

摘? 要: 为了更加灵活的应用分类算法,针对数据挖掘中分类算法的可扩展性展开分析,首先介绍决策树分类算法、K最近邻分类算法这2种常见分类算法,并且分析分类算法的可扩展性,明确分类算法的作用以及扩展分类算法的3点原因,最后从应用快速算法、及时分割数据、表达与维护数据关系这3个方面着手,阐述可扩展性的实现方法。数据挖掘中分类算法的可扩展性能够充分发挥分类算法优势,提高分类结果准确性,及时完成数据挖掘。因此本文主要研究了数据挖掘中分类算法的可扩展性,希望能够提供一定的参考价值。
关键词: 数据挖掘;分类算法;可扩展性;决策树分类算法
中图分类号: TP312? ? 文献标识码: A? ? DOI:10.3969/j.issn.1003-6970.2019.10.035
本文著录格式:曹素娥. 数据挖掘中分类算法的可扩展性探讨[J]. 软件,2019,40(10):155158
Exploration on Expansibility of Classification
Algorithms in Data Mining
CAO Su-e
(school of Computer and Network Engineering, Shanxi Datong University, Shanxi Datong, 037009)
【Abstract】: In order to apply classification algorithm more flexibly, the scalability of classification algorithm in data mining is analyzed. Firstly, two common classification algorithms, decision tree classification algorithm and K nearest neighbor classification algorithm, are introduced, and the scalability of classification algorithm is analyzed. The function of classification algorithm and three reasons of extended classification algorithm are clarified. Finally, from the application of fast algorithms, timely segmentation of data, expression and maintenance of data relations, expatiate on scalability implementation methods. The scalability of classification algorithm in data mining can give full play to the advantages of classification algorithm, improve the accuracy of classification results, and complete data mining in time. Therefore, this paper mainly studies the scalability of classification algorithm in data mining, hoping to provide some reference value.
【Key words】: Data mining; Classification algorithm; Scalability; Decision tree classification algorithms
0? 引言
数据挖掘中分类算法[1]是最为常见的一项技术,按照数据集特征构建分类器,以此为未知类别样本赋予类别。通常分类器构建主要有训练、测试这两个环节,训练环节需要对训练数据集特征进行分析,使所有类别都有对应的数据集模型,进入到测试阶段之后,通过类别描述、模型准确划分测试类别,从而保证分类结果精准性。分类算法应用的过程中需要了解其中隐藏的规则,这就需要发挥分类算法可扩展性特点,下面围绕这一点展开分析。
