郭俭 徐亚军
摘 要:随着在线课程和线上学习的普及,大量的在线学习行为数据被积累。如何利用数据挖掘技术分析积累的大数据,从而为教学决策和学习优化提供服务,已经成为新的研究重点。文章基于苏州线上教育中心的学习行为数据,结合用户设定与對用户行为数据的挖掘分析,提出了一套资源画像的建设方法,该方法为个性化推荐及跟踪提供了数据基础。
关键词:资源画像;大数据算法;个性化推荐系统
中图分类号:TP391 ? ? ? ? ? 文献标志码:B ? ? ? ? ?文章编号:1673-8454(2019)12-0077-04一、引言
苏州线上教育中心是苏州市教育局于2018年1月面向基础教育领域推出的线上学习平台。中心以“全名师、全过程、全免费”为核心理念,统筹全市名优教师资源,通过个人电脑、手机、平板电脑和电视等端口向全市师生提供“名师在线直播”“名师在线答疑”“名师优质资源”“在线学习行为数据分析与智能引导”等教育服务。平台上线后用户使用活跃,总登录人次已达870.3万,日均登录2.1万人次;微课观看总数475万余人次,人均观看28.3次;名师直播课观看91.8万次,场均参与583人,初步形成了常态化的应用局面。
随着师生大量的使用,平台积累了海量的行为数据。挖掘这些数据背后的价值,在智能分析的基础上,将分析结果再度作用于日常教与学,初步实现人工智能技术的导入与应用,是中心近期建设的重要内容。为此,研发团队基于项目实际,使用大数据分析与人工智能技术等方法手段,进行了资源画像模型等的研究与开发。二、学习资源画像建设的基本思路
学习资源,是指用于学生学习的各类素材的统称。本文所指的学习资源,是指可用于在线学习的各类资源,主要包括:微课/直播课等视频资源、教师讲解类等音频资源、PPT课件/Word课件等文档资源、练习题/考试题等习题资源、练习卷/测试卷/考卷等检测卷资源。
要实现学习个性化,学习资源是载体。个性化学习的优化,其实质是对资源在时间、空间等维度上的最优化安排利用。
学习资源画像,实质是一组标注,用以对资源的特征进行推荐系统可识别的描述。在在线学习平台,可以综合利用传统的资源标注与基于行为大数据的分析来设定,可以从如下几个方面来考虑:1.资源属性标注
资源属性标注,即系统提供功能,对资源的关键属性进行手动或者半自动的资源标注,通过系统的算法,形成为资源的特征描述。此类方法较为传统,对于资源数量不是很大时非常有效,对于推荐系统的冷启动会有较大的准确性,是很值得进行建设的内容。资源标注的内容包括:
(1)资源的基本属性
如资源所属的学科、教材章节、知识点、难易度、长度、推荐使用场景等。
(2)资源的可推荐属性
在苏州线上教育平台,由于资源的海量特性,一个章节或知识点下面往往绑定了几个甚至几十个资源,学生用户进行选择耗时耗力,又未必有好的效果。在教育局的主导下,各学科教研员对每个章节的资源逐个细看审核,挑选出其中最优质的1到2个资源,标注为推荐级,然后通过系统引导学生进行基于优质资源的学习。在此情况下,资源的推荐属性首先是由人工标注的。
