吴东起 吴国兰


摘要:云计算技术的发展飞快:VMware 2011年9月发布vSphere 5.0、历经5.1、5.5、6.0、2016年11月推出vSphere 6.5,对于一款商业平台软件来说,算得上发展迅猛。OpenStack 2010年开始正式发布,每半年推出一个新版本,目前已是第15个版本-Ocata(2017年2月推出);新版本相对于上一个版本完善了原有的功能,也扩展了很多新的功能。这两款云平台软件在IaaS方面的表现各有千秋,该文以这两个平台下的VM批量部署的例子进行比较,进而分析、总结了OpenStack和VM-ware vSphere在资源调度上的异同、优劣。
关键词:云计算;虚拟机;虚拟机调度;资源分配;VMware vSphere;OpenStack
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)22-0028-04
1说明
1)本文中的斜体字表示该部分内容是变量,在具体操作中会有变化。
2)本文中的OpenStack指的是OpenStack 0cata版本,VM-ware vSphere指的是VMware vSphere 6.5。
3)本文中涉及两种虚拟化平台,各自有术语体系,有时难免混乱,为避免误解,做以下说明:
VMware vSphere中的虚拟机(Virtual Machine)概念为大多数人所接受,但在OpenStack中又有两种叫法:在dashboard(控制面板)中叫做instance(实例),在openstack命令行中则用server(可理解为“云服务器”涞表示,我用VM作为它们的统称。
4)笔者是在基本相同的硬件环境下将VMware vSphere与OpenStack下部署多台虚拟机的情况进行测试比较的,具体为:主机都是两台DELL PowerEdge R920服务器、同一个网络环境、本地存储;VMware vSphere的vCenter Server安装在两台主机的其中之一上,OpenStack将其中一台主机作为单一控制节点同时也是计算节点。
2VMware vSphere下虚拟机(Virtual Machine)的部署
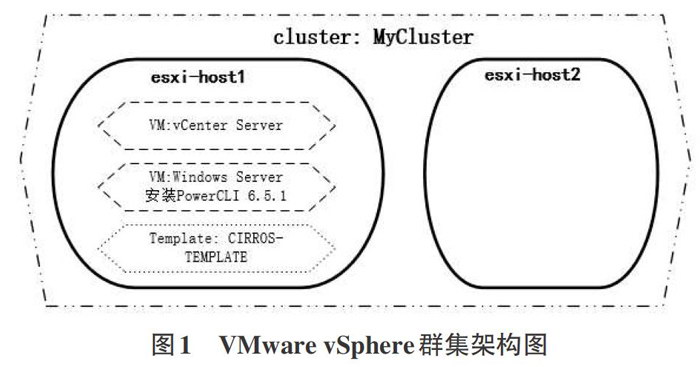
笔者在VMware vSphere下完成虚拟机部署的系统架构如“图1 VMware vSphere群集架构图”所示:
为了实现我们的虚拟机部署方案,在物理机上安装ESXi6.5后,依次做了以下工作:
1)在主机esxi-hostl上新建虚拟机,安装操作系统Win-dows Server 2012(10.1.28.38),在系统上安装配置Windows域,安装SQL Server 2012,安装配置vCenter Server 6.5,在vCenterServer上建立数据中心并添加两台主机-esxi-hostl、esxi-host2
2)创建主机群集MyCluster,包括主机esxi-hostl、esxi-host2,并启用DRS。
3)创建vSphere分布式交换机(vSphere Distributed Switch)
4)创建虚拟机模板CIRROS-TEMPLATE
5)新建一台Windows Server虚拟机,并在其上安装Power-CLI6.5.1(接下来的脚本将在这台虚拟机上运行)为了与后述的OpenStack环境下的VM部署相对比,我在VMware vSphere环境下没有使用vSphere web client图形界面创建虚拟机(vSphereweb client图形界面也不支持批量部署虚拟机),而是使用Pow-erCLI脚本来创建。
下面是PowerCLI批量部署虚拟机的脚本代码,该脚本完成的主要操作是:
以administrator身份连接vCenter Server(10.1.28.38),获取创建虚拟机的模板(CIRROS-TEMPLATEJ,获取群集(MyClus-ter),设置虚拟机名称前缀(vmname-),使用循环语句foreach在群集上建立15台虚拟机,建立虚拟机DRS组(vmGrp),建立主机DRS组(vmHostGrp),创建虚拟机一主机DRS规则(MyRule),即虚拟机“vmname-1”,“vmname-2”,“vmname-3”必须运行在主机“esxi-hostl”之上,虚拟机“vmname-4”,“vmname-5”,……,“vm-name-15”则由DRS群集自动调度。
该脚本的具体内容如下:
3OpenStack下实例(Instance)的部署
笔者在OpenStack下完成实例部署的系统架构如“图2节点服务视图”所示:
两台主机的名称分别是Umaster50(是控制节点,同时也是计算节点)、Ucomputer51(计算节点),都是先最小化安装操作系统ubuntu 16.04,然后安装配置如“图2节点服务视图”所示的服务,具体过程不是本文重点,在此略过。
