

摘 要:针对基于云计算平台的移动教学系统中存在的语义信息表达不足导致检索结果不理想的问题,提出一种基于本体的移动学习资源语义检索模型,该模型包括检索信息分词、语义扩展和语义检索3大模块。基于该模型采用七步法,利用Protégé本体构建工具构建移动学习资源本体;利用集成开发工具Eclipse和Xcode开发基于本体的移动学习资源语义检索系统,该系统包括基于iPad的客户端程序和后台服务;通过平台使用验证模型的可行性。
关键词:移动学习资源;云计算;语义检索;信息检索;本体;本体构建
DOIDOI:10.11907/rjdk.151511
中图分类号:TP301
文献标识码:A 文章编号文章编号:16727800(2015)009002503
作者简介作者简介:刘艺(1982-),男,山东淄博人,河南省农业科学院图书馆助理研究员,研究方向为计算机应用。
0 引言
近年来,随着无线通信技术、移动计算技术和移动终端的发展,一种新学习方式——移动学习应运而生。移动学习是移动技术与数字化技术(eLearning)相结合而产生的一种新兴数字化学习形式[ 1 ]。移动学习能满足人们随时随地自主学习的需求,必将成为未来学习的新模式,移动学习资源也将成为决定移动学习能否顺利开展的关键因素[ 2 ]。随着互联网的快速发展,移动学习资源呈现迅猛增长趋势,移动学习资源数量不仅多,而且结构复杂,导致学习资源检索困难或检索结果冗余信息较多。因此,高效合理组织这些资源是提高移动学习资源检索效率的有效途径。
信息检索方式有传统信息检索、数据库数据检索和语义Web数据检索。其中,传统数据检索主要是对文本和Web中的信息进行检索,但检索条件一般存在语义模糊性,导致检索结果不准确;数据库数据检索一般具有明确语义,要求精确获得满足条件的数据,但数据库查询是结构化查询,对于网络中诸多非结构化数据,其使用范围并不广泛;语义Web数据检索是基于知识的、语义的匹配,在提高检索查准率和查全率方面都有很好的表现,通过对相关文档的解析和推理在语义层面实现信息检索,实现高效率智能化检索[ 3 ]。语义检索与传统检索的主要区别体现在前者是对查询条件进行语义层面处理,表现为语义扩展,提高查准率和查全率[ 4 ]。目前,基于本体的语义检索主要有基于现有本体的语义检索和基于领域本体的语义检索两种方式[ 5 ]。
本文以改善移动教学系统中移动学习资源检索有效性为目标,采用基于领域本体语义检索的数据检索方式,利用语义网中的关键技术,设计基于本体的移动学习资源语义模型,并开发基于本体的移动学习资源语义检索系统。
1 模型框架
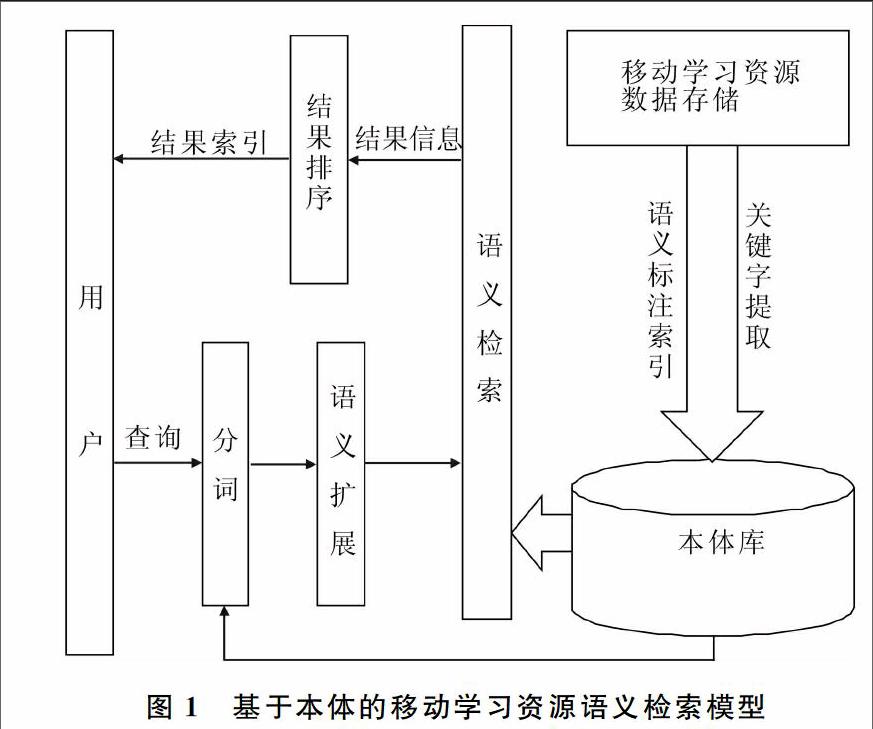
基于本体的移动学习资源语义检索模型如图1所示,它由3大模块组成:分词、语义扩展、语义检索。
图1 基于本体的移动学习资源语义检索模型
1.1 分词
用户输入查询内容通常有以下3种情况:单个单词、多个单词和句子。因此, 基于本体的移动学习资源模型首先要对用户输入的查询信息进行分词处理。本文采用基于本体的正向最大匹配分词算法对用户输入查询信息进行分词,该算法核心思想为:首先,从左向右截取用户查询信息作为待匹配汉字串;然后,将该汉字与本体库中的词条进行匹配;最后根据匹配结果不同进行相应处理。算法流程如图2所示。