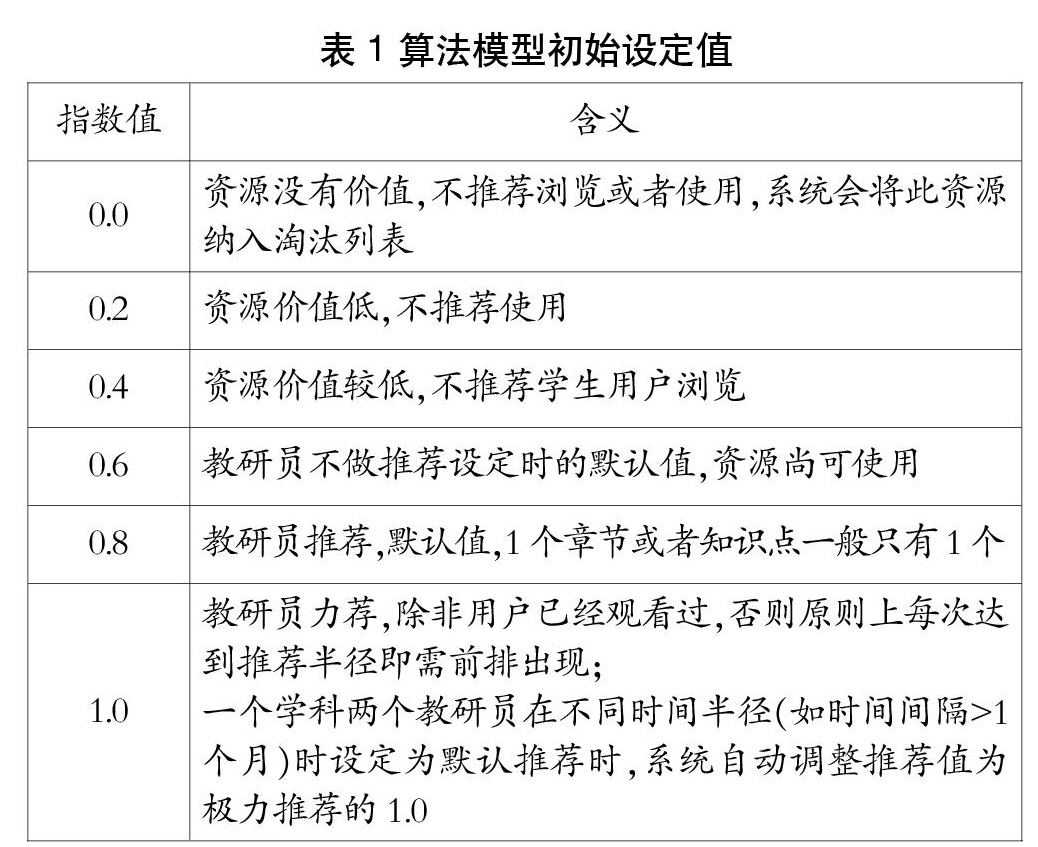
为进行计算,资源的可推荐属性的处理方式与前述的基本属性不一致,需要考虑到更多的维度,并综合以后使用归一化的推荐指数来进行描述,0代表不推荐,1代表强烈推荐,0至1之间的小数体现推荐的强弱程度。表1为我们对教研员推荐的算法模型初始设定值。
除了教研员可以设定资源为推荐外,其他平台用户(教师和学生)也可以进行推荐,不同的用户推荐指数的权重应该有所区分:区域级的教研员,一般负责一个区一个学科的教育教学研究,具有相当的权威性,需要具有最高的计算权重;学科带头人/特级教师等,也是教育专家,对资源间的有效性有更深刻的了解,他们推荐的资源也应该有较高的权重;一般的任课教师,可以以一个较低的权重进行推荐指数的计算。推荐指数的计算,除了需要按照推荐者的身份进行区分外,也需要把推荐者人数纳入计算范围,一个资源受到10个人的推荐和3个人推荐,计算出来的推荐指数需要体现10个人推荐资源的指数值大于3个人推荐资源的指数值。一个资源的最终推荐指数是综合了不同用户权重、推荐人数量等维度计算出来的数值,此公式不同的团队有不同的算法,在此不作细述。
(3)资源负向评价指数
资源负向评价指数,为综合对资源的投诉、在评论中的负面评价等因素进行衡量的指数。资源负向评价指数取值[0,1],0为不具有负向评价,系统可以进行推荐;1为强烈的负向评价,系统不能将资源推荐给任何人。资源的负向评价指数具有很强的指向性,主要包括:
投诉:被投诉并经核实的,平台需要进行惩罚性的自动处理,该资源成为淘汰资源,除了资源作者、平台管理员之外,无人能够看到此资源,即事实上的资源下架。
负面评论:在资源的评价中,经过情感分析发现有负面评论的,需要根据负面评价的占比进行反向推荐,即即使被其他操作认可可以推荐的,也需要降低其推荐优先度。
我们以单纯的线性计算公式举例如下:
负向评价指数=本资源被负向评论的总数/本资源被有效评论的总数
实际公式需要考虑如情感指数程度、评论总数等因素,进行必要的纠正;需要考虑适当放大负向评价指数的负面作用,降低被选中率;处理之前,需要使用情感分析引擎进行预处理,区分无效评价、负面评价、其他评价三类。
(4)资源响应半径
由于基础教育具有周期性教学的特点,如每年9月10日,六年级英语会上教材Unit 1的相关内容。区域级在线学习平台一般都以支持同步学习场景为主,随着学习章节的推移,对新章节资源的需求会在几天之內从零达到高峰,并在几天之内迅速恢复为零。如何对章节进行数字化的建模,不同的团队有不同的做法,我们介绍一种简化的算法。
①场景半径的计算
时间响应与具体场景具有紧密的结核性,如对于同步学习,已经学习过的课程,其资源需要降低推荐几率,而即将学习的课程资源,则需要大幅提高其被推荐的几率,越是近越应该高;对于阶段性回顾,如期中期末的复习与回顾,则与同步学习相反,目的是对此阶段学习的内容进行拔高与回顾,对于尚未学习过的课程的资源则不应该出现在推荐列表中,而之前学习过的,属于拓展提高的资源或者容易错的题目应该高频率出现在推荐列表中。
