摘 要:汉语中地名歧义现象非常普遍。我国每个县级城市基本上都有一个镇名叫城关镇。在信息抽取、融合、知识图谱构建中,首先要解决地名歧义问题。运用最大生成树算法,提出了一种地点归一化的混合模式解决方法,其基本步骤为:基于CRF的地点命名实体识别;用最大生成树的图搜索算法进行地名消岐,如无法消岐,则通过半自动抽取计算缺省地名。对《人民日报》2013下半年相关数据进行测试显示,正确率为93.7%。
关键词:信息抽取;地点归一化;最大生成树;命名实体;歧义
DOIDOI:10.11907/rjdk.151159
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2015)007-0026-04
0 引言
地点归一化任务是确认一个有歧义地点命名实体的确切含义。地名有歧义的情况非常多,譬如,我国名叫城关镇的地名就非常多,地点归一化在信息抽取系统中至关重要。
地点归一化是词义消歧(Word Sense Disambiguation)中的一个特殊部分。词义消歧方法很多,譬如基于带有注释的语料库,通过手写规则或者机器监督学习来进行词义消歧[1-3];或者基于语料库无监督方法 [4-6]。地点归一化不同于传统的词义消歧,多数情况下由于选择的限定导致难以区分出一个地点的确切含义。譬如在句子“大雁塔位于西安”中,通过“位于”这个词我们可以确定西安肯定是一个地名,但是不足以确定这个地点的确切含义。地点归一化对同一篇文章中与该地点实体共同出现并且在地理上对其有约束的其它地名非常依赖。如果一篇文章中同时提到了“西安”、“咸阳”和“宝鸡”,那么这3个地点名词的确切含义极有可能是陕西省西安市、陕西省咸阳市和陕西省宝鸡市。有一些固定的关键字驱动模式可以通过上下文确定地点命名实体的确切含义。这些模式用“省”、“市”、“镇”、“位于”等词语作为关键字。例如,模板“某某+市”就能识别地点。本文提出运用Maximum Spanning Tree方法解决地点消岐问题。构造一个图,在这个图中每个节点代表一个地点的一种含义,每条边代表两个地点含义之间的关系。通过一个图的生成算法可以得出最好的结果。如果这样还不能解决所有节点,则可以使用该地点的默认含义,每个地点的默认含义都是通过统计处理半自动抽取出来的。
1 地点归一化应用
