温海标


摘要:不平衡数据集的特点是类样本数量差异比较大,K近邻(K-Nearest Neighbor,KNN)算法在对这种数据集分类时,容易出现多数类偏向,即容易将少数类识别为多数类。LLRKNN算法是为了降低多数类偏向的影响,对K近邻样本进行重构得出权值,算法分类决策由K近邻样本的权值决定。实验结果表明,LLRKNN算法对不平衡数据集的性能优于KNN算法,具有更好的稳定性。
关键词:不平衡数据;分类;K近邻;重构
中图分类号:TP311? ? ? ? 文献标识码:A? ? ? ? 文章编号:1009-3044(2018)36-0238-02
Abstract: Unbalanced data sets are characterized by large differences in the number of class samples. K-Nearest Neighbor (KNN) algorithm is prone to majority class bias when classifying such data sets, that is, it is easy to identify minority classes as majority classes. LLRKNN algorithm is designed to reduce the influence of most class bias. The weights of K-nearest neighbor samples are reconstructed. The classification decision of LLRKNN algorithm is determined by the weights of K-nearest neighbor samples. The experimental results show that the performance of LLRKNN algorithm for unbalanced data sets is better than that of KNN algorithm and has better stability.
Keywords: imbalanced data; classification; K nearest neighbour; reconstruction
数据样本分类是利用已收集的数据样本,对未知样本类别的新样本进行样本类别预测。在样本收集过程中,常常由于某些类别的样本数据难以收集,从而导致数据样本集中一些类别样本占少数,形成不平衡样本集,例如医学肿瘤特征数据集中,恶心肿瘤特征数据占少数。
在机器学习的实际应用中,大多数分类训练样本集是非平衡的,有研究表示[1],非平衡样本集会影响机器从中学习的规则的准确性,而且失衡度越大,即各类训练样本数量差异越大,影响就越大。因此,如何优化传统分类方法,以提升对不平衡数据分类性能是目前机器学习领域里研究热点之一。
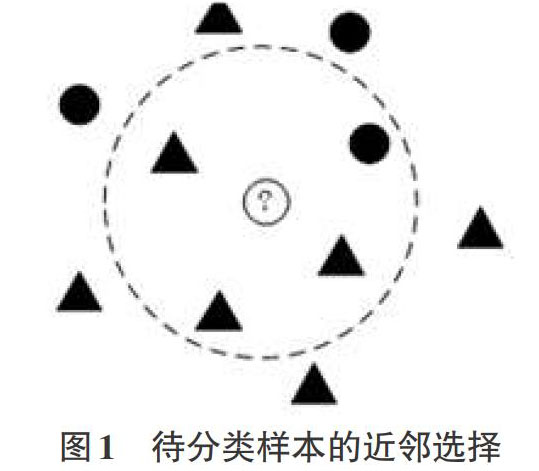
常见的传统分类方法有:支持向量机、决策树、随机森林、神经网络等。其中K最近邻方法是选取K个待分类的近邻样本,以少数服从多数的规则,决定待分类样本的类别,其原理简单,易实现,得到广泛研究。当采用K最近邻方法对不平衡数据分类时,该方法的缺点时明显的,如图1,当K=4时,即待分类样本选取4个近邻点,根据KNN的“少数服从多数”规则,将待分类样本的类别确定为三角形类。而待分类样本的实际类别是圆形类,该方法在此错分类的根本原因是“少数服从多数”的分类决策规则。因此使用K最近邻方法对非平衡数据分类时,容易出现多数类偏向问题,分类准确率通常较低。本文采用局部线性重构方法,得出近邻样本的权值,根据各样本类别的权值比重决定待分类样本的类别,以优化K最近邻方法分类决策规则,降低分类器对多数类的偏向。
1 LLRKNN算法
1.1 算法原理
LLRKNN算法的基本思想是对待分类样本的K个近邻点加权,减少多数类对分类决策的影响。其基本原理是待分类样本可以被其局部领域内的近邻样本点采用重构方法[2]线性表示,重构的目的是得出各个近邻样本的权值,待分类样本类标号由各类别的权值确定,而不是各类别样本数量决定。LLRKNN算法分为预处理和类标号决定阶段,预处理阶段中把数据集中类标号未知的样本作为待分类样本,其他为训练样本,為了降低各个样本的属性值范围不一致对选取近邻点造成影响,将样本的非类标号属性值采用最小最大规范化法[3]转换为[0,1]之间。类标号决定阶段主要工作是采用欧式距离函数[4]计算出待分类样本与训练样本的距离值,选择的K个离待分类样本最近的样本作为局部领域内样本,通过重构得出局部领域内每个近邻样本的权值,计算近邻样本各类别的权值,最后统计出最大权值的类,将其类标号赋予待分类样本。
1.2 算法步骤
训练样本集记为[Xx1,x2,…,xn ,X∈Rd×n],待分类样本[y∈R1×d],其中 n为样本数,d为样本属性个数。
步骤1 把样本的所有非类标号属性值规范化为[0,1]区间,如下式:
式1中,A为样本的非类标号属性,max和min分别表示该属性的最大和最小值。
步骤2 通过欧氏距离函数计算出待分类样本与所有训练样本的距离:
根据式2计算的结果值,选取K个与待分类样本距离值最小的样本作为局部领域近邻样本。
步骤3 局部领域近邻样本线性重构待分类样本,通过如下式得出每个近邻样本的权值:
式2中,[N∈Rk×d]是近邻样本矩阵,[W∈R1×k]为存储了每个近邻样本的权值向量。
步骤4 通过计算式2得出每个近邻样本的权值,,根据下式计算待分类样本与每类别近邻样本的线性组合的差值,差值最小的类作为待分类样本类标号:
其中i表示近邻样本某一类的标号,[W*i]表示属于i类的近邻样本权值向量,[N*]表示属于i类的近邻样本矩阵,[y*]表示待分类样本类标号。
