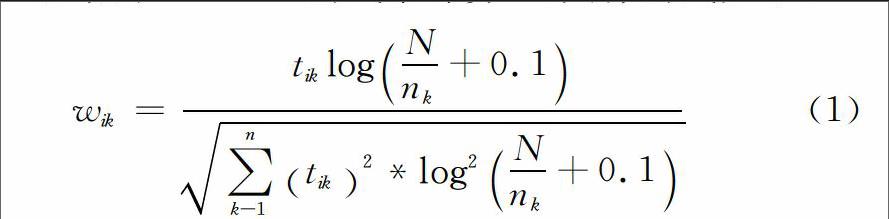
摘要摘要:基于主题搜索的主题网络爬虫,只抓取与用户主题相关的页面。在深入分析主题页面分布特征和主题相关性判别算法的基础上,提出了一个面向主题搜索的网络爬虫模型,它很好地克服了通用搜索引擎准确率偏低、信息内容相对陈旧、信息分布范围不均衡等不足。实验结果表明,尽管基于主题爬虫的搜索增加了内存使用率,但也成倍提升了搜索的准确性,提高了抓取效率以及抓取结果的利用率。
关键词关键词:搜索引擎;主题爬虫;信息采集
DOIDOI:10.11907/rjdk.151856
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2015)011006803
作者简介作者简介:万文兵(1983-),男,江苏仪征人,硕士,仪征技师学院电子信息系讲师,研究方向为计算机应用。
0引言
当前,互联网迅速发展,网络上多元化信息呈指数级增长,大数据时代已经到来,网络逐渐变成涵盖全球的非结构化数据库。鉴于网络的分布式特性,网络上的各种信息多是无规律的,很难对它进行结构化管理。如何高效提取和利用这些信息成为网络信息检索技术研究的重点。传统通用搜索引擎百度、Yahoo和好搜等,作为一个辅助检索工具成为互联网用户访问万维网的入口。然而,通用搜索引擎在为网络用户提供便利之时,也暴露出自身的多种不足,如:信息分布范围不均衡、所搜内容相对陈旧、搜索结果准确率较低等。为解决上述问题,主题搜索网络爬虫应运而生。
主题搜索实质上是面向主题的搜索,它是专为查询某一特定主题而设计的查询工具,它的搜索区域仅限于网络的某一子集,通过提供个性化信息搜索服务,把搜索应用限制在特定的主题或特定领域上,在具体搜索过程中无须遍历整个Web网络,只访问、下载与主题相关的信息,这既节约了网络资源,也提高了搜索质量。作为搜索引擎重
要组成部分的网络爬虫,实际上是一种页面内容自动采集程序,通过网络爬虫可实现从万维网上下载页面并构建搜索引擎数据库。与通用爬虫相比,主题网络爬虫能够更快、更多地采集预先定义好的与主题相关的页面。另外,主题搜索可针对不同主题分块采集,并对采集结果整合,进而提高整个搜索的覆盖率和页面利用率。
1主题网络爬虫
用户进行网络体验过程中,搜索引擎的作用非常明显,它的覆盖率、准确率和搜索速度(即搜索耗时)直接决定着用户的网络体验度,而搜索引擎基本上都是采用多线程并发搜索技术,定期搜索、抓取网页,并对其进行分析,以便获取关键词、统一资源定位符URL等。当前,搜索引擎外表呈现出多样化趋势,所提供的功能也有所不同,但是就其原理来说,构造基本都一样,即由网络爬虫、索引模块、信息检索以及用户接口4部分组成。在搜索引擎中网络爬虫的地位极其重要,它的功能好坏直接决定了搜索引擎数据容量的大小和优等页面以及死链接的个数。
主题网络爬虫作为主题搜索引擎中最核心的内容,主要用来抓取与用户特定需求有关的页面。主题爬虫依据用户预先给出的主题和特定的页面算法过滤与主题无关的链接,并将与主题相关的链接加入到URL队列中,并以此预测将要抓取的URL与其主题相关度,由此选择下一步将要抓取的网页统一资源定位符,直至系统停止重复遍历。所有被网络爬虫抓取的页面最终都会统一保存,同时,系统会在已存信息的基础上进行过滤、分析,以便建立索引。主题爬虫基本目标就是尽可能多地访问网络节点,下载与主题有关的页面并摒弃无关页面。与通用爬虫追求覆盖的全面性不同,主题爬虫更为关注抓取的效率,它仅对与特定主题内容相关的页面感兴趣。与传统爬虫相比,主题网络爬虫需要解决好4个方面的问题:①如何对主题进行描述或定义,即如何用格式化语言描述所要搜索的主题;②URL遍历次序如何确定,此种搜索一般依据相关性确定遍历次序;③网页数据如何分析与过滤;④主题网络爬虫的覆盖度如何提高。
