
摘要:介绍了Apriori算法和智能推荐的基本思想,针对当前互联网应用中智能推荐复杂性问题,提出了云计算环境下基于Apriori的聚类算法模型。该模型根据用户访问网站的行为特征数据,分析和挖掘出用户期望的浏览对象,动态调整云计算系统的智能推荐内容。实验结果表明,该算法模型有效提高了智能推荐的准确性和效率。
关键词:Aporiori;智能推荐;云计算;MapReduce;Hadoop
DOIDOI:10.11907/rjdk.151322
中图分类号:TP3-0
文献标识码:A 文章编号:16727800(2015)006000803
基金项目基金项目:浙江省教育科学规划项目(2014SCG430)
作者简介作者简介:金伟健(1982-),男,浙江义乌人,硕士,义乌工商职业技术学院机电信息分院讲师,研究方向为计算机网络安全、云计算。
0 引言
在信息技术支持下,智能推荐系统能够为用户提供个性化的推荐结果,使每个用户获取自己真正需要的信息。随着云计算时代的到来,网络内容提供商要想更好吸引用户访问,增加受关注程度和客户满意度,必须在用户体验和网站特点上进行研究。智能推荐作为增加用户体验、提升网站满意度的有效途径,近年来受到了业界研究人员的广泛关注。搜索引擎输入的是查询关键字,推荐引擎输入的则是用户的行为特征数据。智能推荐就是针对这种行为建模,对用户感兴趣或者期望看到的内容进行推测的服务。
用户行为分析和挖掘是基于用户访问、点击、操作等的“大数据”行为,根据热门、兴趣、地域、探索四大策略逻辑,按照一定算法推测出用户感兴趣的内容。数据分析的目的是建立客户行为模型,推理出目标数据。这些模式可以是客户细分或者客户聚类,也可以是关联规则集。根据这些行为特征建立的模型,能够自动计算出用户感兴趣的内容,判断出用户的可能性需求等。数据挖掘、机器学习、模糊数学和其它信息处理手段被广泛应用于数据分析领域。
本文提出云计算环境下基于Apriori算法的智能推荐模型,该模型通过综合考虑用户浏览行为习惯与心理预期在不同网站的表现,预测出网站推荐访问的内容,动态调整云计算系统的智能推荐策略,在满足用户预期的前提下实现任务的及时性。基于用户行为特征的智能推荐算法,通过对用户行为特征进行统计和数据挖掘得到这类用户的浏览规律,从而增加用户对网站的粘合度和体验。
1 算法模型理论依据及设计思想
云计算环境下,用户访问具有动态性和模糊性。根据用户行为数据生成规则集,为了提高推荐的准确性,并减少噪音,只保留大于最小置信度的规则。为了生成所有频集,使用递归方法。
1.1 Apriori算法概念
Agrawal[1]等提出了用于挖掘关联规则的Apriori算法。Apriori算法使用一种逐层搜索的迭代算法,目标是通过不断迭代,缩小聚类范围。
过程如下:
(1)连接。目标是找出Lk,通过Lk-1 做自连接运算产生候选k-项目集的集合。设置候选集合为Ck。
(2)剪枝。对于Ck包含的元素,使所有的频繁k-项目集都包含在Ck中,对数据库进行扫描计算, 计算Ck候选集合元素数量。确定Lk, 从而属于Lk[2]。
1.2 智能推荐建模
