曾小芹 余宏

摘要:文本情感分析是自然语言处理的重要过程。研究首先运用Selenium爬虫抓取评论文本,通过Jieba分词工具对文本进行分词、词性标注及关键词词云的生成,再选用适用于中文文本处理的snowNLP库对评论文本进行情感计算和结果可视化,并通过准确率和召回率验证了研究结果,将对结果进行了详细分析。最后,给出了进一步研究方向。
关键词:中文文本情感分析;SnowNLP;Python;NLP
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2020)08-0181-03
文本情感研究是计算机语言学、人工智能、机器学习、信息检索、数据挖掘等交叉领域的研究热点,具有高度综合性和实用性。文本情感分析就是对文本的显性主观性或隐性关联性信息进行分析,让机器感受人类的感情从而更深入地理解人类语言,为自然语言处理(NLP)的研究提供有效帮助。而NLP在诸多实际应用如个性化推荐系统、信息安全过滤系统、网络用户兴趣挖掘、网线预警系统等的决策制定中都有产生带来巨大的经济、社会效益。为此,对文本情感识别具有重要的学术研究意义及社会经济价值。
1 主要相关技术简介
1.1 SnowNLP库
Python有多个工具库用于自然语言处理,但绝大多数是针对英文的处理。由于中英文的诸多差异,很多库不能直接拿来使用,要扩展也不简单。SnowNLP库是一个用Python语言编写的专门处理中文文本的类库,与其他类库不同的是它的实现没有依靠NLTK,所有算法均是自主实现,且自带语料库和情感字典。SnowNLP支持多种中文文本处理操作包括:中文分词、词性标注、情感分析、文本分类、转换成拼音、繁体转简体、提取文本关键词、提取文本摘要及计算文本相似度等[1],功能十分全面。
1.2 Selenium爬蟲
传统的爬虫通过直接模拟HTTP请求来爬取站点信息,但当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创版权得不到保护,且传统的方式和浏览器访问差异比较明显,当前很多网站网页都有反爬虫机制,要想获取网页内容就没有那么轻松了。Selenium是自动化浏览器技术,通过驱动浏览器来模拟真实浏览器完成网络行为,最终拿到网页渲染后的信息。整个过程就如真正的用户在操作,为此,它用于爬虫躲避反爬机制再合适不过。Selenium爬虫支持多种语言及多种浏览器.不用去分析每个请求的具体参数,比起传统的爬虫开发起来更容易,它唯一的不足是速度慢,如果对爬虫的速度没有要求,那使用Selenium是个非常不错的选择。当然,在实际的操作过程中,还会遇到很多意外,比如,虽然Selenium完全模拟了人工操作,给反爬增加了困难,但如果网站对请求频率做限制的话,Selenium同样会被封杀,所以通常还得给浏览器设置代理技术等。
2 SnowNLP库情感分析
文本情感分析又称为文本倾向性分析和意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理预测的过程,其中情感分析还可以细分为情感极性(倾向)、情感程度及主客观分析等。一般来说,情感可以从多层次、多角度进行分类,中国传统文化中就有“七情”——好、恶、乐、怒、哀、惧和欲。在实际的语言应用场景中,不能对一个文本进行一分为两的划分,且情感倾向存在极性和强度,不能单纯地将情感词归为某一类等问题。为此,为了精准计算文本情感值,文本情感分析行为应该建立在当前基准情感词典基础上,关注文本词语在不同情感类别中的强度值,计算出不同语境下词语情感,进而得到文本情感值。当然,本文为简化处理,暂时将文本情感划为两类,关于情感极性与强度的衡量问题将作为下一研究阶段的重点。
利用SnowNLP库的文本情感分析的基本流程如下:
(1)自定义爬虫抓取信息保存至文件。根据研究需要可抓取不同字段信息保存到不同类型的文件。Selenium爬虫首先要创建浏览器句柄即加载浏览器驱动,再定位页面元素来获取信息文本。
(2)中文分词、词性标注及可视化显示关键词。中文分词工具也有很多,snowNLP本身能完成,但其准确率不如Jieba分词,为此,本次研究采用Jieba完成分词等工作。为了直观表现、对比文本关键词的重要性,采用WordCloud生成词云的形式来完成结果的可视化步骤。
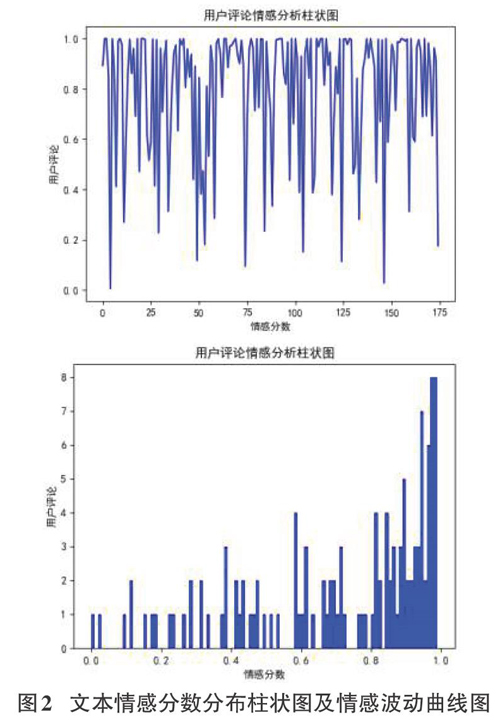
