摘要:语义Web的发展日新月异,惠普公司(HP)在研究语义Web方面处于领先地位,其发布的Apache Jena系统为研究语义Web提供三元组存储(Triple Store)平台、RDF(Resource Description Framework)平台和OWL(Web Ontology Language)平台,Apache Jena是HP实验室开发的一个用于处理语义Web和链接数据应用的免费开源Java工具包,本文研究基于Jena系统的知识融合三元组存储结构。
Abstract: The development of Semantic Web is changing rapidly. Hewlett-Packard Company (HP) is the leader in the research of Semantic Web. Its published Apache Jena system provides Triple Store, RDF (Resource Description Framework) and OWL (Web Ontology Language) platform for research Semantic Web.Apache Jena is a free and open-source Java toolkit developed by HP Labs for processing semantic web and linked data applications. This paper studies Jena-based knowledge fusion triple storage architecture.
关键词:Jena;语义Web;RDF;知识融合;RDFS;OWL
Key words: Jena;Semantic Web;RDF;knowledge fusion;RDFS;OWL
中图分类号:TP202 文献标识码:A 文章编号:1006-4311(2018)08-0126-040 引言
关系数据模型和半结构化数据模型是两种重要的数据模型,半结构化数据模型通常用XML和相关的标准表示,它是大多数关系数据库管理系统DBMS的一个附加特征[1]。RDF模型和RDFS(Resource Description Framework Schema Specification)规范是W3C的推荐标准,基于这个标准和XML语法建立的资源、信息、知识越来越多,它们大多以RDF文件的格式描述并存放在网络上,广泛存在于数字图书馆、知识库、本体等中。面对海量的数据和知识,如何保证一个RDF文件内容、版本等的一致性和正确性[2],如何把不同RDF文件中相同的知识通过集合操作提取出来、不同的知识合并在一起,这是一个值得研究的知识融合语义Web问题,二十世纪九十年代末至今,国内外许多专家在从事这个领域研究。但RDF模型和RDFS规范是一项涉及知识面比较广的系统工程,目前,HP实验室的Jena系统对它的研究比较领先。2003年至今,我们对Jena系统的体系结构进行了研究,并基于Jena系统实现了知识融合的并集、交集、差集等操作,本文研究基于Jena系统的知识融合三元组物理存储(Triple store)结构。1 Jena2系统的体系结构
Jena是HP实验室开发的一个用于处理语义Web和链接数据应用的免费开源Java工具包。Jena1版本于2000年发布,Jena2版本于2003年发布,2017年版本升级到apache-jena-3.5.0,本文使用的版本是Jena2.1(以下简称Jena)。Jena系统为研究语义Web提供Triple Store、RDF、OWL平台,Jena根据RDF模型和RDFS语法规范提供建立和操作RDF图的Java API,支持集合的并集、交集、差集操作。
通过调用Jena系统提供的核心API,创建和读取RDF图,实现集合的并集、交集、差集操作,可以使用XML格式、RDF格式或Turtle格式序列化三元组。
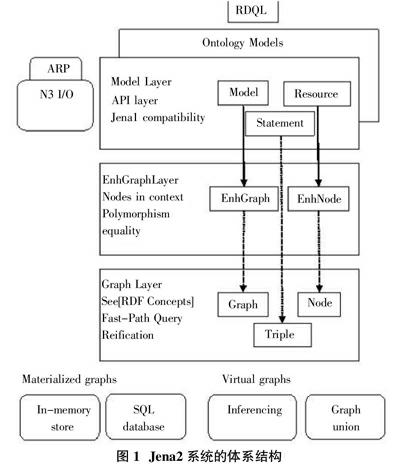
Jena系统的体系结构由Graph、EnhGraph、Model三层组成,如图1所示。Graph层主要实现三元组的存储,EnhGraph层为图和节点实现多种操作视图,Model层为应用编程人员提供不同视图,用来创建RDF图和操作RDF图,本文主要研究Graph层三元组的存储。2 存储结构中用到的Java集合框架
在Java类集中常使用的接口是:Collection、List、Set、Map、Iterator、ListIterator、Enumeration、SortedSet、SortedMap、Queue、Map.Entry[3]。
Jena系统用Java开发,三元组的存储结构中用到Java中的集合框架、HashSet、HashMap、List和Iterator(迭代器,也叫反复器)等知识[4]。