智能推荐 模型集合多种技术,包括关联规则、数据挖掘、模糊决策、机器学习等,既要将大数据的样本预处理好,也要融合好多种技术,取长补短。随着系统吞吐数据规模的扩大,大数据挖掘成为智能推荐模型成功的关键,因此必须选择分布式策略处理大量用户行为数据,并进行深入挖掘。MapReduce简单易用,其迭代式的运算框架能很好地满足这种数据挖掘分析的需求。
1.3 基于MapReduce的客户特征智能推荐模型
本文基于用户访问站点的行为特征,建立一种基于用户行为特征分析的云计算调度机制,其模型如图1所示,用户终端负责收集本地用户行为信息再上传给各类服务提供商的用户行为数据分析模块。用户行为数据分析模块通过对用户提交任务和查看任务结果行为的历史数据进行统计与分析,采用相应的分布模型对用户各时间片段内的工作状态和心里预期任务完成时间进行定性刻画。用户行为规律数据按服务类别化,采用唯一的服务类别编码并统一存储在云计算综合控制中心的策略管理模块。任务调度模块收到任务管理模块的请求后根据服务编码查找当前时间片段的资源分配策进行资源动态分配。
MapReduce是Google提出的一个软件框架,它提供了一种在大规模计算机Cluster中对大数据进行分布式处理的算法,通过将海量数据集切分成小数据集,提交给不同的计算机节点作并行处理。 MapReduce将客户行为特征数据结构化为
2 云计算环境下智能推荐实现策略
目前有很多改进的关联规则算法,但是大部分未考虑算法的执行效率。为了提高算法效率,本文提出了一种基于MapReduce的任务调度算法来进行Apriori数据挖掘。
2.1 Map阶段
通过对用户特征行为进行建模,将Apriori连接和剪枝的过程抽象成Map和Reduce的过程,从而实现推理运算的并行化处理。Hadoop[78]平台下的MapReduce任务调度是等待响应机制,即等待每个节点的请求,先是主节点应对响应,计算出哪个从节点是空闲的,如果空闲就分配任务给它,依次类推地响应计算请求。
2.3 实验及结果分析
系统基于Hadoop0.20.0[912]开发, 硬件配置是:Core 2 E7500 Dual-core Processor 4GB RAM。软件配置是:Ubuntu Linux 11.10,Hadoop-0.20.0,JDK 1.6。
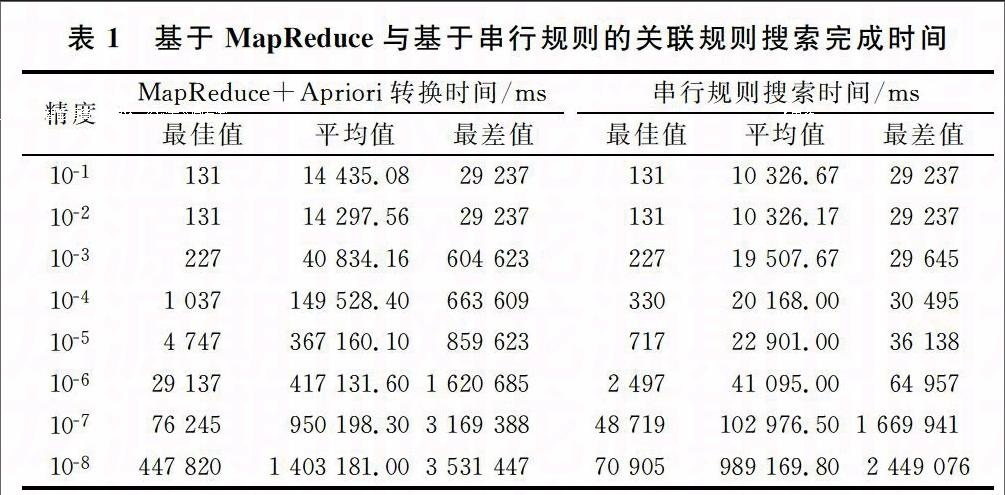
按照Hadoop部署手册将Apriori算法Jar包部署到实验平台,配置文件中替换Hadoop中自带的FIFO的配置节点。实验总共部署9台PC作为Cluster,其中一台主机作为主节点Map主机,剩下的8台PC作为子节点机。试验中分别采用FIFO传统调度算法和本文所提出的基于MapReduce的Apriori算法,在HDS这个基准测试程序中进行Apriori变化实验,以及用户特征行为获取,输出初始规则集。为了比较并行算法和传统串行算法对JOB的影响,设置JOB精度为8个组,再根据Cluster的当前作业负载,确定每组中JOB的数量。
