李亚芬 李征


摘要:针对出版社内资源采集渠道不便,资源管理混乱等问题,本文使用开源资源库Alfresco开发全新的资源库系统,实现了对社内资源的重新整合与统一管理。特别是,提出词语语义相似度加权的TextRank方法对采集到的文本资源进行自动标注,这对数字出版中教材的创作有着非常大的帮助作用。
关键词:数字出版;资源库;Alfresco;TextRank
中图分类号:TP311 文献标识码:A DOI:10.3969/j.issn.1003-6970.2015.05.008
0 引言
随着计算机技术、通讯技术和网络技术的发展,数字出版业务相对传统出版业务,逐渐显示出独特的优势。外研社正处在由传统出版到数字出版的转型期。数字出版是为数据库而编写内容,更强调了内容数据的重要性和内容的可重复利用性。它将内容拆分成一个个的独立的内容单元,通过模板对这些内容单元进行按需重组,最后由动态发布引擎,生成纸质书、电子书、光盘等一系列的出版产品,实现按需出版业务。因此,资源的采集和初步加工是实现数字出版的前序环节。
目前,外研社的出版业务中存在以下一些问题。作者编写内容的结构差异,导致了出版社在处理作者交稿的时候,需要占用很大的精力去处理内容结构差异,同时,资源采集渠道的不便也会影响资源采集的数量和质量,也不便于出版社实现采集的资源的全社使用和统一管理。社里目前只是对资源进行简单地存储和基于文件夹的分类,缺乏对资源的描述,使资源的可利用性差。所以,本文设计实现了一个面向互联网和内网的资源采集、资源标注等综合型的资源库系统,可以提供方便快捷的资源上传、资源转换功能,在很大程度上减少出版社收集资源的时间和人工成本。本文还使用词语语义相似度加权的TextRank方法对社内的教育资源进行基于知识点的自动标注,方便创作者按照教学目的对内容资源进行检索和重新组织,这对数字出版中教材的创作有着非常大的帮助作用。
1 系统功能设计
1.1 总体功能模块
本文重点对外研社的出版生产业务过程进行了详细的调研,设计出的资源库系统由资源管理、资源加工、用户管理、日志管理四大功能模块组成。详细见图l所示。
(1)资源管理模块主要提供资源的上传下载、查看预览、查询等;
(2)资源加工模块主要提供对资源的格式转换拆分和资源的知识点标注;
(3)用户管理模块主要提供对用户的权限、信息的编辑和查询;
(4)日志管理模块负责记录用户行为,包括登陆、查看数据、下载数据、使用数据等。
1.2 资源知识点标注
资源加工模块提供对资源的知识点标注。资源知识点标注是资源智能化的重要体现方式之一。外研社资源主要包括各类大中小学教材教辅,文本资源占绝对大部分,每个文本资源内部都有一定的知识结构。经过知识点标注的资源具有功能上的独立性。方便创作者按照教学目的对内容资源进行组织。编辑人员的专业领域知识往往不够完备,知识点标注易受主观因素影响,使标注的准确度降低。人工标注还要耗费一定的精力和体力,工作效率会降低。因此,本文提出了资源的知识点自动标注。
关键词是表达一个文档核心意义的最小单元。本文选择文本关键词作为知识点。选择适当的关键词提取方法就显得非常重要。目前的关键词提取方法分为有监督的方法和无监督的方法两大类。有监督的方法需要通过训练语料构建模型实现,无监督的方法仅借助于词语之间的关系直接从文本本身提取,无需训练过程,计算速度快,应用较为方便。考虑到在上传文档资源时,自动完成关键词的提取,无监督方法既可以保证提取关键词的准确性,又能保证计算的快速性,因此本文选用无监督的方法实现关键词的提取。TextRank方法其中的代表,在众多无监督关键词提取方法中表现出卓越的性能。本文对传统的TextRank进行改进,使用词语语义相似度加权的TextRank关键词提取算法,使其更加适用于知识点的标注。