正式部署实例前,先要为OpenStack用户建立环境,即将用户名、密码、项目名称、域名称、认证URL等信息导出到对应的系统环境变量中,为操作方便起见,我们一般用一个脚本来实现,比如下面的n14_openrc文件:
有了上面的客户端脚本,如果想以域default,项目n14和用户n14-1的身份运行openstack客户端,只需要以如下格式加载
$.n14_openrc
同样,OpenStack管理员(admin)用户也可以使用类似的脚本建立工作环境,文中用admin_openrc表示该脚本名称,其具體内容在此略过,可参照n14_openrc。
在创建实例(instance)/云服务器(sgiver)之前,一般情况下要确定的几个要素是:实例类型(flavor)、镜像(image)、网络(net-work)、安全组(security-group)、密钥对(key-pair)、实例名称。
实例类型定义了实例对CPU、内存、磁盘的需求;镜像定义了实例的源(类似于VMware vSphere里的模板,包含了实例的操作系统和其他的软件);网络定义了实例所在的网络;安全组用来控制进出实例的流量(相当于实例外部一道防火墙)、密钥对定义了公钥和私钥用以登录实例。
以下命令可以登录到任一节点上运行,也可以把它们保存在shell脚本中,具体功能依次是OpenStack管理员用户建立实例类型(名字为m1.nano)、镜像(名字为cirros)、外部网络(名字为providerl;OpenStack普通用户n14-1建立自定义网络(名字为seffl4,网络id为ed8be57e-9695-411e-822d-030909b03feJ)、路由器(名字为routerl4)、安全组(名字为default)、密钥对(名字为mykey),服务器组的(名称为grp-1):
下面一组命令先建立具有互斥策略的服务器组,然后新建13个实例,并应用该服务器组策略一将这些实例尽可能分散在不同的主机上f如果有13台以上的主机可用,将在优先级较高的13台主机上分别建立13个实例,但在我们的实验环境下只有两台主机,这一部署策略的特点没有充分体现出来),接着获取第一个实例的信息,最后建立的两个实例cosvm-1、cosvm-2与第一个实例civm-1在同一主机上(假设d821cd84-6f03-4afa-98b8-cf077fde0487就是civm-1的UUID)。
上述操作在OpenStack的horizon图形界面下也可以非常方便地完成。
4VMWARE VSPHERE、oPENSTACK在资源调度上的比较
对任何一种提供IaaS服务的云平台来说,资源无非是CPU、内存、电源、存储器和网络资源。经过在VMware vSphere、OpenStack下部署虚拟机/实例的体会,笔者认为二者在资源调度上有以下区别:
1)从资源调度的工作方式上来说,VMware vSphere对资源分配的主要机制是通过对资源的份额、预留和限制的配置来实现的,在启用DRS(vSphere Distributed Resource Scheduler-分布式资源调度)群集、数据存储DRS群集、OVS…的情况下,可以在群集层次上调度资源。
OpenStack中对实例的管理是通过核心组件nova来实现的。nova的架构比较复杂,包含很多组件,其中nova-scheduler实现实例资源调度服务,也就是负责决定在哪个计算节点上运行新建实例,以及如何分配资源。新建实例的调度过程分为两步:
(1)通过过滤器(filter)选择满足条件的主机一计算节点(运行nova-compute的节点)
(2)通过权重计算(weighting)选择在最优(权重值最大)的主机上创建实例(Instance),即过滤器过滤出可用的主机列表后,调度器会对每个可用主机进行加权计算,算出各主机的权重,再根据权重选中优先级最高(权重最大)的主机为实例分配资源。加权的计算方法就普通的加权算法,假设加权指标为w1、w2等,那么公式就是:
权重=w1加权系数。w1基准值+w2加权系数*w2基准值+…
w1、w2这些指标由配置文件nova.conf中的选项fil-ter_scheduler.weight_classes设置,其默认值是nova.scheduler.weights.all_weighers,即默认表示采用以下加权指标来计算权重:
RAMWeigher(可用内存)、DiskWeigher(磁盘空闲空间)、MetricsWeigherf根据metrics_weight_setting设置的公式计算权重)、IoOpsWeigher(主机IO负载)、PCIWeigher(PCI设备数量)、ServerGroupSoftAffinityWeigherf运行的属于同一个服务器组的实例数,正值)、ServerGroupSoftAntiAffinityWeigher(运行的属于同一个服务器组的实例数,负值)。