图2 基于本体的正向最大匹配分词算法流程
利用伪代码对基于本体的正向匹配算法的具体描述如下:
Initialization(查询信息) //处理用户信息,最后只包含汉语字符
S=Left(汉语字符,M) //从左向右选取M个汉字,作为匹配汉字串S,M
是由本体库中含有待匹配的汉字串首字符的最长词条
的字符数确定的
If S=本体中的词条
then Print “S” //待匹配汉字串S与领域本体库中的词条进行匹配,如
匹配成功,则把汉字串S作为一个词切分出来,返回结果
Else S=S-1 //去掉待匹配汉字S串末端的最后一个汉字
End If
1.2 语义扩展
语义扩展主要是对查询的扩展,将与原查询相关的语词添加到原查询,得到比原查询更长的新查询,以提高信息检索查全率和查准率,弥补用户查询信息不足的缺陷。本文采用一种基本的语义查询扩展方法[ 6 ]来实现基于本体的移动学习资源语义检索模型语义扩展。该算法具体步骤如下:
①如果有需要扩展的查询词Word,则执行步骤②,否则执行④;②给初始查询设置权值;③计算与查询词Word相关的所有实体概念的语义权值,设置阈值λ限制Word的扩展范围,执行步骤①;④对λ范围内的语义信息一并提取作为扩展向量内容。其中设置阈值λ是为了防止语义漂移。
1.3 语义检索
语义检索的核心思想:首先,对用户检索的信息进行语义扩展后得到新检索词集合w′;其次,将w′送入检索组中进行数据语义检索;最后,对检索到的结果集进行排序,并将排序结果返回给用户。本文采用基于标签的LSI算法对结果集进行排序,具体算法过程如下所示:
(1) 初始化数组n=max;weight[ n ]=0;
(2) 利用like简单匹配算法求检索结果与每个用户关键字的相似度,并更新weight[ i ];
(3) 根据公式:
simtotal=Lw(k)n[]i=1m[]j=1simm(Wi,Kj)
求出每一个移动学习资源与W的总相似度,并记录;
(4)对结果按相似度排序,并返回给用户。其中simtotal为语义总相似度,Lw(k)为关键词K的频度,simm(Wi,Kj)为Wi和Kj的语义相似度。
2 本体库构建
2.1 相关概念
本体最初是哲学上的概念,哲学上定义的本体是“对世界上客观存在物的系统的描述”,是对“存在”的系统化的解释或说明。近年来,随着信息技术的不断发展,本体已成为人工智能、知识工程、信息检索与获取、知识表示等领域的热门研究课题。在人工智能领域,定义本体为“给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成这些词汇外延的规则的定义”。在信息系统和知识工程领域中,Gruber将本体定义为“是概念模型的明确的规则说明”;本体也被定义为“是一个为描述某个领域而按层次关系组织起来的一系列术语,这些术语可以作为一个知识库的骨架”。本体是用于描述或表达某一领域知识的一组概念或术语,其可用来组织知识库较高层次的知识抽象,也可用来描述特定领域的知识[ 7 ]。目前,计算机领域认为本体是共享概念模型的明确形式化规范说明[ 8 ]。