2主题网络爬虫搜索策略算法
2.1系统模型
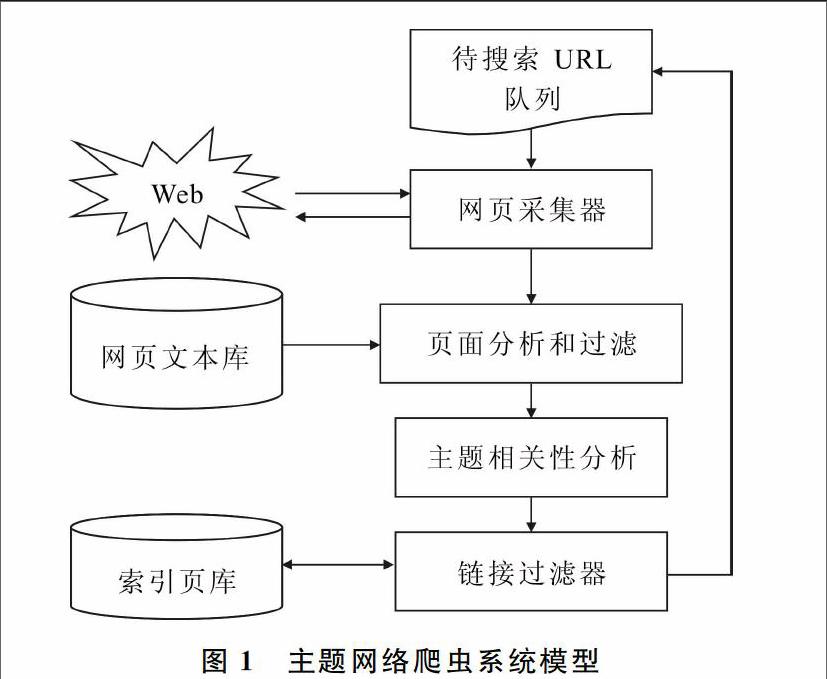
主题网络爬虫是通用爬虫的特例,它通过对通用网络爬虫进行特定功能扩充以实现面向主题的网页信息提取。在面向主题信息进行自动采集时,主题爬虫处理过程一般包含4部分:主题确立、网页采集、页面分析和过滤、主题相关性计算(链接过滤)。主题网络爬虫系统模型如图1所示。
主题爬虫从待搜索URL队列开始,利用网页采集模块对相应的网页进行访问并尝试下载。所下载的网页由解析模块按照HTML语法解析,并提取网页特征信息及超链接地址。对于上一步所提取的信息,还需依据一定的策略进行页面重复性判断,并消除重复页面。过滤模块根据提取的网页特征信息和主题概念关系,对页面主题相关度进行评价,筛选出符合要求的页面,并将这些页面保存至网页文本数据库。对于那些与主题要求相符合的URL链接,依据链接相关度算法过滤模块对其过滤,并经过URL消重后加入到待搜索URL队列中,供主题网络爬虫迭代爬行。处于系统核心的主题相关度分析模块,主要实现对抓取页面进行内容分析并提取相关内容,以便计算页面主题相关度具体数值,若计算结果低于网页阈值则抛弃该网页,否则保存;之后仍需进一步分析被保存页面的链接并预测相关度。
2.2主题确立
面向主题的 Web 信息提取的前提是确立主题。所谓主题,实际就是一个概念,它主要用来描述用户所要采集信息所具有的特征。主题概念的范围可大可小,它可以是一个概念、短语、段落,甚至是一篇文章。一个主题往往与若干样本页面有关,一般情况下,网络用户通过选定样本页面来确定所搜索的主题,并提取特征;之后再对样分析,自动提取特征词并根据其在Web页面中出现的次数计算权值;最后对所初选的各样本特征词进行归纳、总结,最终确定一组能够代表主题的特征词。特征词的权值采用Salton[5]总结的TF2IDF公式来计算[6],具体公式如下:
wik=tiklogNnk+0.1∑nk-1tik2*log2Nnk+0.1(1)
在上述表达式中,文档数据库中所包含的全部文档数用N表示,文档数据库中所存储的特征词Tk的个数用nk表示,特征词Tk在文档Di中出现的次数用tik表示。由式(1)所确定的主题实质上就是一个代表主题的基准文档向量,向量的维数就是特征词的个数,每个特征词的权值就是每一维分量的大小。
2.3页面分析与过滤
在众多Web页面中,主题网络爬虫所要面对的多是 HTML页面。因此,在对页面进行分析与过滤过程中,要从语法分析入手,提取出网页正文、链接及相关内容,并对页面主题相关性进行甄别,进而去伪存真,删除与主题无关页面,提高网络爬虫提取主题的准确率。由于待抓取的页面均基于HTML协议,因此,在抓取过程中要以HTML协议为基础进行语法分析。HTML语法分析过程包含Sgml(标记文法)层和Html标记层两个层次,其中,标记文法层主要用于将页面分解成不同的语法成分,Html标记层则主要用来处理正文和标记。另外,前正文的各种状态,包括字体、字号、字型等由标记层维护。通过对页面进行 HTML 语法分析,可采集正文、标题、链接等相关内容,进而判断页面主题相关性以及URL 主题相关性。
2.4网页主题相关度判断算法