2)从资源调度的指标上来说,VMware vSphere对CPU、内存以及存储IO配置份额、预留和限制,具体点说就是可以基于份额分配占资源提供方的总的百分比,或者分配所保证的最少资源预留量,或者设置资源使用的上限。VMware vSphere要实现自动化的资源调度需定义DRS群集,即当需要在DRS群集上新建虚拟机的时候,系统会根据设置采用两种不同的处理方式:
(1)自动选择合适的主机、存储运行虚拟机。
(2)显示虚拟机运行位置、存储位置的建议,用户可以选择接受或覆盖。
在DRS群集上可以使用关联性规则,控制群集内主机上的虚拟机的放置位置。可以创建两种类型的规则:
(1)用于指定虚拟机组和主机组之间的关联性或反关联性。关联性规则规定,所选虚拟机DRS组的成员可以或必须在特定的主机DRS组成员上运行。反关联性规则规定,所选虚拟机DRS组的成员不能在特定的主机DRS组成员上运行。
(2)用于指定各个虚拟机之间的关联性或反关联性。指定关联性的规则会使DRS尝试将指定的虚拟机一起保留在同一台主机上。根据反关联性规则,DRS尝试将指定的虚拟机分开,例如,当一台主机出现问题时,将不会同时丢失两台虚拟机。
OpenStack默认在所有可用主机上调度实例,对资源调度的指标粒度要比VMware vSphere的更精细,而且可以更方便地自定义过滤指标,由于可用于过滤的具体指标很多(参见Open-Stack官方手册),并且用户还可以自定义过滤指标,故此不可能一一说明,下面我们列举nova默认调度器Filterscheduler的主要過滤指标:
RetryFilter:重试过滤器,可以过滤掉在以前的调度中不成功的主机。
AvailabilityZoneFiher:为提高容灾性和提供隔离服务,可以将主机划分到不同的区域(Zone)中,在创建实例的时候可以指定实例创建在哪个可用区域中。
RamFiher:内存过滤器,将不能满足flavor(实例类型)内存需求的主机过滤掉。
DiskFiher,:磁盘过滤器,将不能满足flavor(实例类型)磁盘需求的主机过滤掉。
ComputeFilter:计算过滤器(保证只有nova-compute服务正常工作的主机—计算节点才能够被nova-scheduler调度)
ComputeCapabilitiesFilter,:主机(计算节点)特性过滤器,如主机架构等。
ImagePropertiesFilter,:镜像属性过滤器,依据镜像属性进行过滤,如:架构(architecture)、虚拟机监视器类型(hypervisortype)等。
Hosts Aggregates(主机聚合):主机聚合过滤器,根据主机聚合的CPU内核数、内存空间、磁盘空间、实例数、IO负载等指标对主机聚合进行过滤。
IoOpsFiher:并发IO操作过滤器,可以过滤掉并发IO操作超过max_io_ops_per_host的值的主机。
SameHostFiher、DifferentHostFiher:将新建实例调度到与其它实例相同或不同的主机上。
SimpleCIDRAffinityFilter:主机IP过滤器,可将实例调度到指定IP地址段的主机上。
ServerGroupAffinityFiher、ServerGroupAntiAffinityFiher:服務器组调度器,可以调度同一服务器组的实例位于相同主机上,或位于不同的主机上。
OpenStack不仅可以依据计算资源、存储资源、网络资源属性对主机进行过滤,还可以依据单元(cell)属性对主机进行过滤。
3)从高可用(HA)的角度,尤其是VM的高可用来看,VM-ware vSphere明显走在前面一通过DRS群集实现两个级别的高可用:vSphere HA能让故障虚拟机快速恢复、vSphere Fault Tol-eranee能保证虚拟机的持续可用。此外DRS群集的DPM(vSphere Distributed Power Management)功能可以根据群集资源利用率来打开和关闭主机电源,从而减少总体功耗。简单说,就是当DMP检测到群集中有足够多的空闲资源的时候,会关闭一台或多台主机以减少能耗;反之,当检测到空闲资源较少的时候,会打开处于待机状态的主机,并使用VModon将虚拟机迁移到这些主机上。而OpenStack实例的高可用还没有统一的解决方案,相关工作组正在进行这方面的工作,还处于初级阶段。
4)从用户的角度来看,OpenStack的控制节点管理所有资源,用户在使用资源的时候只需要向控制节点提出请求,具体的资源分配对用户来说是透明的;VMware vSphere的vCenterServer虽说管理所有资源,但作用更像是一个统一的顶层接口,用户在使用资源的时候要指明计算资源、存储资源的名称、位置等信息。
