张天奕
[摘? ? ? ? ? ?要]? 构建双语平行语料库是实现基于实例的机器翻译的主要工作,而实现双语语料的对齐则是构建双语平行语料库的基础。主要目标是针对英语与汉语的特点,搭建一个面向文学领域的、句子级别对齐的英汉平行语料库。语料库的构建过程包括英汉句子对齐,经过清洗存入数据库,并实现对语料库的浏览、检索、导出功能。最终目标是为机器自动翻译提供可以定制的、高质量的标注数据集。进而开发了一个用户交互模块,允许用户调用包括爬虫模块、句子对齐模块、语料导入模块、句对检索模块、语料库浏览和修改模块、语料导出模块在内的所有功能模块,最后展示实验成果。
[关? ? 键? ?词]? 英汉双语;机器翻译;平行语料库;句子对齐
[中图分类号]? H315? ? ? ? ? ?[文献标志码]? A? ? ? ? ? ? ? [文章编号]? 2096-0603(2020)44-0154-04
一、引言
(一)背景
在当今信息社会,人们经常会接触到非母语的信息资源,而汉语与英语的使用都非常广泛,英汉互译已经融入了我们的生活与工作之中。为了满足人们的这一需求,研究发展机器翻译技术已经成为一种潮流。随着计算机技术的进步,基于实例的机器翻译思想正在逐步成为未来机器翻译探索的重要方向,而基于实例的机器翻译必须经过查询平行语料库来完成翻译,因此构建一个双语语料库是实现基于实例的机器翻译的前提。
20世纪80年代中期,语料库就开始应用于小说文本的翻译。在20世纪90年代建立了一大批平行语料库中,小说文本占有较大比例[1]。
汉语和英语在语法规则及语序上有着明显的区别,且存在大量难以翻译的俗语,这点在文学作品中尤为明显。这使传统的基于规则的机器翻译在实现英汉互译时面临诸多问题,在机器翻译英文时往往无法得到通顺的中文译文。这时需要建立一个内容丰富、准确可靠的英汉平行语料库,通过查询该语料库将有效地提高译文的质量,使机器翻译向“信”“达”“雅”的方向发展。
(二)技术发展状况
构建英汉平行语料库需要从收集并整理好的英汉双语文本中提取对应的双语片段,将它们成批量地存放到数据库当中,为了完成这项工作我们需要高效且精确的句子对齐技术。
研究各个级别的对齐技术一直是构建双语平行语料库的主要议题。平行语料库中只保存已经对齐的语料,语料对齐的精确度越高,平行语料库越可靠。本文将使用句子级别的对齐思想,方法主要有以下三种[2]。
1.基于长度的对齐方法。这种方法的核心假设是一种语言及其译文的长度是接近的。因为不需要参考词典信息,逻辑简单,所以运行效率高、容易实现,但对齐的准确度则相对较低。这种对齐方法由Brown和Gale提出[3][4],他们使用这种方法完成了英法双语的对齐任务,因为英语与法语发源于拉丁语系,同属字母文字,源语言与译文的长度相差不大。但英语与汉语差别较大,互为译文的英语与汉语中,往往英文的长度要明显长于汉语的长度。如果采用这种方法实现英语与汉语的句子级别对齐,则需要另外寻找一种衡量句子长度的方法。
2.基于词汇的对齐方法。通过计算一对双语文本中翻譯匹配词汇的数量占总词汇数量的比例来衡量其对齐的概率。翻译匹配词汇的占比越大,其互为翻译的概率就越高。该理论需要考虑三种情况。第一种是匹配两种语言中单词拼写相似的词汇信息,该情况面向英语法语等拉丁语系的字母语言,应用于构建英汉平行语料库时,因为两种语言区别太大,这种情况也就不再适用。第二种是匹配不同语言中存在的有着明确相同涵义的词汇,例如数字、日期、专有名词等,这些词汇在不同的语言中表达固定的涵义,合理运用这些词汇能够有效地提高对齐的准确率。第三种是匹配不同语言中涵义相对灵活多变的词汇,比如形容词、动词、名称等,这些词汇在不同语言中的涵义有所差异,匹配难度较大,但其词汇基数大,因此对它们进行匹配也是提高句子级别对齐准确率的重要途径。基于词汇的对齐思想对齐的准确度较高,但往往需要访问额外的双语词典作为参照,或者用已有的双语语料作为训练集,统计词汇匹配概率[5]。故而运行速度较慢。
