常逢佳 李宗花 文静 常逢锦

摘要:随着就业压力日渐增加,准确全面地获取数据可以帮助高校学生规避就业风险、正确认识自身价值,具有相当重要的研究价值。基于Python的网络动态招聘数据抓取方案利用requests库抓取Ajax异步请求多页数据源,抓取的内容更为全面;对抓取到的招聘数据进行统计分析,对多线程效率进行对比分析,显示爬虫具有良好的适应性。该方案抓取的网络资讯在科研、求职等方面具有一定实用价值。
关键词:网络爬虫;招聘;Python;数据分析
DOI:10.11907/rjd k.191156
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2019)012-0130-04
0引言
据北大青鸟统计,2019年高校应届毕业生人数高达834万,再加上中专技校、往届毕业生、海外留学人员等,预计超过1500万人求职,形成了巨大的就业压力,毕业生就业问题成为社会关注焦点。
同时,随着海量信息的涌现和信息技术的不断进步,网络招聘广泛出现在各种网络信息中,但大量招聘网站真假难辨,高校毕业生难以在众多职位信息中作出正确选择。目前,互联网上存在许多同类招聘网站,表1列出目前比较规范的求职网站。但是现有招聘网站大部分是各类企业面向整个社会在互联网上发布职位信息,其数量庞大,信息结构复杂,求职者很难在大量职位中找到适合自己的职位,导致有时企业招不到人才,而求职者无法找到合适岗位。
黄贵斌等介绍了几种采用聚类算法将学生、企业进行分类的方法,但是在职位推荐功能中,没有采用实际招聘职位,并且数据量小,分析学生和企业真实历史数据的可行性较低。因此,对于就业推荐系统,招聘数据时效性和真实性十分关键。若能准确抓取招聘数据并深入分析与挖掘,可实现对大学生就业方向的有效预测与引导。
因此,本文通过分析拉钩网招聘信息的存储方式进行关键数据的获取研究,以Python为技术基础进行开发,综合运用多个Python网络函数库,从中获取公司名称、地区、职位名称、工作年限、工资、公司资质、公司规模、福利等信息,最后将数据保存到Excel电子表格中,以便统计分析和为后期就业推荐系统开发提供数据。
1爬虫技术概述
目前,获取招聘信息最主要途径是通过搜索引擎,其最核心构件是网络爬虫,若无该技术后继工作将无法开展。网络爬虫又称网页蜘蛛、网络机器人,是一种按照一定规则,自动抓取万维网数据信息的程序。如果把万维网比作一张大网,则爬虫技术就是网上的蜘蛛,若将网络节点比作网页,这个“蜘蛛”爬到何处就等于访问了哪个网页,获得了相应信息;而后可顺着这些节点继续爬到下一个节点,这样整个网的所有节点便被这个“小蜘蛛”全部爬到。而搜索引擎就是将“小蜘蛛”爬取到的数据以一定策略进行处理,并为用户提供服务,从而达到信息检索的目的。
1.1Python爬虫
Python是一款开源的、可以运行在任何主流操作系统中的解释性高级程序设计语言。选择Python作为实现招聘信息爬虫的语言主要考虑如下:
(1)开发效率高。因为爬虫的具体代码需要根据不同的网站进行修改,Python方便、简单的语法可以高效地节省开发时间及成本。
(2)Python爬取网页文档的接口更简洁。Python为爬虫开发提供了如urllib、urllib2等丰富的第三方库。爬虫程序可以模拟浏览器访问网站的流程,得到网站所有HTML数据,比其它语言(c、c++、Java)更方便、快捷。
(3)网页爬取后的数据可以是结构化数据,如XML和JSON等;也可以是非结构化的数据,如办公文档、文本、HTML、图像等。Python支持一些解析技术,包括正则表达式、Xpath、Beautiful Soup等,如果返回的是HTML格式的数据,则可使用lxml库解析网页,通过节点提取等一些常规方法,提取出真正需要的数据。如果返回的是JSON格式的数据,则可通过JSON解析获取数据。
1.2通用爬虫流程
通常可以按照不同的维度对网络爬虫进行分类,例如,按照使用场景,可将爬虫分为通用爬虫和聚焦爬虫;按照爬取形式,可分为累计式爬虫和增量式爬虫;按照爬取数据的存取方式,可分为表层爬虫和深层爬虫。在实际应用中,网络爬虫系统通常由几种爬虫技术结合实现。
