陈磊磊


摘要:近年来,互联网和电子商务企业堆积了海量文本文档类型的数据,如何通过有效的手段对这些数据进行整理,并进行真正有质量的数据挖掘已经成为计算机科学关注的焦点。本文对文本数据之间的相似性进行了研究,并采用VSM技术和TF-IDF加权策略对文本文档进行了预处理。然后,采用不同测度距离作为相似性度量对数据进行了K-Means聚类实验,并对实验结果进行分析和总结。最后基于之前的结论,在改善文本聚类质量方面,做出了一定的探索。
关键词:文本聚类;K-Means;测度距离;聚类质量
中图分类号:TP311.1
文献标识码:A
0 引言
聚类(Clustering)是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。简而言之,聚类的结果是样本数据对象构成的多个类或簇(cluster),一个簇中的对象有较高的相似度(similarity),而不同簇中的对象差异较大,而这种相似度通常通过距离来度量。
文本聚类(Text Clustering)主要是依据著名假设:同类的文档相似度较大,不同类文档相似度较小,其结果是将文档集合分为若干个簇。整个聚类过程无需指导,事先对数据结构未知,是一种典型的无监督机器学习问题。文本聚类在搜索引擎返回结果聚类,信息过滤和推荐,图书馆文档分类,文档自动整理等方面都发挥着重要的作用。
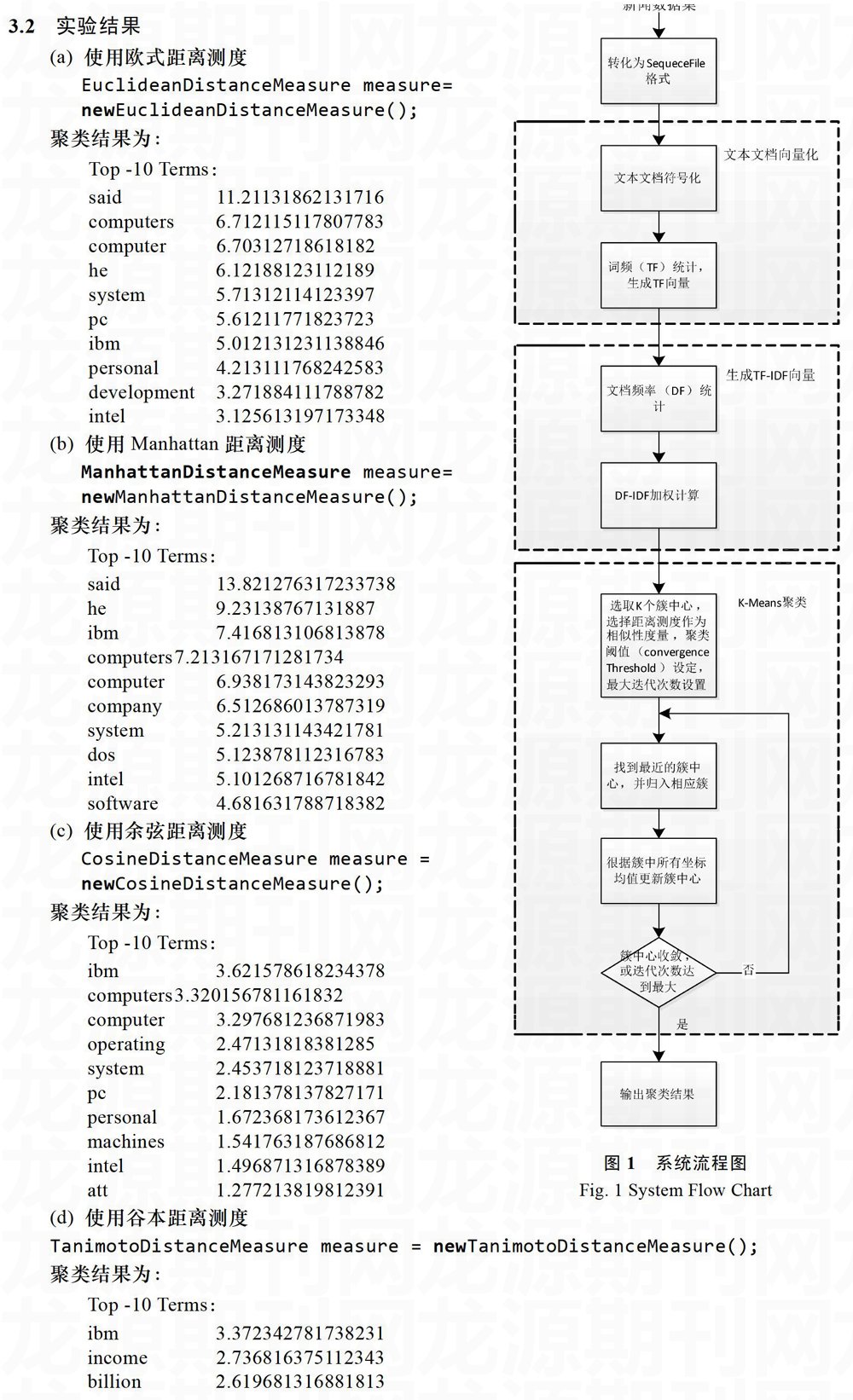
本文首先对文本预处理的过程进行了介绍;然后对K-Means算法及该算法在相似性度量方法进行了研究;之后,在Mahout计算框架下,以不同距离测度作为相似度测量方法,使用Reuters-21578新闻数据集进行了K-Means聚类算法实验,并对结果分析和总结;最后,在针对具体数据集的聚类质量的改善方向做了一定的探索。
1 文本预处理
1.1文本相似性度量
聚类的关键在于寻找一个可以量化两个数据对象之间相似性的函数。对于文本文档,一种可能的度量方法是两篇文档中相同词的数量。因此,可以收集每篇文档中的词频,如果文档的词汇交集中很多单词的词频数比较接近,那么可以断定这些文档是相似的。基于这种思想,可以对所有的文本文档进行聚类。
1.2文本文档向量化
为了将文档数据转化为计算机能够读取的记录,需要以单词作为文本文档对象的特征将其映射到数字并表示为向量(vector)形式。这种将特征编码为向量的过程称为向量化。
VSM(Vector Space Model,向量空间模型)是向量化文本文档的常用方法。给定一个这些被向量化的文本文档全部单词的集合,集合中的单词在任意某个文档中出现过一次。给每个单词分配一个编号,此编号便是它在文档向量中所拥有的维度。维度最大的可能数就是文档向量的基数(eardinality),文档向量常被认为有无限维度。
文档向量形式仅仅包含每个单词在文档中出现的次数,并且这个数值会依次存储在各个单词所在的维度上,这个数值通常被称为TF(Term Frequency,词频)权重。