3.混合方法。结合上述两种方法,在精确度和运行速度之间折中,得出的对齐方法即是混合方法[6]。Moore将基于句子长度的对齐方法与词典相结合来实现句子对齐[7]。Utsuro[8]等完成的日文与英文的句子对齐实验证明,混合方法比单纯任何一种方法效果都要好。一些语言学或非语言学的启发式信息,例如同源词、标点数字、由大写字母构成的专名以及在原文和译文同形式出现的字符串等,都可以作为句子对齐的依据[9][10]。
(三)主要研究内容
本文将在分析研究汉语与英语的语言特点的基础上,构建高质量的平行语料实验数据,包括探索如何提高语料句子级别对齐的精确度。在此基础上讨论英汉平行语料库的构建方法。
1.平行语料库爬虫的设计与实现
编写高效的、自动化的网络爬虫。使用爬虫获取一定数量的文学作品的中文版本和英文版本作为平行语料库的信息来源。因为需要的数据量较为庞大,故需要较高的爬虫运行速度。
2.平行语料的清洗、对齐及入库工作
统一语料的格式,实现语料的句子对齐。将所有通过爬虫收集到的语料以TXT的格式保存,因为TXT文件体积小,存储简单方便,兼容性好。之后根据实现句子对齐程序的要求修改语料的格式,将表达同一含义的汉语和英语的段落交替排列。
语料对齐处理。将表达同一含义的汉语和英语一一对应,这是搭建平行语料库比较关键的一步。以段落为单位的语料对齐较为容易实现,但以句子为单位的语料对齐处理则比较困难,由于英语和汉语在语法上存在差别,想要将句子内的各种结构全部严丝合缝地对齐是比较困难的。Paraconc、A-ligner等软件可以实现句子的对齐,本文将在基于长度的对齐方法的基础上,结合部分基于词汇的对齐方法进行句子对齐处理研究。
3.平行语料库的后台管理平台
将对齐的语料存入数据库,数据库使用mysql,数据库的规模初步定为70000~100000条。制作一个图形界面来实现上述的两个功能,即输入网络地址自动获取新的语料并以TXT的格式保存,以及实现语料的句子级别对齐并在显示框中显示对齐结果、将结果存入数据库增大其数据量。此外,提供给用户便于使用的接口,包括导出功能、检索功能、浏览功能等。系统提供一个句子级别对齐的英汉平行语料库,允许用户自主维护语料库,用户可以自主地不断完善该语料库,以方便自己的使用。致力于为研究者们提供数据量充足的、可操作性强的、精确度高的、可以自主维护的英汉平行语料库。用户群体选择正在学习机器翻译或研究相关内容的人员。
二、系统设计
(一)概要设计
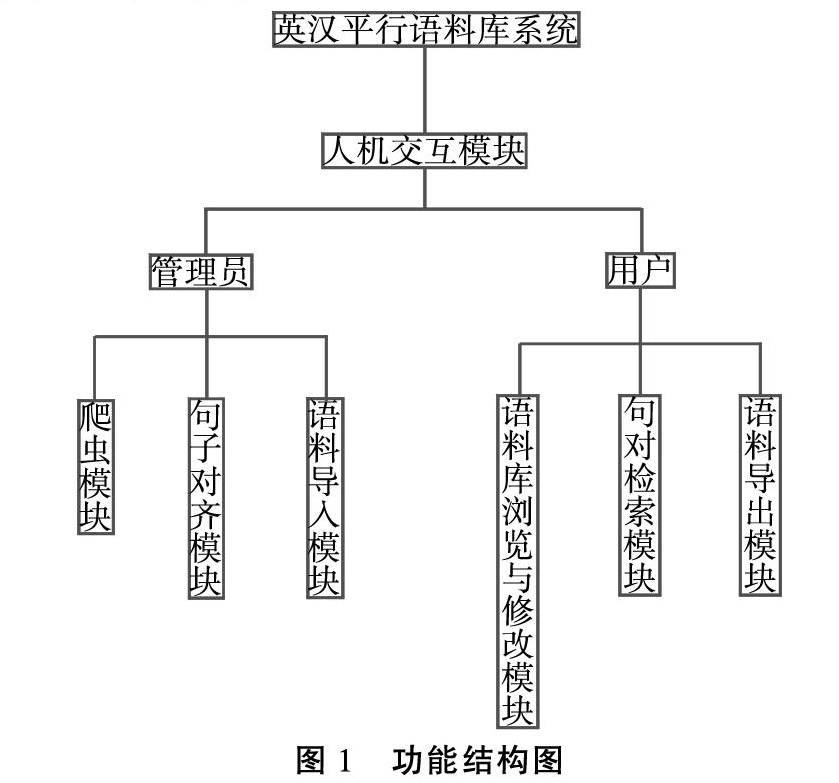
该系统包含爬虫模块、句子对齐模块、语料导入模块、语料库浏览与修改模块、句对检索模块、语料导出模块、人机交互模块共七个功能模块。
1.爬虫模块
爬虫模块实现下载英汉双语文档的功能,提供从指定的数个英文学习网站中下载文档的接口,用户需要在用户界面中输入网址与自定义的工程名称,该模块将自动完成下载工作。
