张辉 韩发 鹿方凯

摘 要:针对空间局部密度变化和需要用户输入参数的空间聚类问题,提出自适应局部密度变化的空间聚类方法。借助 Delaunay三角网构建空间邻近关系的优势,首先给出点密度的度量标准,即与点直接相连的边长度均值。将核点定义为一阶邻域中至少存在一个密度相似点,在此基础上应用广度优先搜索算法对一阶邻域进行搜索,对密度相似的核点进行扩展,将密度远小于核点密度的点作为簇的边界点。在判断点密度是否相似时,根据已加入核点的平均密度和密度变化率自动调整参数值。通过模拟实验,对比DBSCAN算法实验结果,对提出的算法进行验证。实验结果表明,该算法不仅能够自动适应局部密度变化和识别出离散点,而且能适应不同形态的空间簇。
关键词:空间聚类;自适应;局部密度不同;点密度;Delaunay三角网
DOI:10. 11907/rjdk. 182134
中图分类号:TP312文献标识码:A文章编号:1672-7800(2019)001-0095-04
Abstract:In order to solve the problems of spatial clustering with local density changes and requiring parameters given by the user, this paper proposes a spatial clustering method with self-adaptive local density variation. In this paper, the Delaunay triangulation is used to construct the spatial proximity relationship. The metric of the point density and the mean value of the first-order neighbors side-length are firstly given. The core point is defined as that there is at least one point with similar density in the first-order neighborhood. On this basis, the breadth-first search algorithm is used to perform search on the first-order neighborhood, and the core points with similar density are extended, and points far less than the density of the core is considered as the boundary points of the cluster. When judging whether the density of points is similar, the parameter values are automatically adjusted according to the average density and the rate of the density change of the core points that have been added. Through simulation experiments and comparison of experimental results of DBSCAN algorithm, the proposed algorithm is verified. Experimental results show that the algorithm can automatically adapt to local density changes and different forms of spatial clusters and identify discrete points.
