马亚铭 陶利民 刘子琦

摘 要:为了提升电商大数据平台复杂数据操作性能,通过分析电商业务特点,从数据重新组织与平台参数调优两个方面对数据平台进行优化。在数据重新组织方面,使用ORC数据格式存储数据,并对数据表进行合理的分区、分桶;在平台参数调优方面,对业务涉及到的主要组件参数进行针对性调节。最后,通过搭建具有32个节点的Hadoop集群,并使用TPC-DS测试集进行仿真实验,验证调优思路及方法的有效性。结果表明,调优之后的平台性能大约是未进行任何优化平台的7.5倍,优化效果显著。
关键词:大数据平台;电子商务;Hadoop;性能调优
DOI:10. 11907/rjdk. 192524 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2020)005-0186-04
0 引言
电子商务的诞生及发展给人们生活带来了巨大便利,随着电商规模的进一步扩大,电商平台每日会产生海量数据。如何对这些数据进行快速、有效的存储与处理,是保障电商业务顺利开展以及推动其发展的必备条件。Hadoop作为一款优秀的开源大数据平台,被大多数电子商务企业所采用。为了获得更好的数据处理性能,需要根据电子商务业务特点,对该平台进行针对性的性能调优。由于Hadoop的广泛应用,学者们对其调优方法已进行了较多研究。如王康等[1]阐述针对Hive数据仓库的通用调优方法,即对Hive与MapReduce相关参数进行调优;王勇等[2]总结了基于HBase健康大数据平台的多种调优方法等。综合这些调优方法,将其归纳为以下4个方面:①数据重新组织,如数据分区、分桶等;②调节Hadoop平台自身参数,如设置HDFS读写缓存大小等;③采用辅助技术,如数据压缩等;④Hadoop源码调优,可以是改进某种算法或策略等。
然而,针对性能调优的已有研究多为一些通用的或其它场景下的调优,尚没有针对电商平台的调优方法总结。本文根据对工程实践的总结,阐述针对电商大数据平台的性能调优方法。
1 Hadoop平台基本框架
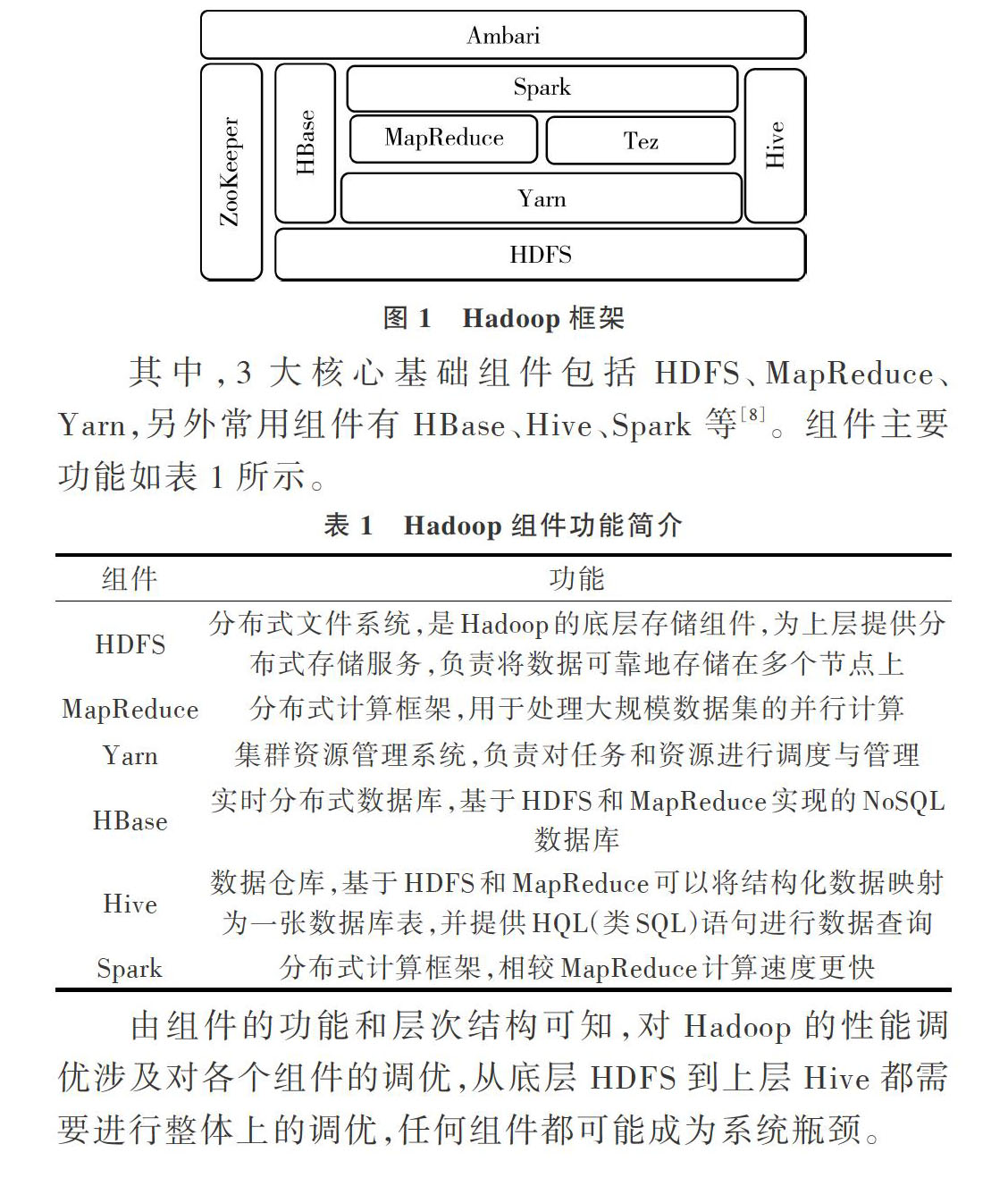
Hadoop是一款基于Java分布式大数据处理与分析的软件框架。用户可在不了解分布式底层细节的情况下开发分布式程序,充分利用集群进行高速运算与存储,解决了大数据的可靠存储与处理问题[3]。Hadoop经过多年发展已演化成一个生态系统,其基本框架如图1所示。
由组件的功能和层次结构可知,对Hadoop的性能调优涉及对各个组件的调优,从底层HDFS到上层Hive都需要进行整体上的调优,任何组件都可能成为系统瓶颈。
2 电商大数据平台调优
电子商务平台是用于支撑商品在互联網上进行交易的平台。其涉及到的主要业务流程包括:①商品信息维护;②订单管理;③销售记录(sales)和退货记录(returns);④仓库(warehouse)库存记录(inventory)维护;⑤CRM客户关系管理(customer、customer_address)等。