在进行聚类时,我们常常基于距离测度来计算两个文档的相似性。但是在大多数文档中,最频繁的词往往是a、the、that、is、are等,这类词称为停用词(stopword)。无论用什么距离测度,聚类结果往往会被这些频繁词的权重所左右。因此我们可以采用改进的加权方法来修复这些缺陷。
1.3TF-IDF加权策略
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档)是一种用于资讯检索与文本挖掘的常用加权技术。文档向量中的值不再是简单的词频,而是词频乘以文档频率的倒数,也就是逆文档频率(IDF)。也就是说,一个单词在所有文档中越是频繁出现,那么它的作用就越小。
文档频率(DF)是有这个单词出现的文档个数。假设单词wi的文档频率为DFi逆文档频率IDFi为:
IDFi=1/DFi
如果一个单词在文档中频繁出现,则其IDF值可能会太小,导致文档向量中单词的权重值过小。对此,一般乘以一个常数,通常是文档(N)个数来归一化IDF值。所以IDF公式改为:
DFi=N/DFi
因此,在文档向量中,单词wi的权重Wi为:
Wi=TFi*IDFi=TFi*N/DFi
上面公式中IDF值仍然不够好,单词词频(TF)在权重中重要性不够明显。因此,通常的做法是对IDF值取对数:
IDFi=log(N/DFi)
综上所述,对于单词wi,TF-IDF权重Wi为:
Wi=TFi*log(N/DFi)
所以,文档向量中,单词对应维度上的值就是上述权重。这样加权的结果就是,停用词的权重小,罕见词的权重大。因此,通常来说,当一个单词有很大TF值和较大IDF值时,它会被认为是文档中的重要单词或主题词。
2 K-Means算法
2.1算法思想
K-Means(K均值)算法是一种通用的聚类算法,可以很容易的运用于大部分的场合。K-Means算法重要采用一种迭代的思想,其具体算法思想如下:
假设有n个点,需要聚成k个簇。选择k个点作为簇的中心点,然后算法进行多次迭代处理并调整中心点位置,直到最大迭代次数,或者中心收敛于固定的点不在移动。
每次迭代分为两步骤。第一步,找到距离中心最近的点,并将这些数据点赋给相应的簇。第二部,试着用各簇中所有点的坐标均值更新中心位置。
算法过程如下,
(1)从n个文档随机选取k个文档作为中心点
(2)对剩余的每个文档测量其到每个中心点的距离,并把它归到最近的中心点的簇
(3)重新计算已经得到的各个簇的中心点心
(4)迭代2~3步直至新的中心点与原中心点相等或小于指定阈值,算法结束
结果显示,在此距离测度下,聚类质量有所提升,但是仍然存在said这样的常见词汇。因此,我们永远不可能找到完美的簇,只有通过寻找更合适的技术来接近它。
5 结论