资源库提供基于知识点的查询。在输入查询检索词后,首先将检索词与知识点关联网中的知识点进行匹配。知识点关联网是以树形结构表示知识点之间关联的网络。若匹配成功,则选择该知识点的上一级知识点一同作为检索词抛给搜索引擎,进行资源的知识点检索,这样可以检索到相关资源。
2 资源库架构设计
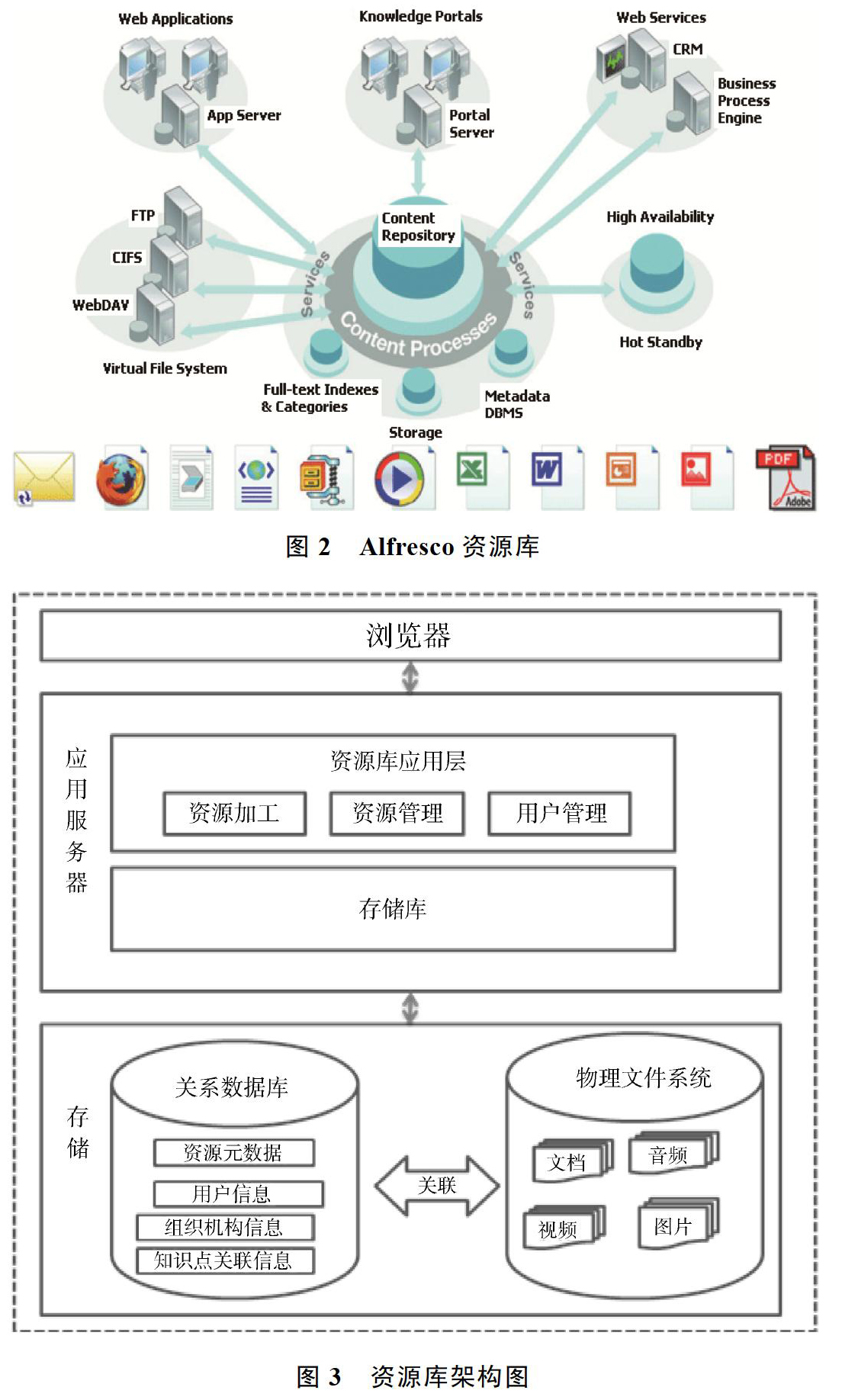
本系统主要是基于外研社内网和互联网,除了为社外人员提供提交资源的入口外,主要为社内工作人员搭建一个共享社内数字资源的平台。因此决定采用browser/server(简称B/S)结构的设计思想。Alfresco一款优秀的开源资源库,是一个完全的Java应用程序,基于J2EE框架,如图2所示。它是B/S结构。Alfresco中的内容应用程序和web应用程序都是基于内容存储库的服务上开发的,内容存储库处于资源库的最底层,由数据库、索引和内容文件组成,是资源库的核心。
Alfresco是基于Java开源框架Spring开发的,它提供了一系列可以通过不同接口调用的数据存储服务,通过以下三个基本服务实现存储访问内容:节点服务、内容服务和搜索服务。内容是信息数据的载体,通过内容服务,元数据及内容都可以根据内容模型的规则定义被结构化。
本文通过对Alfresco进行开发与定制,使其满足本文的需求。Alfresco中,资源的元数据存储在关系型数据库里,而内容本身则以二进制文件的形式存储在文件系统中,数据库存储提供高效的查询、事务处理及管理功能,而文件系统则保存比较大的内容数据。根据Alfresco的架构形式,本文对资源库进行架构设计,如图3所示,使用内容存储库提供的基本服务实现资源加工模块、资源管理模块,用户管理模块功能的开发。关系数据库中主要提供资源元数据信息的存储、用户信息的存储、机构组织信息以及知识点关联信息的存储。物理文件系统提供对资源的二进制形式文件存储。
3 资源库实现的关键方法和技术
3.1 词语语义相似度加权TextRank
关键词提取算法
TextRank的思想来源于PageRank,通过把文本分割成若干组成单元并建立图模型,结点代表词语,边代表词语之间的关联,利用投票机制对文本中的重要成分进行排序,一个结点链人的结点集表示其投票支持者,投票者越重要,数量越多,则被投票者的排名越靠前。仅利用单篇文档本身的信息即可实现关键词提取。传统TextRank中,某个词语的影响力分值是均匀传递到与其相邻的词语中,构建的图模型是一种无项无权图,考虑到本文要处理的是自然语言文本,部分词语之间的关联度会更高一些,因此,本文引入边权重计算。由于教育资源中,知识点易共现,同时知识点之间存在较大语义相似度,本文考虑将相关联的词之间的语义相似度,加入边权重计算中,夏天等考虑词语本身的重要性差异,提出了考虑词语结点影响力的相关因素的词语位置加权的TextRank方法,该方法引入词语的覆盖影响力、位置影响力和频度影响力用于计算词语之间的影响力概率转移矩阵。本文考虑到知识点往往出现在文章标题中,往往是文中的高频词汇,因此本文在边权重计算中加入位置影响力和频度影响力,提出了词语语义相似度加权的TextRank方法。
令G=(V,E)为结点集和边集构成的有向图,V为结点集,由文本中的候选关键词构成,候选关键词指经过中文分词、词性过滤、去停用词处理后,获得的词语集。对于任意一个结点vi
资源加工模块中的知识点标注是在上传文档的动作中自动完成的。本文创建新的java类TextAnalyser,该类封装了读取文本内容、关键词提取、关键字存储的功能。将其加入上传文档时对应的spring配置文件中。该类首先调用内容服务ContentService获取资源的文本内容,接着调用使用词语语义相似度加权的TextRank方法对文本内容进行分析,提取后的关键词通过节点服务(NodeService)和内容服务(contentService)获取资源在数据库中的存储位置信息,将关键词保存到相应的元数据数据库中。