在这些业务流程中会经常对一些大表(如商品信息表),进行大量的CRUD(增删改查)操作。针对电商业务流程的数据处理特点,一般从以下两方面进行性能调优,分别为数据重新组织与平台参数调优。
2.1 数据重新组织
对数据进行针对性的重新组织可以提高数据输入的有效性,对数据进行更精准的处理,从而提升系统性能。针对电商大数据平台,主要采取如下措施:
(1)使用ORC 格式。ORC文件格式是一种Hadoop生态圈中的列式存储格式,有多种文件压缩方式,并且有着很高的压缩比。其提供row group index、bloom filter index等多种索引,而且文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以节省HDFS存储资源,查询任务的输入数据量也大幅减少[4]。同时ORC通过压缩、分片并逐段记录中间结果的方式提高数据块管理能力,能有效提高数据读取效率[4]。
在电商数据存储中,如果继续使用传统行式存储对诸如订单表、商品表等这些庞大的数据表进行管理,查询效率会非常低。若依靠索引优化查询,由于数据量的庞大,建立与维护索引的代价都非常大。由于ORC格式具有的上述特性,将电商平台的相关数据以ORC格式加以组织,可大大提升数据操作速度。
(2)数据表分区分桶。分区、分桶可以减少扫描成本,在一定程度上提高查询效率。由电商业务模型及数据模型可知,随着交易规模的扩大,将会产生很多数据量庞大的大表(几十个TB以上),而日常业务流程中又需要对这些大表进行频繁的查询操作。因此,针对业务的数据操作特点进行适当的分区、分桶,可提高数据操作速度。
在确定分区、分桶字段时,不仅要关注该字段是否常被用于查询,还需要关注该字段值数量等综合因素。例如,在电商业务流程中,经常需要根据商品名称进行商品信息查询,但若根据商品名称这一字段进行分桶,亿级的商品数将会对应亿级数量的桶文件,显然是不可行的。因此,根据商品分类或地区等信息进行分桶,也可以有效提高查询效率。
2.2 平台参数调优
电商平台管理的数据类型主要是一些结构化数据,数据操作大多是SQL型操作,因此调节参数主要涉及到的Hadoop平台组件有Yarn、Hive和Spark。其中每一个组件都有大量系统参数,本文只列举一些重要的、对电商数据平台性能有较大影响的参数,并对这些参数进行分析与调优。
2.2.1 Yarn
(1)yarn.nodemanager.vmem-pmem-ratio:该参数是虚拟内存与物理内存的比率,默认值为2.1。增大该参数可以起到增大虚拟内存的作用,以避免Yarn的Container内存不足。因此,在存储空间足够的情况下,可根据实际物理资源及任务特点适当增大该参数的值,以保证yarn有足够的内存空间可以使用。
(2)yarn.nodemanager.resource.percentage-physical-cpu
-limit:该参数是对NodeManager管理下所有Container可使用CPU资源的限制。在电商数据平台场景下,本文仅考虑怎样达到最优性能。一般允许yarn完全使用CPU资源,即该参数值为100%。
