杨丕仁

摘要:随着互联网的发展,网络已经成为人们生活不可缺少的一部分。现在接入互联网的形式已经发生了变化,由传统的PC机接入发展到今天的各种移动终端(手机、平板电脑、物联网设备)接入,从而对网络安全提出了更高要求。在网络安全管理中,对用户行为管理是最基本的,只有管理好用户的上网行为才能做对网络可查可管。该系统将以Python程序架构为基础,设计一套适合处理校园网络用户上网行为的程序。
关键词:网络安全;用户上网行为;数据分析
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)15-0117-03
随着互联网技术的发展,各种网络设备功能越来越来完善,设备性能管理方面也比较智能化,在网络管理上发生了变化,不再像过去花费大量的人力忙于维护网络设备,而是要分析用户的上网行为,为用户提供一个安全稳定的网络环境。目前所得到的用户上网行为都是从网络设备上获取的,这些数据中存在脏数据[1],脏数据不符合要求,对于分析用户上网行为存在干扰。并且这些数据量非常大,而且还分散在不同的文件中,不便于以后的存储和运算。如何对这些数据进行分类、清洗并进行有效的存储是网络行为分析的一个重要问题。
文章首先介绍python程序设计语言的相关组件和功能架构,在此基础上,设计并实现了基于python语言的分析用户上网行为的分类与清洗系统,验证了系统的有效性和稳定性,并对数据的处理时间和数据的压缩比例进行分析。
1 Python程序的介绍
Python是一种解释型交互式、面向对象、动态语义、语法优美的脚本语言。自从1989年Guido van Rossum发明,经过几十年的发展,已经同Tcl、perl一起,成为目前应用最广的三种跨平台脚本语言。Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议[2] 。Python的主要特点有:
1)免费开源、简单易学
Python是FLOSS(自由/开放源码软件)之一[3]。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。Python是一种代表简单主义思想的语言,阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。Python极其容易上手,因为Python有极其简单的说明文档 。
2)速度快
Python 的底层是用 C 语言写的,很多标准库和第三方库也都是用 C 写的,运行速度非常快 。
3)高层语言
Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
4)可移植性
由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)[4]。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE、PocketPC、Symbian以及Google基于linux开发的android平台。
5)面向对象
Python是一种公共域的面向对象的动态语言[5],Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
6)可扩展性
如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
7)可嵌入性
可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
8)丰富的库
Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
9)规范的代码
Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。
2 系统架构的设计
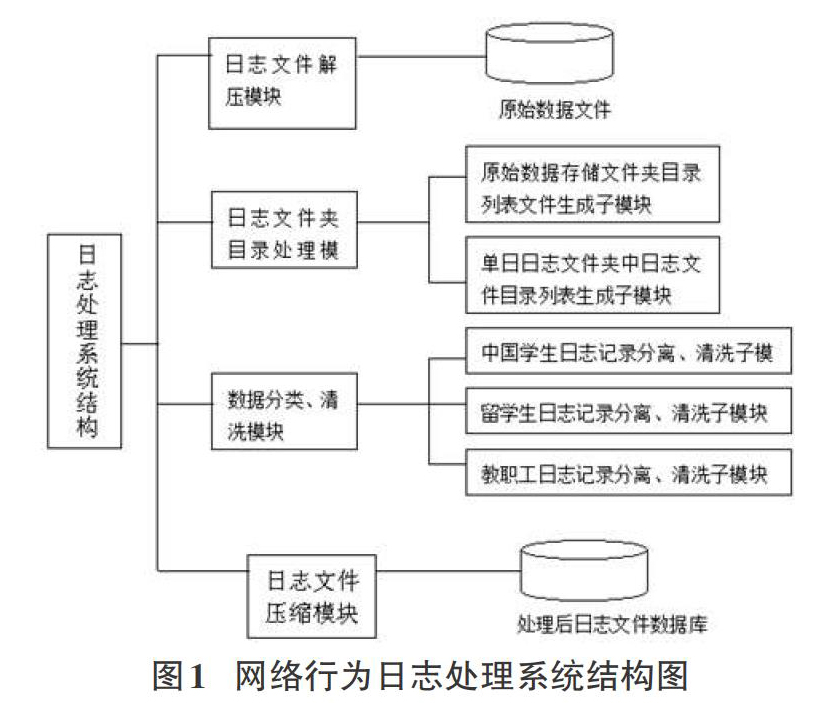
由于网络用户上网行为数据可以从网络安全设备(如防火墙、网络认证网关)上直接采集,所采集到的数据中有很多信息是不需保存的,并且生成的日志一般都是一个2万多条记录的压缩文件。在实际的用户行为管理分析中需要对这些压缩文件进行解压、分类、清洗,然后提取有用信息,并对所提取的信息进行压缩处理,以便以后用于数据挖掘。系统结构设计如图1:
在日志处理系统结构设计中,日志解压模块实现对原始数据自动解压,并保存在以日期命名的文件夹中日志文件;日志文件夹处理模块用于处理长时间保存日志文件和日志文件夹,使处理结果生成一个带有路径的文件名列表的文本文件。这个文本文件可以使下一步数据分类、清洗模块快速定位到所要处理文件的位置和名称。根据大理大学网络用户特点设计数据的分类和清洗模块,实现把中国学生、留学生、教职工、校外人员的网络行为日志文件进行分离,并把这些日志文件中没有实际意义的记录清除,最终把分类文件分别合并到以日期命名的文件中,为以后大数据的科学计算和智能分析提供纯净的数据源。日志文件压缩模块实现对分类、清洗过后的日志文件进行压缩,提高存储效率。
3 系统的实现
3.1 目录处理模块的实现
采用python程序设计语言中的os模块,实现对目录路径和文件名的处理,第一步,将原始数据目录下的所有文件夹的路径写入到一个文本文件中,例如:D:\campus big data\Datadirectory.txt,以便数据处理时循环遍历所有文件夹,其代码实现如下:
def CreateRawdatadirectory():
data_file_path="D:\\campus big data\\Raw_data\\"
day_log_path=os.listdir(data_file_path) #日日志文件夹路径
log_files_list=[] #每天的.log文件所在目录,如D:\campus big data\data\2016-03-01
fw=open("D:\\campus big data\\Raw_Datadirectory.txt","w")
for item in day_log_path:
fw.write(data_file_path+item+"\\") #Raw_Datadirectory.txt写入
fw.write("\n")
fw.close()
第二步,生成日志文件夹文件,将每日文件夹下的所有日志文件路径写入对应文件夹下的文本文件。例如:D:\campus\bigdata \data \201 6-03-01\file_path.tx文件,在数据处理时可以快速遍历所有日志文件,其代码实现如下:
def CreateLogDirectory():
fr=open("D:\\campus big data\\Raw_Datadirectory.txt","r")
fr_s=fr.read()
log_files_list=fr_s.split("\n")
for directory in log_files_list:
fw=open(directory+"file_path.txt","w")
try:
log_filename=[fname for fname in os.listdir(directory) if fname.endswith('.log')]
for fname in log_filename:
fw.write(directory+fname) #file_path.txt文件写入
fw.write("\n")
except:
pass
fw.close()
fr.close
第三步,创建多级目录,创建处理后数据存储的多级目录。例如:Ch_students目录、Oversea_students目录、Teachers目录,用以保存不同用户的上网行为日志文件。
3.2 解压和压缩模块
根据目录处理模块所得到的路径文件,调用python提供的zipfile模块,把原始数据进行解压,并把清洗过的用户行为数据进行压缩,代码的设计如下:
解压过程:
def FromZip(file_path_prefix): #
file_directory="D:\\campus big data\\Raw_data\\2016-03-01\\"
zip_filename=[fname for fname in os.listdir(file_directory) if fname.endswith('.zip')]
for item in zip_filename:
zip_path=file_directory+item
zfile = zipfile.ZipFile(zip_path,'r')
filename=zfile.namelist()[0]
data=zfile.read(filename)
flog=open(file_directory+filename,'w+b')
flog.write(data)
flog.close
压缩过程
def ToZip():
file_directory="D:\\campus big data\\Raw_data\\2016-03-01\\"
log_filename=[fname for fname in os.listdir(file_directory) if fname.endswith('..log')]
for item in log_filename:
log_path=file_directory+item
f = zipfile.ZipFile('archive.zip','w',zipfile.ZIP_DEFLATED)
startdir = "c:\\mydirectory"
for dirpath, dirnames, filenames in os.walk(startdir):
for filename in filenames:
f.write(os.path.join(dirpath,filename))
f.close()
由于程序在运行时是直接调用目录处理模块所得的路径文件,这样就可以缩短程序运行的时间,提高程序的运行效率。
3.3 数据分类、清洗模块
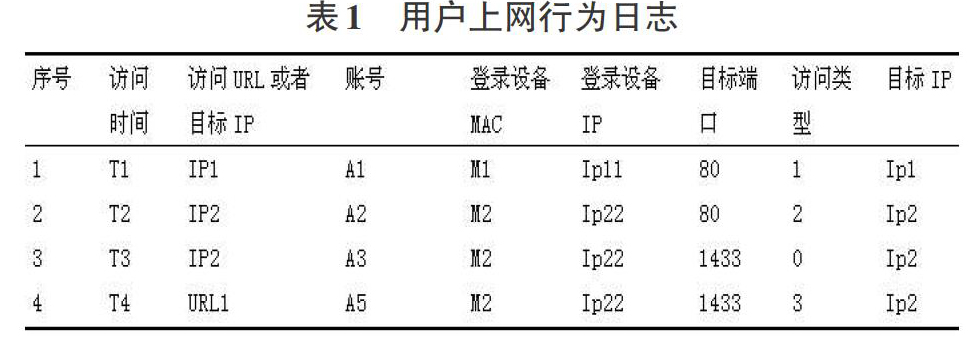
在网络用户上网行为日志数据中,有许多信息是没有意义的,我们需要对这些数据进行分类和清洗。原始数据结构如下:
3.3.1 数据的分类
根据学校校园网络用户的特点,我们可以把用户分为教工、国内学生、国外学生。根据上网的区域可以分为办公区、教职工住宅区、学生宿舍区。利用python语言对文件快速处理的特点对用户进行分类,并分别存储在不同的文件中,代码如下:
fwrite_log=open("data_log.txt",'w') #数据处理后存文放文件
fread_log=open("2016-03-01 00-00-00..txt",'r') #打开日志文件