该模块使用Python的selenium模块实现对Google Chrome浏览器的监控,连接运行于5000端口上的Pyspider爬虫框架,Pyspider将根据用户输入的网址与自定义的工程名称创建新的工程,之后selenium将自动修改Pyspider爬虫代码、保存工程以及运行工程,最后输出JSON格式的英汉双语文档。
2.句子对齐模块
句子对齐模块实现英汉双语文档句子级别的对齐工作。用户需要手动将爬虫模块获取的英汉双语文档从JSON格式转换为TXT格式,并将互为译文的英文与中文篇章交替排列。向句子对齐模块输入处理好的TXT文档,该模块将自动完成英汉双语语料的篇章及段落级别的对齐,之后使用算法在英汉平行语料段落级别对齐的基础上实现句子级别的对齐。
最后句子对齐模块将输出已经对齐的句对,并将对齐的结果显示在用户图形界面上,供用户审阅。
3.语料导入模块
语料导入模块将句子对齐模块输出的已经对齐的句对存储到数据库当中构成语料库。数据库选择MYSQL,数据库有用户和管理员两种角色,用户角色可以读取、调用数据库中的语料但不能对数据库进行增添、修改和删除操作。管理员角色则可以完成对数据库的修改工作。
该模块实现了用户对英汉平行语料库的增添功能,用户可以通过该模块不断地扩充英汉平行语料库的数据量。该模块必须使用数据库的管理员角色才能使用,用户角色没有使用权限。
4.数据库浏览与修改模块
数据库浏览与修改模块提供接口使用户可以通过图形界面浏览语料库中储存的所有英汉平行句对,并允许用户对句对的内容进行修改或直接删除某些句对。通过该模块实现了用户对英汉平行语料库的修改与删除功能,用户可以在使用该英汉平行语料库的过程中手动修改一些观察到的翻译错误,或直接删除一些句子对齐出错的句对,这有助于提高英汉平行语料库的句子对齐精确度,使该语料库更加可靠。同样该模块必须使用数据库的管理员角色才能使用,用户角色没有使用权限。
5.句对检索模块
句对检索模块提供接口允许用户从英汉平行语料库中检索英汉平行句对,用户可以通过句对的序号检索句对,输入句对的序号之后所有符合条件的句对将全部显示在用户图形界面上。用户也可以使用英文词汇和中文词汇检索句对,输入英文或中文的关键词,用户图形界面将显示所有包含该关键词的句对。通过该模块用户可以观察某一个词汇在英汉双语翻译中的具体实例。
6.语料导出模块
语料导出模块提供接口允许用户从英汉平行语料库中导出语料,导出文件的格式可以在TXT格式与CSV格式之间选择。用户可以通过该模块将英汉平行语料导出以满足自己的需求。
以上关于操作MYSQL数据库的功能全部通过Python的Pymysql模块完成。
7.人机交互模块
人机交互模块管理用户图形界面,为用户呈现所有的接口。用户可以在这里调用其他模块的所有功能。用户图形界面使用Python的Tkinter模块完成编写。
(二)详细设计
1.数据流动
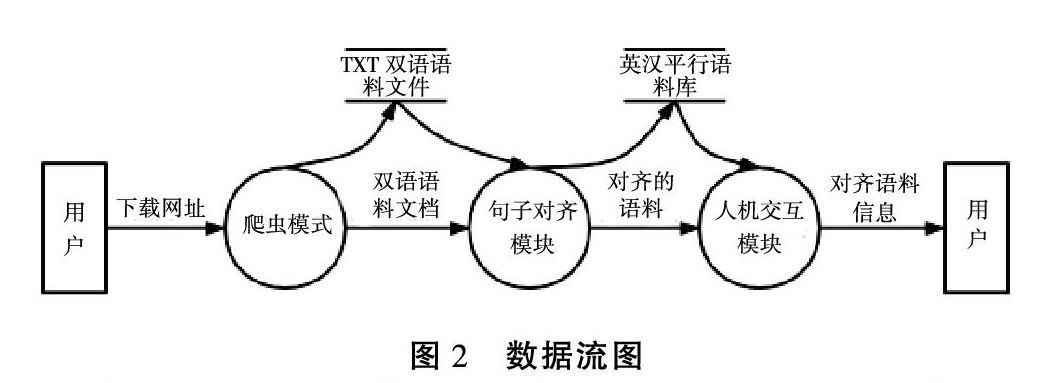
各个模块之间的数据流动情况如下图。
如图所示,爬虫模块从网络中获取到TXT格式的英汉双语文档之后将该TXT文档输入句子对齐模块;句子对齐模块处理TXT文档后得到对齐的英汉平行句对组,将该句对组存入英汉平行语料库;已经构建完成的英汉平行语料库根据用户的需求将语料信息传递到人机交互模块,人机交互模块将信息呈现给用户。
2.主要算法
本实验的核心算法是用于实现英汉语料句子级别对齐的句子对齐算法。
