姜兴琼+杨德强

摘要:少数民族服饰图像识别有助于人们了解、认识、弘扬和传承民族文化。以少数民族服饰图像为研究对象,完成了图像增强,阈值分割,利用PCA方法提取少数民族服饰图像主成分特征,按照欧式距离取最小的原则得出图像的匹配度,实现了民族服饰图像的识别。实验结果表明,该算法平均正确识别率为64%左右。
关键词:阈值分割;图像增强;PCA;少数民族服饰识别
中图分类号:TP391.4 文献标识码:A 文章编号:1009-3044(2017)29-0195-04
Abstract: Ethnic minoritiescostumes image recognition helps people to know andunderstand the national culture, contributes to carry forward and inherit the national culture. In this paper, Based on ethnic minoritiescostumes image, this papercompletes the image enhancement, threshold segmentation, and employs PCA method to extract minority clothing image principal component characteristics, then obtains the matching degree of the imageaccording to the principle of minimum among the Euclidean Distance, implements the national costumes image recognition.The experimental results show that the algorithm has an average correct recognition rate about 64%.
Keywords:Threshold segmentation; Image enhancement; PCA; ethnic minorities costumesrecognition
1 概述
快节奏的现代生活,使得传统的少数民族服饰面临消失的危机,少数民族服饰文化的数字化保护和传承已经刻不容缓。随着科技的发展,已有一些先进技术手段被用于少数民族服饰文化的保护与传承[1]。龚成清提出了一种基于图片内容的感知哈希算法,将图片唯一地映射为一段数字摘要,即对每张图片生成一个“指纹”(fingerprint)字符串,然后比较不同图片的指纹,比对的结果越接近,就说明图片越相似[2];詹曙,王俊,杨福猛,方琪为了克服图像识别中光照,姿态等变化带来的识别困难,同时提高稀疏表示图像识别的鲁棒性,提出了一种基于Gabor特征和字典学习的高斯混合稀疏表示图像识别算法[3];陈微微提出基于分块的不规则图形相似比较的图像匹配算法[4];Szummer和Picard主要研究室内和室外图像的分类,在基于Ohta颜色空间中的颜色直方图的信息的基础上,利用K-近邻分类器对图像进行分类[5]等。
本文针对少数民族服饰图像,通过一系列的图像预处理后,利用PCA获取服饰图像的PCA特征,按照欧式距离取最小的原则进行图像识别。
2 算法的整体结构设计
整个算法主要由图像预处理、提取特征与图像识别等两个模块组成,其算法整体结构如图1所示。
图像预处理部分由图像灰度化、图像增强、阈值分割三个部分组成,利用加权平均法将彩色图像转换为灰度图像,运用直方图规定化扩展图像灰度值的动态范围,达到增强图像整体对比度,使图像的细节更清晰;使用迭代法确定阈值后,进行图像分割将图片中的目标与背景分割。
提取特征与图像识别模块由提取PCA特征、建立分类器、图像识别三个部分组成,主要完成利用PCA提取阈值分割所得到的目标的PCA特征,运用欧式距离建立分类器,并将PCA特征作为输入量输入分类器,对图像进行识别,并输出识别的结果。
3 图像预处理
由于图像容易受到图像自身和外界因素的影响,需要进行图像预处理,优化图像,减少计算量,保留有用的信息,尽量减少无用的信息。预处理主要包括图像增强、阈值分割。本文利用加权平均法把彩色图像转化为灰度化图像,如图2。
图像增强部分完成了直方图均衡化和直方图规范化,如图3和图4。
圖像分割有助于图像识别,图像分割质量的好坏直接影响后续图像处理的效果。阈值分割的基本思路是图像中前景区域即所提取的目标和背景区域属于两个不同的灰度集合,这两个灰度集合可以使用一个属于灰度级的阈值T进行分割,使图像分割为前景区域和背景区域。
迭代法基于逼近的思想,首先选择一个近似阈值T,将图像分割成两部分和,计算区域和的均值和,选择新的分割阈值,重复上述步骤直到和不再变化为止。本文分割结果如图5。
4 提取特征和图像识别
