张帅 杨雪霞


摘 要:针对传统文本—图像对抗模型中,由于反卷积网络参数过多容易产生过拟合现象,导致生成图像质量较差,而线性分解方法无法解决文本—图像对抗模型中输入单一的问题,提出一种在线性分解基础上加入流形插值的算法,并对传统DCGAN模型进行改进,以提高图像的鲁棒性。仿真实验结果表明,生成花卉图像的FID分数降低了4.73%,生成鸟类的FID分数降低了4.11%,在Oxford-102和CUB两个数据集上生成图像的人类评估分数分别降低了75.64%和58.95%,初始分数分别提高14.88%和14.39%,说明新模型生成的图片更符合人类视角,图片特征更为丰富。
关键词:生成图像;过拟合;深度卷积;流形插值;对抗网络
DOI:10. 11907/rjdk. 201133 开放科学(资源服务)标识码(OSID):
中图分类号:TP317.4 文献标识码:A 文章编号:1672-7800(2020)008-0216-05
Abstract: In the implementation of the traditional text image confrontation model, many parameters of deconvolution network are easy to produce over fitting phenomenon, resulting in poor image quality, the linear decomposition method cannot solve the problem of single input in the text image confrontation model. In this paper, an algorithm based on linear decomposition with popular interpolation is proposed, and the traditional DCGAN model is improved to enhance its robustness to image size. Through simulation experiment, the FID score of flower image and bird image is reduced by 4.73% and 4.11%, the human evaluation scores of the images generated on oxford-102 and cub data sets are 75.64% and 58.95% lower than the original, and the initial scores are 14.88% and 14.39% higher.The experimental results show that the image generated by the new model is more in line with the human perspective, and the image features are more abundant.
Key Words: generating image; over-fitting; deep convolution; epidemic interpolation; adversarial network
0 引言
隨着人工智能技术的飞速发展,深度学习技术成为学者们的研究热点,并在计算机视觉、语音识别、自然语言处理等多个领域取得了诸多成果。其中,GoodFellow 等[1-3]于2014年首次提出了GANs(Generative Adversarial Nets)概念,即生成对抗网络,目前生成对抗网络已成功应用于图像处理领域。
当前生成图像主要是基于生成对抗网络模型,而递归神经网络[4]和卷积神经网络[5]的提出使图像生成更为高效。递归神经网络常用于处理标题语句,从而形成标题向量,也被用来学习区分文本特征表示;卷积神经网络用于图像特征提取,进而形成图像特征向量,其中深度卷积对抗网络也被用于生成人脸、相册封面和房间内部结构。生成对抗网络衍生出的模型包括GAN-INT-CLS[6]、GAWWN[7]、StackGAN[8]和StackGAN++[9]等,虽然这些模型在图像生成方面取得了诸多进展,但其都是以深度卷积对抗网络为基础的,容易造成计算资源浪费以及过拟合现象,主要原因是由于传统卷积网络层数较浅及参数量较大。
为了解决传统卷积网络的缺点,Simonyan[10]提出线性分解方法,在增加卷积网络层数的同时减少参数数量,降低计算量,使得生成的图像不会完全拟合真实图像,从而降低过拟合。为了解决输入标题单一导致生成图片类型单一的问题,本文引入流形插值方法,并结合线性分解的优点,针对如何提高图像质量进行深入研究。
1 相关模型