元数据对知识的组织管理与信息检索具有重要意义,是描述数据及其环境的数据[ 9 ]。元数据和本体都是随着计算机网络技术发展而出现的新方法,对信息检索和知识组织与管都具有重要意义。
七步法[ 10 ]是斯坦福大学医学院开发,主要用于领域本体构建。该方法的具体实现过程:第一步,确定知识本体的专业领域和范畴;第二步,考查复用现有知识本体的可能性;第三步,列出知识本体中的重要术语;第四步,定义类和类等级体系;第五步,定义类属性;第六步,定义属性约束;第七步,创建实例。
教育资源建设规范(CELTS)是为资源开发者提供一致的标准,为实现资源广泛共享和保证学习者或教育者高效利用资源、统一开发者行为习惯而提供的支持。《教育资源建设技术规范》[ 11 ]的基本结构包括网络课程、常见问题解答、资源目录索引、文献材料、案例、课件、试卷、试题、媒体素材等,并且包含LOM的必需元数据。
2.2 移动学习资源本体库构建方法
本文采用本体构建方法中的七步法并结合移动学习资源元数据,按照CELTS规范开发移动学习资源本体库。参照CELTS标准,采用本体构建方法中七步法开发元数据与移动学习资源本体库流程如图3所示。
图3 参照CELTS及七步法进行本体构建流程
2.3 移动学习资源本体构建
根据上节构建移动学习资源本体步骤:第一步,选取CELTSC规范的学习对象元数据作为构建本体的元数据方案;第二步,采用基于关联知识点属性来和知识点本体进行映射,以实现基于本体的移动学习资源管理和检索;第三步,从元数据中提取术语列表:软件类、视频类、文本类、课件类、媒体素材类、网络课程类、标题、创建者、语种、标识符、贡献者、姓名、联系方式、关联关系、资源位置等;第四步,定义类和类的层次;在第五步和第六步中,根据学习对象元数据中的数据元素对类的属性和属性约束同时进行定义;第七步,生成实例。
3 系统实现
系统服务器端使用Eclipse作为开发平台,构建基于C/S架构和MVC框架移动学习管理平台,本系统平台目前支持的移动终端有iPad、iPhone。系统框架结构如图4所示。基于本体的移动学习资源语义检索模型在该系统中作为服务器端移动学习资源管理的一部分,也是整个系统的核心部分,直接影响学习者使用该系统的效率及学习兴趣。在实际运用中,该系统为学习者带来了便利。
4 结语
本文通过分析移动教学平台系统中存在的移动学习资源信息检索效率低问题,结合现有本体相关技术和基于本体语义检索方面的研究成果,提出了一种基于本体的移动学习资源语义检索模型,并将该模型运用到移动教学平台系统中。通过大量学习者使用该平台,收集和总结学习者使用后的感想,结果表明该模型运用效果较为理想。该模型是解决移动教学系统中移动学习资源语义检索的一种有效方式,能帮助学习者准确搜索到符合需求的学习资源。
图4 基于本体的移动学习资源语义检索原型体系结构
参考文献参考文献:
[ 1 ] 郭绍青,黄建军,袁庆飞.国外移动学习应用发展综述[ J ].电化教育研究,2011(5):105109.
