陈若飞+姜文红
摘要:作为开源云计算平台的核心技术之一,MapReduce作业处理框架及其作业调度算法,对整个系统的性能起着至关重要的作用,而数据本地性是衡量作业调度算法好坏的一个重要标准,首先本文介绍和分析了MapReduce基本原理,MapReduce作业处理机制和MapReduce作业调度机制及其在数据本地性方面表现出的优缺点等相关内容。其次,针对原生作业调度算法在数据本地性考虑不周全的问题,结合数据预取技术的可行性与优势,通过引入资源预取技术设计并实现一种基于资源预取的Hadoop MapReduce作业调度算法,使作业执行效率更高。
关键词:云计算;Hadoop;MapReduce;作业调度;数据本地性;资源预取
中图分类号:TP393 文献标识码:A DOI:10.3969/j.issn.1003-6970.2015.02.014
0 引言
云计算作为一种新型的商业计算模式,是分布式并行处理和网格计算等多种技术的拓展和延伸,代表了当前并行计算技术发展的新阶段。资源调度作为云计算技术的一个重要组成部分,其效率直接影响整个云计算环境的工作性能。而数据本地性是衡量作业调度算法好坏的一个重要标准。
最早的Hadoop版本主要是单用户提交的批处理任务服务,其调度算法采用先进先出(FIFO,First InFirst Out),作为Hadoop默认作业调度器一直沿用至今。它具有简明和易于实现等优点,它主要适用于单个用户提交同一类型的作业。FIFO不会以用户为中心为多个用户提交的多种类型的作业实现合理的安排,这将导致集群整体性能及系统资源利用率低下,甚至造成阻塞。针对FIFO缺陷的第一个尝试解决方案为HOD(Hadoop On Demand),相比于FIFO,HOD对用户提交的小作业响应更快,多个用户提交作业时等待时间大大缩短。然而HOD数据本地性较差,资源利用率低下。Yahoo和Facebook在使用Hadoop的过程中各自针对FIFO的缺陷提出了计算能力调度算法(Capacity Scheduling)和公平调度算法(Fair Scheduling)。但是这两种算法都存在数据本地性和推测执行的问题。
数据预取已经是一种公认的隐藏由缓存丢失引起的数据访问延迟的有效方法,今年也有人用于改进Hadoop作业调度算法中,如Jiong Xie等人利用数据预取技术将任务的输入数据在调度之前从计算节点的磁盘预取到内存中,这样节省了任务执行时读取数据的时间,从而减少作业的响应时间。这虽然较大程度上提高了任务的执行效率,缩短了执行时间,但是并没有对数据本地性进行考虑。王涛等人提出的一种相对于用户访问任务的文件预取与合并算法,Sangwon等人为解决多用户在HOD上共享集群资源时不能保证数据本地性的缺点而提出了基于资源预取和预洗牌的调度策略HPMP,然而,HPMP的首要目标是保证机架本地性而不是节点本地性,虽然对HOD来说数据本地性问题有较大的改善,而对于原生Hadoop来说并不适用。
综上所述,近年来,已经有一些研究者对Hadoop作业调度中的数据本地性问题进行了相应的研究与探索,但是大多数考虑不全面,还有待进一步研究与发展。
针对以上问题引入了资源预取的概念,本文提出基于资源预取的调度算法,先预选出待预取资源的候选节点,然后预选出待预取的非本地map任务,最后进行资源的预取,这样可以保证非本地map任务不用等待即可分配到其存有输入数据的节点,提高数据本地性。本文通过改进Hadoop0.20.2版本上实现改进算法,与Hadoop原有三种作业调度算法进行对比,实验结果表明改进算法可以保证更好的本地性,从而有效的提高了系统资源利用率。