以DCGAN网络为基础,Dosovitskiy等[11]训练一个反卷积网络,根据一组指示形状、位置和照明的图形代码生成三维椅子效果图;Gregor等 [12]提出DRAW模型,该模型应用递归变分自编码器与注意机制生成真实的门牌号图像;Reed等[13]提出一种端对端的可视化类比生成方法,并在实验中使用卷积解码器有效模拟了二维形状、动画游戏角色与三维汽车模型。上述模型均基于传统卷积神经网络加以构建,尽管生成图像质量较高,但由于网络层数较浅,参数量大,导致计算量过大,而且生成的图像与训练集中的图像过于相似,容易造成计算资源浪费以及过拟合现象。
VGGNet[14]是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,具有很好的泛化性,较好地解决了传统神经网络存在的问题。VGG网络最主要的思想是增加网络深度、缩小卷积核尺寸。VGG-16网络由13个卷积层+5个池化层+3个全连接层叠加而成,包含参数多达1.38亿,其核心思想为线性分解。
本文基于VGG-16与流形插值[15-16]思想构建一种混合网络模型,如图1所示。在确保图像多样性的同时,保障了图像生成质量。采用基于 VGG-16 网络的思想对传统卷积神经网络进行改进,即对卷积网络进行线性分解[17],旨在不过多影响识别准确率的前提下尽量减少网络参数、提高训练效率,同时引入流形插值思想,并丰富生成图片的类型。
2 本文算法
2.1 网络结构
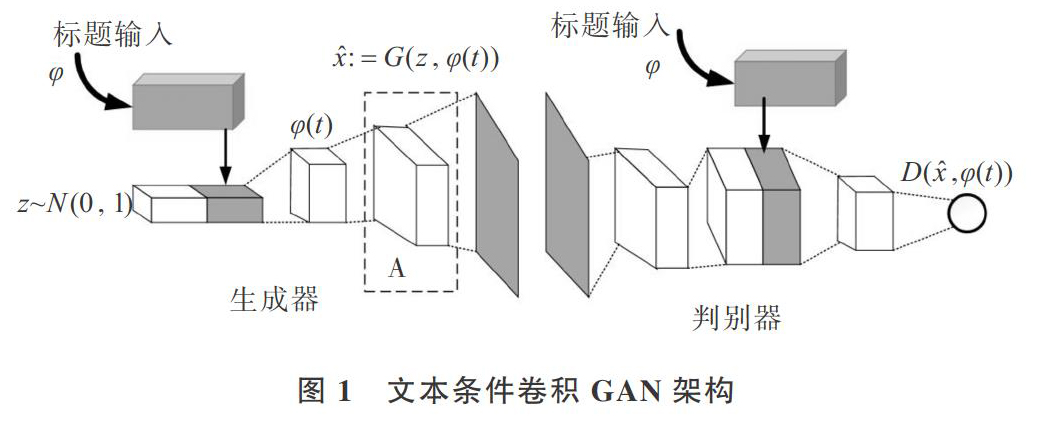
如图1所示,左侧为生成网络,右侧为判别网络,标识A为卷积网络在生成器中的位置,本文将对该位置的卷积网络进行线性分解。在生成器中,首先从噪声分布[z~Ν(0,1)]中进行采样,使用文本编码器[φ]对文本查询T进行编码,使用连接层将嵌入的描述[φ(t)]压缩为小尺寸,然后采用LeakyReLU激活函数对其进行处理,最后连接到噪声矢量[z]。接下来的推理过程就像在一个正常的反卷积网络中一样:通过生成器G将其前馈,一个合成图像[x]是通过[x←G(z, (t))]生成的。图像生成对应于生成器G中基于查询文本与噪声样本的前馈推理。
在判别器D中,首先利用空间批处理归一化和LeakyReLU激活函数执行多个层的步长为2的卷积处理,然后使用全连接层降低描述嵌入[φ(t)]的维数,并对其进行校正。当判别器的空间维度为4×4时,在空间上复制描述嵌入,并执行深度连接;接下来执行1×1的卷积和校正,再执行4×4的卷积,并利用D计算最终分数;最后对所有卷积层执行批处理规范化。
2.2 匹配感知判别器(GAN-CLS)
在传统GAN中,判别器接受两种输入:带有匹配文本的真实图像和带有任意文本的合成图像。因此,其必须隐式地分离两个错误源:错误的图像以及与文本信息不匹配的真实图像。为此,对GAN训练算法进行改进,以将这些误差源分离出来。除训练期间对判别器的真/假输入外,它还添加了第三种输入,由文本不匹配的真實图像组成,判别器必须学会将其评分为假。步长为α的GAN-CLS训练算法如下:
1: Input: minibatch images x, matching text t, mismatching[t],number of training batch steps S。
2. for n = 1 to S do
3. [h← (t)] {Encode matching text description}
4. [h← (t)]{Encode mis-matching text description}
5. [z~Ν(0,1)Z]{Draw sample of random noise}
6. [x←G(z,h)]{Forward through generator}
7. [sτ←D(x,h)]{real image, right text}
8. [sw←D(x,h)]{real image, wrong text}
9. [sf←D(x,h)]{fake image, right text}
10. [LD←log(sτ)+(log(1-sw)+log( 1-sf))/2]
11. [D←D-αδLD/δD]{Update discriminator}
12. [LG←log(sf)]
13. [G←G-αδLG/δG]{Update generator}
14. end for
其中,[x]表示生成的假图像,[sτ]表示真实图像及其对应句子的关联得分,[sw]表示真实图像与任意句子的关联分数,[sf]表示假图像与其对应文本的关联分数。[δLD/δD]表示D的目标相对于其参数的梯度,G也是如此,第11行和第13行表示采取梯度步骤更新网络参数。
2.3 卷积网络对称分解
VGGNet通常用于提取图像特征,将多个相同的3×3卷积层堆叠在一起,而且网络结构越深,性能越好。本文对图1中A处对应卷积网络进行线性分解,如图2所示。