1? 数据挖掘中的几种分类算法
1.1? 决策树分类算法
在数据挖掘中,决策树分类算法[2]属于非常经典的分类算法之一(流程图见图1),按照从顶至下递归的顺序构建决策树模型。所构建的决策树所有结点均通过信息增益度量明确测试属性,以此进行分类规则的提取。
1.2? K最近邻分类算法
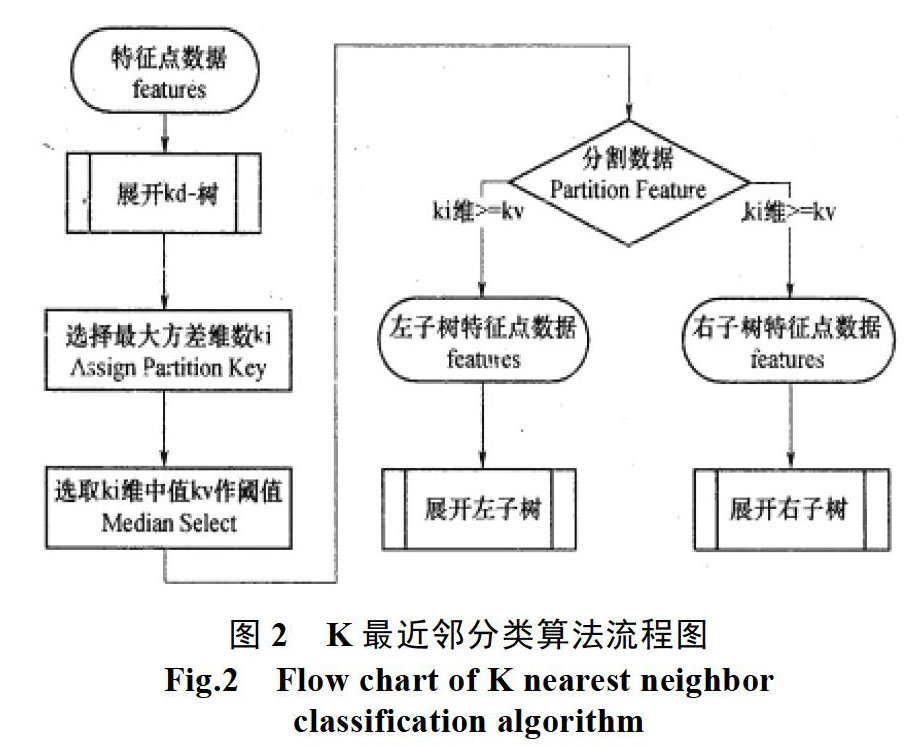
实际应用中K最近邻分类算法的思路非常简单(流程图与数据结构见图2表1),先将样本所处特征空间内K个最相似样本假设为相同类别,且该样本也属于这一类别。按照相邻最近一个或多个样本类别判断未分类样本类别。分析可知该分类算法是以极限定理为基础,但其实类别决策使只是和少量有限样本有密切关系。所以,通过K最近邻分类算法能够保证样本选择平衡性。同时,因为该算法并非按照类域明确样本类别,主要是通过邻近少量样本为依据进行确定,所以样本类域重合、相交较多的未分类样本集最适合应用该算法。
2? 分类算法可扩展性
针对分类算法的可扩展性[3],分析可以确定以下几点原因:第一,提升分类精准性。拓展分类算法最为核心的原因,是能够切实提高分类精准性以及结果有效性;第二,满足算法对于空间提出的严格要求。很多决策树算法对于訓练样本驻留内存有一定的限制,因为训练样本在主存、高速缓存两者之间重复进出,降低算法效率低下。所以,拓展分类算法可以有效提高算法效率,满足空间方面的要求;第三,掌握小事件情况。因为数据挖掘中存在一些噪音数据,以免小事件错认成假事件、过适应问题,所以数据集内部样本要足量,才能够更加准确的发现小事件。为了更高效的拓展分类算法,需要结合具体要求选择有效的方法,保证分类算法 可扩展性的实现。
3? 数据挖掘中分类算法可扩展性的实现
3.1? 应用快速算法
3.1.1? 构建限制模型空间
通过线性回归分类、简单神经元、单层决策树这三种方法可以构建限制模型空间,因为模型空间比较小,使用难度不高的学习算法可以快速学习。
3.1.2? 应用启发式搜索
如果只是对非连续性数据进行考虑,那么决策树算法时间复杂度受样本数线性影响发生变化。然而连续性数据需要结合情况重复排序,所以最后所表现的复杂度明显提升。使用启发式算法建构决策树[4],期间可能缺乏可理解性,一般会使用理解起来比较容易的规则代表相应的知识,同时为了能够保证规则精准性,经常选择减少错误剪枝法。但是该方法可扩展性能较差,无法保证计算复杂度。鉴于此,在研究过程中分别了解了RIPPER算法和? 不分而治算法,前者可以有效提升准确性,但是却 不能保证计算复杂度;后者则极大的提升了分类准确性。
针对分而治之方法的应用[5],要先以最大信息熵属性变量为原则划分数据集区域,随后将属性分枝循环处理。因为经过分区的子节点只是将初始数据集中其中一个子集覆盖,所以原始训练集内有价值的信息资源可能会遗失,影响最终分类结果。例如表2所示训练集[6],运行C4.5就可以获得图3所示的决策树。但是C4.5忽略了规则r1:“IF
3.1.3? 分类算法优化与拓展
利用数据结构可以有效优化、拓展分类算法扩展[7]。那么在决策树分类的过程中,针对其所具有的连续属性,需要在所有内部结点中提炼出最佳分裂标准,期间均要以属性取值为依据排列训练集顺序,该环节会浪费大量时间。所以,建议应用SLIQ算法,通过预排序技术,消除决策树所有结点在数据集排序环节的相关需求。SLIQ算法在应用中应用广度优先方法建构决策树,为决策树内叶子结点明确最优分裂标准,同时也可以完成驻留磁盘数据集的分类操作。在SLIQ给予数据结构以新的定义,为树的构造提供方便。因为SLIQ主要是应用驻留磁盘属性表、单个驻留主存类表,类表大小受训练集中元组数目成比例影响产生变化,所以类表无法在主存存放,便会降低SLIQ算法性能。
3.2? 及时分割数据
数据分割[8]主要可以避免算法在数据集中运行,从而将大数据集中数据挖掘问题加以解决。选择样本程序时需要挑选一或多个子集,将其与学习算法一一对应,以此便可以形成分类法。获得的分类法可以利用组合程序的方式形成一个分类法。若将数据集视为一个表格,可以采用实例抽样、特征抽样的方式达到分类抽样的目的。为了有效处理多个子集,建议使用串行处理。并行处理这两种方式。