地点归一化在事件抽取与合并、事件可视化以及实体概况等方面都有着广泛的应用。
(1)事件抽取与合并。
事件的提取是在事件合并之前完成的。提取之后的事件在合并之后能提供重要的内容。事件合并的过程主要是检测信息的兼容性,比如检测同义词、名字的别名和回指词的共指关系,以及时间和地点的归一化。如果两个事件在时间和地点上冲突,这两个事件就不能合并,如图1所示。
图1 事件合并示例
(2)事件可视化。
通过地点归一化可以显示一个事件在什么地点发生。
(3)实体概况。
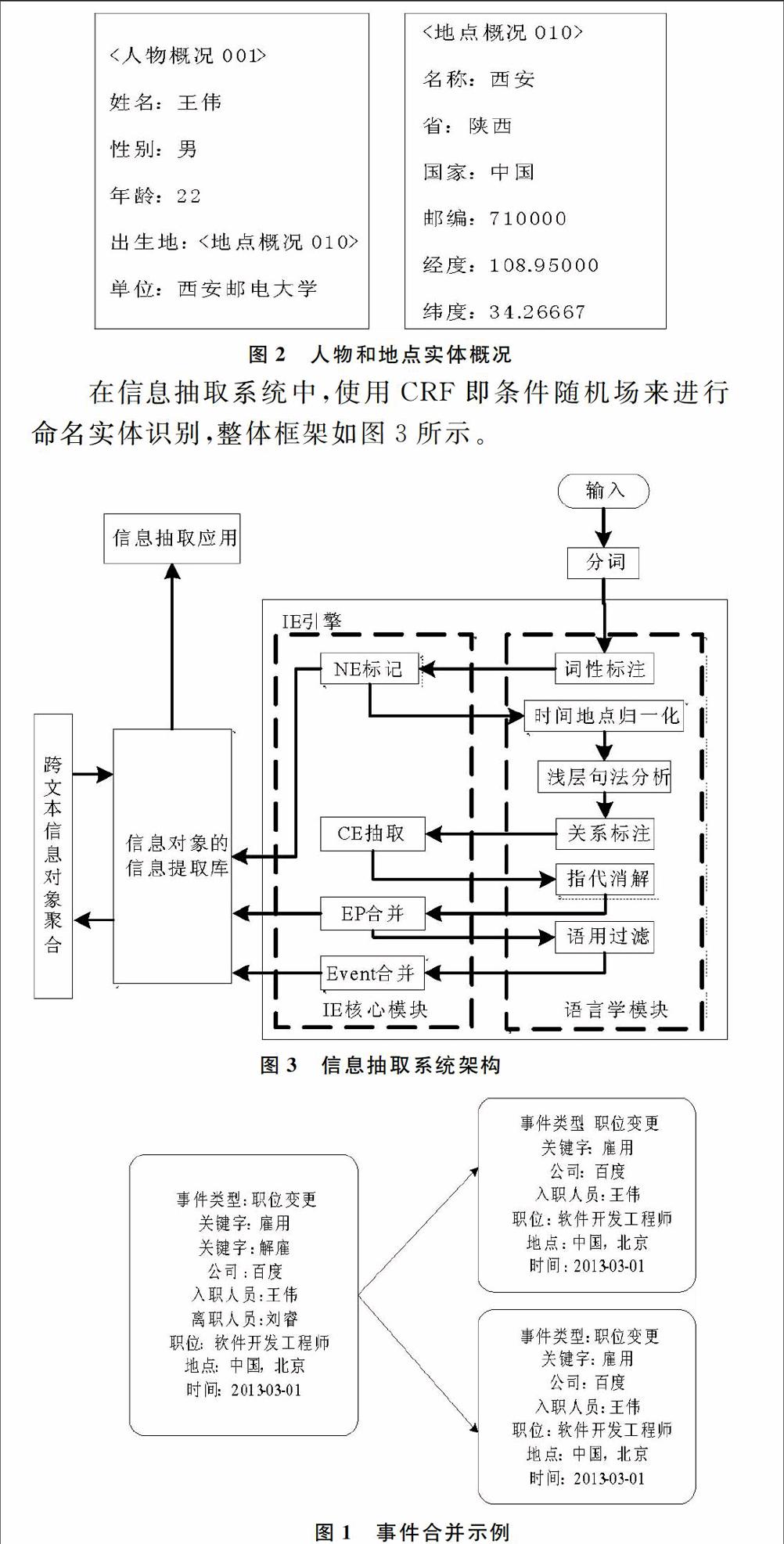
实体概况就是一个实体(比如人物、地点、组织机构)的信息对象,一般定义成一个属性值矩阵(Attribute Value Matrix),用来表示实体的各项关键信息,包括和其它实体间的关系。每一个属性槽都代表了实体在某一方面的信息,在概况属性值矩阵中,每一个关系都由一个属性槽来体现,如图2所示。
2 地点命名实体识别
命名实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、组织机构名等等。命名实体识别的任务是将待处理文本中的信息分为3大类(实体类、时间类和数字类)、7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。命名实体识别系统[7-14]可对文本中的人名、地名、组织机构名、时间等进行识别。
图2 人物和地点实体概况
在信息抽取系统中,使用CRF即条件随机场来进行命名实体识别,整体框架如图3所示。
图3 信息抽取系统架构
基于自然语言处理技术的中文信息抽取系统采用了有限状态转换机(FST)规则和统计机器学习相结合的方法,运用多层模块化设计思想实现非受限域的中文分词、词性标注、命名实体识别、时间地点归一化、句子识别分析。
3 最大生成树算法
通过地点词的上下文确实对该地点的归一化有很大帮助,但是仍然有相当多的词语无法通过上述模型进行判定。一般一个文本中出现的所有地点之间联系紧密,所以为了确定一个有歧义地点的确切含义,对该地点所在的文本作全局分析是很有必要的。
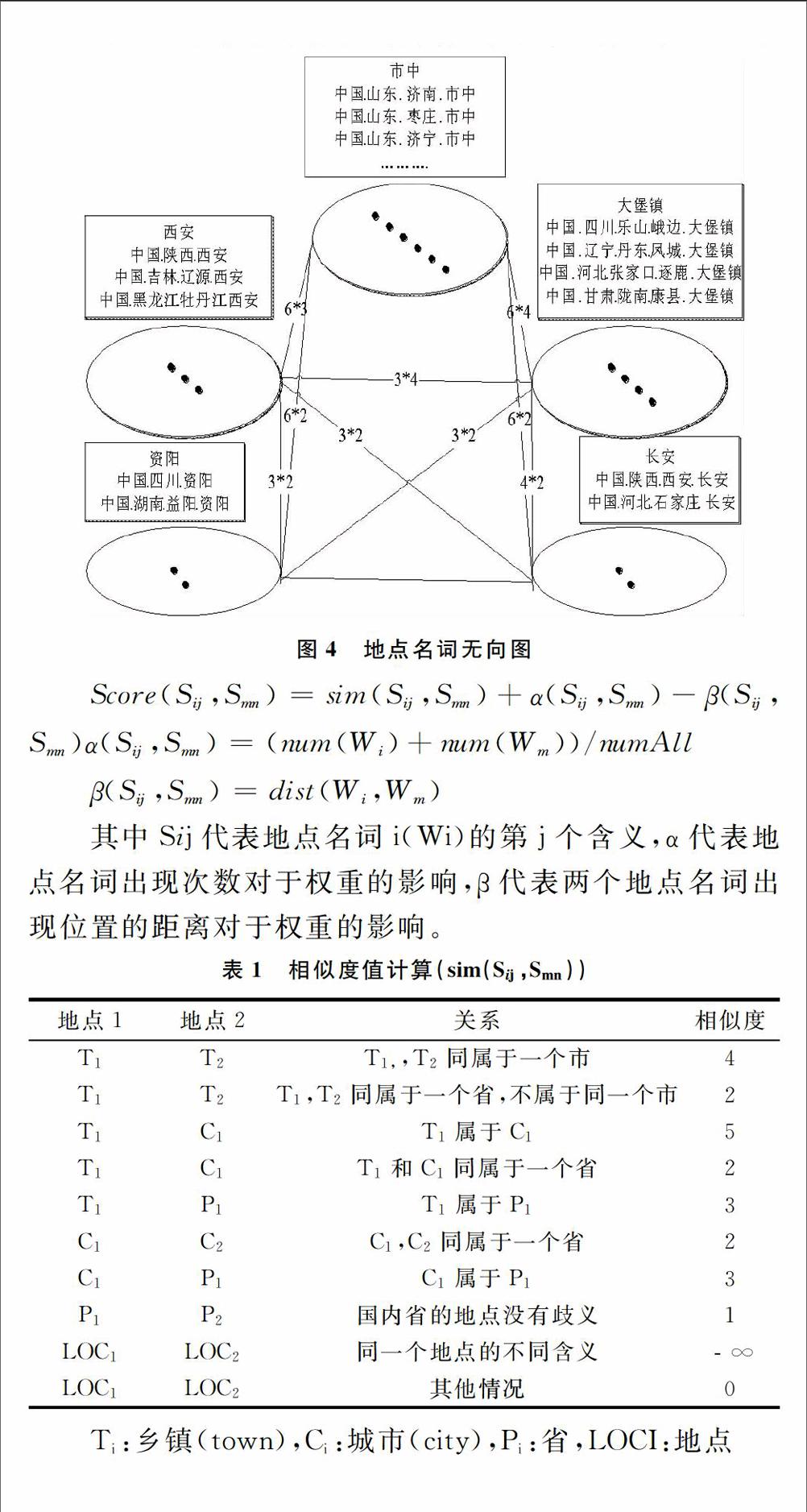
