李博涵 蔡永香 邓舒颖 王督


摘要:该文尝试将序列模式挖掘算法Prefixspan应用于中文文本新词提取中,针对Prefixspan算法挖掘出的序列模式不连续、挖掘出的序列模式项相互间存在包含关系等问题,对算法进行改进,采用语义特征与统计相结合的方法,实现了从中文语料中有效提取新词。实验结果表明,该方法对于专业领域新词的识别具有较高的准确性。
关键词:Prefixspan;序列模式挖掘;新词提取;投影数据库;新词发现
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2018)08-0160-04
1概述
新词不仅仅指词典的未登录词,更是指带有大量修饰语的复合词。
新词发现在自然语言处理领域中的机器翻译、信息检索、文本分类、文本摘要、领域本体等领域都有广泛的应用。对中文文本中的新词进行正确发现、提取并加以利用,构建专业领域专业词汇词典,可以为进一步信息过滤、内容分类以及信息聚类提供帮助。关于新词提取,目前主要的方法是通过对词语在文本中各种特征进行分析,利用监督学习或者无监督学习建立抽取模型,进一步提取新词。而新词在文本中的特征主要可以分为语义特征与统计特征两种,统计特征主要指的是词语的一些通过数学统计得到特征,如词频、词语位置、TFIDF值等。而语义特征指的是词语的词义特征,如词语的词性、词汇链特征、词语之间的相关度等。针对这两类特征,通常分别采取基于语义特征的获取方法或者基于统计的获取方法,或者将二者结合起来。一般情况下,基于统计特征的新词抽取方法相对比较简单、通用性比较强,如基于词频统计的抽取方法、基于TFIDF值的抽取方法,基于词共现的抽取方法等;基于语义特征的方法一般比较复杂,抽取效果较好,但在构成模式的规定上,新词的构成模式易与旧的构成模式造成冲突,较难维护。现在大多数研究者采用两者结合的方法,发挥各自的优势,提高新词发现的效果。
经过对中文文本中出现的新词分析发现,新词的序列具有顺序特征和连续性,且大多数以较长的固定组合形式多次出现在语料中。序列模式挖掘算法适合挖掘这种出现频率高的模式,但这种算法挖掘出的是离散型序列。本文对序列模式挖掘算法Prefixspan进行改进,使之适用于连续性序列模式的挖掘,并应用于中文文本新词提取中,并采用语义特征与统计相结合的方法实现从中文语料中提取新词。实验结果表明,这种方法对于新词的识别具有较强的准确性。
2改进的Prefixspan算法
给定一个序列或者由多个序列组成的序列数据库,同时给定一个用户指定的最小支持数阈值,序列模式挖掘就是应用数据挖掘技术找出所有出现次数不小于用户设定阈值的子序列。
序列模式挖掘是由Agrawal和Srikant于1995年首先提出的,随后他们提出了广义序列模式(GSP)挖掘算法;序列模式挖掘的模式增长方法PrefixSpan,以及它的前驱算法FreeSpan则由Han等人与2001年提出,其中PrefixSpan算法因包含更少的投影库和子序列连接而被广泛应用于序列模式挖掘中,比GSP算法和FreeSpan算法性能更优。国内外的学者对PrefixSpan提出了很多优化改进方案。例如在陆介平等人提出的ISPBP算法,用增量数据库来减小投影数据库,提高了算法效率;张坤等提出的SPMDS算法,将投影数据库是否相等的判定问题转化为伪投影是否相等的问题,对前缀树做索引,简化搜索代价;韩高伟针对现有的序列模式PrefixSpan算法提出了一种增量式数据流双重加权序列模式算法DWC-SP-MDS,利用增量式方法更新挖掘结果,同样提高了运行效率。这些改进的算法在运行效率、内存使用、算法可扩展性上均有了优化,但因为挖掘出的序列模式具有离散型的特征,不能直接用于中文连续性文本模式的挖掘。