1 基于资源预取的调度算法
该算法主要包括三个大的步骤:预选节点、预选任务和预取资源。由于当前普遍认为reduce任务不存在数据本地性问题,这里仅考虑map任务。
1.1 预选TT
一般在Hadoop中,不会有这一步,JobTracker与TaskTracker之间采用了pull通信模型,这种模型,JobTracker不会主动与TaskTracker进行通信,而总是被动的等待TaskTracker汇报信息并领取相应的命令,TaskTracker可以定时的向JobTracker发送心跳信息,当从节点TaskTracker中有空闲slot时,就会向JobTracker发送心跳信息,当然这里预选TT时,当进行轮询,正好这个从节点有空闲计算槽(slots)时,就把这个空闲节点加入预选队伍中,这是第一种情况,这种情况比较简单。另一种是轮询到的这个节点没有空闲计算槽(slots),这时就需要对这个节点进行判断,判断条件主要是该节点释放计算槽(slots)的快慢程度,也就是正在执行计算槽(slots)中的任务执行的快慢程度,当前任务执行快的节点最有可能释放忙碌槽(slots)。这种情况下还需要考虑一个问题就是,进行资源预取的时候,能否保证当前正在运行的任务结束之前就完成预取,如果不能,就没必要进行数据的预取,因为这样反而浪费系统的资源,而得不偿失,因此需要进行条件的判断,根据任务执行的进度和任务已执行的任务量的大小,计算还需要多少剩余时间完成该任务,将这个时间与在TaskTracker间传输一个数据块的时间进行比较,才能确定是否能将次节点作为候选的节点。这是第二种情况,以下是该算法的大致流程。
步骤1 计算TT(TaskTracker)上正在执行任务的剩余执行时间。首先要先计算对于任意一个任务T,它的任务进度增长率记为progressRate(T),计算方法如式(1)所示:
progressRate(T)=progress(T)/(currentTime-dispatchTime(T)) (1)
其中progress(T)是当前任务执行进度,currentTime为系统当前时间,dispatchTime(T)为任务T被调度的时间。
则可以估算出一个任务的剩余时间记为timeLeft,如式(2)所示:
timeLeft=(1-progress(T))/progressRate(T)) (2)
任务的剩余时间可以由任务进度增长率评估。
步骤2计算Hadoop在TT(TaskTracker)之间传输一个数据块所需要的时间,在Hadoop中,一般的,Hadoop文件块大小是固定的,一般设置为64M,则数据块间传输数据所用时间记为timePerBlock,如式(2)所示:
timePerBlock=lockSize/tranRate (3)
blockSize一般为64M,tranRate为集群网络的理论传输速率一般为100Mbps.
步骤3 进行比较,选取节点,当心跳轮询到该节点时,判断该节点上正在运行的任务中有剩余完成的时间大于传输一个数据块所需时间的map任务,如果有,则把该节点加入预选队列中,因为这样可以再该任务完成之前可以进行数据预取。如果存在timeLeft>timePerBlock任务的节点,则把该计算节点加入candidateTTs集合中,反之,退出本次预取操作。