其中实例抽样比较常用随机抽样、策略抽样这两种方法,策略抽样在类分布均匀性较差的训练集内比较常用。特征抽样的应用,一方面是因为属性集增长之后,过适应会有更大的几率出现,这时需要选择属性较高的子集保证算法准确性。另一方面,属性数量在算法执行时间复杂度中属于核心要素,所体现的复杂度并非受属性数线性增长影响。那么在算法分割中应用特征选择这一方法,需要在已经掌握知识的基础上去除不需要属性,随后选择域,为该域赋予相关性,在众多属性中选择一个子集,计算某个属性与目标规则二者之间具备的相关性,构建属性子集。鉴于此,可以确定尽管数据分割能够在大数据集分类中应用,但分类精准性不高。
3.3? 表达与维护数据关系
3.3.1? 融合分类算法与数据库技术
数据挖掘算法在计算环节一般会消耗大量时间,计算任务的完成还需要有充足的磁盘I/O操作作为支持。通过数据库技术[8~9]可以将复杂计算、I/O操作中存在的问题解决,使用该种方法也可以节省时间,通过编程语言完成基本搜索。与此同时,为了更好的表达数据之间的关系,需要将分类算法、数据库技术充分结合,这也是目前研究的要点。通过分析与实践总结三种可行的结合方法,即几乎不使用数据库、稀疏结合、紧密结合。目前数据挖掘系统中以几乎不使用数据库架构最为常见,通过自己研发的存储管理模式,可以按照特殊挖掘任务对存储管理进行优化,但是其缺点在于无法实现数据库成熟技术的充分应用。
数据库管理系统有非常强的存储管理性能,同时对于数据挖掘操作也给予帮助。例如一些数据挖掘系统所应用的恢复机制、日志机制、并发控制能力,支持用户按照数据备份来实现数据挖掘查询。其他数据挖掘系统中也运用了数据库技术,但其作用只是体现在数据的存储、恢复上,主编程语言内部嵌入SQL查询,可以在系统中输入SQL选择语句,调取相应的记录集,如此一来结果记录集的拷贝与应用浪费大量时间,直接降低了运行效率。
与数据库相结合的架构主要是应用数据库技术,数据挖掘中的一些计算由数据库系统负责,以免应用程序数据传输环节浪费时间,使算法执行效率得到提升。一些数据挖掘系统开始应用该种方法,同时也可以使用UDF(用户自定义函数)进行决策树分类,但是因为UDF并非数据库系统内部函数,其所具备的功能需要通过用户编程的方式体现,数据库查询、处理这两项功能没有得到体现,这便对其性能的提升帶来限制。鉴于此,以标准数据库技术为基础研发了KDS算法,利用复杂查询执行、UDF调用达到预期目的。同时也可以也使用数据库技术获得带有可扩展功能的分类算法,即GAC-RDB,发挥关系数据库管理系统优势,利用聚集计算这一项功能完成分类分布统计等一系列操作,最大程度的提升算法运行效率。
3.3.2? 采用分布式模式进行数据挖掘
分布式数据挖掘在实践过程中主要有三个流程,第一,将未挖掘数据划分为多个子集,子集数量以可用处理器数量为准,将所有数据子集传输至处理器中;第二,所有处理器在运行期间形成的数据需要应用挖掘算法传递到局部数据子集,这时处理器运行相应数据挖掘算法;第三,所有数据挖掘算法将局部知识、全局知识、一致知识进行整合。这种分布式数据挖掘与抽样方法类似,分布式处理主要是通过预测精度的方式保证速度,在实践中有极高的使用价值。
4? 结束语
综上所述,分类算法作为非常重要的数据挖掘技术,需要按照算法效率、计算准确性等做出综合考虑,充分发挥算法可扩展性,获得准确的分类结果,同时优化算法性能。目前关于数据挖掘中分类算法的研究处于发展阶段,其中还存在一些问题亟待解决,尤其是分类算法可扩展性,相关人员需要从这一方面入手,展开深入探究,明确可扩展性对于分類算法与数据挖掘的重要作用,使用有效的方法完成分类算法的扩展,获得准确的数据分类结果。
参考文献
[1]Stanfill Bryan, Reehl Sarah, Bramer Lisa, Nakayasu Ernesto S, Rich Stephen S, Metz Thomas O, Rewers Marian, Webb- Robertson Bobbie-Jo. Extending Classification Algorithms to Case-Control Studies.[J]. Biomedical engineering and com pu ta tional biology, 2019, 10.