(3)情感计算,结果可视化。snowNLP中情感计算实现过程很简单,只要文本调用sentiments方法即可,具体使用见实例。但其实在sentlments方法中调用了sentIment下的分类方法,Sentiment对象首先调用load方法加载训练好的数据字典,然后再调用classify方法,在classify方法中实际调用的是Bayes对象中的classify方法,具体可查看SnowNLP库中的sentIment文件夹下的一init_文件等。再运用Matplotlib生成情感分数分布柱状图和情感波动曲线图来实现结果可视化。
(4)结果评估。结果可以使用准确率、召回率来衡量。召回率用来度量完整性或灵敏度。较高的召回意味着更少的假负,而较低的召回意味着更多的假负。提高召回率往往就会降低精确度,两者往往难以同时达到最理想的状态。
3 SnowNLP库情感分析实例
本研究目的是用SnowNLP库来分析下豆瓣上书籍的短语文本情感,详细过程如下:
(1)获取评论文本。其实无论使用什么方式抓取文本,都要仔细分析所需信息存在于页面的哪些标签以及在标签的哪些属性里。本研究使用Selenium来爬取所需实验文本,主要抓取的是豆瓣上的关于《Python编程快速上手》这本书的所有短评评论,将所有评论存储在txt文本中,同时也将其他与评论相关的字段如评论用户名、用户链接、评论时间、推荐星数、评论等信息一同存储在csv文件,以备后续研究所用。部分代码口1如下所示:
c= open(”book-douban. csv”,”w”,encoding= 'utf-8)#写文件
writer= csv.writer(c,dialect=(”excel”))#写入对象
writer.writerow([”序号”,”用户名”,”评分”,”评分标题”,”有用数”,”日期”,”评论”])
driver= webdriver.Firefox0
i=l
while i<20:
url="https://book. douban. com/subject/26836700/comments/hot?p="+ str(i)
driver.get(url)
eleml=driver. find_elements_by_xpath("//div[@class= 'ava_tar'ya")
elem2= driver.find_elements_by_xpath ("//span[@class=7 com-ment-info'yspan[ll")
elem3= driver.find_elements_by_xpath ("//span[@class=7com-ment-vote 7]/span[1n
elem4= driver.find_elements_by_xpath ("//span[@class=7 com-ment-inf0 7]/span[2]”)
elem5 = driver. find_elements_by_xpath("//span[@class=7shortT)
tlist=[]
k=( )
while k<20:
num= ia:20+k+1#序号
name= eleml[k].get_attribute("title")#用户姓名
score= elem2[k].get_attribute("class")#用户评分及内容
content= elem2[k].get_attribute("title")
useful= elem3[kl.text#有用数
date= elem4[k].text#日期
shortcon= elem5[k].text#评论
templist=[ ]
templist.append(num).append(name).append(score)
templist. append(content). append (useful). append(date). append(shortcon)
writer.writerow(templist)
k=k+l
i=i+1
c.close()
当然,在爬取文本信息过程中遇到的相关问题有:(1)网页上的用户名及评论中出了特殊字符即中文文字以外的一些符号,简单解决方案:对出现特殊字符字段,使用代码shortcon=shortcon. translate(non_bmp_map)来去掉特殊字符;(2)爬取过程中虽然暂未出现被封杀情况,但豆瓣页面内容本身有折叠隐藏的部分信息,即使代码正确也无法完全抓取,此时需要加入异常处理代码,折叠部分文本需要手动收集;(3)评论文本并不每页都是同样的数量,为此,不能固定每页爬取的数量,应该灵活计算。
(2)中文分词。本研究是采用结巴分词方法对上述评论文本进行分词,具体代码在作者的其他论文中可查看。再运用WordCloud生成文本分词后的词云,核心代码及词云图如下所示:
with open(path+ 'cut_word.txt 7, encoding= 'utf_8) as f.
