王海玲 周志彬

摘 要:利用Python编程语言的Scrapy框架,为猫眼网站设计一个网络爬虫程序,对猫眼网页中《复仇者联盟4》的用户评论进行抓取。对抓取下来的网页信息进行信息提取,并将有用信息转换为dataframe格式存储到csv文件中;再将csv文件中的数据通过Pandas库进行提取排列,并利用Pyecharts库生成可视化图表的html页面;最后修改url中的setoff属性,通过改变starTtime的值,成功获取了更多评论。结果表明,比正常获取评论数的最大值990条多了16倍。
关键词:Scrapy框架;爬虫;数据可视化
DOI: 10. 11907/rjdk.191814
开放科学(资源服务)标识码(OSID):
中图分类号:TP393
文献标识码:A
文章编号:1672-7800(2020)004-0224-05
0 引言
随着大数据时代的来临,普通搜索已无法满足人们对信息获取的需求,网络爬虫应运而生。网络爬虫又称网络蜘蛛,是一种能够根据程序设计者所设计的规则自动抓取特定网页信息的程序。按照实现原理可分为3类:第一类是通用网络爬虫,指搜索引擎爬虫,类似于百度、谷歌等大型搜索引擎[1],其特点是根据一定的策略,用特定的计算机程序,将互联网上的信息加以收集并对信息进行筛选和排列后展示给用户,搜索引擎由搜索者、用户界面、索引器和搜索器4部分组成[2];第二类是聚焦爬虫,其可以针对特定网页,也称为网络蜘蛛、网络机器人,还经常被称为网页追逐者。它与搜索引擎的区别在于其针对性强并细化了搜索内容[3];第三类是增量式网络爬虫,是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面[4]。此外,也涌现了很多成熟的爬虫框架,如非常流行的Scrapy[5-10]。
但是,传统爬虫网络获取页面较少,无法满足爬取需求,代码也比较复杂。本文通过修改url中的setoff属性,改变starTtime的值,以猫眼网站为例,通过Scrapy搭建爬虫项目,分析整个爬虫原理。一是实现程序在远程服务、手机端的部署;二是通过改变不同的数据接口,实现对猫眼网络电影《复仇者联盟4》更多评论信息抓取,并对获取的数据进行可视化分析。
1 Scrapy框架介绍
Scrapy是由Python开发人员开发的一种高速、高级的Web捕获框架,它被用来抓取网站内容并从页面中提取结构化数据。与普通网络爬虫不同的是,基于Scrapy的爬虫系统抓取的网页信息需与用户需求相关,而无需对互联网上的所有资源进行采集[11-13]。
1.1 框架组成
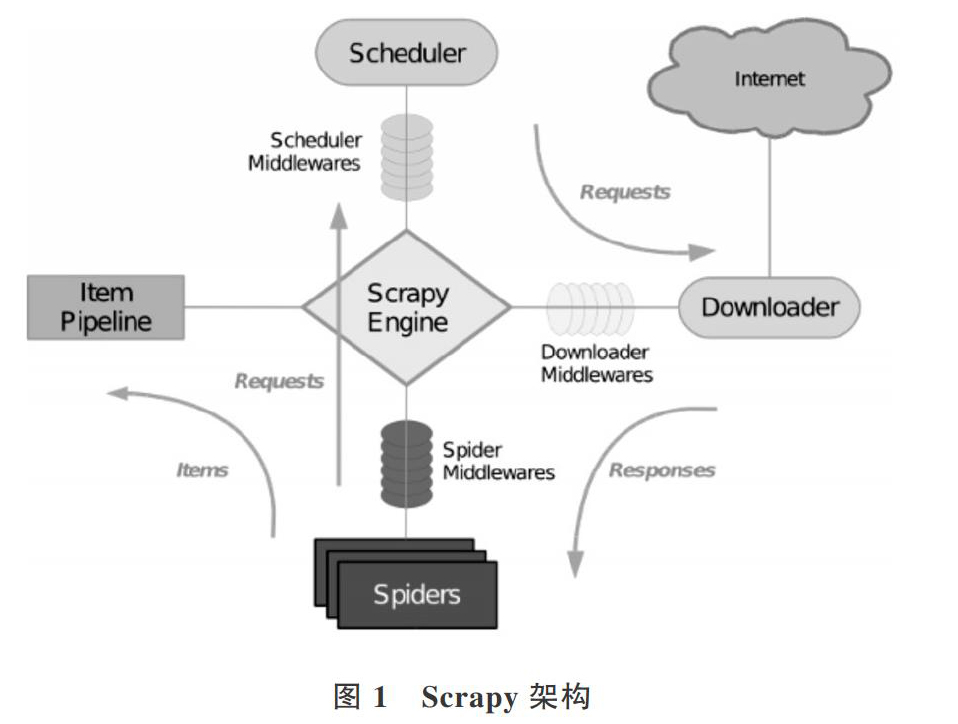
Scrapy架构如图1所示,其中包含了Engine、ItemPipeline、Downloader、Spider以及Scheduler等几个组件模块,图中箭头表示数据在整个系统中的处理流程[14-15]。
1.2 组件说明
Engine:引擎是触发系统工作任务的框架核心,系统数据流处理都由它统一调度处理的。
调度器:用来接受引擎传达的请求,并将请求压入队列中,在引擎再次请求时返回。可以想像成一个URL的优先队列,它会决定下一个要抓取的网址是什么,并对网址进行查重,去除重复网址。
下载器:下载网页中所需内容,然后将该内容返回给爬虫。
爬虫:从特定网页也即实体中抓取所需信息,分析页面信息,提取下一页的链接进行递归爬取。