5)从批量部署的角度来说,OpenStack无论是在dashboard的horizon界面中还是命令行下,都可以轻松进行批量部署;VMware vSphere下的Web Chent每次只能创建一个虚拟机,如果要批量部署,就要通过稍显麻烦的脚本来实现。
6)从创建VM的效率上来说,同等条件下,OpenStack创建实例的效率要比VMware vSphere创建虚拟机的效率高出许多,可以说不可同日而语。
7)从资源调度的自主性来说,OpenStack作为开源软件,可以自定义资源调度方案、可以选择使用其它调度器分配资源,而VMware vSphere当然不会允许用户做这些自定义设置。
5结论
经过对上述两种平台的学习,以及本人在实际工作中使用这两种平台的体验,我认为在资源调度方面VMware vSphere仍然是传统虚拟化思维方式,而OpenStaek则是开放融合的云计算思维方式,从前文的对比中看出,除了在VM的高可用性方面OpenStaek稍逊一筹外,资源调度的其它方面OpenStack均表现出色。当然VMware vSphere在文档质量、易用性、某些性能的稳定性方面目前还是要强于OpenStaek。
使用VMware vSphere和OpenStack两款产品的对比,感觉就像是网络环境下使用Windows服务器和Linux服务器的对比:一商业、一开源;一易上手、一难入门;一自成体系、一组件成堆由用户组装;一成熟但前景不明、一青涩但潜力无限;一风光不再、一拥者日众……。
对IT工程人员来说,0penStaek相对于VMware vSphere的优势不仅体现在资源调度上,尽管部署一个OpenStack私有云环境要耗费的精力远多于VMware vSphere,但从系统运行效率、运维的性价比上来说,开始阶段的付出绝对是值得的。就像当年我们掌握了Linux服务器,就觉得不用考虑购买Win-dows服务器一样。
- 基于经济学视角下的农村劳动力转移和教育培训研究
- 三下采煤技术的探讨和构建
- 物价上涨对高校食堂改革的影响
- 我国厚煤层开采的技术研究
- 煤矿采掘工作面顶板管理问题的处理方法探析
- 浅议军品价格工作改革
- 古汉山矿1701回风巷巷道支护设计
- 中日政府金融审计主要特色差异及启示
- 局部煤柱下安全采煤技术分析
- 矿井煤矸分装分运实现绿色开采
- 企业工资薪酬相关费用列支问题探讨
- 大学生模拟创业实践平台体系建设研究
- 家庭农场会计核算之浅析
- 如何提升财务会计的职业判断能力
- 对上市公司进行财务报表分析的作用研究
- 企业人力资源管理创新问题研究
- 会计电算化对企业内控治理的影响
- 企业财务管理及改革策略探析
- 大学生开设特产专卖的社会意义
- 中小会计师事务所年度财务报表审计报告常见问题
- 试论如何实现更高质量的职业指导
- 会计审计以及会计财务核算浅析
- 浅谈我国个人所得税现状
- 浅谈企业人力资源开发
- 关于工程项目财务控制分析
- distractedness'
- distractednesses'
- distractednesses
- distractedness's
- distractful
- distractibilities
- distractibility
- distractible
- distracting
- distractingly
- distraction
- distractions
- distraction's
- distracts
- distraught
- distraughtly
- distraughtness
- distress
- distressed
- distressedly
- distressedness
- distressedness'
- distressednesses'
- distressednesses
- distressedness's
- 猪不吃,狗不啃
- 猪仔
- 猪你贵
- 猪倌
- 猪八戒
- 猪八戒上墙头——熟路一条
- 猪八戒上阵
- 猪八戒上阵——倒打一耙
- 猪八戒下凡——没个人模样
- 猪八戒下凡(猴子照镜子泥人儿掉在河里)——没个人模样
- 猪八戒倒打——翻脸不认帐
- 猪八戒倒打——翻脸不认账
- 猪八戒倒打一钉耙
- 猪八戒做梦娶媳妇儿——想得倒美
- 猪八戒做梦结婚
- 猪八戒初进高老庄——假充好汉子
- 猪八戒办事——既懒又不老实
- 猪八戒卖凉米线——人丑名堂多
- 猪八戒卖凉粉——人丑名堂多
- 猪八戒卖凉粉——样数不少,滋味儿不小
- 猪八戒卖豌豆粉,人丑作料多
- 猪八戒吃人参果
- 猪八戒吃人参果——不知其味
- 猪八戒吃人参果——不知贵贱
- 猪八戒吃人参果——全不知滋味