两种语言之间的配对模式可以大致分为四种情况。分别是中文与英文句子一一对应的‘1-1型配对;两句中文对应一句英文的‘1-2型配对;一句中文对应两句英文的‘2-1型配对以及多句中文对应多句英文的‘m-m型配对,m一般大于2,我们将包含m-m在内的其他配对类型统一定义为‘2-2型配对。因此双语语料的配对模式共有‘1-1‘1-2‘2-1‘2-2四种[11]。在这四種配对类型中,大多数中文与英文句子是‘1-1型配对关系。为了简化问题,这里我们假设相互对齐的双语语料在文本中以相似的顺序出现,不会出现语料交叉对齐的现象[12][13]。
三、总结与展望
该系统完成了英汉平行语料在句子级别上的对齐工作,从对齐精确度和程序运行速度两方面综合考虑,改进已有的算法,提出了一种用于英汉平行语料句子级别对齐的算法。系统使用户可以对英汉平行语料库进行自我维护,用户能够根据自己的需要改进语料库。
同时系统还有一些问题有待于进一步完善。
1.该系统在对齐精确度和运行速度之间存在较大的矛盾冲突,在只应用基于长度的句子对齐思想时,系统的对齐精确度不足,引入了基于词汇的句子对齐方法之后,对齐精确度有所提高,但又明显地减缓了运行速度。如果能进一步优化算法,将能使这个问题得到改善。
2.句子对齐模块对输入的英汉双语文档的格式要求比较苛刻,如果格式不符合标准就无法完成句子的对齐工作,需要进一步改进代码优化句子对齐模块对输入的英汉双语文档的兼容性。
参考文献:
[1]黄立波.中国当代小说汉英平行语料库:研制与应用[J].外语教学,2013,34(6):104-109.
[2]王占军,姚卫东.一种汉英双语句子自动对齐算法[J].计算机仿真,2009,26(2):329-333.
[3]P.F.Brown,J.C.Lai,R.L.Mercer.Aligning Sentences in Parallel Corpora[C].Proceeding of the 29th Annual Meeting of the Asso-
ciation for Computational Linguistics(ACL91).Stroudsburg:Asso-ciation for Computational Linguistics,1991:169-176.
[4]Gale,Church.A Program for Aligning Sentences in Bilingual Corpora[J].Computational Linguistics,1991,19[1]:75-102.
[5]Church K W.Char_align:A program for Aligning Parallel Texts at the Character Level[C].Proceedings of the 31st Annual Meeting of the Association for Computational Linguistics(ACL93),Coumbus,OH,USA.Stroudsburg:Association for Computational Lin-guistics,1993:1-8.
[6]劉昕,周明,朱胜火,等.基于自动抽取词汇信息的双语句子对齐[J].计算机学报,1998,21(8):135-139.
[7]Robert C Moore.Fast and accurate sentence alignment of bilingual corpora[C].Proceedings of AMTA 2012,2012:135-144.