2.1 Prefixspan算法
Prefixspan是一种使用数据库投影技术的深度优先搜索算法,它具备处理大序列数据库的能力。主要思路是:首先进行频繁项的产生和挖掘工作,使用频繁前缀划分空间,针对每一个频繁项经过投影,各自产生一个投影数据库,从而生成投影数据库集合。然后采用分治的策略,不断产生更多、更小的投影数据库,在各投影数据库上进行序列模式挖掘。相关基本概念如下:
序列数据库S是元组
Prefixspan的具体算法可参考文献。
2.2改进的Prefixspan算法
对中文文本尤其是科技新闻类文章中出现的新词进行分析发现,构成新词的短语或字具有顺序特征和连续性,且大多数以较长的固定组合形式多次出现在语料中,运用序列模式挖掘算法Prefixspan可以将这样的固定组合的形式提取出来,但在实际应用中仍存在以下兩方面的问题:
1)在构建投影数据库时,Prefixspan算法舍弃了对非频繁项的存储以及对投影序列数小于最小支持度的投影数据库的扫描,然后依次从序列中的若干子序列中扫描是否存在频繁项集。这种方式可以不用扫描不可能出现频繁序列的子序列,但这样获取的序列模式是离散的,前后序列在原文本中可能是不连续的,这样的模式不满足词语的连续性要求。
2)Prefixspan算法挖掘出的满足条件的序列模式项相互间可能存在包含关系,新词发现需要对这种情况进行筛选处理。
针对上述问题,我们进行以下几方面的改进:
1)考虑到既要减少迭代次数,又要保证挖掘的序列模式具有连续性特征,在构建投影数据库时,需构建两个不同的频繁序列集合,其一用于删除非频繁项,构建一个初始的频繁序列集合ItemSet1,在投影时不再扫描投影序列数小于最小支持度的投影数据库;其二用于不删除非频繁项集,获取当前前缀在各个序列中的局部频繁项,组成一个新的频繁序列集合Item-Set2,用于对后续的满足支持度要求的后缀进行递归挖掘;在进行投影数据库的生成和扫描的过程中,省略在后续的多元素项中判断是否包含此元素的步骤,只需要判断当前子序列中的下一个元素是否符合阈值要求即可,从而减少投影数据库的规模及扫描投影数据库的时间。
2)对挖掘出来的候选新词集进行进一步的筛选,包括①候选新词集中需舍弃掉模式序列个数为一的词语,因为这些词是分词时就直接划分出的词,说明这些词已经在词库中存在,不是新词;②词性语义过滤;③当候选词之间存在包含的关系时,在满足同等阈值的情况下,通常情况是短语越长,内涵越多,所以将被包含项舍弃掉。
3中文文本新词提取方法
基于上述该改进的Prefixspan方法,我们进行中文文本新词提取方法如下:
1)使用NLPIR汉语分词系统对语料库中的语料进行分词与词性标注准确性,并将中文文本转换为序列数据集;
2)利用改进的Prefixspan算法从序列数据集中递归挖掘候选新词集;
3)对得到的候选新词集进行筛选过滤,这包括对词库中已经存在的旧词过滤,对词性语义过滤以及对有包含关系的词语进行取舍等;
4)将筛选得到的新词加入新词词典。
中文文本新词提取的方法实现主要由文本预处理模块、新词挖掘模塊、候选词过滤模块等三个子模块组成。具体过程如图1所示:
3.1文本预处理
中文语料的格式不一,在序列模式挖掘前需要进行文本预处理。文本预处理包括分词标注和序列数据集转换。分词标注是利用已有的词库对文本进行分词处理,为了方便进一步的词性语义过滤,还需要对词性进行标注。本文是采用汉语分词系统NLPIR的jna分词包进行分词与词性标注,分词的结果以“单词/词性”格式返回。