图2表示用两个3×3的卷积网络代替一个5×5的卷积网络。第一层表示用一个3×3的卷积在5×5的窗格上移动,得到一个3×3的输出,如第二层所示,接着用一个3×3的卷积核作运算,最后得到第三层的输出。虽然两者作用是一样的,但是卷积网络分解在增加网络层数的同时能够减少参数,达到降低过拟合的效果。
2.4 流形插值学习(GAN-INT)
流形插值可视为在生成器目标中添加一个附加项,以最小化以下公式:
其中,[z]从噪声分布中提取,[β]在文本嵌入[t1]和[t2]之间插值。在实践中发现,当[β]=0.5时效果良好。其中,[t1]和[t2]可能来自不同图像,甚至是不同类别。
3 实验及结果分析
3.1 实验数据及参数设置
在实验数据集选择和参数设置上,本文引用鸟类图像的CUB数据集和花卉图像的Oxford-102数据集。在实验中,将这些图像划分为不相交的训练集和测试集。CUB有150个训练类+验证类和50个测试类,而Oxford-102有82个训练类+验证类和20个测试类。在进行小批量选择训练时,随机选取图像视图和其中一个标题。
本文对所有数据集使用相同的GAN体系结构,训练图像大小为64×64×3。在深度连接到卷积特征图之前,文本编码器产生1 024维的输入,并在生成器和判别器网络中将图像投射到128维。在Adam优化过程中,设置学习率为0.000 2,动量为0.5,并采用交替步骤更新生成器和判别器网络。从100维单位正态分布中对生成器噪声进行采样,使用64个小批量,并训练100轮。
(3)本实验中也总结了人类评估方法,在测试集中随机选择30个文本描述,针对每个句子,生成模型生成8个图像。将8个图像与对应文本描述对不同人按不同方法进行图像质量排名,最后计算平均排名以评价生成图像的质量和多样性。
3.2 定性结果
本文比较GAN-CLS、GAN-CLS-NA和GAN-CLS- NA-INT 3种模型图像生成效果,其中CLS-GAN-NA模型在GAN-CLS模型基础上对卷积网络进行线性分解。GAN-CLS得到了一些正确的颜色信息,但图像看起来并不真实。将3个模型在各个数据集上训练及测试完成后,都有8个英文标题作为输入,每个标题重复8次,共形成64个标题作为输入,得到8行8列的图像,每行8幅图像对应相同的8个标题。在Oxford-102 Flowers数据集中,GAN-CLS结果如图3所示。
图3对应的输入标题有8个,其中2个如下:①the flower shown has yellow anther red pistil and bright red petals;②this flower has petals that are yellow, white and purple and has dark lines。
在Oxford-102花卉数据集上的GAN-CLS-NA结果如图4所示。
在GAN-CLS-NA模型基础上引入流形插值思想,其中2个标题的变换如下:①the flower shown has yellow anther red pistil and bright red petals→the flower shown has blue anther red pistil and bright yellow petals;②this flower has petals that are yellow, white and purple and has dark lines→ this flower has petals that are red, white and purple and has red lines。
GAN-CLS-NA-INT模型在Oxford-102 Flowers數据集上生成的花卉图像如图5所示。
对比图3与图4相同的行可以发现,其对应的图片标题是相同的,花的基本颜色与形状没有明显区别,但图4的图像更为真实;图5与图4相比,在相同的行中,前4列标题相同,且基本颜色、形状及细节方面都非常接近,后4列则引入了流形插值后生成的图像,可以发现背景及花的一部分颜色发生了改变,使得整体图像的特征类型更加丰富。在CUB鸟类数据集中,GAN-CLS结果如图6所示。
以上图片对应的输入标题有8个,其中2个如下:①this small bird has a blue crown and white belly;②this small yellow bird has grey wings, and a black bill。
在CUB鸟类数据集上的GAN-CLS-NA结果如图7所示。
在CUB鸟类数据集中,GAN-CLS-NA-INT结果如图8所示。
以上图片对应的输入标题有8个,其中2个标题及变换如下:①this small bird has a blue crown and white belly→this small bird has a red crown and blue belly;②this small yellow bird has grey wings, and a black bill→this small white bird has grey wings, and a blue bill。