comment text= f.read( )
color_mask= irnageio.imread(path+"book.jpg")#讀取背景图片
Stopwords =stopwordslist(" stopword. txt")#添加自定义停用词表
cloud = WordCloud(font_path= "FZYTK. TTF", back-ground_color= 'white 7,
max words=200, max_font_size=200, min_font_size=4, mask=color_mask,sto pwords=Stopwords)
word_cloud = cloud.generate(comment_text) #产生词云
irnage_colors = ImageColorGenerator(color_mask)
plt.imshow(cloud.recolor(colorL且mnc=image_c olors》
plt.figure( )
plt.imshow(color_mask, cmap=plt.cm.gray)
plt.axis("off")
plt.show( )
在词云中,显示越大的词越能体现评论文本的核心思想,可以看到关于本书的主要讲解的是python的基础知识,适于入门使用,并且也注重编程的训练。
(3)情感分析。基本过程:按行读取评论文本,利用循环每行文本调用sentiments方法计算得到每行(条)评论的情感分数(0-1的一个值),将其他存入文件。核心代码[3]如下:
source= open(”comment.txt”,”r”,encoding=”UTF-8”)
line= source.readlines0
scorel=[]#情感分数数组
i=( )
fori in line:
s=SnowNLP(i)
r=s.sentiments
scorel.append(r)
mpl.rcParams[font.sans-serif']_[SimHei']#显示中文
matplotlib.rcParams[axes.umcode__ mlnus] =False#显示负号
ph.hist(scorel,np.arange(0,1, 0.01), facecolor=b)
plt.xlabel(”情感分数”)
plt.ylabel(”用户评论”)
plt.title(”用户评论情感分析柱状图”)
plt.show( )
source.close( )
在情感分析的时候,为了更清晰的判断情感的极性分类,通常可以将情感区间从[0,1.0]转换为-0.5,0.5],位于0以上的是积极评论,反之消极评论。从上图可知,柱状图直观展示所有评论的分数分布情况,曲线图说明评论的情感波动情况。评论情感波动性较小,大部分评论情感比较集中、接近。
上述代码会从文件中逐行读取文本进行情感分析并输出最终的结果。SnowNLP库中训练好的模型是基于商品的评论数据,此次研究就不需要重新训练模型。但它也可用于其他类别文本的情感分析,只不过在实际使用的过程中,需要根据自己的情况,重新训练模型。
(4)结果验证。首先人工标记每一条评论的情感极性——1表示积极评论,一1表示消极评论。本次评论文本情感分析结果:积极评论准确率及召回率分别为0.784和0.978,消极评论准确率及召回率分别为0.935和0.507。从结果可看出:positive类文本被正确识别的有97.8%的召回率,说明在positive类文本中极少存在识别错误的情况,但positive类却只有78%的准确率,准确率有待提升。negative类准确率达到93%,这意味着负类情感识别十分精准,但召回率却只有50%,说明存在很多负类情感文本被错误地分类。对于负类文本来说,由于中文的博大精深,通常在使用语境中用负面词汇来表达正面评价,如“不是很好”。当然,中文也存在很多中性词或极性强度根据语境决定的词汇,但分类器却只能将词汇情感一分为二。
4 结论
本文完成了使用snowNLP库进行文本情感的分析,总结如下:第一、语料库十分关键,如果构建了精准的类别语料库来替换默认语料库,准确率可能更高;第二、情感分析通常需要与评论的具体时间段結合起来,这样就能在特定的场合发挥情感分析更多的应用,比如舆情预测预警等[3];第三、情感分析经常不应该一分为二地划分两个不相干的集合,因为词语在不同语境会产生不同的情感极性或强度,这样会降低情感分析的准确性。相关问题将作为后续研究进行。
参考文献:
[1] zhiyong_will.情感分析一深入snownlp原理和实践[EB/OL].https://blog. csdn. net/google19890102/article/details/8009 1502.2018.6.