通过对Alfresco中的相应页面的JSP文件进行扩展或重写,可以定制实现资源管理前台界面。实现上述功能的Spring Beans、java class、iava script、JSP等文件将作为Alfresco的应用程序进行重新打包和部署,Alfresco提供AMP(Alfresco Module Packages)来实现打包,可以实现定制代码与Alfresco核心代码的分离,打包部署后,新的功能就加入到Alfresco中了。
4 结论
本文中,本文使用开源资源库Alfresco开发全新的资源库系统,实现了对社内资源的高效存储、加工与管理。提出了词语语义相似度加权的TextRank关键词提取算法,将其应用到资源知识点标注中,使资源库成为面向教育的知识库,更加满足数字出版业务的需求。
- 甲钴胺联合—硫辛酸治疗糖尿病周围神经病变的疗效评价
- 提高油水井作业一次成功率的对策探讨
- 内河水运工程设计中常见问题分析
- 浅谈培养小学数学课堂教学气氛方法的研究
- 浅谈小学生数学运算能力的培养
- 合作让自学更高效
- 高中数学学案教学法的初步实践与体会
- 试论交互式电子白板在高中数学教学中的应用
- 关于幼儿园数学纳入科学领域的思考
- 试论小学数学课堂有效提问引导学生自主合作探究学习教学模式的实践问题
- 数学实践活动课如何培养小学生的实践能力
- 小学数学教学情境课堂的创设方法的探讨
- 高中数学教学中数形结合法的运用探讨
- 浅谈初中数学教学的创新策略
- 浅议数学建模思想在课堂教学中的渗透
- 教学生活化视角下小学高年级数学教学的创新
- 浅谈新课程高中数学课堂提问有效性研究
- 小学心理健康教育中的家校合作策略分析
- 关于建立学校和家庭教育间良性互动的探讨
- 对“家校共同体”在小学生品德发展地位的理性分析
- 家校合作在大学生心理健康教育中的应用探析
- 精彩的瞬间,心灵的洗礼
- 航海职业教育的困境和出路探讨
- 让幼儿在自主游戏中获得社会交往能力
- 幼儿园一日生活常规有助于幼儿良好生活习惯的养成
- supermodest
- supermodestly
- supermoisten
- supermoistened
- supermoistening
- supermoistens
- supermolecules
- supermolten
- supermoral
- supermorally
- supermorose
- supermorosely
- supermoroseness
- supermorosenesses
- supermullion
- supermullioned
- supermunicipal
- supernation
- supernations
- supernatural
- supernaturalist
- supernaturalistic
- supernaturality
- supernaturalization
- supernaturally
- 后心
- 后忧
- 后怕
- 后怕虎
- 后怕虎前怕龙
- 后恭前倨
- 后悔
- 后悔、烦恼的样子
- 后悔不及
- 后悔也晚了
- 后悔何及
- 后悔已晚
- 后悔已经来不及
- 后悔当初不该这样做或没有那样做
- 后悔无及
- 后悔药
- 后悔药儿
- 后悔药吃不得
- 后悔药没处买
- 后悔药,没处买
- 后悔莫及
- 后悔迟
- 后患
- 后患无穷
- 后戒