然后,为了从预选队列中预选节点,需要对此队列进行排序,按照相差时间的多少由小到大进行排序。已排好序的队列会每隔一个心跳更新一次,以保证预选节点的时间有效性。
1.2 预选作业任务
上面一节确定了候选计算节点集合,这一节将介绍预选作业任务,这是因为每个map任务所处理的数据块不一样,所以还需要预选出待预取的map任务,在确定map任务之后,才可知道所需要预取的数据块,完成相应的预取工作,而应该向正在运行的作业中选出未运行的任务作为待预取的作业任务。
本文所提出的调度算法,是从上边确定的候选计算节点选出一个节点,从正在运行的作业中选出关于此节点的非本地任务。而Hadoop传统的调度算法则是如果TaskTracker有空闲节点,会向JobTracker发送心跳信息,此时JobTracker会通知调度器调度任务,调度正在运行的相对于此节点数据本地性选出待分配的map任务,对这个map任务进行资源预取操作,因为要考虑到数据块间的资源预取操作也会消耗一定的系统资源,所以从候选节点中选取一个节点即可,这样可以减少一下系统资源。
在选择该任务的时候,和传统的Hadoop调度策略任务选择策略的基本步骤类似。但只需考虑失败任务和未运行的任务即可,其基本流程如下所示。
步骤1 选取要进行数据间预取的候选节点targetTT,读取最近更新的候选列表,选取排名靠前的TaskTracker,即任务的剩余时间最小且在完成任务之前有充足的时间完成预取的计算节点。
步骤2 选取任务,对于正在运行的作业,首先要选取失败的任务failedMaps,因为失败的任务在作业中是有最高优先级的。如果failedMaps不为空,则从列表中选取一个失败次数最多的任务,这个任务相对于上一个步骤选取出的targetTT的数据本地性进行筛选。如果该任务为node-local,则整个算法结束,反之,如果不是node-local,则把该任务加入到任务中,记为toPrefetchMap。
步骤3 如果toPrefetchMap仍然为空,则在该作业中没有运行的任务nonRunningMapCache中进行选择,如果nonRunningCache不为空,则按照选取出的targetTT的数据本地性进行任务的选择,如果nonRunningCache存在node-local任务,则整个算法结束。反之若nonRunningCache不存在node-local任务,则从中按照优先级选择一个rack-local的任务加入到toPrefeteheMap。
本次作业任务的选择已经完成,如果该算法没有结束,则可进行下一步进行数据块间的资源预选操作。
1.3 数据块间资源的预取
本节主要详细介绍数据块间的资源预取,在步骤1中选择出待预取的节点,在步骤2中选择出待预取的任务,而在这一节根据待预取的任务的元数据信息,在待预取的节点targetTT上为待预取的map任务预取数据块。
根据待预取的map任务的元数据信息,还有一定的策略,能够确定待预取资源所在的源节点。因为输入的数据会被分为多个分片split,默认每个分片split为64M。每个map任务对应一个数据块,每个数据块对应一个数据分片split,每个数据分片又有3个副本,而这三个副本又按照一定的策略分布在一定的机器节点上,首先一个副本分布在同机器的一个节点上,第二个副本在同机架的另一台机器上,第三个副本在不同机架的一台机器上,所以要预取资源,应该选择与targetTT最近的机器节点的数据分片进行预取。算法流程如下。
