
摘 要:针对垂直搜索引擎中精确抽取网页中特定字段的问题,对DIPRE算法进行了研究和改进。阐述了DIPRE算法在垂直搜索引擎中的重要作用,探讨了DIPRE算法在抽取复杂结构网页时的不足,并提出了改进,包括种子定位方式,将单模匹配扩展成多模匹配并引入定位索引,再根据已有技术对改进后的算法进行了实验验证。结果表明,改进后的算法在精度和效率上都符合预期。
关键词关键词:垂直搜索引擎;DIPRE算法;种子定位;单模匹配;多模匹配;定位索引
DOIDOI:10.11907/rjdk.161451
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2016)008-0030-03
0 引言
垂直搜索引擎是针对某一特定领域、人群或需求提供的信息检索服务,因此垂直搜索引擎的爬虫(Spider)在抽取数据时应该具有相当的选择性。DIPRE(Dual Iterative Pattern Relation Extraction)是Google创始人之一Sergey Brin针对抽取互联网上特定格式或类型的数据而提出的一种算法,由于垂直搜索引擎具有较强的专业性和针对性,因而DIPRE算法在垂直搜索领域里具有较为广阔的应用前景,但随着Internet上的信息量呈指数级增长,网页结构越来越多样化,利用DIPRE算法抽取数据无论是在广度还是在精度上都已遇到瓶颈[1],如何在发挥DIPRE算法优势的基础上弥补其不足成为一个值得研究的问题。
3 实验结果