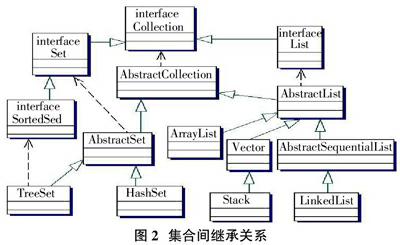
集合主要用来处理各种类型的对象的聚集,每一个对象都具有一定的数据类型。集合保留了对Object类的引用,因此,任何数据类型的对象都可以存放在集合中。集合包含3个重要接口:Collection、Set、List(如图2所示),它们都可以用来组织多个对象,但是又各不相同[5]:Collection中的对象存放没有一定的顺序,并且允许重复;Set也是对象的无序聚集,但是不允许重复(即相同的對象只能在集合中出现一次),HashSet的特点是无序不重复,允许null存在;List是一个有序的对象聚集,对象按照一定的顺序存放,同时允许重复,元素允许null。
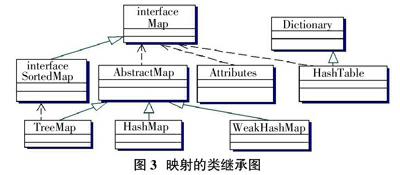
HashMap的特点:它是一系列“键-值”对的集合,可以通过一个键找到相应的值。可以使用Put方法向映射中加入一个“键-值”对,映射中不能包含重复的键,如果插入的键已经存在,那么新插入的值将取代旧的值。其中“键”和“值”可以是任意类型的对象。图3是映射的类继承图。
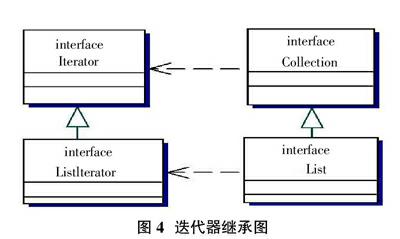
对集合中的每一个元素的访问使用的是迭代器Iterator,对于Set来说,利用迭代器Iterator所获得的元素顺序不是一定的。对于List来说,有一个更实用的迭代器ListIterator,它直接继承自Iterator,但是它除了可以得到下一个元素之外,还可以得到前一个元素,可以添加元素,可以设置元素。图4是迭代器继承图。
 3 三元组的存储结构
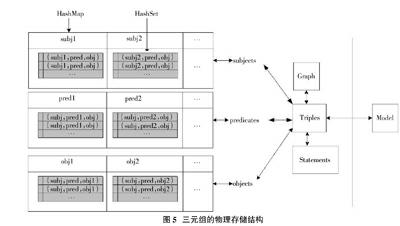
3 三元组的存储结构RDF模型和RDFS语法规范是一项涉及知识面比较广的系统工程,HP实验室的Jena系统对它研究比较全面,本文研究团队对Jena系统进行了解析,用Togerther工具分析Jena系统的类图(UML图),JbuilderX配合Togerther打开Jena系统的源程序代码,找到了三元组在该系统中的存储结构。图5是三元组的物理存储结构图,最右边Model是RDF图的抽象形式,相当于一个模型加工廠,提供给用户各种各样的Model API,用户可以通过模型提供的接口根据不同需求进行各种各样的访问、操作和应用编程。左边部分是图Graph及三元组的存储结构,这一部分主要作为通用数据结构的存储。
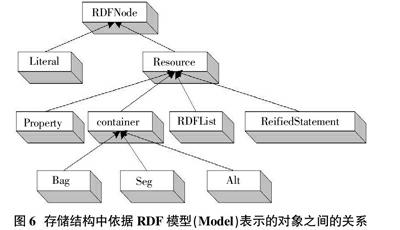
图6是存储结构中依据RDF模型表示的对象之间的关系图,RDFNode由Literal和Resource两类组成,Resource由Property、container、RDFList、ReifiedStatement组成,container由Bag、Seg、Alt组成。

图7是存储结构中图、三元组和节点之间的关系图。其中Node由固定的节点(Node Concrete)和可变的节点(Node Fluid)组成,固定的节点由Node Blank、Node URI、Node Literal、Node NULL四类组成,可变的节点由Node ANY、Node Variable组成。三元组Triple依赖Node构造产生。
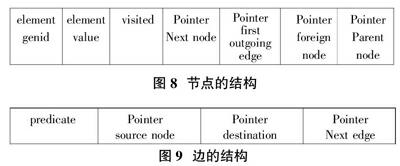
Subjects和objects以节点存放,一个结点的具体结构如图8所示;predicates以边存放,每条边的结构如图9示。

同样,Model加工厂把一个RDF文件序列化成三元组(可以理解为一个图)的过程是一个牵涉RDF模型和RDFS规范的系统工程,其中与三元组存储结构密切相关的是节点到三元组的映射及在数据结构中的存储。三元组的存储结构是知识融合的核心之一。下面举例说明节点到三元组的映射:假设被序列化的三元组为(I,am,a teacher)、(I,am,a student)、(You,are,a student)、(You,are,a teacher)。为了说明的方便,简化为(I,am,t)、(I,am,s)、(Y,are,s)、(You,are,t),图10是节点到三元组映射示例。每个Subjects、Predicates、Objects的存储结构是一个HashMap,每个键对应的键值是一个HashSet,在前面讨论过HashMap的特点是:它是一系列“键-值”对的集合,可以通过一个键找到相应的值(用Get方法),可以使用Put方法向映射中加入一个“键-值”对,但映射中不能包含重复的键,如果插入的键已经存在,那么新插入的值将取代旧的值。其中“键”和“值”可以是任意类型的对象。所以,在添加的时候,首先要判断添加的键是否存在,如果存在,则不需要添加该键,但要先用Get把该键在HashMap中对应的键值取出来,并强制转换成HashSet,然后转为对HashSet的操作,由于HashSet的特点是无序不重复,允许null存在,所以,如果HashSet中已经有要添加的三元组则不进行添加操作,如果没有则把新的三元组添加进去(其实就是在合并三元组)。假若在HashMap中要添加的键不存在,则在HashMap中New一个HashSet,并把对应的键添加到HashMap中,键值添加到HashSet中。