对于传统爬虫而言,其在工作过程中,会对页面中所有链接进行处理,而不管这些链接是否符合用户需求,这与主题爬虫完全不同。在具体爬行过程中,主题爬虫更倾向于先判别待爬行页面,对于那些与主题相关度很低的页面,主题爬虫认为某些特征词可能只是偶尔出现,这些偶尔出现的特征词和待选主题并联不大,甚至二者之间不存在任何关联,其中的链接对最终搜索结果的出现也没有任何意义。因此,为了保证主题爬虫所采集的页面主题和指定主题相关,必须事先设定具体的阈值,在处理链接之前先依据阈值将相关度较低的页面删除,以免主题爬虫在接下来的处理中爬行该链接,进而提高采集网页的准确率。本文采用计算复杂度较小的向量空间模型算法对网页进行实时过滤。将一组确定的特征词看作是主题,由特征词的个数n确定向量空间的维数,每个特征词的权值Wi作为每一维分量的大小,则主题用向量表示为:
α=(α1,α2,……αn)i=1,2,3,…..n αi=Wi(2)
对爬虫所采集的页面进行分析,并经过中文分词处理构造一个特征词集合。统计特征词出现的频率,并求出频率之比,以出现频率最高的特征词作为基准,其频率用Xi=1表示。通过频率比,求出其它特征词的频率Xi,则该页面对应向量的每一维分量为XiWi,页面主题用向量表示为:
β=(X1W1,X2W2,….XnWn) i=1,2,…,n(3)
用两个向量夹角的余弦表示页面的主题相关度[7]:
Cos<α,β>=(α,β)/(|α| |β|)(4)
对于指定的网页相关度阈值r ,当满足cos <α,β>≥r,就可以认为该页面和主题是比较相关的,应该保存到网页库中;否则,即是不相关的,将此网页删除。至于r的具体取值,则需要根据经验和实际要求来确定。如果把r设小一点,则可获得较多的页面,否则,获得的页面则会少一些。
3评估实验
评估实验可以检验实际环境中上述算法的可靠性。依据上述算法,本文实验选择医疗信息作为主题进行评估测试。实验中,精选了15个医疗主题网站,25个与医疗无关的网站进行集中测试,共有超7000个页面接受了测试。为确保测试的普适性,评估实验采用开源的Java爬虫框架Heritrix作为测试的基础框架。
Heritrix框架易于扩展,利用这一网络爬虫框架,实验者可以通过扩展组件轻易组合抓取逻辑,并从网络上抓取所需的任何资源,本次实验通过扩展Extractor组件来实现页面解析和主题相关度计算。
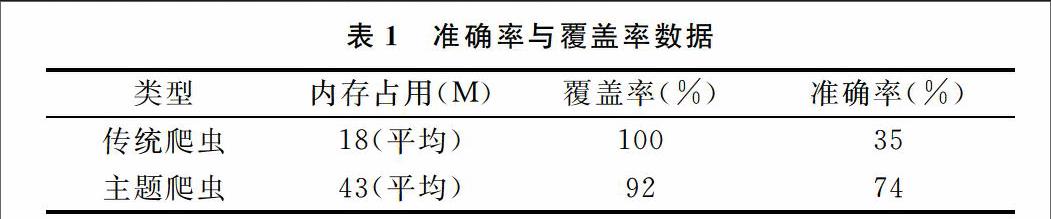
实验中,爬行深度设为4,线程为50,网页相关度阈值r设为0.1,实验结果如表1所示。
表1准确率与覆盖率数据
类型[]内存占用(M)[] 覆盖率(%)[] 准确率(%)
传统爬虫[] 18(平均)[] 100[] 35
主题爬虫[] 43(平均)[] 92[] 74
与传统爬虫相比,主题爬虫在内存占用、覆盖率和准确率3个方面都有不少变化。其中,内存使用成倍增加,这与网页内容解析任务重和向量空间模型复杂度高密切相关;覆盖率略微偏小,究其原因是在预测URL主题相关性的过程中,删除了部分与主题相关的URL;准确率则明显高于传统爬虫搜索,这主要归功于通过过滤主题与分析链接,删除了大量与主题不相关的页面。通过实验结果的对比分析,不难发现基于主题爬虫的搜索尽管增加了内存的使用率,但也成倍提升了搜索的准确性,提高了抓取效率以及抓取结果的准确率。
4结语
随着网络用户个性化信息服务需要的增长,面向主题爬虫的主题搜索将成为搜索引擎发展的主要趋势。在主题搜索引擎中,主题网络爬虫决定了这一搜索引擎能为用户提供资源的数量和“新鲜程度”。 本文研究充分说明,以主题爬虫为基础开发主题搜索引擎,能显著提升搜索的准确性,提高抓取效率以及抓取结果的利用率。
参考文献参考文献:
[1]张博,蔡皖东.面向主题的网络蜘蛛技术研究及系统实现[J].微电子学与计算机,2009(5):126129.