从表1可以看出,在求解精度较低时,两种算法的求解时间相当,但随着求解精度的增加,基于MapReduce的Apriori连接和剪枝过程要明显优于传统的串行搜索。这是因为,由于函数的求解精度小,算法的并行迭代次数少,因此MapReduce框架的优势显示不出来。在最极端的情况下,例如两个表的关联规则生成,任务经过一次MapRedece过程即可求解,因此两种算法所花时间差异不大。随着候选集合的扩展、精度的提高,加上迭代次数的增加,基于MapReduce的Apriori要明显优于线性的关联规则算法。
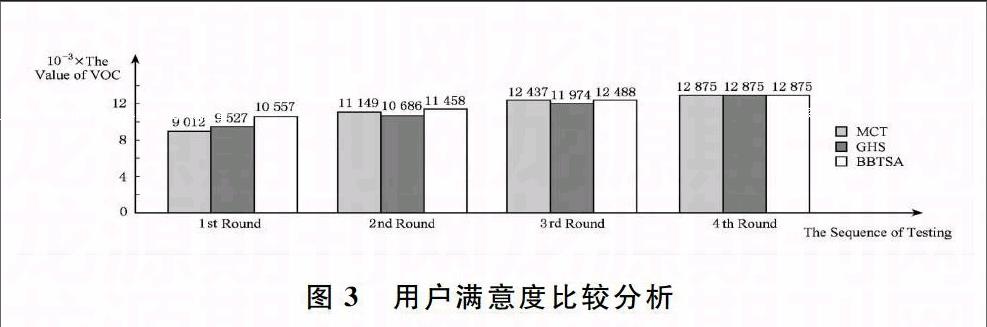
从图3可以看出,经过对比,在客户满意度VOC调查中,经过MapReduce框架处理的Apriori算法明显优于其它数据挖掘算法。基于框架结构可以有效提升变换的稳定性,使小波变换的时间和精度稳定在一个水平线上,而线性变换算法由于是串行执行,完全依赖于处理器全部的处理时间,因此在稳定性上,基于MapReduce的Apriori算法更具优势。
3 结语
本文针对移动互联网用户连接问题,将Apriori算法引入到智能推荐系统设计中,提出了一种云环境下的智能推荐模型。为提高用户行为特征分析及关联预测速度, 并实时应用到网站推荐中, 设计了在MapReduce上运行的具有高效率的Apriori并行算法模型。为减少算法中边际效应对预测的影响,可将Apriori应用到云计算中,所设计的并行算法可以实现负载平衡且干扰少, 因而具有较高的加速比且具有适于Apriori算法的特性。但该模型尚有许多待改进之处,如:智能推荐系统的模糊性、容错性等。如何准确划分推荐层次,以及在用户行为数据不可信的情况下,如何对智能推荐模型进行识别和优化则有待进一步研究。
参考文献参考文献:
[1]AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C].In Proceeding of the 20th International Conference on Very Large Databases,1994:487499.
[2]赵卫中.基于云计算平台Hadoop 的并行Kmeans聚类算法设计研究[J].计算机科学,2011, 38(10):166168.
[3]周景才.云计算环境下基于用户行为特征的资源分配策略[J].计算机研究与发展,2014,51(5):11081109.
[4]张凯.云计算下基于用户行为信任的访问控制模型[J].计算机应用,2014,34(4):10511054.
[5]M BURROWS.The chubby lock service for looselycoupled distributed systems[J].Proceedings of the 7th symposium on Operating systems design and implementation,2006,6(2):335350.
[6]J BERLINSKA,M DROZDOWSKI.Scheduling divisible MapReduce computations[J].Journal of Parallel and Distributed Computing,2011,3(71):450459.