[ 2 ] 张田,李子云,汪睛睛.基于云计算的移动学习资源卡法初探[ J ].现代教育技术,2012(11):5961.
[ 3 ] JIAO YUYING,ZHANG LU.Model structure of ontologybased semantic retrieval[ J ].Information Research,2006(10).5457.
[ 4 ] 焦玉英,温有奎,陆伟.信息检索新论[ M ].武汉:武汉大学出版社,2008.
[ 5 ] 张德政,庄洪波.基于领域本体网络模型的知识获取技术[ J ].计算机工程,2007,33(7):190191.
[ 6 ] 付苓.基于本体的语义检索研究[ D ].曲阜:曲阜师范大学,2010.
[ 7 ] 岳静,张自力.本体表示语言研究综述[ J ].计算机科学,2006,33(2):158162.
[ 8 ] 史一民,李冠宇,刘宁.语义网服务中的本体综述[ J ].计算机工程与设计,2008,29(23):59765982.
[ 9 ] Baidu Metadata[ EB/OL ].http://baike.baidu.com/view/107838.htm,20100310.
[ 10 ] 尚新丽.国外本体构建方法比较分析[ J ].图书情报工作,2012(4):116119.
[ 11 ] 张功杰.基于本体的领域资源语义检索研究[ D ].广州:暨南大学,2007.
责任编辑(责任编辑:孙 娟)
- “互联网+”视角下高职管理会计实践教学模式研究
- 共享汽车保险的创新研究
- 大数据背景下高校数据式审计模式的创新与变革
- 微课+翻转课堂”模式下《财政学》教学设计
- 应用型人才培养视域下高职院校创新创业教育课程教学模式探索
- 资产证券化过程中信用增级方式研究
- 中国奢侈品行业与非物质文化遗产的互促发展之路
- 我国老年长期护理保险的发展现状及改善措施
- 移动互联网时代下社交电商发展模式及典型代表分析研究
- 国际原油价格对中国股市收益影响研究
- 德清地理信息小镇三圈融合产业生态链特色及未来发展建议
- 危机后的英国宏观审慎管理:框架变革与运作模式
- 银行理财产品投资分析及优化
- 云南省科技金融发展状况及政策建议
- “互联网+扶贫”背景下广西农村电商发展策略研究
- 商业银行资产证券化的双刃剑特性研究
- 监管沙盒的发展:思路创新、实践与不足
- 金融科技视域下金融控股公司的监管转型
- 基层人民银行内部控制面临的新问题及对策研究
- 县域绿色金融发展面临的问题及建议
- 国际绿色金融债券环境效益信息披露的主要经验及其对我国的启示
- 现阶段银行理财子公司面临的挑战及发展对策
- 新时期地方金融“本土化”问题研究
- 基于GIS的我国房地产泡沫空间传染性研究
- 普惠金融中大型商业银行的角色定位与路径选择
- outjested
- outjesting
- outjests
- outjet
- outjinx
- outjinxed
- outjinxes
- outjinxing
- outjourney
- outjourneyed
- outjourneying
- outjourneys
- outjuggle
- outjuggled
- outjuggles
- outjuggling
- outjumped
- outjumping
- out-jumps
- outjumps
- outjut
- outjuts
- outjutted
- outkick
- outkicked
- 丏
- 丐
- 丐乞
- 丐养
- 丐头
- 丐帮
- 丐户
- 丐效
- 丐施
- 丐沐
- 丐者
- 丐貣
- 丐贷
- 丐颉
- 丐食
- 丐饭
- 丑
- 丑上天了
- 丑不丑,一合手;亲不亲,当乡人
- 丑丑做夫人
- 丑丑妇
- 丑丫头爱搽粉
- 丑了面皮
- 丑事
- 丑事出大家