0 引言
随着数据获取技术快速发展,空间数据量变得庞大,并且成为探索空间领域知识的重要依据,因此迫切需要利用空间数据挖掘技术发现空间数据中隐含的有用知识。空间聚类作为空间数据挖掘的一个重要分支,是将数据对象进行分组,使得每一个组内对象之间相似性最小,且组间对象之间的相似性最大[1]。
基于划分的聚类方法和基于層次的聚类方法,是较早提出的较为有效的基本聚类方法,旨在发现球状簇,却很难发现任意形状的簇[2-4]。为了发现任意形状的簇,基于密度的聚类方法能够过滤低密度区域,发现稠密样本点组成的类簇,并能识别噪声数据[5-8];基于格网的聚类方法[9],在某种程度上类似于基于密度的方法,采用基于格网的数据结构对数据集进行聚类。但基于密度和基于格网的聚类方法不能较好处理局部密度变化的簇,且需要人为设置参数。基于图论的聚类方法是将所有实体构建的图分割成一系列子图,每个子图视为一个空间簇,对局部密度变化的簇具有很好的聚类效果,但仍没有解决基于密度方法中需要人为设置参数的问题[10-11]。混合聚类方法一般会对几种聚类算法的优点进行组合[12]。综上,算法大都具有不适用于局部密度变化的数据集,或需要人为设置参数的缺点。基于密度的聚类方法在这两方面最为突出,算法也大都以基于密度的聚类方法为基础进行改进。在基于密度的聚类方法中,DBSCAN(Density Based Spatial Clustering of Applications with Noise)算法作为应用最广泛的密度聚类算法,具有发现任意簇、自动排除噪声点、无需指定类别数的优点[13];但是当数据集密度差异较大时,由于DBSCAN方法设定了全局密度参数,无法正确识别局部密度不同的空间数据簇,算法的两个参数也不易设置[5]。OPTICS(Ordering Points to Identify the Clustering Structure)[6]算法通过对基于密度的聚类排序,即表示出数据的密度结构,解决了空间数据局部密度分布不均问题,但也受DBSCAN算法自身局限的影响,不能对周围稀疏样本点区域有较好处理效果,且计算量大。SNN(Shared Nearest Neighbor)[7]和VDBSCAN(Varied Density Based Spatial Clustering of Application with Noise)[8]算法也是针对变化密度进行改进的,虽然可以发现不同密度的簇,但在某些情况下无法产生正确结果,选择合适的参数也十分困难。
为了解决空间局部密度不同和参数不易选择的问题,本文对DBSCAN算法进行改进,提出一种适应局部密度变化的空间聚类方法——SADBSCAN(Self-adaptive Density Based? Spatial Clustering of Applications with Noise)。该方法利用Delaunay三角网构建空间邻近关系的优势,对直接相连且密度相等的数据点进行扩展聚类[14-15];在自适应方面,算法进行核点扩展时,首先由用户给出一个阈值,然后根据数据点的分布情况,自动调整参数,得到一个更合适的值。
1 SADBSCAN算法