不同的年份,开学日期的不同导致了相同的日期资源的时间特性也不一样,如同样是3月4日,在2018年为第一周的周日,而在2019年为第三周周一,仅一年之隔就相差了一周以上。为了使时间半径具有更好的针对性,特对时间进行如下分割:需要系统级设定各学期、寒暑假的开始结束日期,按照表2进行每一天的计算。
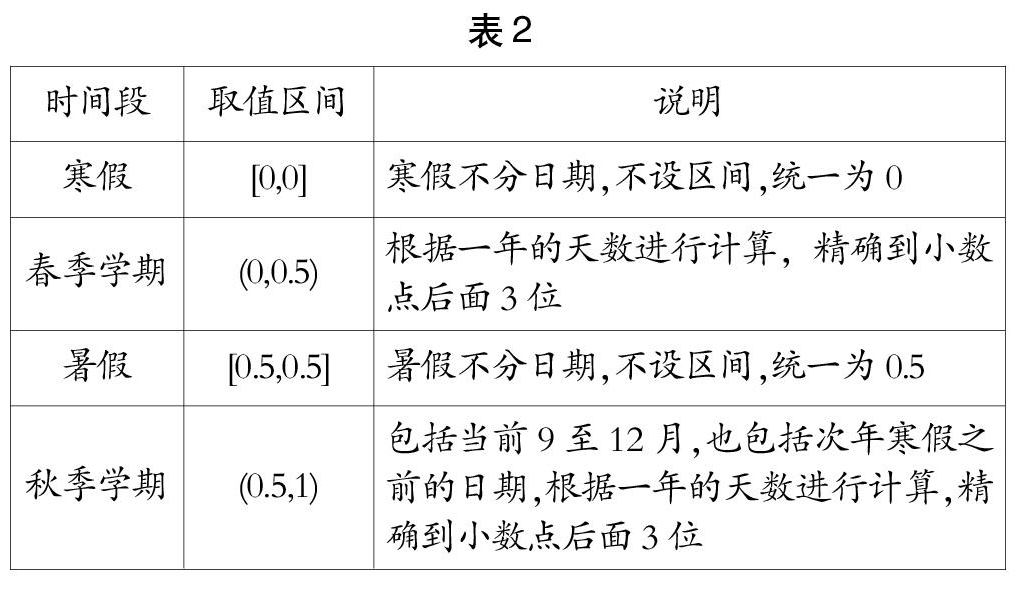
为得到此数据,需要通过平台设定的方式设定如上四个时间段,即寒假起止日期、春季学期起止日期、暑假起止日期、秋季学期起止日期。由于需要考虑平台对春季和秋季学期日期的设定,故做如下约定:秋季学期的结束日期可以覆盖寒假的起止日期,即寒假日期可以单独设定,无须考虑是否与秋季学期、春季学期覆盖。春季学期的结束日期可以覆盖暑假的起止日期,即暑假日期可以单独设定,而与春季学期无关。为防止有空档日期,建议将秋季学期的结束日期设定为寒假中的某一天,并将次日设定为春季学期的开始日期。同理设定秋季起止日期。
如此,根据系统的设定,资源的时间半径将按照表3中的规则取舍。不同的学期天数可能不一样,为简单起见,可以使用简单线性缩放来进行处理。

②教材章节响应半径
教材章节响应半径,需要根据教材章节的同步设定进行处理。根据不同的学科,教材章节具有不同的特性。如语文和英语类,其教材章节很平铺化,一册书具有固定的课数;数学和物理等理科类课程,则有大小章节之分,不同的章节课时数也会发生较大的变化。
为方便统一计算,教材章节半径按照如下策略进行:相应半径以0-1.0的数值来表述,0为开学的进度,1为期末的进度。
实际教学时,需要考虑到期中考试和期末考试两个特殊阶段,在此阶段,主要为阶段性的复习,我们称之为复习阶段,在正常的计算时,需要将此复习阶段和同步学习阶段分开来处理。复习阶段和同步学习阶段分别使用不同的引擎进行处理,故教材章节半径,仅计算同步学习的章节半径。
如平台有教材章节进度设定的,使用基于时间轴的方式进行数字归一化处理:根据平台的设定,每个章节会有上课时间的设定;如“有理数”上课期间为5/8至5/20,根据该时间段在该学期内的分布值来计算。另外,为方便起见,对于一个章节使用期间的中间值来计算后赋值。
如平台无计算学科教材章节进度设定的,则根据章节进行平分计算。如学科章节仅有一层的,则按照章节数平均计算;如果学科章节有两层甚至三层的,将所有章节补齐到两层或者三层,示意如图1。

③其他响应半径
除了教材章节响应半径,还有其他响应半径,如知识点响应半径,可以通过类似的方法进行计算而得,不同类型的半径,在与场景相结合计算相似度半径时,需要有相应的算法。2.基于行为大数据的分析计算与推导
基于行为大数据的分析计算,需要在采集大量用户使用资源的基础上进行计算,如果平台用户行为少,则计算会非常不准确,当一个区域级学习平台进入常态化的使用,每天都有大量数据产生以后,基于行为大数据的资源价值分析计算就变得非常有意义。行为大数据种类很多,分析的维度也很多,对资源价值的衡量的准确度也就很精准。
(1)资源热度指数