提取特征是图像识别的关键组成部分,提取特征的目的是为了尽可能地保留图像信息,以达到有效识别;特征提取的好与坏直接关系着图像识别的结果。本文采用了基于主成分分析PCA(Principal Components Analysis)来实现少数民族服饰图像的识别。
4.1PCA理论基础
主成分分析PCA(Principal Components Analysis)广泛地被应用在模式识别与数据压缩,其主要优点是对数据进行降维和去除冗余,其方法是利用样本的协方差矩阵进行特征分解,将其协方差矩阵的特征向量和特征值求出来,并找出其较大的几个特征值对应的特征向量作为所分析数据的主成分即PCA特征表示原数据,从而达到降维和去冗余的目的[6][7]。
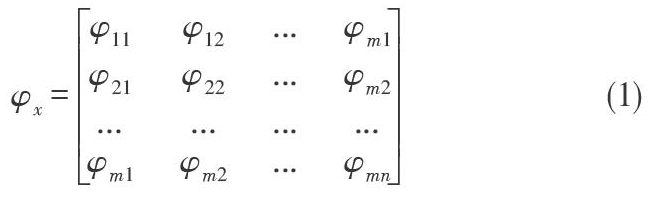
如果一个数据是n维矢量向量,记作,则向量X的协方差矩阵可以表示为:
其中对称矩阵,利用正交矩阵Q对数据做正交变换得
其中,Y的各分量之间互不相关,克服了原数据向量间的相关性,去除了只带有少量信息的数据,保留了能体现原数据的总体趋势的信息,以较少数量的主要特征描述原数据向量,达到降低维数的目的。具体流程如下:
假设有m个待处理的数据,令矩阵X用共n个数据表示,那么表示一个待处理的数据集。其中,。
(4) 排序。降序排列特征值,将特征值按从大到小的顺序排列,其对应的特征向量也从大到小的顺序排列。
(5) 计算总能量并选取其中的较大值。若为S的对角阵,那么总能量为对角线所有特征值之和S。由于在(4)里面已对V进行了重新排序,所以当前几个特征值之和大于等于S的90%时,可以认为这几个特征值可以用来"表征"当前矩阵,假设这样的特征值有L个。
(6) 计算基向量矩阵W。实际上,W是V矩阵的前L列,所以W的大小就是。
(7) 计算z-分数
(8) 计算降维后的新样本矩阵
其中,表示W的转置的共轭矩阵,大小为, 而Z的大小为 , 所以Y的大小为, 即降维为n个 L 维向量。
4.2 基于PCA的少数民族服饰识别
基于PCA的图像识别方法首先是要将样本图像转换成一个特征向量集,是样本图像的基本组件的集合,投影到特征表达空间即PCA子空间;然后把待识别图像提取的PCA特征投影到特征表达空间,通过计算它的投影点在特征表达空间里与样本图像PCA特征的欧式距离,按照欧式距离取最小的原则来进行识别。算法描述如下:
(1) 获取图像库中被预处理优化过的服饰图像集合T。设图像库中有N幅民族服饰图像,进行图像预处理后得到N个样本图像,每一个样本由其像素灰度值组成一个向量,则样本图像的像素点数即为的维数,由向量构成了N维的样本向量集,大小为。
(2) 根据公式(20)计算样本向量集T的平均向量u,得到均值图像.
(3) 根据公式(21)计算每一张图像与均值图像的差值x,即用T集合里的每一个元素减去(2)中所得的u,将样本图像中心化。
(4) 根据公式(22)计算协方差矩阵S。
(5) 求出协方差矩阵S的特征向量和特征值。
(6) 降序排列特征值以及与其对应的特征向量。
(7) 根据公式(28)计算出累计贡献率,然后根据累计贡献率从(6)中的特征向量中选出k个特征值对应的特征向量组成主成分
(8) 识别服饰,将得到的所有样本的PCA特征投影到PCA子空间,把待识别的图像进行优化之后提取PCA特征投影到PCA子空间,根据公式(14),找到某个样本PCA特征投影后的向量和待识别的图像投影后的向量距离最近的,即待识别服饰图像属于该样本所属的民族。
4.3 最近邻法分类器欧式距离
当PCA子空间中被投影了待识别少数民族服饰图像的PCA特征后,一般是通过计算出其与特征表达空间中服饰图像之间的距离,选择距离最短的,即属于该类。而在此选用了欧式距离:
其中,x表示待识别的服饰图像的PCA特征,y表示样本集内的某一个民族的服饰图像的PCA特征。
5 实验结果
本次设计是基于PCA的基础上,通过识别进行优化过的少数民族服饰图像,识别出民族。本实验MATLAB编程,图像库中一共有100幅图像,共有5个民族,每一个民族的服饰图像有20幅。测试时每一个民族选取了10幅服饰图像进行,该算法的实验结果如表1所示。
实验结果证明该算法的平均正确识别率为64%,该算法具有一定的可行性与正确性,其中,对布依族服饰图像的正确识别率达到了80%,哈尼族的68%,苗族的58%,佤族的56%,最后是白族的54%。布依族的正确识别率如此高,是由于该族的服饰边缘线条特别明显,与其他族的服饰差异很大。下面是对每一个民族的服饰图像错误识别情况统计。
从表2可以看出,白族的服饰图像有28%被错误识别为哈尼族,识别为佤族和布依族的都为8%,2%识别为苗族。被识别为苗族、布依族、佤族服饰图片是主要由于待识别的服饰图像的背景太过复杂,阈值分割效果不佳,且本文没有考虑光照对图像的影响;而被错误识别为哈尼族更多的原因是由于图像库中白族样本图像数量少,提取的特征不够典型。
表3中,哈尼族的服饰图像有22%被错误识别为布依族。图像库中哈尼族服饰图像有20幅,其中13幅为半身服饰图像,只有7幅是完整的服饰图像。