[8]Utsuro T,Ikeda H,Yamane M,et al.Bilingual Text Matching Using Bilingual Dictionary and Statistics[C].Proceedings of the 15th International Conference on Computational Linguistics (COLING94), Kyoto,Japan.Stroudsburg: Association for Computational Linguistics,1994:1076-1082.
[9]熊文新.英汉环保领域平行语料的句对齐与再对齐[J].现代图书情报技术,2013(234):36-41.
[10]Simard M,Foster G F,Isabelle P.Using Cognates to Align Sentences in Bilingual Corpora[C].Proceedings of the 1993 Conference of the Centre for Advanced Studies on Collaborative Research:Distributed Computing(CASON93).IBM Press,1993:1071-1082.
[11]张艳,柏冈秀纪.基于长度的扩展方法的汉英句子对齐[J].中文信息学报,2005,19(5):31-37.
[12]Philippe Langlais,Michel Simard,Jean Veronis.Method and practical issues in evaluating alignment techniques[C].Proceedings of COLING-ACL,1998:711-717.
[13]Dekai Wu.Alignment[M].Handbook of Natural Language Processing,CRC Press,2010:367-408.
◎编辑 曾彦慧
Literature-Oriented English-Chinese Parallel Corpus Construction
ZHANG Tian-Yi
Abstract:Constructing a bilingual parallel corpus is the core work of realizing the Case-based machine translation,and achieving the alignment of bilingual corpus is the foundation of constructing a bilingual parallel corpus. According to the characteristics of English and Chinese, the main goal of this article is to build an English-Chinese parallel corpus that is focused on the literary field and aligned with the sentence level. The corpus construction process includes English-Chinese sentence alignment, storing in the database after cleaning and realizing the browsing, retrieval and export functions of the corpus. Providing a customizable, high-quality annotation data sets for automatic machine translation is the ultimate goal of this corpus. Furthermore, a user interaction module that allows users to call all functional modules that include web crawler module, sentence alignment module, corpus import module, sentence pair retrieval module, corpus browsing and modification module and corpus export module will be made, finally showing the experimental results.
Key words:English-Chinese bilingual;machine translation;parallel corpus;sentence alignment
- 利用微课、翻转课堂等方法促进英语学习效率的提升
- 浅析文本解读在高中英语阅读教学中的运用
- 开展经典名著阅读,提升学生核心素养的研究
- 从一次磨课历程引发的写作教学思考
- 浅谈新课改背景下高中英语教学模式及教学方法改革 与创新
- 高中英语课堂教学有效导入策略初探
- 小学英语在网络环境下的教学策略
- 高考英语语篇填空解题思路之我见
- Research on Integrating Modern Educational Technology into High School English Teaching
- 探究小学英语绘本教学存在的问题及解决策略
- 初中英语阅读课教学与学科核心素养培养
- 浅谈初中英语阅读方法与技巧
- 人教版必修一Unit4“Earthquakes”教学案例与反思
- 基于核心素养的小学英语绘本阅读教学
- 多元评价在初中英语教学中的应用
- 高中英语“建构式概要写作课堂模式”分析
- 牛津英语Book5Unit2《TheEnvironment》(第二课时) 教学设计
- 初中英语口语教学与英文歌曲的融合策略
- 利用有效教学,让初中英语教学更精彩
- 小学英语教育游戏人物设定策略探讨
- 小议初中英语学困生的教学策略尝试
- 浅谈初中英语教学如何提升学生核心素养
- 高中英语写作教学中对学生观察力、思维能力的培养 策略
- 跨界借力滋养教学
- 高中英语教学中文化品格培养策略研究
- obedience
- obedient
- obediently
- obedientness
- obese
- obesely
- obeseness
- obesenesses
- obesity
- obey
- obeyable
- obeyance
- obeyed
- obeyer
- obeyers
- obeying
- obeyingly
- obeys
- obituarial
- obituarian
- obituaries
- obituarily
- obituarists
- obituarize
- obituary
- 走哪响哪
- 走嘞
- 走嘴
- 走四方
- 走回头路
- 走在一条道上
- 走在前面
- 走在天上的人
- 走在水边上,直怕湿了鞋
- 走在高岸上观望
- 走坂
- 走壁飞檐
- 走夜路
- 走夜路不怕碰见鬼
- 走夜路吹口哨
- 走大褶儿
- 走大路怕水,走小路怕鬼
- 走大道怕水,走小路怕鬼
- 走失
- 走头无路
- 走头没路
- 走奔
- 走好
- 走婚
- 走子午