项目管道:负责处理爬虫从网页中提取的实体,主要功能是对实体进行持久化,验证实体的有效性,清除不必要的信息。当爬虫对页面进行解析时,会将其发送到项目管道中,并按几个特定的顺序对数据进行处理。管道的执行过程具体包括清洗HTML数据、验证解析到的数据、检查是否为重复数据,并将解析到的数据存储到数据库中。
爬虫中间件:位于引擎和爬虫之间的框架,负责处理爬虫的响应及输出。
下载器中间件:位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应[16-18]。
1.3 Spider工作流程
首先解析第一个URL,获取它的请求,在其返回时检索回调函数;之后在回调函数中,对解析网页进行响应,返回项目对象和请求对象的迭代,请求中还将包含一个回调信息,由Scrapy下载;然后对其进行回调处理,在回调函数中,对网站内容进行解析,使用Xpath选择器生成解析后的数据项;最后,从爬虫返回的信息通常都进入到项目管道中。
1.4 Pandas库
Pandas模块是Python用于数据导人及整理的模块,对数据挖掘前期数据处理十分有用。Pandas库具有两种数据类型:Series类型和Dataframe类型。本文主要采用Dataframe数据类型,Dataframe是一种带“标签”的二维数组,基本操作与Series类型相似。
1.5 Pyecharts库
Pvecharts是Pvthon中用来生成Echarts图表的类库,而Echarts是支持数据可视化的一个JS库,用Echarts生成的数据图形效果非常好。Pyecharts与Python接口一起,方便在Pvthon中直接使用数据生成。使用Pvecharts可以生成单独的网页,也可以在Djangoflask中集成和使用。本文主要使用Pyecharts生成独立的Web显示图表。
1.6 Json库
Json是一种轻量级的数据交换格式,其结构简单、层次清晰,易于编写和读取,也可由机器轻松解析生成,达到提高网络传输效率的目的。在数据交换方法中,它是颇具优势的数据交换格式之一。绝大多数网页都具有Json格式的数据文件,Javascript是Json的主战场,相比于XML而言,Json自然是更具有优势的数据交换格式。此外,JSON和XML还有一个很大区别,即有效的数据速率。JSON作为数据包格式传输时效率更高,因为JSON不需要像XML這样严格的封闭标签,与总数据包相比,这极大提高了有效数据量,从而在数据流量相等的情况下降低了网络传输压力[19-20]。
Json库中的Encode函数在Python中可以有效地转换Python对象和Json对象。尤其在可视化数据时,将获得的数据转换成Json对象,可以使数据灵活地转换为Pandas库的数据操作对象。
2 Spider模型建立
本文以Scrapy为框架编写网络爬虫程序,使程序可自动爬取猫眼网的指定信息。在抓取到指定的Json文件地址后,对该地址下的数据进行格式转换及存储操作,具体步骤如下:
(1)使用Pycharm在Terminal中搭建Scrapy框架,建立“maovan”工作项目。
(2)在item.py文件中创建需要爬取的字段属性,其中有城市:“city”,评论:“content”,用户id:“user_id”,昵称:“nick name”,评分:“score”,评论时间:“time”,用户等级:“user level”。
