摘要:分类算法是数据挖掘技术中非常重要的一个研究领域,预测离散数据的分类标号。主要应用于客户分类、垃圾邮件处理、信用卡分级等。该文主要研究分类中的决策树算法,并应用于我校学生招生录取数据,采用Python语言建立分类模型,并验证了该模型的准确率。
关键词:决策树;Python;招生数据
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)29-0016-02
1 决策树理论介绍
决策树算法是一种典型的分类算法,它的分类过程是基于样本数据建立一棵倒立的树的过程。从树的根节点到叶节点的路径实际就是决策的过程,确定数据样本所属类标号的过程,它是一个递归地从上到下确定分支节点和叶节点的过程﹒叶节点存放的是数据样本所属的类标号;分支节点根据数据样本的某个合适的属性值进行数据集划分[1]。
2数据介绍
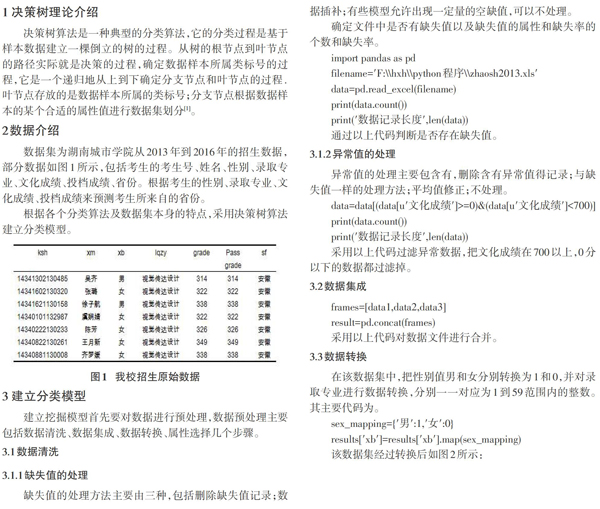
数据集为湖南城市学院从2013年到2016年的招生数据,部分数据如图1所示,包括考生的考生号、姓名、性别、录取专业、文化成绩、投档成绩、省份。根据考生的性别、录取专业、文化成绩、投档成绩来预测考生所来自的省份。
根据各个分类算法及数据集本身的特点,采用决策树算法建立分类模型。
3 建立分类模型
建立挖掘模型首先要对数据进行预处理,数据预处理主要包括数据清洗、数据集成、数据转换、属性选择几个步骤。
3.1数据清洗
3.1.1缺失值的处理
缺失值的處理方法主要由三种,包括删除缺失值记录;数据插补;有些模型允许出现一定量的空缺值,可以不处理。
确定文件中是否有缺失值以及缺失值的属性和缺失率的个数和缺失率。
通过以上代码判断是否存在缺失值。
3.1.2异常值的处理
异常值的处理主要包含有,删除含有异常值得记录;与缺失值一样的处理方法;平均值修正;不处理。
采用以上代码过滤异常数据,把文化成绩在700以上,0分以下的数据都过滤掉。
3.2数据集成
采用以上代码对数据文件进行合并。
3.3数据转换
在该数据集中,把性别值男和女分别转换为1和0,并对录取专业进行数据转换,分别一一对应为1到59范围内的整数。其主要代码为。
4结论
基于Python语言,对我校招生数据建立决策树分类模型,通过考生的录取年份、性别、录取专业、文化成绩、投档成绩预测考生所属省份,其准确率非常高。该预测模型对我校招生工作,学生的分布有一定的帮助。
参考文献:
[1]黄雪华. 决策树和贝叶斯分类算法在学生专业录取数据中的应用研究[J]. 湖南城市学院学报自科版, 2017, 26(4): 63-65.
【通联编辑:王力】
- 浅谈如何激发中职学前教育专业幼儿园教育活动设计与实践课程的学习动力
- 高校英语语法教学现状分析及策略探究
- 浅谈技校学生的心理问题及疏导策略
- 关于大学生英语演讲技巧探析
- 民间美术在校外教育中的开发及实施策略研究
- 基于学科核心素养的高三英语阅读教学实践
- 基于文化对等视角的大学英语翻译教学研究
- 基于数据挖掘的高校学生干部作用分析
- 基于民间传统游戏的幼儿教学活动研究
- 高职院校课程思政的瓶颈与对策研究
- 大学生体育核心素养培育及价值研究
- 刍议初中语文教学中如何有效地开展主题式名著阅读
- 《建筑材料》课程实践教学研究
- 数形结合思想在初中数学学习中的渗透研究
- 加强课外阅读指导对良好阅读习惯的培养研究
- 和善与坚定并行的正面管教
- 大学生积极社会心态培育的形式和路径研究
- 打造“本土特色”社区教育品牌项目的思考
- 从爱出发,从点滴做起
- 汽车英语翻译方法与技巧研究
- 试论教育生态环境下柔性管理文化与独立学院教师发展的融合
- The Literature Review of Attribution Theory
- 中等职业学校数学教学中存在问题及对策分析
- “1+X”证书制度背景下《建筑综合识图》课程教学改革研究
- 研究“互联网+”助力小学语文阅读教学的整合与创新
- exchange
- exchangeabilities
- exchangeability
- exchangeable
- exchangeably
- exchange/change/return
- exchange contracts
- exchangecontrol
- exchange conˌtrol
- exchanged
- exchangeeconomy
- exchange eˌconomy
- exchange market
- exchangemarket
- exchangeofshares
- exchangerate
- exchange rate
- exchangerateexposure
- exchange rate exˌposure
- exchangeratemechanism
- exchange rate mechanism
- exchangers
- exchanges
- exchange²
- exchange¹
- 玉莲
- 玉莹
- 玉葬香埋
- 玉葱
- 玉蕊
- 玉蕗藤
- 玉蕙
- 玉蕤
- 玉薤
- 玉藓
- 玉藕
- 玉藻
- 玉虎
- 玉虚
- 玉虚饭
- 玉虫
- 玉虬
- 玉虹
- 玉蚁
- 玉蚕
- 玉蛆
- 玉蛾
- 玉蜀黍
- 玉蜍
- 玉蝉