表4中,佤族的服饰图像有16%被错误识别为哈尼族,错误识别为白族和布依族的都为13%。图像库中佤族样本图像有20幅,其中11幅图像是多人的,只有9幅是单人图像,提取的PCA特征不够典型,不能够将佤族服饰图像的特征很好的表征。
表5中,布依族的服饰图像有12%被错误识别为哈尼族。图像库中布依族样本图像有20幅,其中6幅图像的背景很复杂,阈值分割效果不佳,且布依族服饰从外观、线条上跟其他四个民族有很大的差别。
表6中,苗族的服饰图像有26%被错误识别为布依族,错误识别哈尼族为8%,为白族和布依族的都为4%。图像库中苗族样本图像有20幅,其中7幅图像是多人的,还有10幅是半身服饰图像,提取的PCA特征不够典型,不能够将苗族服饰图像的特征很好的表征。
6 总结
本文通过实验对比分析直方图均衡化与直方图规定化的图像增强效果,结合少数民族服饰图像的特点,采用直方图规定化增强少数民族服饰图像,该算法可拉伸灰度范围,增加目标图像的对比度;运用双峰法、迭代法、OTSU法进行对比实验,实现前景与背景分离;采用最近邻法分类器,把通过PCA提取的PCA特征作为输入向量,实现图像识别,本文算法的平均正确识别率为64%,仍然还有很多工作需要进一步完善。
参考文献:
[1] 彭生琼,郭飞,詹炳宏,沈蓓.少数民族服饰特色资源库构建技术研究[J].制造业自动化.2015,37(4):44-47.
[2] 龚成清.基于Java的相似图片搜索[J].电脑开发与应用.2012,25(10):13-15.
[3] 詹曙,王俊,杨福猛,方琪.基于Gabor特征和字典学习的高斯混合稀疏表示图像识别[J].电子学报,2015,43(3):523-528.
[4] 陈微微.基于颜色特征提取的图像搜索引擎研究[D].重庆:重庆理工大学,2012.
[5] Szummer M.,Picard R.,Indoor-Outdoor Image Classification,IEEE International Workshopon Content-Based Access of Image and Video Databases CAIVD98[J],Bombay,India,1998:42-51.
[6] Weng.JJ.,1996.Crescepton and SHOSLIF:towardscompre-hensive visual learning. In:Nayar,,S.K.,Poggio.T.(Eds.)Early Visual Learning.Oxford University Press,pp. 183-214.
[7] 杜洪,夏欣,琚生根,王能.基于PCA圖像压缩算法研究与实现[J].四川大学学报:自然科学版.2014,51(5):910-914.
- 民营医院财务管理存在的问题及解决措施
- 大数据时代财务共享服务中心研究
- 试论基于企业互联网时代的财务会计风险防范
- 金融功能视角下的金融体制改革逻辑
- A股“垃圾股”退市难的原因及对策分析
- 探究“互联网+”时代企业财务管理的现状
- 高职院校图书馆服务创新的思考
- 论中小企业技术创新问题及对策
- 工学结合、校企合作育人模式下现代学徒制实践应用对策研究
- 高等院校智慧“云课堂”信息化教学设计的创新与实践
- 新形势下企业廉洁文化落地的探索与思考
- 浅谈企业政治思想工作中的问题及对策
- 浅议高校学院党政管理队伍的建设与培养
- 基层党员干部培训有效性研究
- 浅析火灾损毁林地的森林资源恢复
- 浅谈城市河道水环境综合整治
- 关于环境工程建设在生态城市的应用
- 京津冀环境可持续发展的影响因素
- 房屋租赁管理存在的缺陷和解决措施
- 谈计划生育档案管理存在的问题及对策
- 高层住宅建筑工程施工管理的探讨
- 房屋土建工程质量监督管理问题与强化建议探究
- 浅谈现代化城市轨道交通运输安全管理模式
- 人事档案管理对企业人力资源管理的意义和作用探究
- 浅谈河道管理部门如何做好长江生态环境保护工作
- sewery
- sewing
- sewing machine
- sewing machines
- sewings
- sewn
- sews
- sew sth up
- sew sth ↔ up
- sew up
- sex
- sex appeal
- sex ap peal
- sex drive
- sexed
- sexer
- sexes
- sexest
- sexier
- sexiest
- sexily
- sexiness
- sexinesses
- sexing
- sexism
- 含在嘴里怕化了,捧在手中怕丢了
- 含在嘴里怕化了,顶在头上怕吓了
- 含在嘴里都硌牙
- 含在眼里要流还未流下的泪珠
- 含垢
- 含垢包羞
- 含垢匿瑕
- 含垢受辱
- 含垢弃瑕
- 含垢忍污
- 含垢忍耻
- 含垢忍辱
- 含垢纳污
- 含垢藏瑕
- 含垢藏疾
- 含声儿
- 含奸
- 含孕
- 含孝
- 含宏光大
- 含宥
- 含宫咀征
- 含宫嚼征
- 含容
- 含容终有益,任意是生灾