[2]汪涛,樊孝忠.主题爬虫的设计与实现[J].计算机应用,2004(6):4547.
[3]戚欣.基于本题的网络主题爬虫设计[J].武汉理工大学学报,2009(2):3538.
[4]谢惠,秦杰.基于用户查询关键词的网页去重方法研究[J ].现代图书情报技术,2008(7):4346.
[5]MURRAY B,MOORE A.Sizing the Internet[M].Cyveillance Inc,2009.
[6]LIU HY,MILIOS E,JANSSEN J.Probabilistic models for focused web crawling[C].Proceedings of the 6 th annual ACM international workshop on Web information and data management,2004.
[7]朱良峰.主题网络爬虫的研究与设计[D].南京:南京理工大学,2008.
责任编辑(责任编辑:杜能钢)
- 个税改革对国民幸福指数的影响
- 城乡居民大病保险运行状况及发展路径研究
- 工程造价管理在港口工程的应用研究
- 基于翻转课堂的《物流运输管理与实务》教学模式设计
- 基于安全可持续视角我国农产品冷链物流发展对策研究
- 建设基层堡垒激发党建力量全力融入生产经营
- 论“互联网+”党员志愿服务
- 新形势下建筑企业思想政治工作面临的新问题及应对策略
- 远程教育对我国现代职业教育质量发展的影响
- 重组背景下第三方检测机构人力资源改革对策
- 文化创意视野下非物质文化遗产的产业化发展研究
- 基于乡村振兴战略的现代生态农业转型路径探索
- 新形势下推进无锡城市建设高质量发展分析
- 互联网金融支持山东省生产型企业新旧动能转换的F2B模式探索
- 制造业发展与污染物排放的关联效应研究
- 公立医院加强疫情防控期间跟踪审计工作的分析
- 高职院校网上报销系统优化对策探析
- 我国个税改革的不足及完善建议
- 河南省居民消费价格指数预测
- 新中国成立以来国家审计及其职能的历史演进
- 堤防工程维修养护定额标准及其应用研究
- 全面预算背景下建筑企业财务管理对策研究
- “互联网+”背景下广东省税收征管研究
- 高职会计教学引入案例教学法的有效尝试
- 疫情期间“翻转课堂+网络直播”在教学中的应用
- surrenderers
- surrendering
- surrenders
- surrendry
- surreptitious
- surreptitiously
- surreptitiousness
- surreptitiousnesses
- surrogate
- surrogated
- surrogates
- surrogateship
- surrogateships
- surrogating
- surrogations
- surround
- surrounded
- surroundedly
- surrounder
- surrounding
- surrounding area
- surroundings
- surrounds
- surtax
- surveillance
- 忠贞的事迹
- 忠贞的人
- 忠贞的情意
- 忠贞的美德
- 忠贞的节操
- 忠贞者遭冤屈
- 忠贞而仁爱
- 忠贞而有节操
- 忠贞而爱民
- 忠贞诚信
- 忠贞诚恳
- 忠贤
- 忠贯日月
- 忠贯白日
- 忠贯金石
- 忠赤
- 忠邪
- 忠雅堂文集
- 忠靖侯
- 忠顺
- 忠顺亲王
- 忠驱义感
- 忠骨
- 忠魂
- 忠魂毅魄