
- 电子白板辅助多维互动课堂模式的方法研究
- 交互式电子白板在小学数学教学中的应用探析
- 巧用多媒体技术 实施高中历史直观教学
- 基于ARSandbox的中学地理可视化教学及应用示范
- 新国标学校运动场塑胶工程施工管控要点
- 基于巴特勒学习模式的电动势课堂教学
- 混合教学模式在冶金工程专业综合实验中的应用
- 微课在服装工艺课程实践教学中的应用研究
- 工训教学中机械测量教学模式分析和探索
- 回归现实探讨风景园林专业能力培养
- preremit
- preremits
- preremittance
- preremittances
- preremitted
- preremitting
- preremorse
- preremorses
- preremoval
- preremovals
- preremove
- preremoved
- preremoves
- preremoving
- preremunerate
- preremunerated
- preremunerates
- preremunerating
- preremuneration
- preremunerations
- pre-renaissance
- prerenaissance
- prerenal
- prerental
- prerentals
- 抃跃
- 抃踊
- 抃转
- 抃鳌
- 抄
- 抄上了
- 抄买卖
- 抄付
- 抄件
- 抄入名册
- 抄内
- 抄写
- 抄写书籍
- 抄写佛教经典
- 抄写清楚
- 抄写誊录
- 抄写,书写
- 抄击
- 抄刊古书而形成的脱漏或讹误
- 抄劫
- 抄化
- 抄化子不见了拐棒儿——受狗的气
- 抄化子不见拐棒儿——受狗的气
- 抄取
- 抄口