我们在地点归一化程序中构造了一个有权重的无向图,如图4所示,图中的每个节点代表了一个地点的一个含义,每一条边代表了两个地点的相似度权重。显然,一个地点的不同含义所代表的节点是没有边连接的,或者说这条边的相似度是负无穷大。最大生成树算法参考了Kruskal的最小生成树算法[15],所构造的无向图最大生成树的每一个节点即为每一个地点最有可能的含义。
图4 地点名词无向图
对于两个节点边的权重计算,定义如下规则:
①地点同属于一个省或一个市,那么所给的权重就要大一些;
②地点名词出现在文本中的位置也要作为参考。两个地点名词在文本中出现的距离越近,它们的权重越高;
③ 地点名词在文本中出现的次数同样会影响权重的计算。在无向图中多次出现的地点名词将只有一个节点来代表。假定在一个文本中多次提到的相同地点名词只有一个含义,即遵循One sense per discource原则[16]。
当计算地点之间的权重时,预先定义的相似度值如表1所示。地点名词出现的次数和不同地点在文本中出现位置的距离也要加以考虑。在选择了一条边之后,意味着这条边的两个节点所代表的含义就是该地点的最终结果,与此同时,这两个地点的其它含义也不会再参与最大生成树计算。权重值通过下面的公式进行计算:
Score(Sij,Smn)=sim(Sij,Smn)+α(Sij,Smn)-β(Sij,Smn)α(Sij,Smn)=(num(Wi)+num(Wm))/numAllβ(Sij,Smn)=dist(Wi,Wm)
其中Sij代表地点名词i(Wi)的第j个含义,α代表地点名词出现次数对于权重的影响,β代表两个地点名词出现位置的距离对于权重的影响。
表1 相似度值计算(sim(Sij,Smn))
地点1地点2关系相似度T1T2T1,,T2同属于一个市4T1T2T1,T2同属于一个省,不属于同一个市2T1C1T1属于C15T1C1T1和C1同属于一个省2T1P1T1属于P13C1C2C1,C2同属于一个省2C1P1C1属于P13P1P2国内省的地点没有歧义1LOC1LOC2同一个地点的不同含义﹣∞
LOC1LOC2其他情况0
Ti:乡镇(town),Ci:城市(city),Pi:省,LOCI:地点
4 默认地名计算