步骤1 确定源节点集合sourceTTs,从toPretchMap中的TasklnProgress类中读取出任务所需数据的位置信息,这些位置信息组成源节点的集合,以便按照一定的策略选取出一个合适的源节点进行预取。
步骤2 选择一个源节点,根据Hadoop集群conf目录下的topology.data文件,获取Hadoop集群的网络拓扑信息,可以知道源节点集合中的节点与targetTT的距离,选取距离targetTT最近的源节点,记为sourceTT,那么怎样衡量两节点之间的距离,这里比较简单,如果两个节点是同一个节点,距离记为0;如果两个节点位于相同机架,距离记为2;如果两个节点位于相同数据中心的不同机架,距离记为4;如果两个节点位于不同的数据中心,记为6。
步骤3 在步骤2中选取一个合适的源节点soureeTT,将待预取的map任务所需数据从soureeTT传输到targetTT节点上。
步骤4 更新主节点上的元信息文件,在当前map任务出现空闲计算槽(slots),发送”心跳”给主节点请求新的任务,即toPrefetchMap。
2 实验及结果分析
实验测试环境由4台普通PC机组建而成,所使用的Hadoop版本为0.20.2,配置1个JobTracker节点,3个TaskTracker节点。
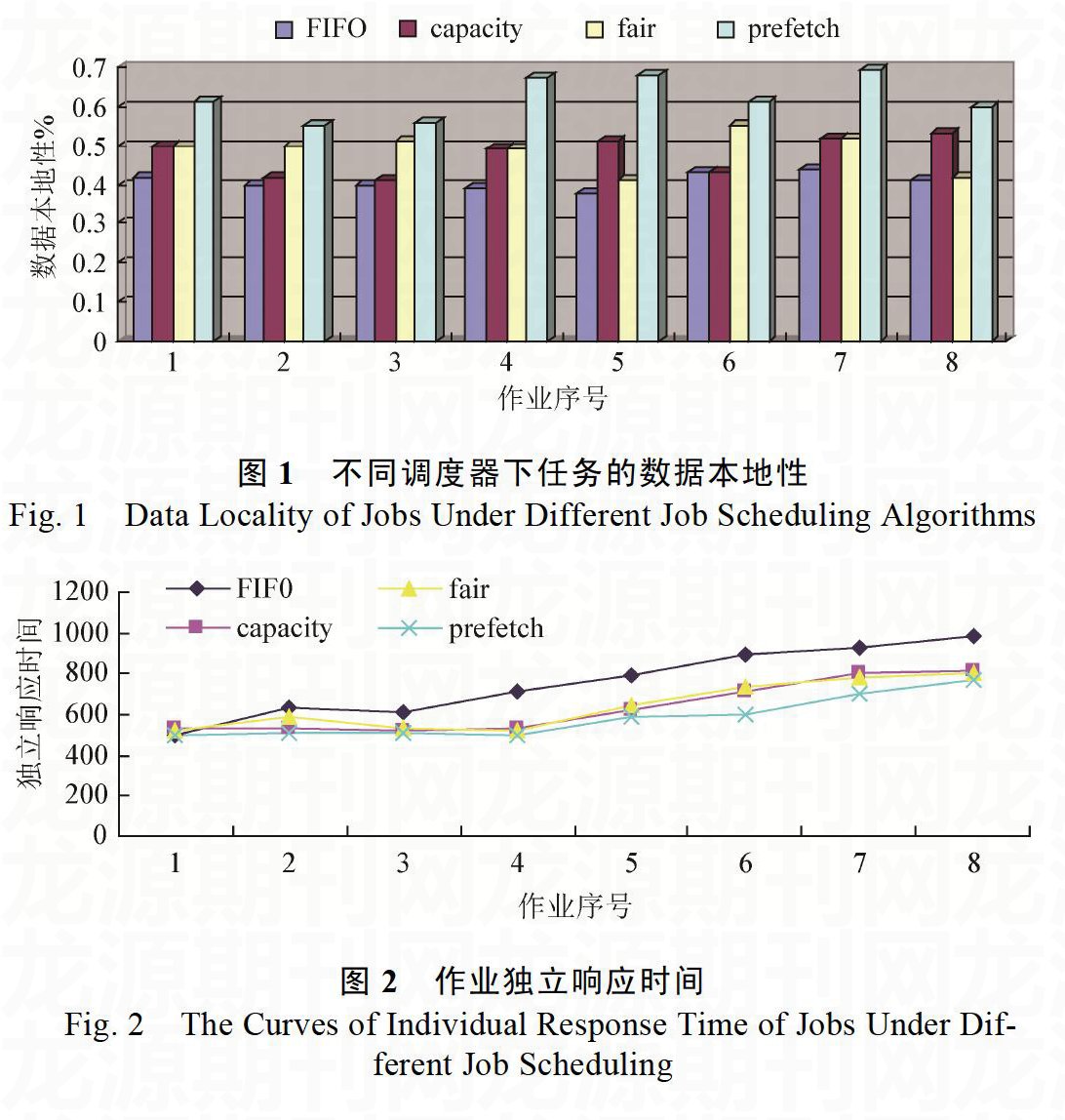
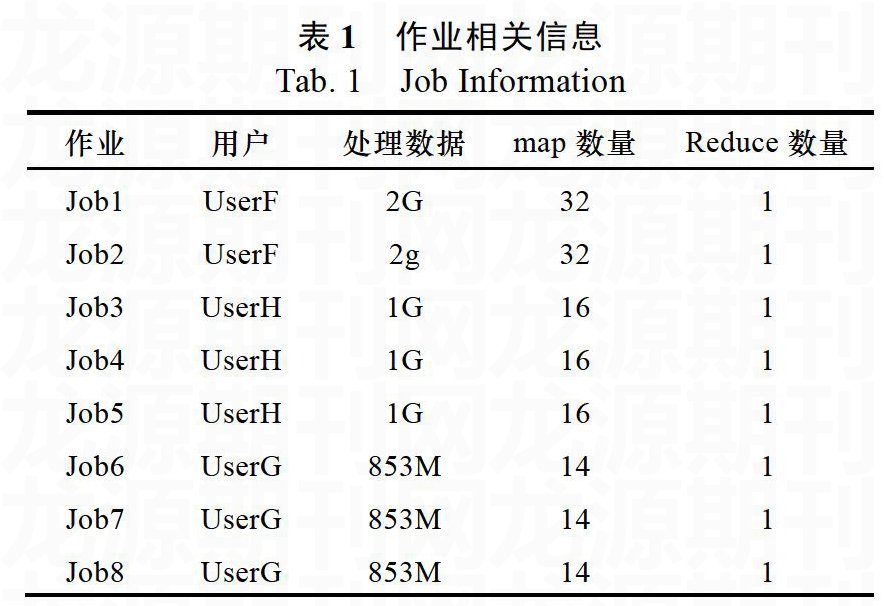
实验过程主要为在实验集群上分别配置使用改进后的调度器与Hadoop原有的三个调度器,实验场景为三个不同用户(userF,userH,userG)同时提交作业。对于改进后的调度器和计算能力调度器,配置为一个用户对应一个队列。采用常用的WordCount作为测试程序,每个用户提交情况如表1所示。试验中对调度算法的度量主要为数据本地性和作业响应时间。前者可通过观察已完成作业的日志,统计其本地性任务占总任务数的比例得到,后者也可通过已完成作业的日志获取。
依次在Hadoop实验集群上配置使用以上提到的4个不同的调度器,按相同方式、相同顺序提交表1的所有作业,观察其运行结果,并进行统计分析得出如下结果。
数据本地性
如图1所示,相同的实验场景下,Hadoop原有的三种调度算法在任务本地性上表现相差不是很大,均保持在40%-50%,这是由于这三种调度算法在任务级调度阶段采用的策略基本相同,仅简单比较任务是否为本地,结果表明这并不能保证良好的数据本地性。而改进后的调度算法,由于在任务级调度策略进行了响应的改进,相比于Hadoop原有的调度算法,对任务的数据本地性均有较大的改善。通过引入资源预取策略可以对任务的数据本地性提升15%-20%不等,平均可提升17%左右。
作业响应时间如图2所示,改进后的作业调度算法,其作业响应时间基本与计算能力调度算法保持相当,但是由于资源预取减少了非本地任务等待本地节点出现的时间,作业的响应时间仍有响应的减少。这也说明资源预取可以改善的不仅只有map任务的数据本地性,还可以减少作业响应时间。
综上所述,通过在小型Hadoop实验集群上的模拟实验表明,相对于Hadoop原有作业调度算法来说,改进后的调度算法不仅在一定程度上提升了任务的数据本地性,也响应地减少了作业的响应时间,从而证明的该改进思想的可行性与有效性。
3 结论