(3)在创建的爬虫主文件comment.py中,将多个用户代理以数组的形式定义。
(4)通过指定接口获取用户评论地址,并将该地址下的数据转换为Json格式。
(5)通过循环判断,将筛选出来的数据用yieldrequest方法传送到管道中。
(6)在pipelines.py文件中,将数据创建dataframe格式并存储到csv文件中。
(7)创建data_analysis.py,用Pyecharts库及Pandas库的方法对数据进行可视化处理。3页面分析
分析页 url:
m.maoyan.com/m ovie/248172/e omments?_v_=yes
在获取跳转页面时选择xpath对跳转标签进行定位,获取跳转标签下的url。本文使用Chrome开发者工具,maoyan.com为该网站域名,目标url中的“248712”為《复仇者联盟4》在该网站目录下“movle”目录中的编号。但是猫眼网在PC端的设计中未展示所有评论内容,而且PC浏览器接口在访问该网页时被限制,只能获取到热门评论,于是调试为手机端访问模式如图2所示,实际操作是模拟手机端的接口访问猫眼网。
由于猫眼网未设置接口的反爬取机制,通过模拟手机客户端( Galaxy S5)的访问方式,能直接得到猫眼网电影评论信息的Json数据,这更方便结果获取。
4 url构造策略
目标域名:maoyan.com
目标url:
http: //m .maoyan.com/m md b/comments/m ovie/2489 06.json?
_v_ =yes&offset=O&startTime=2019-04-29% 2004: 08:34
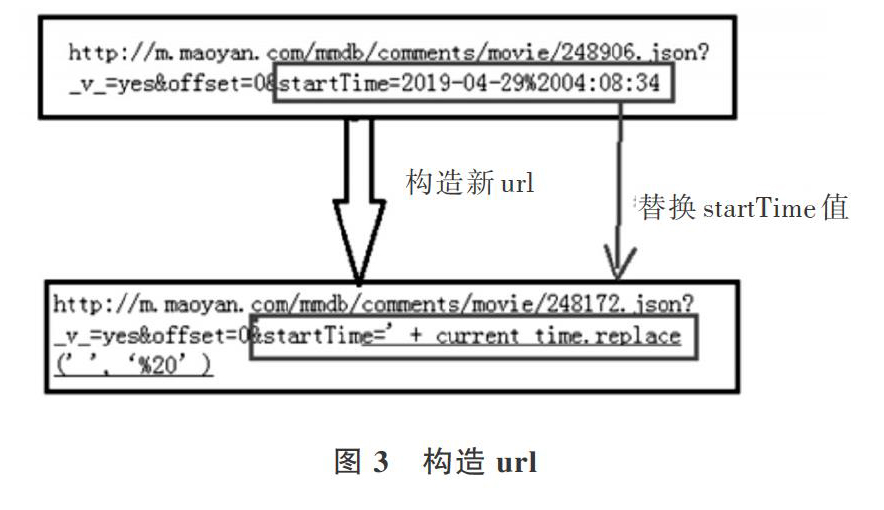
正常情况下,如果以offset(每次+15)的方法控制翻页进行数据爬取,所获得的数据最大值到990条就不能继续获取了。本文在尝试多个不同的接口对评论页面进行访问之后,成功地找到了除setoff外还拥有starttime属性的接口,通过在url中设定setoff为0,改变starTtime的值,即将每页评论中最后一次评论时间作为新的startTime并构造新的url压入队列进行重新访问、爬取,这样就可以获取更多评论,具体构造方式如图3所示。
5“猫眼”爬虫总体设计
5.1 定义item.py
本文使用命令行生成maoyan的Scrapy爬虫项目,同时在该项目目录下生成Scrapy框架的文件目录,如图4所示。
5.2 定义settings.py
在settings.py文件中,将ROBOTSTXT一OBEY属性改为False,ROBOTSTXT-OBEY是一个机器人协议,当其属性为True时,它会限制爬虫文件所能爬取的范围。由于此次爬取的数据内容较大,因此将其改为False,并将其定义于pipelinese.py中的规则激活即可。
5.3 comment.py
comments.py是爬虫的主文件,爬虫代码在此完成。首先在CommentSpider类中定义爬虫名为comment,用al-lowed_domains将除maoyan.com外的域名进行过滤处理,再将多个不同的用户代理以字典的形式储存,定义一个变量随机获取该字典中的不同用户代理。定义一个变量cur-rent_time获取系统当前时间,再对目标url中的start_Time值进行替换,可获得更多评论数。