在将该系统投入实际应用时,我们发现默认地名对整个系统的性能起者至关重要的作用。比如,人们在文章中读到西安这个词时,脑海中立刻闪现的是陕西省西安市,而不是吉林省辽源市的西安或者黑龙江省牡丹江市的西安。默认地名的提取逐渐成为提升整个系统性能的瓶颈问题。正如前面所提到的,一个地点名词可能存在好几个甚至好几十个不同的含义,必须在文章中找到有用的证据来区分哪一个含义才是最正确的。但是在多数情况下,都没有很明显的线索,所以系统只能选择默认地名即大多数认同的地名。
本系统中,地点名词一共有35 867个,其对应的含义有45 062个,涵盖了中国所有镇级及镇级以上地名。其中有4 288个地点名词是有歧义的,其对应的含义高达14 023个,很显然,通过人工方法去得到这4 288个地点名词的默认地名要花费大量的人力物力。因此,我们选择通过最大生成树算法来确定一个地点名词的默认含义。
通过搜索引擎诸如百度、搜搜、有道等能得到许多非常有用的文本数据。本实验采用的是百度搜索引擎。为了获得与地名相关的文本数据,我们编写了一个脚本在百度上下载网页,把每一个有歧义的地点名词作为搜索的关键字(访问网页http://www.baidu.com/s?wd=location),然后下载前3页的网页(30个网页)。
为了从下载的网页中得到该地点名词的默认含义,本文用最大生成树算法对这些网页地名进行处理。
对这4 288个有歧义的地点名词,结果中仍然有一小部分没有得到相应的默认含义,那是因为下载的网页没有足够的依据使结果达到阈值。经过观察发现,这一部分地点名词在其它搜索引擎的搜索结果中,被引用的次数相当低,从而也证明了这一部分地点名词对于整个系统产生的影响非常小。
5 实验数据及结果分析
通过上下文和默认含义信息,地点归一化过程是非常有效和准确的。处理流程分为以下4步:
①地点命名实体的识别;
②将所有地点命名实体分为有歧义和无歧义的;
③对于有歧义的地点名词进行最大生成树处理;
④结果超过阈值的地点名词就用最大生成树得到的地点作为结果,如未超过,则使用默认含义作为结果。
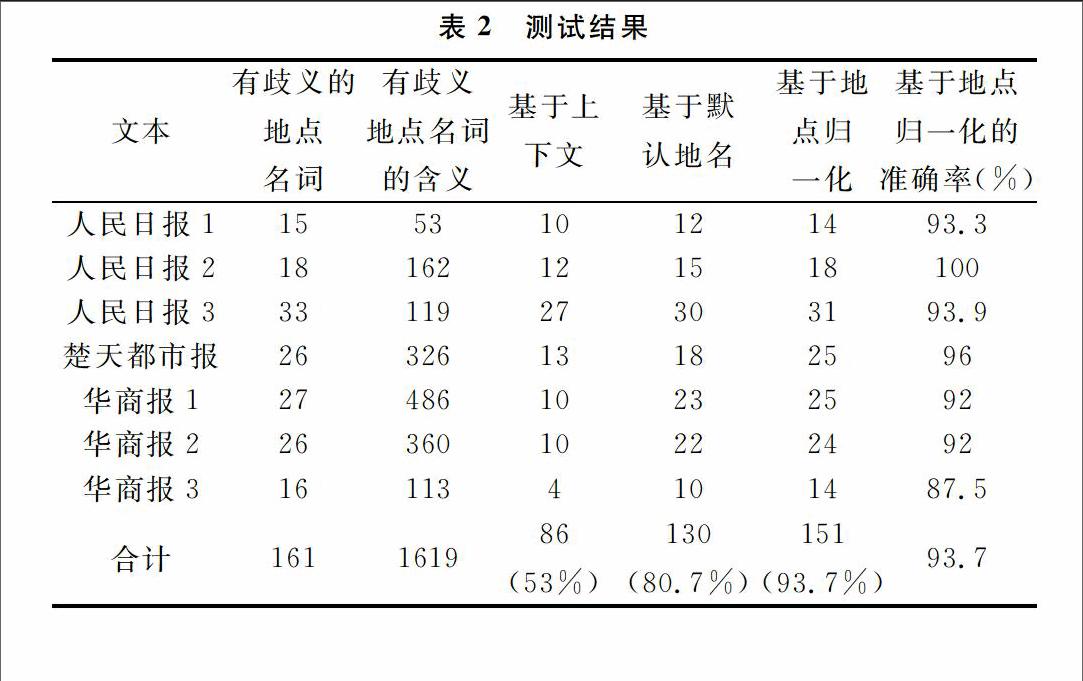
表2是测试结果,以《人民日报》和《华商报》作为主要数据源。如表2所示,第4列表示的是基于上下文确定地点名词的含义结果,如果上下文未能提供有效信息,就直接选取该地点名词的第一个含义作为其结果,通常情况下第一个含义为该地点名词的默认含义,结果显示的准确率为53%。第5列表示的是基于默认地名确定地点名词的含义结果,即直接使用地点名词的默认地名作为其结果,结果显示的准确率为80.7%。第6列表示基于地点归一化处理确定地点名词的含义结果,结果显示的准确率为93.7%。
6 结语
本文提供了一种针对信息抽取的实验结果以及应用地点归一化方法,实践证明准确有效。今后的研究中要继续整合和扩展其它地点名词,比如山脉、湖泊、河流等等。同时要不断调整表1中的相似度值,从而得到更好的归一化结果,达到更高的准确率。
参考文献:
[1] HIRST, GRAEME.Semantic interpretation and the iesolution of ambiguity [M].Cambridge University Press,1998.
[2] MCROY, SUSAN W.Using multiple knowledge sources for word sense discrimination[J].Computational Linguistics,1992,18(1):1 -30.
[3] NG,HWEE TOU,HIAN BENG LEE.Integrating multiple knowledge sources to disambiguate word sense:an exemplar-based approach[C].In proceedings of 34th Annual Meeting of the Association for Computational Linguistics,1996.
[4] DAGON, IDO , ALON ITAI. Word sense disambiguation using a second language monolingual corpus[J].Computational Linguistics,1994, 20(4): 563- 596.
[5] YAROWSKY, DAVID. Word -sense disambiguation using statistical models of rogets categories trained on large corpora[C].In Proceedings of the 14th International Conference on Computational Linguistics (COLING- 92), 1992.