通过使用该指数来衡量被各种场景使用的热度,指数值为归一化后的数值,0代表无人使用,没有热度;1代表非常多的人使用,是热门资源。不同的场景资源热度权重需要细分成不一样的场景维度,场景包括资源观看、资源引用(引用到教案/导学/作业等)、资源收藏、资源点赞、资源评论等。
系统通过用户对资源的各场景行为数据分析以后计算资源场景热度特征指数,每个场景的热度指数,有多种算法可以进行计算,如最简单的可以使用本资源行为发生数与当前学科当前年级最热门资源的比例来进行计算,也可以使用对数等方式进行计算。
在计算完毕一个资源的多个维度的热度指数以后,需要按照设定的权重计算出综合热度指数,在个性化推荐等场景,将使用该综合热度指数进行计算。各场景权重的设置可以有一个初期的设定值,以反映不同行为对资源价值的评价,如资源引用与资源收藏的权重需要大于资源点赞数;资源点赞行为的权重需要大于资源观看行为的权重。为简单起见,我们可以设定一个初始的权重表来将各场景行为热度指数综合计算成综合的热度指数,具体如表4所示。

(2)资源推荐转换指数
当一个资源通过引擎推荐给用户以后,用户在不经意之间做出了两种截然不同的选择:用户受到封面、标题或者相关信息的引导,点击资源观看进行学习或者检测;由于资源展现的信息没有吸引用户,或者用户对此不关心,忽视而过。这两种不同的结果如果进行长时的跟踪,当积累到一定阈值以后,资源的吸引力(≈资源价值)也得以衡量。参照一般互联网公司的推荐算法,资源推荐给用户以后也需要进行跟踪,如果一個资源被推荐多次,但是无人观看,或者观看覆盖度(资源被使用长度/资源总长度,如视频被观看3秒,总时长为300秒,则覆盖度为1%)很低,系统需要认为该资源不受人喜欢;而一个资源被推荐以后,用户点击进去的次数明显较多,则系统需要认为该资源价值较大。
(3)资源推荐转换指数
即为推荐成功的指数,使用归一化的[0,1]数值来表述。在基础教育领域,一般的资源转换成功率较低,故计算一般不建议使用线性除,而是使用对数化以后计算的方式。在实际处理的时候,需要如前所述,将推荐数量较低(如 低于100次)的资源去除,数据量较低时具有一定的偶然性,暂不适合进行资源价值(其实应该为吸引力)的定量计算。
(4)资源的相似度
通过前述的几个维度,我们得到了资源不同维度的特性值,并且尽可能已经做到了归一化的指数处理。资源的相似度,可以使用前述的多个维度组成多维向量空间,并通过计算余弦值或者欧几里得距离等方法,计算出与特定资源相类似的资源列表出来。此类计算已经有非常成熟的公式,在此不做赘述。
(5)资源间的关联
资源间的关联包括相同类型资源间的关联与不同类型资源间的关联。资源间的关联计算是典型的大数据分析计算。本处的资源间的关联不是指前述通过相似度计算出来的资源,而是通过对行为大数据进行分析,找出从属性特征方面低相关、实际使用又是高相关的资源。通过大数据分析的方式,试图得到资源相似度计算得不到的关联信息。资源间的关联,可以使用协同过滤算法来计算所得。三、拓展与展望
前文从多个方面多个维度,对资源的特征画像进行了计算,综合多个特征,可以开始形成一个较为完整的资源画像。