在介绍算法之前,先引出算法的一些相关概念。
D={[p1],…,[pn]}表示一个包含n个实体的数据集,G表示D中实体构成的Delaunay剖分图。每个空间实体[pi]表示Delaunay剖分后三角网中的一个顶点,进而可以给出如下定义:
定义1 K阶邻域。给定一个图G,[pi]为G的一个顶点,其K阶邻域为所有到点[pi]的路径小于或等于K的点集,记为[NK(pi)]。
定义2 点密度。给定一个图G,[pi]为G的一个顶点,[pi]的密度用统计量为其一阶邻域内各点与[pi]边长均值的倒数构造,记为[densitypi],表达式如式(1)。
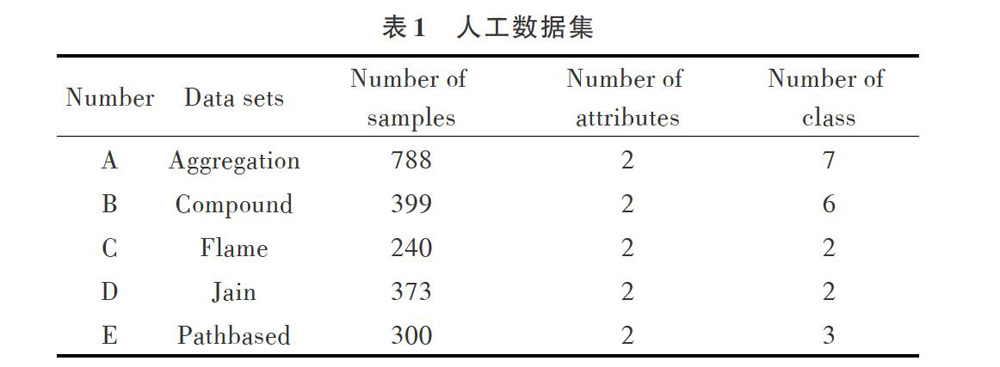
式(2)为一阶邻域内各点与[pi]边长的均值,[dist(pi,pj)]表示点[pi]、[pj]的欧氏距离。如图1所示,对数据集Delaunay三角形剖分后可以发现,左边的簇比较密集,与点直接相连的边长度均值[meanpi]较小,则[densitypi]就较大;右边的簇比较稀疏,与点直接相连的边长度均值[meanpi]较大,则[densitypi]就较小。因此,本文给出的点密度度量标准能够准确度量各类簇的局部密度,最大程度地反映类间差异性。
聚类过程与DBSCAN算法类似,也是从某个核点开始聚类,遍历其一阶邻域,只要存在核点就继续聚类,并将远小于核点密度且两点距离小于α的点判定为边界点,直至再无核点可扩展,则一个簇聚类完成。然后另选一个未访问的新核点重复上述过程,直到所有点聚类完成。上述聚类过程也可以表述为将所有密度直达、密度相连和密度可达的点聚为一类。
2 SADBSCAN算法实现
2.1 实现细节
为了更好地描述和实现算法,先给出数据点的数据结构:
算法还需要设置一个变量CID和一个队列corequeue,用来记录当前使用的ClusterID编号(初始值为0)和存储当前聚类簇中发现的核点。算法步骤如下:
(1)对数据集进行Delaunay剖分,得到三角网集合DT(D)。
(2)遍历DT(D)寻找每个点的一阶邻域[pi]·N[],根据一阶邻域计算点密度[pi]。density。
(3)任取一点[pi],遍历[pi]·N[],若存在与[pi]。density相似的点,则判断[pi]为核点,令ClusterID+1,并将其赋给[pi]。ClusterID, 令[pi]· isCore=1。
(4)遍历[pi]·N[]中的点[pj],若[Dvp(pi,pj)<α],则[pj]为核点,存入corequeue,令[pj]·isCore=1;若[densitypi>>][densitypj]且[dist(pi,pj)<α],则[pj]为边界点,令[pi]·ClusterID=CID,[pj]· isCore=0。
(5)若corequeue不为空,则取出头元素,令其为[pi]·ClusterID=CID,重复步骤(4)、步骤(5)。
(6)若空间数据点全部被访问过,则算法结束,否则转步骤(3)。
2.2 自适应机制
密度波动在一定范围内,即高斯分布的方差在[0,α)区间内,密度波动范围的上界限为[α]。首先用户设定一个上限阈值[α],然后在算法运行过程中根据每次弹出的核点密度偏离中心的程度动态更新[α]值。具体分为以下两个过程:由式(6)计算从corequeue中弹出的核点偏离中心的程度d;由式(7)计算新值[α]。
式(6)中,[cdensityp]表示已被扩展核点(包括核点p)的密度均值。由式(7)对[α]进行自适应,由于偏离中心程度的上限为[α],根据高斯分布特征,在中心值周围有很大一部分数据集,若缩减过快,[α]就会由于该值影响减小到一个较小值,从而不能发现那些d较大并且满足密度相似的点。因此当[d <α2]时,[α]需要缩减;当[d≥α2]时,[α]需要增大。增加比例大于缩减比例,缩减比例值是经过大量实验之后确定的一个相对较优值。