(3)yarn.nodemanager.resource.memory-mb:该参数用于指定yarn可以管理的最大内存容量。在电商场景下,除预留给系统其它进程的内存外,应尽量多地将内存交给yarn进行管理,使yarn可用内存资源最大化。
2.2.2 Hive
(1)hive.exec.dynamic.partition.mode:该参数表示是否允许自动分区。自动分区会自动根据分区字段所有值进行分区。在电商场景下会对多个大表进行分区,并且随着系统的使用,多数分区字段的值会增加或减少。如以商品表的类别字段进行分区,随着业务的扩展与变化,商品类别会增多或减少。采用手动分区方法会非常低效,因此在电商场景下,该字段一般设为nonstrict,表示允许自动分区。
(2)hive.exec.max.dynamic.partitions:该参数表示动态分区的上限。虽然可以利用该参数解决在动态分区时因分区过多造成系统奔溃的情况,但考虑到分区目的是为了加快数据读写,不应该让最大分区数限制实际需要进行的分区,因此一般设置一个足够满足分区要求的数量,并要求选择合理的字段进行分区。
(3)hive.exec.max.created.files:该参数表示一个MapReduce作业能创建的HDFS文件最大数,一般不会让其成为MR作业的限制,而是要让作业本身在系统能力范围内。因此,会设置一个较大的值,默认为100 000。
(4)hive.optimize.sort.dynamic.partition:该参数会对需要写入的数据进行排序,目的是使每次只对一个分区进行写入操作,写入完毕后,再打开下一个分区进行集中写入。
由于在电商业务场景中分区数较多,如果对某个表进行写入时,同时打开这些分区,将占用过多内存,因此该参数一般设为true。
2.2.3 Spark
(1)spark.serializer:spark在进行内存计算时,需要对一些中间结果进行序列化与反序列化,此时需要用到序列化框架。KryoSerializer具有速度快、序列化后体积小等优点,故序列化器一般配置为KryoSerializer。
(2)spark.memory.fraction:调整该参数可以控制spark的shuffle内存和storage内存总量占总内存的比例。需要根据任务类型保证shuffle过程有足够的内存, 同时也要预留一些内存给spark其它功能以及系统软件使用。
(3)spark.memory.storageFraction:该参数调节storage内存所占比例,与参数(2)一起确定shuffle和storage各占内存的比例。可以根据任务类型及表的多少,合理调整该值,增大shuffle内存比例,缩小storage内存比例。因为shuffle过程直接影响计算任务完成速度,shuffle内存应尽量保证每个任务的使用。可以通过监控日志及运行结果发现shuffle过程所需内存,从而对该参数进行调节。
(4)spark.sql.shuffle.partitions:该参数用于确定shuffle过程的partition个数。适当增加partition个数可以增大并行度,提高系统运行效率。