序列数据集转换是将分词与词性标注后的语料转换成可以进行模式挖掘的数据集序列。即需要将语料转换为2.1描述的序列数据库S的过程。考虑到新词可能会在一个句子中的若干分句多次出现,我们将每个分句都当做一个序列来进行处理。
以下面这段中文语料为例:
12月6日,俄罗斯西布尔公司派出技术人员到镇海炼化参观考察。标志着镇海炼化乙烯裂解装置的在线实时优化项目已成为海内外同行业共同关注的焦点。
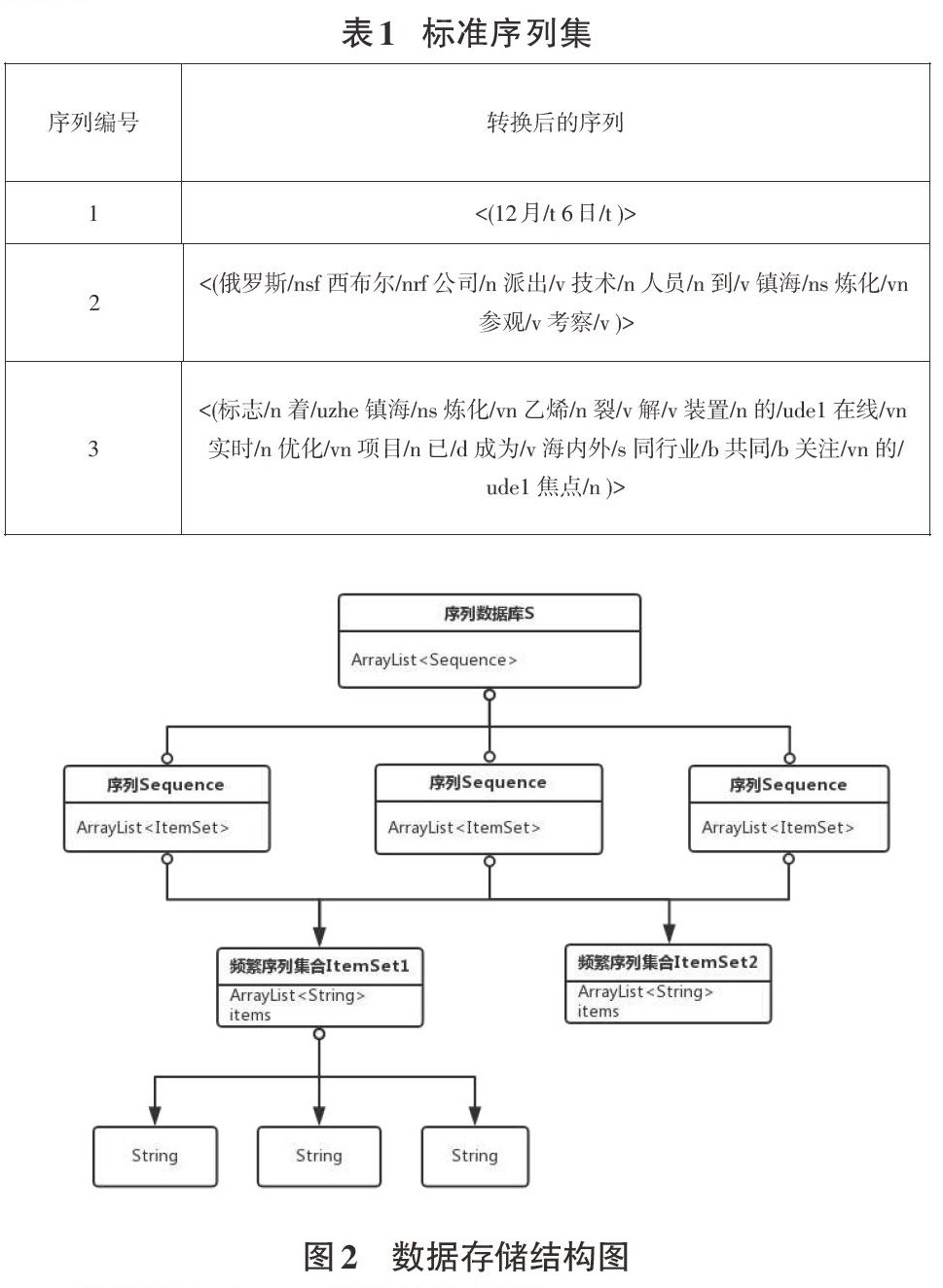
将上述语料转换为标准序列集,转换的部分序列如表1所示:
3.2利用改进的Prefixspan算法进行候选新词发现
ItemSet(字符项集类)
包含属性为:字符ArrayList
按照Prefixspan改进算法,构建投影数据库时,需构建两个不同的频繁序列集合来存储序列以及元素,分别为ItemSet1与ItemSet2;具体的数据存储结构如图2所示。
改进的Prefixspan算法描述如下:
输入:序列数据库S和最小支持度阈值minSupportRate
输出:所有的符合的新词集合
方法:
1)扫描序列数据库S一次,得到模式序列个数为一的频繁序列组成频繁序列集合ItemSet,删除其中的非频繁项,并将频繁项按其支持度从大到小排序,得到ItemSet1。其中,最小支持度min_sup=(最小支持度阈值minSupportRate*序列总数n(S));
2)依次对频繁项进行投影,构建相应的投影数据库,并对每一个投影数据库递归地进行挖掘。其中对每一个频繁项,构建相应的投影数据库,对投影数据库扫描一次,删除ItemSet1的局部非频繁项,得到其局部频繁项ItemSet2。判断当前前缀是否符合最小支持度阈值,如果符合,继续迭代,对投影数据库作关于ItemSet2中符合条件前缀的投影,此时的前缀为满足条件的候选新词;如果条件不满足,则停止当前频繁项的递归,对下一频繁项进行最小支持度阈值的判断;迭代中,局部频繁项与上一步得到的除当前频繁前缀记为α以外的频繁项是相同的;
3)判断递归结束条件,得到候选新词集。
3.3候选词过滤
在候选词过滤模块中我们对候选新词集进行过滤,得到最终的新词集加入新词词典。候选词过滤主要包含三个主要方面:
1)候选新词集中需舍弃掉模式序列个数为一的词语,这样的词出现频率虽然很高但不属于新词;
21词性过滤
抽取出的候选新词包含词性信息,例如『构建/v物/ng联网/vi信息/n模型/n],其词性组合为[v+ng+vi+n+n]。我们实验采用的文本都是油气行业新闻,通过分析总结油气行业领域词库中词汇的词性组成结构,得到了一些常见新词的词性组合模式,我们用这些词性组合模式进行候选新词的过滤。
在词性匹配时,可优先采取对第一个词的词性以及最后一个词的词性进行控制,以提高效率。例如新词通常情况下不以介词(p)结尾,通常以名词(n)结尾;当词语由[m+q]即数次和量词组合而成时,予以舍弃。
3)当保留下来的候选词之间存在包含的关系时,在满足同等阈值的情况下,通常情况下是短语越长,内涵越多,因此,我们将被包含项舍弃掉。我们过滤的步骤是,先对前缀相同的候选新词进行包含项过滤,如“大庆油田”与“大庆油田采油六厂”,我们可以将“大庆油田”过滤掉,保留“大庆油田采油六厂”为新词;再对前缀不同的包含项过滤,如“山东销售分公司”与“润滑油山东销售分公司”,我们将“山东销售分公司”过滤掉,保留“润滑油山东销售分公司”为新词。
通过上述方法保留下来的词作为新词加入新词词典。
4方法检验