[6] YAROWSKY,DAVID.Unsupervised word sense disambiguation rivaling supervised methods[C].In Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, 1995.
[7] 谷川,周宏宇,于江德.融合多特征的中文产品命名实体识别[J].科学技术与工程,2013,13(31):1671-1815.
[8] 李广一,王厚峰.基于多步聚类的汉语命名实体识别和歧义消解[J].中文信息学报,2013 ,27(5):29-35.
[9] 陈钰枫,宗成庆,苏克毅. 汉英双语命名实体识别与对齐的交互式方法[J].计算机学报,2011,34(9):1688-1696.
[10] 乐娟,赵玺. 基于HMM的京剧机构命名实体识别算法[J].计算机工程,2013,39(6):266-272.
[11] 邱泉清,苗夺谦,张志飞. 中文微博命名实体识别[J].计算机科学,2013,40(6):196-198.
[12] 邓本洋,吕新波,关毅. 基于堆积策略的电子病历实体识别[J].智能计算机与应用,2014,4(1):69-53.
[13] 张金龙,王石,钱存发. 基于CRF和规则的中文医疗机构名称识别[J]. 计算机应用与软件,2014,31(3):159-162.
[14] 鞠久朋,张伟伟,宁建军,等. CRF与规则相结合的地理空间命名实体识别[J].计算机工程,2011,37(7):210-212.
[15] CORMEN, THOMAS H, CHARLES E LEISERSON, et al. Introduction to Algorithms[M]. 3rd ed.The MIT Press,1992.
[16] GALE W A , K W CHURCH, D YAROWSKY. One sense per discourse[C].In Proceedings of the 4th DARPA Speech and Natural Language Workshop , 1992.
(责任编辑:杜能钢)
- 数学建模教学融入思政内容的探索
- 浅谈高职院校大学生创新创业项目计划存在的问题及策略
- 新时代高职大学生思想政治教育工作和学生管理工作合力机制构建研究
- 高职《机械CAD/CAM》课程教学探讨
- 新时代《思想道德修养与法律基础》教学方法研究
- 在生物教学中渗透对学生健康生活方式的培养
- 海南省大学生网络公开课自主学习现状及影响因素分析
- 浅析云教学环境下教学共同体的构建
- 高职产教深度融合实践教学育人模式研究
- 浅析如何利用微课培养初中生数学自主学习的能力
- 思维导图在小学语文教学中的应用
- PBL教学法实施路径及效果研究
- 初中物理实验中创造性思维培养的实施策略
- 闽南非物质文化遗产在小学校园文化中的应用与实践
- 助学飞翔,国贷圆梦
- 中职语文口语教学中的多元情境创设策略
- 高中数学微课教学浅论
- 浅谈大学生早起手机打卡行为引导教育与学风建设
- 浅谈小学语文高段导学单关键问题的设计
- 新时代供给侧结构性改革背景下四川省高校大学生就业形势现状分析
- 高校大学生就业指导的困境及全程化指导路径
- 语言输入理论视角下学生听力能力培养探究
- 数控车工技能竞赛样题加工浅析
- 应用型本科院校背景下的电工电子技术课程改革与实践
- 独立学院转设民办高校过程中人才队伍的稳定性研究
- redoubting
- redoubt's
- red pepper
- red peppers
- redraft
- redrafted
- re-drafted
- re-drafting
- redrafting
- redraft's
- redrafts
- red rag
- redrawer
- redrawers
- redrawing
- redrawn
- redraws
- redream
- redreamed
- redreaming
- redreams
- redreamt
- redress
- redressable, redressible
- redressed
- 天空里闪电——雷厉风行
- 天空降下的球状的冰
- 天空高远
- 天空,苍穹
- 天空,高空
- 天空,高远之处
- 天穿
- 天窗
- 天窗下谈天——说亮话
- 天立厥配
- 天章
- 天童第一座
- 天端
- 天竹
- 天竺
- 天竺葵
- 天笑
- 天策
- 天算不由人算
- 天算不由人算。
- 天篷鱼缸石榴树
- 天籁
- 天籁新韵
- 天粟马角
- 天粪