2.3 算法分析
从上述聚类过程分析可知,对于给定含有n个点的数据集,构建Delaunay三角网的时间复杂度为O(nlogn)[16];找到一个点的邻域需扫描一遍所有剖分后的三角形,所需时间为O(n),而n个点的时间约为O(n2);核队列上的循环和处理当前核点的鄰域与数据点数n无关,时间复杂度分别为O(1),所以 SADBSCAN 的时间复杂度为O(n2)。由此可知,本文算法SADBSCAN的时间复杂度与算法DBSCAN相同。
3 SADBSCAN实验
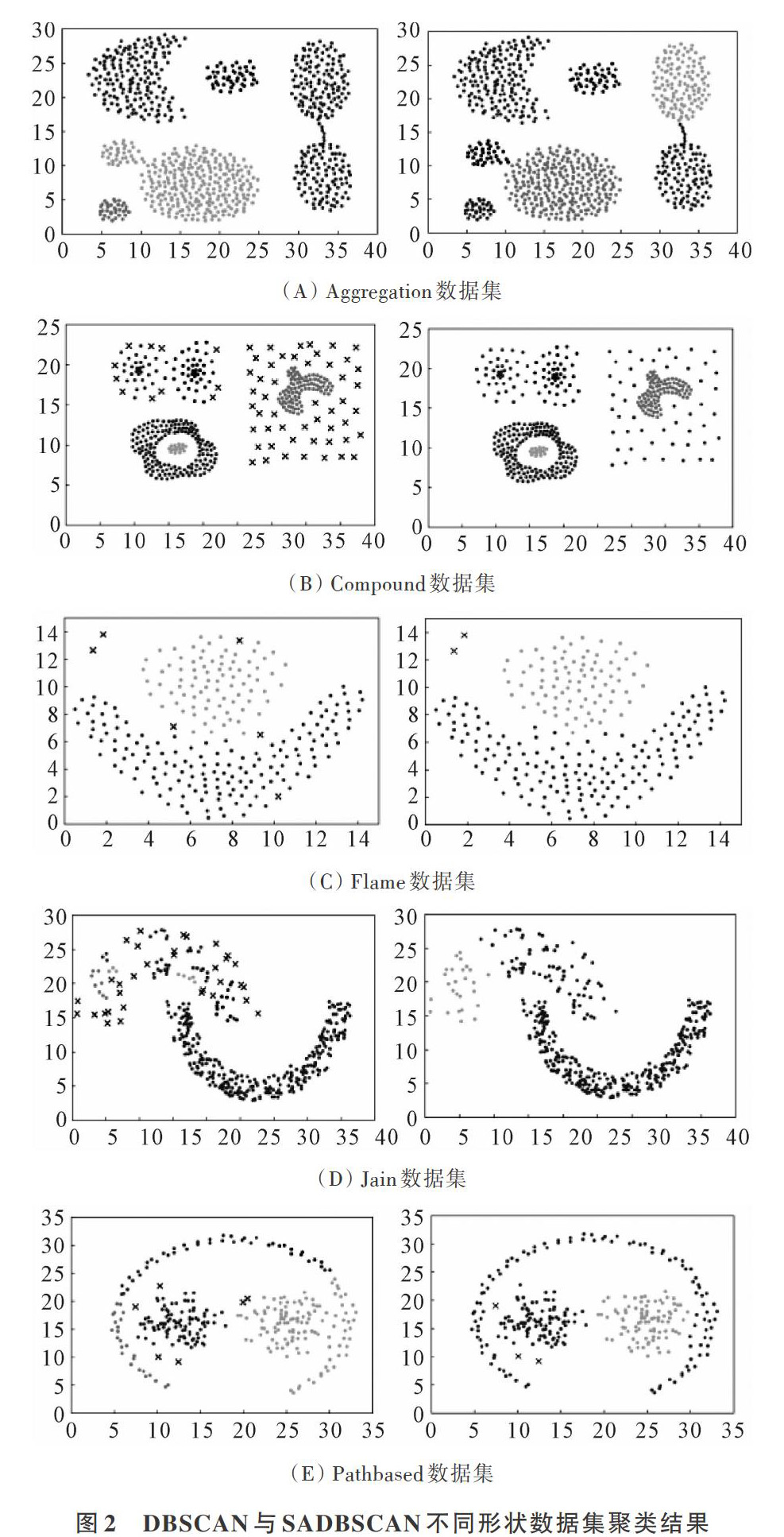
为了验证SADBSCAN算法的可行性与优越性,使用具有不同形状、局部密度和噪声点的标准数据集直观展示聚类效果,并与经典的基于密度的算法DBSCAN进行比较。
3.1 实验数据与结果
使用数据集是在聚类分析中广为应用的标准数据集,均为二维数据,同时具有局部密度不同、簇形各异以及有离散点干扰等各自不同特点。各数据集参数如表1所示,将两种算法分别应用于各数据集上。
- 语文字词教学“边缘化”现象的思考
- 对小学计算机教学的定位与思考
- 微课在小学数学教学中的应用探究
- 微课在农村小学数学教学中的有效性及有效操作的策略研究
- 巧用多媒体拓展小学语文阅读教学
- 小学语文教学对多媒体的灵活运用分析
- 微课在小学语文识字教学中的应用研究
- 如何利用信息技术创建小学语文高效课堂
- 试问如何借助信息技术创建语文高效课堂
- 信息化教学在农村小学语文教学中的运用
- 浅析小学数学生活化教学的策略
- 打击乐器在小学音乐课堂中的作用探讨
- 小学数学教师课堂提问技能现状及策略研究
- 小学美术教学中生活化教学策略分析
- 小学数学教学中的“生活化教学”
- 小学数学教学对趣味教学法的实践
- 趣味教学法在小学语文教学中的运用研究
- 浅议提问在小学语文课堂教学中的运用
- 生活化教学在小学语文作文教学中的运用探析
- 培智语文课堂生活化的探索
- 体育游戏在小学体育教学中的运用分析
- 浅谈绘画日记在小学美术教学中的实践运用
- 整体语言教学在小学英语绘本教学中的应用
- 对小学数学阅读材料的开发和利用
- 小学数学教学提问策略研究
- birdying
- biro
- biro™
- birth
- birth certificate
- birth certificates
- birth-certificates
- birth control
- birthcontrol
- birth control/family planning
- birth controls
- birth-controls
- birthday
- birthdays
- birthed
- birthmark
- birthmarks
- birthplace
- birthplaces
- birthrate
- birth rate
- birthright
- births
- bis
- biscuit
- 穷径
- 穷得叮哩当啷响
- 穷得叮当响
- 穷得屁眼儿挂铃铛
- 穷得当当响
- 穷得精光
- 穷微
- 穷徼
- 穷心
- 穷心剧力
- 穷心输虑
- 穷忙
- 穷忙族
- 穷快活
- 穷态极妍
- 穷怒
- 穷怕亲戚富怕贼
- 穷怕来客,富怕来贼
- 穷思极想
- 穷思毕精
- 穷思竭想
- 穷急
- 穷恚
- 穷悟
- 穷悬