以油气行业新闻作为对象进行方法检验,本文以中国石油新闻网2017年12月份的三篇新闻为提取对象进行方法检验,并与用NLPIR进行新词发现的结果进行了对比。这三篇新闻标题分别为:“华南成品油管网输量首次突破2000万吨”、“金陵石化油品质量升级改造项目通过竣工验收”、“荆门石化连续重整装置开创国内首次在线换剂”。实验结果如表2所示。从表中可以看出:1)随着最小支持度阈值的增大,采用本文方法发现的新词从较长的序列模式中分离保留下来,越来越精炼,这些词作为新词还是很有道理的;2)与NLPIR所发现的新词结果相比较,两者的重叠度还是较大的,当最小支持度阈值较大时,部分NLPIR发现的词在本文方法结果中没有,如序号为1的文档中NLPIR发现的新词“优化管道运行,管输,输量”在本方法中最小支持度阈值设为0.17时没被发现,但在阈值设置较小时(最小支持度阈值设为0.13时),这些词都被发现了,这说明本文方法发现模式序列的能力是具备的,关键是采用适当的最小支持度阈值。另外也存在采用本文方法发现的新词在NL-PIR中没被发现的情况,如序号为3的文档中,本文方法发现的“在线换剂”,NLPIR就没有发现,我们对原文检查发现,该词在原文中出现了5次,人工可以判定该词为新词。
前面的实验分析结果表明,本文提出的基于改进的Prefixs-pan算法的中文文本新词提取方法对于专业领域新词的识别具有较强的准确性,采用这种方法来完善词库具有可行性。只是最小支持度阈值的选取目前还是靠经验给定,因此还需要进一步优化,达到能够根据环境条件自动进行参数调整,来提高该方法的运行效率。
- 推进民营企业档案工作发展的探索与思考
- 优质阅读专题建设·学校文化创新力·高职院校优秀文化传承与创新
- 如何在图书馆教育教学中培养学生的阅读兴趣
- 公共图书馆信息化建设的现状与对策探讨
- 新时期档案信息化管理研究
- 档案资料收录与整编流程的规范化
- 公立医院办公室档案管理特征与策略探究
- 公共图书馆电子阅览室免费开放后的服务与管理
- 浅析农业科技推广档案的管理与利用
- 加强事业单位档案管理信息化建设的有效策略研究
- 中职学校图书馆的建设和管理思考
- “互联网+”背景下档案潜在用户研究
- 有关以人为本提升企业信用融资担保服务档案管理水平的思考
- 事业单位人事档案管理新思路探讨
- 新形势下加强文书档案管理工作的探讨
- 多媒休技术在博物馆展陈设计中的应用
- 图书资料管理的改革与创新探究
- 新时期基层图书馆可持续发展的对策分析
- 为了忘却的纪念
- 对公共图书馆古籍管理现代化的思考
- 高校档案的数字化建设策略及网络化应用研究
- “互联网+”模式下档案信息化建设思考
- 浅谈互联网思维下图书馆服务变革
- 做好基层卫生防疫档案管理工作的研究探讨
- 国土资源档案信息化建设的思路
- redebating
- redebit
- re-debit
- redebited
- redebiting
- redebits
- redecay
- redecayed
- redecaying
- re-decays
- redecays
- redeceived
- redeceives
- redeceiving
- redecided
- redecides
- redeciding
- redecision
- redecisions
- redeclaration
- sister
- sister companies
- sister company
- sistercompany
- sisterhood
- 沮湿
- 沮溺
- 沮溺结耦
- 沮溺耦耕
- 沮滞
- 沮激
- 沮畏
- 沮短
- 沮索
- 沮胆
- 沮舍
- 沮苍
- 沮衂
- 沮解
- 沮訾
- 沮诎
- 沮诽
- 沮谢
- 沮败
- 沮遏
- 沮陷
- 沮颜
- 沮骇
- 沱
- 沱汜