完成上述操作之后,对parse函数进行定义,首先定义item继承items.py文件中的Maoyanltem(),其次定义data变量用response.body方法保存指定页面下的数据,再定义json_data变量保存json格式化过的data值,最后对json_data中的数据进行循环判断,符合条件的数据赋值给item进入管道。
爬虫数据在csv中存储部分如表1所示,其中表头部分包括城市:“city”,评论:“content”,用户id:“user_id”,昵称:“nick—name”,评分:“score”,评论时间:“time”,用户等级:“user_level”。由于表格内容较多,具体评论内容取其前4个字,截取2019年4月29日时间段。
5.4 替换start_Time
为了爬取所有评论信息,在不改变setoff的条件下,将该页面最后一条评论的评论时间作为新的开始时间,即将startTime改为:startTime=-+ current_t.replace(‘,%20)的形式,对页面重新请求,可获取更多评论数。
5.5 pipelines.py
将pipelines.py管道中的数据与各对应数据名做一个字典类型存储在dic t_info,字典每个元素的第1位字符串为生成的csv文件表头。表头内容有城市:“city”,评论:“content”,用户id:“user_id”,用户昵称:“nike_name”,评分:“score”,评论时间:“time”,用户等级:“user_level”,再为其建立dataframe的表格形式,最后输出为csv文件。具体代码为:
import scrapy
class Maoyanltem( scrapy.ltem):
# define the fields for your item here like:
# name= scrapy.Field()
city= scrapy.Field()#城市
content= scrapy.Field()#评论
user_id= scrapy.Field()#用户id
nick_name= scrapy.Field()#昵称
score= scrapy.Field()#评分
time= scrapy.Field()#评论时间
user_level= scrapy.Field()#用户等级
pipelines.py:
import pandas as pd
class MaoyanPipeline( object):
def process_item( self, item, spider):
dict_info={'city': item[ 'city'],‘contem': item[‘content],'user_id:item[‘user_id],
‘nick_name: item[‘nick_name9],
‘score : item[ 'score' ] , 'time' : item[‘time],'user_level: item[‘user_level']}
try:
data= pd.DataFrame( dict_info, index=[O])#為data创建一个表格形式,注意加index=[0]
data.to_csv ( ‘E:/pytest/maoyan/maoyan/info.csv ,header=False. index=True. mode=‘a.