此外,当存储每个三元组时,不但要存储Subject,Predicate,Object本身,而且还要分别存储Subject,Predicate,Object是在哪个三元组中。这样可以实现同时存放三元组及其它们之间的关系。
例如,三元组(I,am,t)和 (I,am,s)的具体存储过程:
存储三元组(I,am,t)时,Subject是I,到Subjects对应的HashMap中查找是否有主键为I的键,查找结果没有,所以把I添加到HashMap的主键中,然后New一个键值为HashSet,把对应的三元组(I,am,t)添加到HashSet中。同理存放Predicate为am,Object为t的情况。
存储三元组(I,am,s)时,Subject是I,发现HashMap中已经有,所以到Subjects对应的HashMap中把主键为I的键值提取出来,并强制转换成HashSet,然后把三元组(I,am,s)添加到HashSet中。当添加Predicate为am时,am已经存在,所以其操作与添加Subject是I的情況类似。名称空间(name space)也存储在HashMap中。
从图10中可以看出,数据存储冗余度大,这是用存储空间来换取时间的一种策略[6]。4 结束语
Jena系统可以使用XML格式、RDF格式或Turtle格式序列化三元组,RDF文件、RDF图和三元组是Jena给用户提供的三种不同操作视图,本文通过对Jena系统的解析,找到了三元组在该系统中的存储结构,为应用Jena系统提供的API操作三元组实现关联数据应用奠定了基础,下一步,紧跟Apache Jena网站提供的开源资料,对新版本apache-jena-3.5.0开展研究,主要研究新版本在RDF、Triple Store、OWL三大应用领域的升级改进。
参考文献:
[1]李兴华,马云涛编.Oracle开发实战经典(基于Oracle 11g、12c)[M].北京:清华大学出版社,2014:16-17.
[2]杨夏柏,杨明.基于Jena系统的知识融合技术研究[J].价值工程,2016(03):213-214.
[3]李兴华编著.Java开发实战经典[M]. 北京:清华大学出版社,2009:494-558.
[4]王克宏主编.Java技术教程(基础篇)[M]. 北京:清华大学出版社,2002:214-258.
[5]张曜等编,Java函数实用手册[M].北京:冶金工业出版社,2003:161-186.
[6]Jeremy J.Carroll,Jena:Implementing the Semantic Web Recommendations, December 2003.
- “中国传统节日”作文素材
- 争当友谊的小使者
- 感谢那一双双眼睛
- 父亲给我的传家宝
- 孩子,谢谢你,让我如此美丽
- 父亲树
- 雨伞
- 我和世界冠军比父亲
- 秋雨潇潇
- 感动我的几个瞬间
- 被忽略了的爱
- 背影
- 品味书香
- 母亲的眼泪
- 好书伴我成长
- 当地球没有引力的时候
- 爱的回报
- 母爱
- 回报母爱
- 《连环画报》伴我成长
- 永世的债
- “爱我母语,爱我中华”读书教育活动
- 梦想
- 时间的守护天使——毛毛
- 不平凡的鹿
- impassabilities
- impassability , impassableness
- impassable
- impassablenesses
- impassably
- impasse
- impasses
- impassioned
- impassionedly
- impassionedness
- impassionednesses
- impassionedness's
- impassive
- impassively
- impassivenesses
- impassiveness, impassivity
- impassivities
- impatience
- impatient
- impatiently
- impatientness
- impatientnesses
- impeach
- impeached
- impeacher
- 机任
- 机会
- 机会一失,不可再得
- 机会主义
- 机会和缘分
- 机会失之弹指间
- 机会成本
- 机会或时间容易过去
- 机会极为难得
- 机会难得
- 机会难得,极易失去
- 机伪
- 机伶
- 机伶变儿
- 机位
- 机体
- 机体因受刺激而收缩
- 机体的局部组织或细胞死亡
- 机体组织因钙沉积而变硬
- 机便
- 机俏
- 机候
- 机偶
- 机儿不快梭儿快
- 机儿不快梭儿快。