资源画像的不同特征,在具体的个性化计算时,一个特征会被不同的计算引擎所采用;一个计算引擎,会根据算法使用到多个画像特征;在多个引擎分别计算出合适的资源列表以后,再由场景引擎进行基于场景的结果计算,最终才会输出一个符合当前用户当前场景的资源列表。总体的资源画像计算与个性化推荐计算引擎流程如图2所示。

[1]金志福.基于大数据的教育资源个性推荐系统设计与实现[D].北京:中国科学院大学(工程管理与信息技术学院),2015.
[2]牟智佳.电子书包中基于教育大数据的个性化学习评价模型与系统设计[J].远程教育杂志,2014,32(5):90-96.
[3]肖年志,郭俭.面向自适应学习的资源模型构建[J].中国教育信息化.2018(3):42-45.
(编辑:鲁利瑞)
- 高压开关设备制造技术的应用
- 沥青混凝土路面冷再生技术及其应用
- 粉喷桩处理公路软土地基施工工艺及质量控制
- 浅析工程量清单计价在工程造价中的应用
- 填石路基施工技术在公路施工中的应用
- 城乡规划中生态建筑设计研究
- 混凝土建筑结构模板施工技术研究
- 建筑工程钢筋施工技术探讨
- 公路工程建设施工质量管理与控制探讨
- 公路路面施工中沥青摊铺技术
- 关于工程质量管理及控制的几点思考
- 电力系统中电费计算方案改进的实施与探讨
- 关于创新的探讨
- 浅谈衡器检定中的替代方法
- 衡器计量检定中的技术问题及应对措施
- 制药企业QC实验室规范化管理的实现分析
- 浅析在事业单位改革中如何有效发挥政工师的作用
- 新时期员工安全教育培训工作在安全生产中的作用研究
- 新形势下基层厂矿意识形态工作创新机制的探讨
- 初探传统养生体育在健康中国建设中的走向
- 危机状态下旅游公共服务供给重点及策略研究
- 中高贯通数控技术专业课程贯通的实践与思考
- 如何寻找最小平方直线
- 浅谈汉字教学策略研究
- 新媒体对大学生思想政治教育的作用研究
- forebodings
- forebow
- forebreast
- forecall
- forecar
- forecarriage
- forecast
- forecastable
- forecasted
- forecaster
- forecasters
- forecasting
- forecastingly
- forecasts
- forecast²
- forecast¹
- fore-cited
- beggared
- beggarhoods
- beggaring
- beggarism
- beggars
- beggars can't be choosers
- begged
- begging
- 肉烂骨头在
- 肉煮烂成糊
- 肉煮烂,嘴也是硬的
- 肉燎
- 肉父
- 肉片
- 肉牛
- 肉猫儿
- 肉理
- 肉生双髀
- 肉畜
- 肉痛
- 肉痛肉抖
- 肉瘤
- 肉皮
- 肉皮儿
- 肉相
- 肉眼
- 肉眼不识泰山
- 肉眼不识神仙
- 肉眼凡夫
- 肉眼凡珠
- 肉眼凡眉
- 肉眼凡睛
- 肉眼凡胎