对比图6与图7相同的行可以发现,其对应的图片标题是相同的,鸟的基本颜色和形状没有明显区别,但二者图像中背景和鸟的姿势不同,图7更真实一些;图8与图7相比,在相同的行中,前4列标题相同,且基本颜色、形状及细节方面都非常接近,但二者图像中背景和鸟的姿势各不相同,后4列则引入了流形插值后生成的图像,可以发现背景及鸟的一部分颜色和姿势已发生改变,使得整体图像的特征类型更加丰富。
3.3 定量结果
首先利用花卉描述标题集与相应图像数据集对CLS-GAN模型进行100轮训练。每轮训练结束后,输入花描述语句生成相应图像,总共生成100幅图像。本文选择的图像评价方法为FID分数评估方法。采用上述图像评价方法,分别对由CLS-GAN和CLS-GAN-SA两种模型生成的100幅图像进行评价,定性结果如表1所示,而利用初始分数和人类评分的定量结果如表2所示。
从表中可以看出,GAN-CLS-NA在Oxford-102花卉数据集上的FID数值与GAN-CLS结果相比,FID分数降低了2.34%;GAN-CLS-NA在CUB鸟类数据集上的FID数值与GAN-CLS结果相比,FID分数降低了2.29%,说明在判别器中对卷积层进行适当分解,在减少参数量与降低过拟合的同时,也提高了生成图像质量。同时,GAN-CLS-NA-INT在Oxford-102花卉数据集和CUB鸟类数据集上的初始评分与GAN-CLS结果相比,分别提高了14.88%和14.39%,说明生成的图像特征类型更加丰富;人类评估分数分别降低了75.64%和58.95%,该指标越低说明越符合人类视角,也即表明生成的图像质量越好。
4 结语
本文在GAN-CLS模型基础上对模型判别器中的卷积网络进行线性分解,并用分解后的卷积网络提取图像特征。在Oxford-102花卉数据集和CUB鸟类数据集上的实验结果表明,本文模型效果优于基于传统卷积网络模型的效果,证明对卷积网络进行适当分解可以降低过拟合,提高生成图像质量。另外,引入流形插值在丰富生成图像类型的同时,也能有效提高图像质量。在未来工作中,将进一步研究如何降低图像失真现象。
参考文献:
[1] DENTON E, CHINTALA S, SZLAM A, et al. Deep generative image models using a laplacian pyramid of adversarial networks[C]. Advances in Neural Information Processing Systems, 2015:1486-1494.
[2] HUANG X, LI Y, POURSAEED O, et al. Stacked generative adversarial networks[C]. ?2017 IEEE Conference on Computer Vision and Pattern Recognition , 2017:1866-1875.
[3] ZHAO J, MATHIEU M, LECUN Y. Energy-based generative adversarial network[C]. Toulon: International Conference on Learning Representations, 2016.
[4] XU R F,YEUNG D,SHU W H,et al. A hybrid post-processing system for Handwritten Chinese Character Recognition[J]. International Journal of Pattern Recognition and Artificial Intelligence,2002,16(6):657-679.
[5] 徐冰冰,岑科廷,黄俊杰,等. 图卷积神经网络综述[J/OL]. 计算机学报,2019:1-31[2020-04-06]. http://kns.cnki.net/kcms/detail/11.1826.tp.20191104.1632.006.html.
[6] REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis[C]. ?International Machine Learning Society (IMLS),2016:1681-1690.
[7] REED S,AKATA Z,MOHAN S,et al. Learning what and where to draw[C]. Advances in Neural Information Processing Systems,2016:217-225.
[8] 陈耀,宋晓宁,於东军. 迭代化代价函数及超参数可变的生成对抗网络[J]. 南京理工大学学报, 2019,43(1):35-40.