3 实验验证
3.1 实验环境与方法
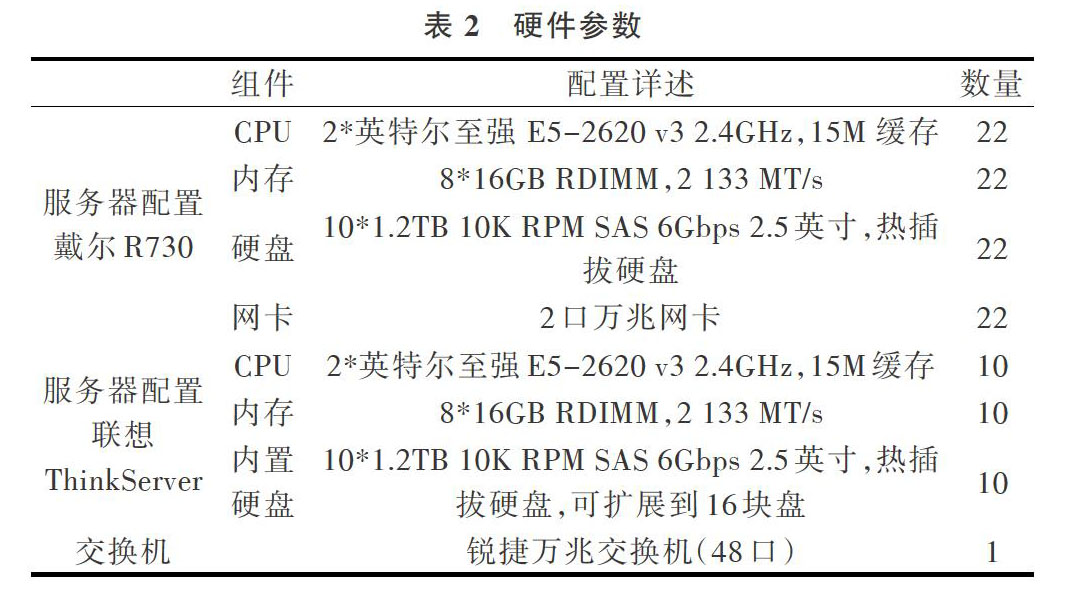
为了验证针对电商大数据平台性能调优的有效性,本文搭建了Hadoop集群。实验环境共有32个节点,详细配置如表2所示。
为了模拟电商日常业务,本文采用TPC-DS相关数据集[5]。该数据集可模拟某在线零售商日常业务数据,基本符合电商业务场景。数据集共包含24张表,这里只列举主要的7张大表,如表4所示。
同时TPC-DS使用99个SQL语句,以模拟零售商日常各种业务流程,本文从中选取10个有代表性的SQL测试平台性能。这10个SQL包含了复杂条件下的库存查询与销售记录查询、销售总额与平均销售额统计计算等,基本涵盖了电商主要业务流程。
3.2 实验过程及结果分析
首先在平台中生成TPC-DS数据集中的数据(本次实验数据总量共30TB),在不进行调优的情况下(在系统默认配置下)使用选择的10个SQL进行数据操作,接着对系统按上文方法进行调优,即数据重新组织与平台参数调节。
将数据格式重新组织成ORC格式,然后进行分区、分桶。根据分析,主要針对几个大表(store_sales、catalog_sales、web_sales、inventory)进行数据组织的优化,根据产品经销存的日常模型综合评估可行性,最终分区分桶方案如表5所示。
从实验结果综合来看,按照本文描述的针对电商大数据平台的调优思路与方法,大大减少了对海量数据的操作与分析时间,显著提升了数据平台性能。
4 结语
本文总结了针对基于Hadoop的电商大数据平台的一般调优思路与方法。系统调优是对系统各方面进行优化的过程,本文仅总结了基础的、有明显提升效果的两种调优方法:数据重新组织和平台参数调优,并通过搭建Hadoop集群,以及使用TPC-DS标准测试集进行仿真实验,结果验证了调优的有效性,调优后的平台性能得到显著提升。本文平台参数主要是依据参数本身的作用,以及结合实践经验,通过手动调节及试验完成调优的。寻求参数最优化有很多算法可以实现,如遗传算法、粒子群算法(PSO)等,可帮助人们寻找参数最优解,避免手动调优的盲目性。
参考文献:
[1] 王康,陈海光,李东静. 基于Hive的性能优化研究[J]. 上海师范大学学报(自然科学版),2017(46):534.
[2] 王勇,尹鹏飞,李娟. 基于HBase的健康大数据平台性能优化及应用[J]. 软件导刊,2017(10):150-153,162.
[3] 许吴环,顾潇华. 大数据处理平台比较研究[J]. 软件导刊,2017(4):212-214.
[4] 曹英. 大数据环境下Hadoop性能优化的研究[D]. 大连:大连海事大学, 2013.
[5] YERUVA S,KUMAR P V,PADMANABHAM P. Distributed data warehouse-experimentation with TPC-DS[C].2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC). IEEE, 2015.