log_txt=fread_log.read().split('\n') #读取每一条记录
for i in range(len(log_txt)): #对每一条记录进行处理
if log_txt[i].strip('\n')!='':
if(log_txt[i].split('\t')[3])[0]=='X':
record=log_txt[i].split('\t') s_row=record[2]+'\t'+record[4]+'\t'+record[5]+'\t'+record[6]+'\t'+record[7]+'\t'+record[8]+'\t'+'\n'
fwrite_log.write(s_row)
fwrite_log.close()
fread_log.close()
3.3.2 数据清洗
根据网络用户上网行为的特点,会出现空行、重复记寻。数据清洗的重要工作就是要把这些干扰信息去除,保留有用信息,为以后的数据挖掘提供纯净的数据。在数据清洗过程中,应用python中的set()和strip()功能把重复记录和空行清除。经过清洗的数据记录数和文件大小都比原来小,表2中可以清晰的反映数据清洗前后的对比。
4 结束语
从程序的运行结果可以得出,用python编写的用户上网行为日志处理程序设计简单,运行效率高,所提取的用用户行为数据可以进一步分析,为校园网络安全提供准确的用户定位,为校园网络的带宽管理和维护提供准确的数据作为参考,并提高网络的服务质量。
参考文献:
[1] 张良均, 樊哲, 赵云龙. Hadoop大数据分析与挖掘实战[M]. 北京: 机械工业出版社, 2016.
[2] 肖建, 林海波. Python基础教程[M]. 北京: 清华大学出版社, 2003: 1-2.
[3] 北京中科红旗软件技术有限公司. 红旗Linux系统应用编程[M]. 北京: 石油工业出版社, 2012: 192.
[4] 陶诚, 陆从珍. 基于C++和Python混合编程的WORD文档操作方法[J]. 信息化研究, 2014(5): 59.
[5] 杨昆, 汪兴东. Python程序员指南[M]. 北京: 中国青年出版社, 2011: 8.
- 浅谈智慧图书馆的构建及智慧服务研究
- 论新形势下图书馆如何发挥社会教育职能
- 图书馆少年儿童图书借阅室读者服务管理与开发
- 基于德国职业教育理念的新能源汽车技术专业建设
- 飞扬琴音 灵动旋律
- 中学英语三段式翻转课堂生态建构研究
- 大学生积极心理培养策略研究
- 浅谈电子技术实践教学中虚拟仿真技术的应用
- 网格化管理模式在高校学生管理工作中的作用
- 数学建模课程中项目化教学的优化途径分析
- 大思政格局下辅导员学生管理工作方法的探究
- 电力营销过程中电价及电费风险控制
- 我国物流上市公司经营绩效分析
- 人才交流服务对促进人力资源合理流动的影响
- 大数据背景下财务会计变革路径研究
- 网络交易安全与民商法保护的相关性探讨
- 浅论卫生院财务管理目标及实现途径
- 政工管理对企业文化建设的影响观察
- 关于国有企业党建工作与企业管理相互融合的思考
- 国土空间规划档案信息共享与服务平台构想与研究
- 卫生系统人事档案管理信息化研究
- 医院人事档案信息化管理探析
- 卫生监督部门档案信息资源共享工作研究
- “互联网+”时代文史馆的发展策略
- 大数据背景下医院档案管理创新路径
- remarried
- remarries
- remarry
- remarrying
- remarshal
- remarshaled
- remarshaling
- remarshalled
- remarshalling
- re-marshalling
- remarshals
- remast
- remasteries
- remastery
- rematch
- rematched
- rematches
- rematching
- remate
- remated
- rematerializations
- rematerialize
- re-materialize
- rematerialized
- rematerializes
- r2022090420003245
- r2022090420003246
- r2022090420003247
- r2022090420003249
- r2022090420003250
- r2022090420003251
- r2022090420003253
- r2022090420003254
- r2022090420003255
- r2022090420003257
- r2022090420003258
- r2022090420003259
- r2022090420003260
- r2022090420003261
- r2022090420003262
- r2022090420003264
- r2022090420003265
- r2022090420003266
- r2022090420003268
- r2022090420003269
- r2022090420003270
- r2022090420003271
- r2022090420003272
- r2022090420003273
- r2022090420003275