[2]张玉梅. 基于Web数据挖掘的个性化推荐系统设计[J]. 信息技术与信息化, 2019(6): 12-15.
[3]陈志忠. 数据挖掘算法在云平台应用中的优化与实施[J]. 电子元器件与信息技术, 2019(3): 8-11.
[4]赵小强, 刘梦依. 基于不平衡数据集的主动学习分类算法[J]. 控制工程, 2019, 26(2): 314-319.
[5]Chao Chuan Jia, Chuan Jiang Wang, Ting Yang, Bing Hui Fan, Fu Gui He. A 3D Point Cloud Filtering Algorithm based on Surface Variation Factor Classification[J]. Procedia Com puter Science, 2019, 154.
[6]钟彩. 边缘检测算法在图像预处理中的应用[J]. 软件, 2013, 34(1): 158-159.
[7]王雨萌, 武小军, 罗雅晨. 基于数据挖掘和RandomForest算法的助学金分类研究[J]. 中国市场, 2019(03): 50-52.
[8]冯杰, 屈志毅, 李志辉. 基于分类稀疏表示的人脸表情识别[J]. 软件, 2013, 34(11): 59-61.
- 论国际互联网对国际私法的影响
- 论养老院联网化连锁平台建设
- 中国临终关怀事业存在的问题与政府政策探析
- 代际视阈下农民工消费文化探微
- 高校图书馆网络信息资源建设研究
- 网络文学版权保护探究
- 新形势下新闻采访的技巧探析
- 浅议《解放日报》的改版
- 基于新媒体视角下马克思主义大众化传播机制建设探究
- 美国西点军校学员连队化管理模式的特点及启示
- 论高校图书馆馆员的社会地位与提升对策
- 网络环境下高校图书馆管理创新研究
- 浅析高校共青团“第二课堂成绩单”制度建设
- 浅议高校辅导员如何开展学生管理工作
- 浅析新媒体时代高校辅导员与大学生的有效沟通机制
- 大学生共享单车消费行为的顾客忠诚度研究
- 农村老年人医疗需求与新农合保障调查研究
- 社会福利治理视角下政策工具的运用研究
- 共享居家养老服务模式的发展探究
- 从高中入学率看农村义务教育的质量问题
- 减重视域下大学生体重变化问题应对路径探析
- 《中药药理学》网络课程建设和应用初探
- 民族院校突发事件应急管理的SWOT分析与实现
- 内地高校新疆籍少数民族大学生文化认同与人际关系研究
- 试论校史教育工作的实效性及发展方向
- manda
- mandarin
- mandarinic
- mandarinism
- mandarinisms
- mandarin's
- mandarins
- mandarinship
- mandate
- mandates
- mandating
- mandator
- mandatories
- mandatorily
- mandatory
- mandatory convertible bond
- mandatoryconvertiblebond
- mandible
- mandibles
- mandibular
- mane
- maneless
- manes
- maneuver
- maneuverabilities
- 受穷罪
- 受窘
- 受窘,难为情
- 受窝囊气
- 受窭
- 受笞刑
- 受笼
- 受管辖
- 受粉
- 受精
- 受精二周的胎儿
- 受精卵
- 受累
- 受累不讨好
- 受纳
- 受纳诉状之竹筒
- 受终
- 受绐
- 受罚
- 受罪
- 受罪罚
- 受罪谴
- 受羁绊
- 受美好自然风光的熏陶
- 受老天保佑