[7]T SANDHOLM,K LAI.Dynamic proportional share scheduling in hadoop job scheduling strategies for parallel processing[J].Dynamic proportional share scheduling in hadoop Job scheduling strategies for parallel processing,2010,2(62):110131.
[8]K KAMBATLA.Towards optimizing hadoop provisioning in the cloud[J].First Workshop on Hot Topics in Cloud Computing,2009,3(2):118.
[9]WU RONG.Cyclic workflow execution mechanism on top of MapReduce framework[C].Washington:Seventh International Conference on Semantics,Knowledge and Grids,2011:2835.
[10]NIELSEN O M,HEGLAND M.Parallel performance of fast wavelet transform[J].International Journal of High Speed Computing,2000,11(1):5573.
[11]WANG C,WANG Q,REN K.Privacypreserving public auditing for data storage security in cloud computing[J].In Proceedings of IEEE INFOCOM,2010,3(2):5960.
[12]WHITE R,WHITE T.Hadoop:the definitive guide[M].Sebastopol:OReilly Media,2012.
责任编辑(责任编辑:孙 娟)
英文摘要Abstract:The basis mechanism of Intelligent Recommendation is introduced. Aimed at solving the complicated issue, a new Apriori Algorithm model based on Cloud Computing is proposed. Recoding to the users behaviors of visiting website, the adaptive viewing objects are calculated by analyzing and data mining. And the contents of Recommendation are adjusted dynamically for computing. By analyzing the experiment result on Hadoop platform, it shows that the new model based on Apriori for Cloud Computing is more efficient and more exact.
英文关键词Key Words: Apriori; Intelligent Recommendation; Cloud Computing; MapReduce; Hadoop
- 清廷与蒙古藩贡的周边传播探析
- 我国失地农民的媒介镜像考察
- 论影视作品的跨媒介多元传播
- 全媒体时代下省级卫视的发展浅析
- 插画如何助力品牌栏目讲好故事
- 论歌剧的美学特征与文化意蕴
- 现代汉语言文学的信息化发展及学生才情培养
- 基于网络传播视角的外语教学的创新研究
- 基于网络自主学习的英语语言学课程教改探索
- 新媒体对学前儿童音乐教育的影响
- 大数据时代环境艺术设计教学思路的转变
- 卫生宣传在疾病预防控制工作中的应用
- 新媒体传播对民族文化传播与融合的作用
- 图书馆工作理论与数字化图书馆服务创新研究
- 精准扶贫价值观传播下高校困难学生的资助情况研究
- 新媒体时代启发式英语教学课堂设计研究
- 翻译文化传播中的互文翻译观及其应用
- 新媒体时代思修课互动教学方法研究
- 新媒体时代英语语言与文化传播路径探析
- 地域文化在品牌包装设计中的应用研究
- 声乐教学理论在实践中的应用与完美融合
- 信息时代高校教务教学管理工作实践探析
- 新媒体时代的大学英语教育模式研究
- 高校青年教师的专业伦理素质培养路径
- 黑龙江民间艺术文化传播的保护与传承
- greedier
- greediest
- greedily
- greediness
- greedinesses
- greedless
- gandered
- gandering
- ganders
- gang
- gangbusters
- gangdom
- ganged
- ganging
- gangland
- ganglands
- ganglike
- gangling
- gangling/gangly
- gangly
- gangplank
- gangplanks
- gangrenate
- gangrene
- gangrened
- 主动吸取各家之长以使自己受益
- 主动地批评自己的错误,争取他人帮助
- 主动大方地资助
- 主动宾句式
- 主动帮助受欺侮的一方
- 主动式
- 主动当引荐人
- 主动性
- 主动承担过失并辞去职务
- 主动承担过失,并检查责备自己
- 主动投案
- 主动投降
- 主动攀附、缔交
- 主动权
- 主动脉
- 主动要求承担某项艰难的工作
- 主动靠近
- 主卧
- 主卫
- 主印
- 主厂制
- 主厨
- 主句
- 主叫
- 主司