具体算法如下:
[算法1? ? LLRKNN算法 输入:训练样本集X,待分类样本y
局部领域近邻个数K
输出:待分类样本类标号
1:[Xy←normailze[0,1]Xy]
2: for i = 1 to n do
3:? ? [d←1×n] 零向量,元素为距离值
4:? ? [d←disty,xj]
5:? end for
6:? ? [N←]根据距离,选取K个近邻样本
7:? [W←argminWi=1mWN-y22]
8:[st.W·1T=1]
9: [y*←argminiy-W*iN*] ]
2? 实验设计
2.1 数据集
实验部分使用的4个数据集选自UCI数据库[5],基本信息如表1所示:
2.2 评价标准
测试分类方法的标准通常采用准确率,准确率高,说明分类效果好,但对不平衡数据分类,采用准确率是不合适的,因为错分少数类的样本对整体分类准确率影响不大。因此,本次实验采用基于混淆矩阵(Confusion Matrix)的F-value,该值更能测验分类方法的性能。
混淆矩阵如下表所示:
其中参数[β]用于调整查全和查准率的影响程度。实验部分将[β]值设定为1,表示查全和查准率的影响程度相当。
2.3 实验结果与分析
实验采用五折交叉验证法,将每个数据集等分五份进行五次实验,每次实验记录查全率和查准率,并计算F-value数据,每个数据集进行五次实验的F-value数据如图2;其均值和标准差如表3所示,算法采用MATLAB编程实现。
由表3可知,用F-value值作分类器的评价标准时,LLRKNN算法比KNN算法提高8.7%~32%,说明LLRKNN算法对不平衡数据分类的性能要优于KNN。各个数据集的标准差值LLRKNN算法比KNN算法小,说明LLRKNN算法有更好的鲁棒性。从图2可以看出各数据集五次实验的F-value值分布,也可看出LLRKNN算法更稳定。
3 结束语
LLRKNN算法是对待分类样本的K近邻进行线性重构得出相应的权值,在分类决策阶段使用权值计算待分类样本与近邻样本类别的重构误差,误差最小的类作为分类样本类别,优化了KNN算法的分类决策方法,一定程度降低多数类偏向的影响。实验中通过对比F-values值,结果表明LLRKNN算法对不平衡数据分类效果更好。
参考文献:
[1] Wang B X, Japkowicz N. Boosting support vector machines for imbalanced data sets[J]. Knowledge & Information Systems, 2010, 25(1):1-20.
[2] Zhang L, Chen C, Bu J, et al. Active Learning Based on Locally Linear Reconstruction[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(10):2026-2038.
[3] JiaweiHan, MichelineKamber, JianPei,等. 數据挖掘概念与技术[M]. 机械工业出版社, 2012.
[4] Pang-NingTan, MichaelSteinbach, VipinKumar. 数据挖掘导论:完整版[M].2版. 人民邮电出版社, 2011.
[5] UCI repository of machine learning datasets[DB/OL].http://archive.ics.uci.edu
[通联编辑:唐一东]
- 浅议新形势下如何做好小学思想政治工作
- 民间体育游戏在幼儿园的传承与创新
- 浅谈小学年级音乐创作能力的培养
- 浅析“留学垃圾”的产生及原因
- 基于京剧审美元素 建立有效审美评价
- 浅析体育游戏在幼儿园体育教学中的运用
- 试论如何提高小学美术课堂教学的有效性
- 植根乡土资源 培养爱国情怀
- 小学德育管理中渗透中国传统文化的实践研究
- 你是我的缘
- 远程美术教育与贵州农村美术教育的发展
- 小学音乐教学趣味性提升策略探讨
- 浅谈小学音乐教学中的创新教育
- 简析体育游戏在小学体育教学中的重要性
- 德育教育在小学数学教学中的渗透
- 教与学其乐融融,小学音乐教学中如何增强学生互动意识
- 学科核心素养本位的小学美术欣赏课教学实践研究
- 提升高职学前教育专业学生幼儿舞蹈编创能力的策略研究
- 音乐活动中审美能力的培养
- 艺术教育对孩子成长的重要性
- 浅谈小学美术教学中如何提高学生学习兴趣
- 在游戏中培养幼儿良好行为习惯
- 幼儿园后勤安全管理工作探讨
- 浅析幼儿绘本阅读教学策略
- 浅析幼儿教育中的家园合作应用
- unborne
- unborrowed
- unbotanical
- unbothering
- unbottle
- unbottom
- unbottoming
- unbottoms
- unbountiful
- unbountifully
- unbountifulness
- unbountifulnesses
- unbowdlerized
- unboyish
- unboyishly
- unboyishness
- unboyishnesses
- unbraceleted
- unbracketed
- unbragging
- unbrake
- unbraked
- unbrakes
- unbraking
- unbran
- 陪京
- 陪人饮酒
- 陪仆
- 陪从
- 陪从或伺候尊长、主人
- 陪从接续词
- 陪从祭祀
- 陪从连词
- 陪价
- 陪会
- 陪伴
- 陪伴·称量词
- 陪伴丧家把死者入棺
- 陪伴做某事
- 陪伴同宿
- 陪伴同行
- 陪伴奉侍
- 陪伴客人
- 陪伴帝王出游
- 陪伴招待
- 陪伴服侍
- 陪伴权贵游乐的人
- 陪伴着一同进行某项活动
- 陪伴着坐
- 陪伴着睡