[6] 姜春宇,魏凯. 大数据平台的基础能力和性能测试[J]. 大数据, 2017(4):43-51.
[7] 詹剑锋,高婉铃,王磊,等. BigDataBench:开源的大数据系统评测基准[J]. 计算机学报,2016(1):196-211.
[8] 倪宁. 大数据时代下电子商务平台的探索和研究——以淘宝网为例[J]. 江苏商论,2014(5):13-14.
[9] LIU B,MENG X,SHI Y. CloudBM: a benchmark for cloud data management systems[J]. Journal of Frontiers of Computer Science and Technology, 2012, 6(6): 504-512.
[10] 陈娜,张金娟,刘智琼,等. 基于Hadoop平台的电信大数据入库及查询性能优化研究[J]. 移动通信, 2014(7):58-63.
[11] 杨浩. Hadoop平台性能优化的研究与实现[D].成都:西南交通大学,2015.
[12] 张新玲, 颜秉珩. Hadoop平台基准性能测试研究[J]. 软件导刊, 2015(1):30-32.
[13] SINGH S,GARG R,MISHRA P K. Performance optimization of MapReduce-based apriori algorithm on Hadoop cluster[J]. Computers & Electrical Engineering, 2017:S0045790617308534.
[14] 刘娟, 豆育升, 何晨, 等. 基于调度器的Hadoop性能优化方法研究[J]. 计算机工程与设计,2013(1):198-202.
[15] 连加典,刘宏立, 谢海波,等. 基于預测机制的分级负载均衡算法[J]. 计算机工程与应用,2015,51(11):67-71.
[16] 董新华,李瑞轩,周湾湾,等. Hadoop系统性能优化与功能增强综述[J]. 计算机研究与发展, 2013, 50(S2):1-15.
[17] 高莉莎, 刘正涛, 应毅. 基于应用程序的MapReduce性能优化[J]. 计算机技术与发展, 2015(7):102-105,112.
[18] TOM W. Hadoop权威指南(中文版)[M].北京:清华大学出版社, 2010.
(责任编辑:黄 健)
- 黑龙江民间艺术文化传播的保护与传承
- 论全媒体时代国际新闻传播人才的创新培养
- 浅谈融媒时代法治类纸媒如何发展壮大
- 回归自然:文艺作品播音中的情感把握
- 《河南能源报》
- 网络传播下地方主流媒体的坚守与突围
- 2017年度中国网络视频满意度调查报告
- 敢于创新谦逊低调立德树人
- 是老师,更是朋友
- 互联网媒介视角下的华莱坞电影产业研究
- 华莱坞小妞电影类型的多元化建构
- 回归心灵原乡:华莱坞电影生态意识扫描
- 不只是电影
- 技术赋权:受者接受信息的议程选择权挑战传者议程设置权
- 论中俄媒介集团合作内容、目标与路径
- 媒介进化定律的历史解码
- 新媒体语境演变下当代中国画创新的变与不变
- 浅述当代景观设计与新媒体艺术的交互融合
- 跨文化传播视域下BBC纪录片《中国老师来 了》透视
- 殖民欲望浸透的晚清军事形象
- 于大申的报人生涯
- 河南省科普信息传播现状及问题分析
- “暖新闻”的正确“打开方式”探析
- 共享信息时代新闻出版品牌社群传播研究
- 传播学视野下大型山水实景演出的时代反思
- flung
- flunk
- flunked
- flunkers
- flunkey
- flunkey, flunky
- flunkeyiana
- flunkeyisms
- flunkey's
- flunkeys
- flunking
- flunk out
- flunk-out
- flunks
- flunky
- fluorescence
- fluorescent
- fluorescently
- fluorescents
- fluoride
- fluorides
- fluorine
- fluorines
- flurriedly
- flurries
- 逃避工作、责任或义务的人
- 逃避征兵
- 逃避徭役
- 逃避或抗交租税
- 逃避推卸罪责
- 逃避时世
- 逃避暑热
- 逃避灾荒
- 逃避灾难
- 逃避灾难、祸害
- 逃避狱吏的追捕
- 逃避现实
- 逃避稽查
- 逃避罪责
- 逃避职事
- 逃避荣禄
- 逃避诛罚
- 逃避谗害
- 逃避责任
- 逃避赋税
- 逃避追逐
- 逃避隐瞒
- 逃避隐藏
- 逃避,躲避
- 逃门