本文对文本文档类型的Reuters-21578新闻数据集,采用欧式距离测度、曼哈顿距离测度、余弦距离测度和谷本距离测度进行了K-Means进行了聚类实验。从实验结果中的分析比较得出结论,余弦距离测度更适合作为文本文档聚类的相似性度量。然后,探讨了影响聚类质量的几个重要因素。然后,基于之前实验的结论编写了自定义余弦距离测度方法,对文本聚类质量进行了科学有效的改善。总之,对于具体的数据集,应该多方面权衡,来寻求适合它的相似性度量方法。
- 浅析我国现行个人所得税反避税规则体系
- 完善员工激励机制 推动企业高质量发展
- 事业单位财务管理存在的问题及对策探讨
- 我国政府会计制度变迁问题研究
- 农村电网改造中配电工程施工的管理分析
- 浅谈人力资源管理发展趋势
- 事业单位会计改革的实践创新与现实意义
- 低碳旅游理念在酒店管理中的运用策略
- 企业金融会计的风险因素及合理化防范对策
- 大数据时代下企业人力资源管理变革研究
- 浅析其他综合收益
- 电力营销计量智能表的功能应用及改进
- 营改增对建筑企业集团的影响研究及应对建议
- 基于新形势下企业经济管理的创新方法
- 互联网+背景下增进收银审核绩效的合理化思路构建
- 互联网+时代下的企业人力资源管理新趋势初探
- 探讨高速公路服务区经营管理模式
- 试论企业应收账款的信用风险管理
- 提高县城电网供电可靠性的思路
- 大数据时代人力资源绩效管理的创新和发展
- 企业会计核算规范化管理措施研究
- 新会计制度下财务管理模式探究
- 生产型企业成本核算方法与核算管理研究
- 试论基于信息化环境下的企业会计核算模式
- 谈提高企业财务预算管理有效性的措施
- welloff
- well off for
- well-oiled machine
- well-operated
- well-ordered
- well-organized
- well-oriented
- well-outlined
- well-packed
- well paid
- well-paid
- well-paid/highly paid
- well-paired
- well-paragraphed
- well-parked
- well-patched
- well-patrolled
- well-patronized
- well-pensioned
- well-peopled
- well-perceived
- well-performed
- well-persuaded
- well-photographed
- well-piloted
- 品格非同凡俗
- 品格骨气
- 品格高尚,不受恶劣环境的影响
- 品格高尚,胸襟开阔
- 品格高尚,节操坚贞
- 品格高洁
- 品格高洁坚贞
- 品格高洁,志向高远的人
- 品格,格调
- 品概
- 品次
- 品流
- 品牌
- 品牌作者
- 品牌机
- 品牌计划
- 品物
- 品玉
- 品玩
- 品画
- 品目
- 品相
- 品种
- 品种、质量、成绩、作风等十分好
- 品种式样