本文给出了传统的Hadoop调度策略,但这种调度策略的map任务有时会不得不分配到非本地节点上,因为首先要对失败的任务进行考虑,对失败的任务不再考虑数据本地性,所以这样会会造成不小的网络开销,浪费等待本地性节点或任务的时间,作业执行效率和资源利用率也会随之下降。本文借助用于预取的概念,在非本地map任务分配之前便预取资源到候选节点的本地磁盘中,以提高和保证任务的数据本地性,并在计算能力调度算法的基础上加入资源预取理念,实现了该思想。最后通过实验证明该算法能够使map任务的数据本地性得到有效的提升,提高了系统资源利用率。
- 探索立体式教育路径共筑价值观精神家园
- 健全民主制度,保障公民的知情权
- 3D打印技术在神经外科教学中的应用探讨
- “一带一路”下民族教育发展机遇与走向
- 职业院校办学体制改革研究探讨
- 教育资源共享对高校发展的意义及举措
- 浅谈农业类高校国际化对本科教学的影响
- 高校新生环境适应性教育问题探究
- 幼儿园男教师成长路径
- 知行合一的安全教育提高幼儿的自我保护能力
- 中职学前教育专业生活化教学法的素材选取
- 探析初中政治教学中学生创新能力的培养
- 西部高校研究生教育中“材料科学”全英语教学的研究与实践
- 提高高中生物实验探究能力的几点做法
- 高职基于能力本位的项目课程教学实践与研究
- 基于核心素养的高职课程体系改革研究
- 基于启发式教学的高校《旅游心理学》课堂教学改革探索
- 浅谈高职艺术设计类专业《PHOTOSHOP》项目化教学改革的实施
- 警察越野障碍的解析
- 探究高中语文教学中现代文阅读教学提升方法
- 创新高职院校思想政治理论课教学模式的几点思考
- 生态学专业《环境科学概论》“五化”教学法的创新与实践
- 体裁教学法与高中英语听力教学
- 中职数学教学中创造性思维的培养
- 教师情感在中学英语课堂教学中的作用
- bring in sth / bring sb in sth
- bring-justice
- bring out
- bring/put sth into effect
- bring round
- bring round to
- brings
- bring sb in
- bring sb in sth
- bring sb in sth / bring in sth
- bring sb out of their shell
- bring sb round
- bring sb round (to sth)
- bring sb/sth around/round
- bring sb/sth before sb
- bring sb/sth, come, get, fall, etc. into line (with sb/sth)
- bring sb/sth down
- bring sb/sth into disrepute
- bring sb/sth round
- (bring sb/sth) up to scratch
- bring sb/sth ↔ in
- bring sb/sth ↔ up
- bring sb to their knees
- bring sb to their senses
- bring sb up
- 王朝的官员
- 王朝的气运
- 王朝隆盛的运命气数
- 王机
- 王权
- 王权被人所窃
- 王条
- 王杵
- 王构
- 王枋
- 王枚
- 王柄
- 王某
- 王树声
- 王樵
- 王正
- 王武献马
- 王母
- 王母仙桃
- 王母使者
- 王母娘娘
- 王母娘娘伸手
- 王母娘娘坐月子——养神
- 王母娘娘开蟠桃会
- 王母娘娘得子