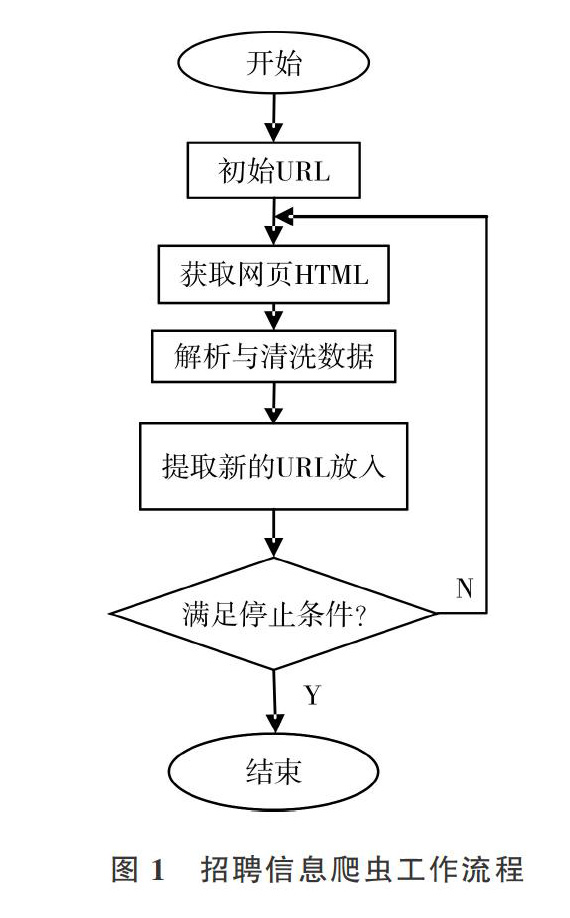
招聘信息爬虫是一个自动提取网页的程序,基本工作流程包括:①选取一个或若干个初始网页的URL;②由网页下载模块获取URL对应网页的HTML,传递给数据解析模块之后,将URL放进已爬取URL队列;③数据解析模块解析收到的HTML,查找标签,提取出标签所需数据,传递至数据清洗模块,经提取后将URL传递至URL调度模块;④调度模块收到解析模块传递过来的URL后,将其和已抓取的URL队列对比,进行去重处理,筛选出未爬取的URL再放人待爬取URL队列;⑤網络爬虫系统在第②一④步循环,直到待爬取队列中的URL全部爬取完毕,或者用户终止进程;⑥数据清洗模块发现并纠正数据文件中可识别的错误,最终将数据存人数据库或Excel表格中。但是,上述爬取行为需要遵循如标注为nofollow的链接或Robots协议等内容。
2网络爬虫案例实现
拉钩网是国内著名的招聘网站,求职者可以通过官方网站提供的信息了解公司概况、岗位需求信息等。为了能够准确地从海量招聘信息中获取想要的数据,本文针对拉钩网招聘信息特征设计爬虫案例,使用爬虫工具专门爬取招聘数据,供后期数据分析。
2.1数据分析
首先利用Chrome浏览器打开拉钩网主页(https://www.1agou.com),在搜索框中输入职位关键字,例如“java开发工程师”,所有与职位相关的信息即被列出,这些信息是待爬取的数据。
右击招聘职位空白处,选择“检查”选项,进入源代码调试窗口,并定位到其对应的标签位置,在
標签中保留一条完整的职位信息。通过data-index属性表明每一页最多可显示15条检索的职位信息。利用network选项卡中XHR(ajax异步请求显示结果)查看positionAjax.json条目,存取的每一页中15条职位详细信息如图2所示。观察JSON数据,该处选取键值名称分别为companyFullName、district、positionN ame、work Y ear、salary、iinanceStage、compa-nySize、industryField、companyLabelList,分别对应公司名称、地区、职位名称、工作年限、工资、公司资质、公司规模、所属类别、福利等含义。经过上述观察分析,这些键值是待爬取数据。
在开发库选取中,Python中的第三方库requests库是基于Python开发的http库,它在Urllib库基础上进行了高度封装,不仅可重复读取返回的数据,还可自动确定相应内容的编码,减少大量工作且使用方便。
2.2爬取流程
爬取的数据主要以JSON格式进行存取,因此爬取流程主要分为如下步骤完成。
(1)利用requests库中的request(‘GET,url,headers=headers).ison()获得response对象。
一些请求如果不是从浏览器发出,则无法获得相应内容,所以爬虫程序需要伪装成一个从浏览器发出的请求。即在发送Request请求时,加入特定的headers,在爬取拉勾网招聘信息时,传递url同时,必须传递伪装浏览器发送请求的headers头。
Referer字段也被用作防盗链,即下载时,判断来源地址是不是在网站域名之内,否则无法下载或显示。拉钩网在header中必须携带Referer字段。同时,由于请求以get方式发送,当传递的URL中包含中文或者其它特殊字符(例如,空格或‘/等)时,需要利用urllib.parse.urlencode()方法将中文参数进行编码。它可以将key:value这样的键值对转换成“key=value”的形式。为了增加爬取程序的通用性,利用input接收用户输入需要爬取的职位名称,并利用split(‘=)[1]进行切割。完成上述功能后定义get_page(url,headers)函数,返回response对象。
(2)将response对象返回的数据进行分页爬取。在获取的response对象中包含每一页最多15个招牌信息,如图3所示。