encoding=‘utf_8_sig)#模式:追加,encod-ing=‘utf-8-sig
except Exception as error:
print(‘写入文件出错一一一一>>>+str( error))
else:
print(dict_info[‘content]+‘一一一一一一一一一一>>>已经写入文件)
5.6 data_analysis.py
在data_analysis.py中对数据进行可视化操作,用Py-echarts库的Render方法生成html文件并保存在制定的目录之下。首先制作观众地域排行榜单,用Pandas库的Counter.most.common方法获取city列表中用户量前20的城市赋值给data_top20,然后用bar对将要生成的图片格式进行定义。
由图5图可以看出,评论的用户观众深圳最多,达703人,第二是广州660人,第三是北京628人。
制作观众评分排行榜单,同样使用Pandas库的数据操作方法对Dataframe类型的数据进行操作,再用Pvecharts库的语法调用被处理过的数据生成最终图表并由html格式文件展示。如图6所示,评价为5的用户观众为10 353人,远超于其他等级用户,说明《复仇者联盟4》的观众绝大部分都认为它是一部值得观看的好电影。
词云可以显示观众评论中出现评论最高的词汇,如图7所示,评论中出现最多的词有“好看”“剧情”“钢铁”“完美”“精彩”“情怀”“特效”等。由此可以看出,大部分观众对《复仇者联盟4》表达了认同和赞美,说明《复仇者联盟4》是一部值得观看的优质电影。
6 结语
本文基于Pvthon的开源Scrapy框架实现猫眼《复仇者联盟》主题爬虫编写,在编写Spider主文件时对URL构造设计进行改造,找到最优办法解决爬取数据量太少的问题。本文共提取出了有效信息16 664条,比常规爬取数据多出16倍,达到了预期爬取数量和质量。此外,通过编写灵活爬虫,简单有效地垂直爬取主题网站,剔除有用信息提取,在存储和查询方面都大大提速,并且精度更高,信息使用率增高,减少了能量消耗,并通过可视化分析使得爬取结果更加直观;最后利用Scrapy框架,在抓取大量数据方面有显著优势,比普通爬虫动则上万的代码量减少很多,提高了信息利用率。
参考文献:
[1]王岩.搜索引擎中网络爬虫技术的发展[J].电信快报,2008( 10):20-22.
[2] 李小正,成功,赵全军.分布式爬虫系统的设计与实现[J].中国科技信息,2012( 15):116-117.
[3] 管华.对当今Pvthon快速发展的研究与展望[J].信息系统工程,2015( 12):114-116.
[4] 孟庆浩,王晶,沈奇威.基于Heritri的增量式爬虫设计与实现[J].电信技术,2014(9):97-102.
[5] 赵本本,殷旭东,王伟.基于Scrapy的GitHub数据爬虫[J].电子技术与软件工程,2016(6):199-202.
[6] 华云彬,匡芳君.基于Scrapy框架的分布式网络爬虫的研究与实现[J].智能计算机与应用,2018,8(5):46-50.
[7] 丁忠祥,杨彦红,杜彦明.基于Scrapy框架影视信息爬取的设计与实现[J].北京印刷学院学报,2018,26(9):92-97.
[8] 王芳,张睿,龚海瑞.基于Scrapy框架的分布式爬取設计与实现[J].信息技术,2019 (3):96-101.
[9]
KAUSAR M A, DHAJA V S,SINGH S K.Web crawler:a revieW [J].International Journal of Computer Application, 2013, 63(2):31-36.
[10] 刘宇,郑成焕.基于Scrapy的深层网络爬虫研究[J].软件,2017,38(7):111-114.
[11] 王磊,刘晓丹.基于Scrapy的网络爬虫系统框架设计与实现[J].微型电脑应用,2018(7):48-50.
[12] 吕俊宏,周江峰.深入解析Cookie技术[J].数字通信世界,2015(6):332-333.
[13]姜彬彪,黄凯琳,卢昱江,等.基于Python的专业网络爬虫的设计与实现[J].企业科技与发展,2016(8):17-19.
[14] 安子建.基于Scrapy框架的网络爬虫实现与数据抓取分析[D].长春:吉林大学,2017.
[15] 张笑天.分布式爬虫应用中布隆过滤器的研究[D].沈阳:沈阳工业大学,2017.