[9] 徐天宇,王智. 基于美学评判的文本生成图像优化[J]. 北京航空航天大学学报,2019,45(12): 2438 -2448.
[10] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale Image recognition[C]. ?International Conference on Learning Representations, 2015:1-12.
[11] DOSOVITSKIY A,SPRINGENBERG J T,BROX T. Learning to generate chairs with convolutional neural networks[C]. IEEE Conference on Computer Vision & Pattern Recognition,2015:1538-1546.
[12] GREGOR K, DANIHELKA I, GRAVES A, et al. DRAW: a recurrent neural network for image generation[C]. International Conference on Machine Learning,2015:1462-1471.
[13] REED S, ZHANG Y, ZHANG Y T, et al. Deep visual analogy-making[C]. ?Advances in Neural Information Processing Systems, 2015: 1252-1260.
[14] 谢志华,江鹏,余新河,等. 基于VGGNet和多谱带循环网络的高光谱人脸识别系统[J]. 计算機应用, 2019,39(2):388-391.
[15] BENGIO Y, MESNIL G, DAUPHIN Y, et al. Better mixing via deep representations[C]. International Conference on Machine Learning, 2013:552-560.
[16] REED S,SOHN K,ZHANG Y T,et al. Learning to disentangle factors of variation with manifold interaction[C]. International Conference on Machine Learning,2014: 3291-3299.
[17] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016: 2818-2826.
[18] HEUSEL M,RAMSAUER H,UNTERTHINER T,et al. GANs trained by a two time-scale update rule converge to a local nash equilibrium[C]. ?Advances in Neural Information Processing Systems, 2017:6627-6638.
[19] SALIMANS T,GOODFELLOW I,ZAREMBA W,et al. Improved techniques for training GANs[C]. Advances in Neural Information Processing Systems, 2016:2234-2242.
(责任编辑:黄 健)
- 档案法规体系变迁视角下档案制度中的权力与权利探析
- 关于文书立卷的批判性研究
- 公共档案馆形成与发展的外动力研究
- 英国国家档案馆网站的教育栏目及启示
- 西方档案史研究发展概述及其启示
- 遗珠之憾
- 选择
- 档案宣传应有“传播维度”概念
- 命运问题
- 话说档案那些事(六):看不明白的档案鉴定
- 互联网+背景下档案工作者真善美品格塑造
- 如何做好企业档案管理与利用工作
- 纸质档案与电子档案“双套制”管理探析
- 地方高校教学档案管理促进教师专业化发展的策略研究
- 高层次人才流动背景下高校人事档案管理中的常见问题及对策
- 新时代档案文化价值实现途径探究
- 公共图书馆评估档案库建设途径探析
- 澳大利亚档案工作者协会“设计档案”联合会议将于10月召开
- “文化多样性专业经验”建筑档案国际会议将于9月召开
- 国际档案理事会专家组面向全球开展“离散档案”调查
- 加州大学洛杉矶分校召开2019年度影视档案馆保存节
- 加拿大档案工作者协会不列颠哥伦比亚大学学生分会举办第11届国际研讨会
- 档案利用与“黑天鹅事件”
- 从年表到目录:1882—1975年加拿大公共档案馆检索工具的体裁演变
- 话说档案那些事(五):归档:将历史装进档案盒
- dramatized
- dramatizer
- dramatizers
- dramatizes
- dramatizing
- drank
- drapabilities
- drapability, drapeability
- drapable, drapeable
- drape
- drapeabilities
- draped
- drapes
- drapey
- draping
- drastic
- drastically
- draught
- draughted
- draughter
- draughters
- draughtier
- draughtiest
- egalitarian
- egalitarianism
- 孥稚
- 孥累
- 学
- 学不倦,所以治己也;教不厌,所以治人也
- 学不厌博
- 学不厌,智也
- 学不可以已
- 学不完的聪明,上不完的当
- 学不沾洽
- 学不精勤,不如不学
- 学不精勤,不如不学。
- 学不躐等
- 学世
- 学业
- 学业、学问
- 学业、技术因不常用而致生疏
- 学业、技艺的功底雄厚
- 学业优博
- 学业优异的学生
- 学业优秀
- 学业修养
- 学业在勤
- 学业巨成
- 学业有成
- 学业有成就之人