实验以某大型网上书城的图书信息为检索对象,包括作者、出版社、出版时间、版次、页数共5个字段,此5个字段之间不含噪声,是测试的理想之选。使用的服务器配置如表2所示。
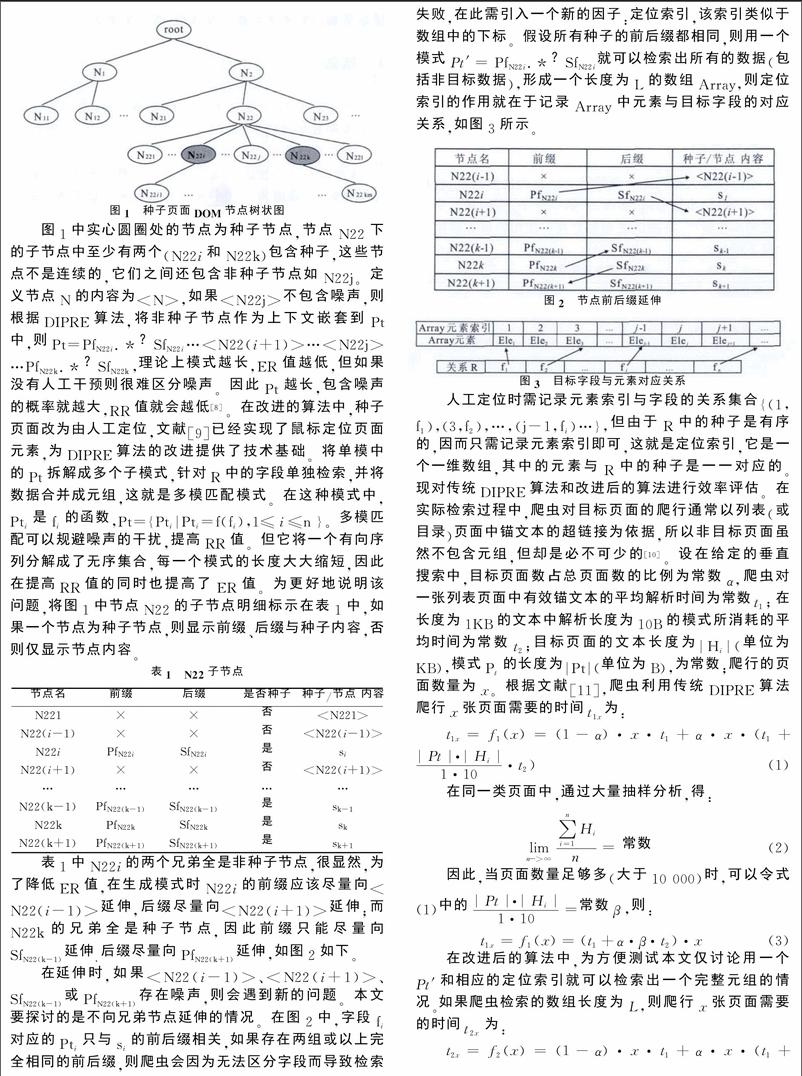
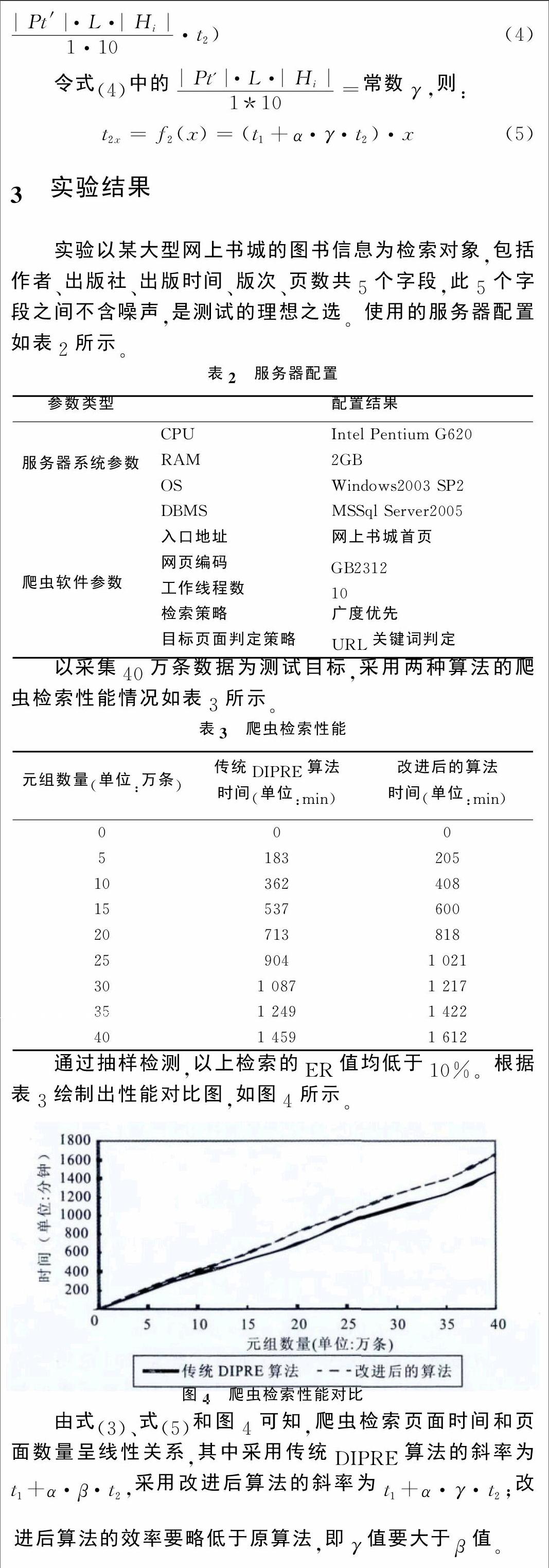
以采集40万条数据为测试目标,采用两种算法的爬虫检索性能情况如表3所示。
通过抽样检测,以上检索的ER值均低于10%。根据表3绘制出性能对比图,如图4所示。
由式(3)、式(5)和图4可知,爬虫检索页面时间和页面数量呈线性关系,其中采用传统DIPRE算法的斜率为t1+α·β·t2,采用改进后算法的斜率为t1+α·γ·t2;改进后算法的效率要略低于原算法,即γ值要大于β值。
4 结语
本文对DIPRE算法进行了扩展和改进,将原算法中的单模模式扩展成多模模式,同时引入定位索引,使得改进后的算法具有很强的实用性和可扩展性。实验结果表明,改进后算法的性能曲线斜率要比原算法的大,效率比原算法低,这是因为||过小导致无法有效过滤数据,使得L远大于R中字段数量,爬虫检索了很多无效值,降低了检索效率。在后续改进中,重点在于降低式(5)中的值,即L的值,这就必须使||达到一个合理的范围,图2中阐述的前后綴延伸方法是个不错的解决方案,如何控制延伸的程度则是后续研究的主要内容。
参考文献:
[1]OREN KURLAND,LILLIAN LEE.PageRank without hyperlinks[J].ACM Transactions on Information Systems (TOIS),2010,28(4):1-38.