[16]
CATTELL R Scalahle SQL and NoSQL data store [J]. ACM SIGMODRecord, 2011(2):12-27.
[17] 刘学.分布式多媒体网络爬行系统的设计与研究[D].武汉:华中科技大学,2012.
[18]李代祎,谢丽艳,钱慎一,等.基于Scrapy分布式爬虫系统的设计与实现[J].湖北民族学院学报(自然科学版),2017,35(3): 317-322.
[19] 陶兴海.基于Scrapy框架的网络爬虫模拟登陆网站实现[J].计算机与软件,2017(6):51-51.
[20] 成功,李小正,赵全军.一种网络爬虫系统中URL去重方法的研究[J].中国新技术新产品,2014( 12):23.
(责任编辑:孙娟)
收稿日期:2019-06-04
基金项目:教育部产学协同育人项目(JCH2019003,JCH2019023);福建省高校产学合作项目(2018H6018);福建省教育教学教改项目( FBJC20170154);福建省产学研项目(2018H6018);漳州市自然科学基金项目(222018J26)
作者简介:王海玲(1982-),女,硕士,厦门大学嘉庚学院信息科学与技术学院副教授,研究方向为数据挖掘与数据分析;周志彬(1996-),男,厦门大学嘉庚学院信息科学与技术学院学生,研究方向为数据挖掘。
- 借力教育帮扶,推动学校发展
- 浅谈小学低年级英语“读”与“说”技能的教学策略
- “玩中学”游戏教学在小学特色美术课堂中的应用
- 新时期农村中学德育工作的实践与探究
- 防疫期间居家锻炼的限制与对策浅探
- 构建思维导图,培养学生核心素养
- 提高小学科学实验学生操作能力的研究
- 初中作文教学有效融入生活初探
- 读懂小学生内心世界,践行数学核心素养
- 农村小学音乐课中巧妙渗透乐理知识探析
- 培养小学生课外阅读能力探析
- 基于翻转课堂模式下的小学数学复习课教学探究
- 初中数学教学有效渗透德育初探
- 走近网络,走进心灵
- 新农村小学“小君子、小淑女”培养模式的研究
- 基于学科核心素养下的小学语文主题阅读教学
- 疫情下小学数学网课教学方法探究
- 破译语言秘妙,生长言语智能
- 小学语文课堂中有效实施经典诵读的策略
- 幼儿数学活动中的有效探索
- 小学数学复习课中的有效练习策略
- 小组合作模式下小学低年级语文早读课程整合探究
- 激发学习兴趣,提高小学书法教学质量
- “语义场”理论在高中英语完形填空教学中的应用
- 浅谈广州版牛津初中英语教材中的Project板块的教学
- outdoors/out of doors
- outdrag
- outdragged
- outdragging
- outdrags
- outdrank
- outdraught
- outdream
- outdress
- outdressed
- outdresses
- outdressing
- outdrinking
- outdrinks
- outdriven
- outdrives
- outdriving
- outdrove
- outdrunk
- outduel
- outdueled
- outdueling
- outduelled
- outduelling
- outduels
- 某些动物及肉类的气味
- 某些动物在个体发育过程中的形态变化
- 某些动物在寒冷的冬季休眠
- 某些动物在某阶段不吃不动
- 某些动物头颈上的长毛
- 某些动物的口腔两侧存食的囊状构造
- 某些动物的感觉器官
- 某些动物的硬壳
- 某些动物的羶腥臊臭的气味
- 某些动物脚趾间的簿膜
- 某些动物遇到敌人时,为了保护自己,装成死的样子
- 某些十字花科蔬菜植物的花茎
- 某些单位的名称
- 某些发给凭证的机构
- 某些可饲养的幼小动物
- 某些合成纤维织物
- 某些器官的边缘
- 某些器物的附属部分
- 某些国家政府的首脑
- 某些国家最高权力机关
- 某些国家的元首
- 某些国家的军事政治警察
- 某些国家规定本国所信仰的宗教
- 某些国家高于兵、低于军官的军人
- 某些场面的大致情况