2.3相关问题
在测试过程中,为尽量使程序面对各种问题时仍能正常运行,本文对爬虫细节进行如下设置。
(1)为了防止因频繁访问而被网站封锁,本文爬虫设置了随机时间间隔。根据实验结果,将间隔设置为0.5~2s。
(2)设计了断点记录功能。在获取职位列表和详细资讯内容的同时,将正在爬取的地址和其在职位列表中的位置保存起来。爬虫重新启动时,根据断点位置继续运行,无需从头开始,该功能可节省大量时间。
(3)采用多线程爬取数据技术,效率可大幅提高。
(4)拉钩网采取反爬取技术,若同一个IP反复爬取同一个网页,很可能被封,因此设置代理IP池。
3结果分析
在爬虫效率测试中,分别使用不同的线程数量进行测试,测试数据如表2所示。为了节省爬取时间,将爬取搜索职位页面设置为3页。
从测试结果可以看出,线程数量从1分别变化为2、3时,爬取速度均有明显提升。线程数量上升到4时,系统为了维护各个线程需要分配出一定资源;同时考虑到网络带宽等因素,增加线程对爬虫速度已无明显影响。因此,多线程技术的使用需要考虑机器性能、网络带宽等各种因素。
4结语
本文以爬取拉钩网招聘数据为例,介绍了一种爬取招聘数据的爬虫程序设计。面对复杂的网络,本文爬虫设计方法仍存在一些问题,有进一步优化的空间。例如:爬取数据较多时,速度较慢,可以通过缓存与多进程技术再次提升爬虫效率,建立分布式爬虫应对海量数据。本文爬虫工具的实现为后续研究工作奠定了一定基础。
- 延期补偿费的统计分析
- 中俄经贸深度合作的颠覆性创新研究
- 关于现代设计观的思考
- 双转台五轴数控机床误差的动态实时补偿研究
- 国有企业员工招聘体系中的问题与对策分析
- 薪酬福利与工作体验的激励性比较研究
- 不同类型高校城市管理专业建设调研及建设启示
- 从战略管理的角度看新乡党性教育基地经营策略
- 新型城镇化背景下地方高校城乡规划专业实践教学改革探索
- 乡镇基层做好第三次农业普查工作的路径探析
- 农村经济发展与人力资源开发探究
- 城乡社会保障一体化发展思考
- 南宁市机构、社区、家庭三维一体养老模式构建探索
- 当前农村集体“三资”管理存在的问题与对策
- 论集体土地上安置房安置模式的利弊及对策分析
- 农村集体经营性建设用地入市改革探析
- 现代信息技术在物流管理中的应用研究
- 面向云计算与物联网技术的电子商务模式研究
- 共享经济背景下打车软件对传统出租车行业的冲击
- 支付宝和微信支付在应用场景上的差异性研究
- 京津冀协同发展机遇下河北省跨境电子商务发展对策分析
- 关于大学生课堂使用手机对学习效果影响的调查分析
- 杭州市农村电商集聚区团建实践研究
- 移动互联网汽车保险服务设计研究
- 电子商务专项职业能力培训课程标准
- untersenesses
- unterser
- untersest
- untestable
- untestifying
- untextural
- untextured
- unthanking
- unthawed
- unthawing
- untheatric
- untheatrical
- untheatrically
- unthematic
- unthematically
- untheological
- untheoretic
- untheoretical
- untheoretically
- untherapeutic
- untherapeutical
- untherapeutically
- unthick
- unthicken
- unthickened
- 儿童散文
- 儿童文学
- 儿童时代
- 儿童时期
- 儿童时期结下的交情
- 儿童是新时代的创造者,不是旧时代的继承者
- 儿童束发成两个角
- 儿童片
- 儿童玩具
- 儿童生理和心理上提早成熟
- 儿童电影
- 儿童的乳牙
- 儿童的天使
- 儿童的容颜
- 儿童竹马
- 儿童般的心情
- 儿童节
- 儿童观
- 儿童诗
- 儿童说细侯
- 儿童赌博
- 儿童走卒
- 儿童迎细侯
- 儿童银行
- 儿花女花