[2]LIU GUI-MEI.An adaptive improvement on PageRank algorithm[J].Applied Mathematics:A Journal of Chinese Universities(Series B),2013,28(1):17-26.
[3]GHOLAM R AMIN,ALI EMROUZNEJAD.Optimizing search engines results using linear programming[J].Expert Systems With Applications,2011,38(9):11534-11537.
[4]LIN LI,GUANDONG XU,YANCHUN ZHANG,et al.Random walk based rank aggregation to improving web search[J].Knowledge-Based Systems,2011,24(7):943-951.
[5]E GARCIA,F PEDROCHE,M ROMANCE.On the localization of the personalized PageRank of complex networks[J]. Linear Algebra and Its Applications,2013,439(3):640-652.
[6]SHAYAN A,TABRIZI,AZADEH SHAKERY,et al.Personalized pagerank clustering:a graph clustering algorithm based on random walks[J].Physica A:Statistical Mechanics and its Applications,2013,12(5):15-24.
[7]ALEXGOH KWANG LENG,P RAVI KUMAR,ASHUTOSHKUMAR SINGH,et al.Link-Based spam algorithms in adversarial information retrieval[J].Cybernetics and Systems,2012,43(6):459-475.
[8]LI LIAN,ZHU AI HONG,SU TAO.An improved text similarity calculation algorithm based on vsm[J].Advanced Materials Research,2011,1250(225):1105-1108.
[9]LI MIN,ZHAO JUN.Research and design of the crawler system in a vertical search engine[C].Guilin:In Proceedings of the 2010 International Conference on Intelligent Computing and Integrated Systems,2010:790-792.
[10]EVANTHIA E TRIPOLITI,DIMITRIOS I FOTIADIS,GEORGE MANIS.Modifications of the construction and voting mechanisms of the random forests algorithm[J].Data & Knowledge Engineering,2013,87(7):112-118.
[11]柳厅文,孙永,卜东波,等.正则表达式分组的1/(1-1/k)-近似算法[J].软件学报,2012,23(9):2261-2272.
(责任编辑:孙 娟)
- 蒙古族传统家具三维模型数据库的构建
- 探析计算机数据库安全问题与对策
- 计算机软件数据库设计原则探讨
- 基于SOA构架的音频资料库系统
- 二维码技术在高校多媒体教学中的应用
- FLASH多媒体课件的脚本应用探讨
- 基于Authorware开发程序的全屏显示问题研究
- 基于视频的交通监控技术研究
- 基于iOS的订单配送路径规划App的设计实现
- 基于Zigbee的智能窗户控制系统
- 基于颜色定位和边缘检测的车牌定位方法
- 应急训练智能平台的研究
- 一种带红外遥控功能的智能插座的设计与实现
- 基于信息处理的乌兹别克语语音变化现象自动还原技术研究
- 基于人工神经网络的电力变压器故障诊断
- ERP系统中销售开票业务模块的设计与实现
- 基于Wi—Fi的手持设备广播平台的设计
- VisualBasic教学和实践中若干问题的探讨
- 论文申报系统中规则生成/解析引擎的设计与实现
- 试论开源云计算openstack在高校计算机机房中的应用
- 油田施工方案网上审批系统的开发与应用
- 智能互动展示技术在传统手工艺展示中的应用研究
- VMware在高校计算机机房中的应用及实现
- 基于MATLAB/Simulink的电力故障检测系统设计
- 可逆随机数生成器的设计
- senior high schools
- seniorities
- seniority
- seniors
- senior²
- senior¹
- sensation
- sensational
- sensationalise
- sensationalised
- sensationalises
- sensationalising
- sensationalism
- sensationalisms
- sensationalist
- sensationalists
- sensationalization
- sensationalize
- sensationalized
- sensationalizes
- sensationalizing
- sensationally
- sensationless
- sensations
- sense
- 果报
- 果报不爽
- 果掷
- 果掷河阳
- 果掷潘郎
- 果掷行车
- 果敢
- 果敢决断
- 果敢坚决
- 果敢坚毅
- 果敢强劲
- 果敢有魄力
- 果敢正直
- 果敢而有魄力
- 果敢英勇
- 果断
- 果断仗义
- 果断做出决定
- 果断刚毅
- 果断勇猛
- 果断敏锐
- 果断明察
- 果断的处理方法
- 果断而敢于行动
- 果断而有才能