[2] Eastmount.基于SnowNLP的豆瓣评论情感分析[EB/OL].https://blog.csdn.net/E astmount/article/details/85 118 81 8.2018, 12.
[3]王树义,廖桦涛,吴查科.基于情感分类的竞争企业新闻文本主题挖掘[J].数据分析与知识发现,2018,2(3):70-78.
【通联编辑:代影】
收稿日期:2019-12-11
基金项目:2017年度江西省教育厅科学技术研究项目青年项目:基于Python NLP库的中文文本情感识别研究(编号:GJJ171193)
作者简介:曾小芹(1986-),女,江西人,讲师,硕士,主要研究方向为大数据及其处理等。
- 用对称性求解圆锥曲线高考题
- 一类过定点的函数族的试题命制与分析
- 一类试题太“另类”转化思想显“神威”
- 用“两边夹”解题的若干操作策略
- 2018年高考数学模拟试题(一)
- 介绍一道原创“数学文化”高考模拟题
- 灵活选择参数优化解题思路
- 二次曲线定比公式及其应用
- 一个杠杆问题的解法及推广
- 线性规划问题的实际应用
- 在高中数学教学中忽视数学文化的表现与对策
- 基于学科学习力的数学课程结构
- 北师大版与人教A版高中数学教科书比较研究
- 谈课堂教学中数学核心素养的提升
- “简单的线性规划问题”的八步教学设计
- 培育核心素养,寻根教材教学
- 核心素养下“说数学”运用于个别辅导的案例研究
- 基于微课的高中数学教学设计与思考
- 教研活动与教研功力的提升
- 商榷这道商榷题的修改题组
- 费恩斯列尔——哈德维格尔不等式的推进
- 关于三角形边长一个猜想的证明及推广
- 一类条件可化为“∏x=1”的不等式研究述评
- 2018年高考数学模拟试题(二)
- 2018年高考数学模拟试题一)
- pleasurist
- pleat
- pleated
- pleaters
- pleating
- pleatless
- pleats
- pleb
- plebbish
- plebbishness
- plebification
- plebify
- plebiscite
- plebiscites
- plectrum
- plectrums
- pled
- pledge
- pledg(e)able
- pledged
- pledgeless
- pledger
- pledgers
- pledges
- pledge²
- 文章写得极好
- 文章写得极好,无人能比
- 文章写得精妙无比
- 文章写得非常婉转、曲折
- 文章创作的新意
- 文章别出心裁,富有独创性
- 文章前后连贯
- 文章前好后差
- 文章功力精深
- 文章北斗
- 文章十分美妙
- 文章千古事,得失寸心知
- 文章华丽铺陈
- 文章华美,字字珠玑
- 文章单薄,没有内容
- 文章博大精深
- 文章可以起病,是天下之良药
- 文章各处
- 文章各部
- 文章合为时而著
- 文章合为时而著,歌诗合为事而作
- 文章呆板
- 文章和绘画的传神处
- 文章和语言
- 文章和谋略