依力达尔·依明
摘要:特定领域的命名实体识别方法在不同的领域中都会存在很大的差别。不同领域的文本具有其自身的不同的特性,这致使目前已有领域的识别方法很难满足识别新的特定领域的发展需求。针对在特定新领域中所存在的问题,提出了以随机场、半监督学习和主动学习相结合的方法为基础对特定领域的命名实体的识别方法进行研究,从而形成一个特定的领域命名实体框架,进而能够满足各个不同领域的命名实体识别方法的需求。这篇文章选用了几乎在所有特定领域中都能够通用的方法构建特征,从而实现了对特定领域的命名实体识别方法的研究。
关键词:特定领域;命名实体;识别方法;研究
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2020)08-0208-03
特定领域中最基本的信息单位是命名实体,命名实体不仅是文本原有名称的缩写,也是文本的唯一标识,它往往能够涵盖文章的主要内容。命名实体的识别是现代自动化识别技术中的一门最基础又极其重要的技术。最近几年,对特定领域的命名实体进行现代化自动识别时已经非常的普遍了。在生物领域的命名实体识别,文献针对不同的事物领域采用了不同的生物向量机,并且以隐马尔可夫对生物医学命名实体识别为基础开展了生物领域的命名实体识别;文献并且以隐马尔可夫对生物医学命名实体为基础提出了一种产品命名的实体识别方法,从而实现汉语文本命名的识别;文献在军事领域方面,将机场的随机条件和规则相结合的方式实现了对军事领域的实体命名识别;文献在音乐领域方面,以隐马尔可夫对生物医学命名实体为基础提出了歌手名和歌曲名等进行了实体识别;文献在医学领域方面,使用了将条件随机任何规则相结合的方式从而实现了医学领域的命名实体识别。
为了能够验证这篇文章所采用方法的科学性与正确性,实验部分做了反复多次的实验,从而确保准确率达到相应的标准。经过一系列的实验研究发现该方法在交通领域中得到了实现了的命名实体识别效果,从而验证了该实验方法可以在实验的过程中应用。
1 特定领域命名实体识别方法的相关知识
由于各个文本在不同的领域中都有其不同的特点[1],所以文章所阐述的命名实体方法只能适用于特定领域的命名实体识别。如果将这些领域的命名实例方法应用于其他领域的命名实体识别,识别的效果将会意想不到的下降。所以这篇文章针对在命名实体中存在的问题进行了分析.从而提出了一种将条件随机场监督学习和主动学习相结合的计算方法,既然形成了一个可以适用于特定领域的命名实体识别的技术框架[2]。这个实验在开展的过程中所采用的是将各领域的文本的基本特征和基本构建进行结合的方法,然后在随意的条件下对特定领域的命名实体进行识别,然后再使用人工对低于阈值的文本进行标注。
1.1 条件随机场
条件随机场指的是一些研究人员以隐马尔可夫实验和最大熵模型实验为基础提出的一种概率判别模型。概率判别模型可以很快地判别出众多序列中的特征,从而可以用来克服隐马尔可夫模型中严格的强独立性假设问题。与此同时[3],条件随机场通过对全局统一规划可以得出最优输出点的条件概率,从而可以有效地克服隐马尔可夫模型中出现问题标记的现象。
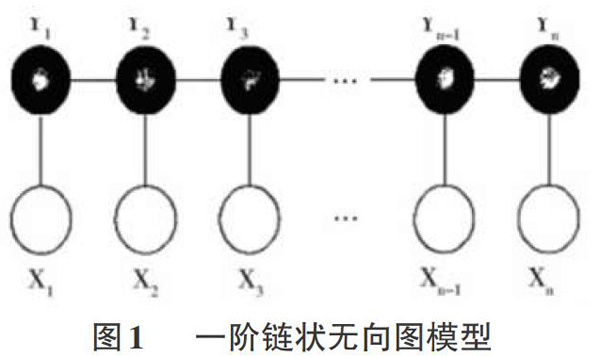
组合参考频率系统也被称为马尔可夫条件随机场,它可以用来定义:在一組特定的观察序列中,可以将该观察序列记为X,给一个标记序列的连接记为Y。然后使用马尔可夫条件随机场将该条件区别看作为没有条件的无向图模型[4]。虽然条件无向图的模型结构非常随意,但是因为一阶链结构在计算的过程中非常的简单,所以在建立条件无向图的模型结构时一般会采用一阶链结构。组合参考频率系统可以看为一阶链状无向图模型的各输出点之间的分隔,并且都存在一阶链状无向图模型可以体现出马尔科夫独立性,如图1所示:
通过图1的一阶链状无向图模型我们可以计算出Y的条件概率。
1.2 半监督学习算法和主动学习算法
半监督学习算法又被称为自训练算法。半监督学习算法是指将有监督学习和无监督学习算法进行结合的一种统计计算学方法。可以通过将大量的标注和未标注的语料进行分类和自主练习,并且整个计算过程都是自动化不需要人力的参与。关于城市城轨交通领域方面的文本,如果采用人工的方法对语料进行标注[5],不仅会严重地降低城市城轨交通的运行效率,反而会浪费大量的时间。因此为了能够减少用人工对语料进行标注的方法使用,就需要多采用组合参考频率系统进行反复的训练,必要时还可以结合半监督学习算法,从而组建一个具有较强泛化能力的模型。
这篇文章采用半监督学习算法,基本流程如下所示:
输入:已经标注的训练集标记为L特征集合标记为V.没有被标注的训练集标记为U。
(1)利用已经标记的训练集L在特征集合v上可以现在出模型Cl。
(2)再利用模型C1对没有标记的训练集U进行命名实体的识别,并计算没有标记的训练集U的置信度。
(3)从没有标记的训练集U中选择出高于阈值的一个样本u加入已经被标记的训练集L中,最后从没有标记的训练集U中删除高于阈值的样本u。
(4)之后的计算就需要依照以上三个步骤反复地进行,最后得出最简化的计算模型。
如果想要在计算的过程中采用半监督学习算法的方式[6],就需要选择初始分类器具有高的分类精准性。如果计算人员不能够保证初始分类器具有高度的分类精准性,并且在计算的过程中没有人工的干预,那么就会导致在反复计算的过程中出现错误积累的现象,从而导致分类器的训练实验失效。
与半监督学习算法相比较,主动学习算法的优势在于它能够自动的选择有利的训练模型将没有标注的样本进行标注,从而在反复计算的过程中尽量减小标注成本和分类学习的计算规模。研究人员已经将主动学习算法应用到语言处理领域中[7],比如将文本语言进行分类、构建没有标记的语料库、语言实体的命名与识别等。再次与半监督学习算法相比较,半监督学习算法与主动学习算法两者最大的区别在于:半监督学习算法不需要人工的干预,通过自身所选定的训练模型来选择置信度高并且没有被标注的数据进行利用;而主动学习算法在计算的过程中,能够自动化的选取最有价值的标注样本加入已经标注过的样本中。
2 以条件随机场为基础的命名实体识别
2.1 分词和标注
这篇文章采用的是我们国家最具有权威性的分词系统ICT_CLAS[8]。应用中国权威的中文分词系统ICT-CLAS对城轨交通进行分词处理,并且其词性的标注结果将作为条件随机场学习的重要特点。这篇文章使用字母符号为(A.B.C.D)集合对特定的领域文本实体的第一字符、中间字符和最后一个字符的集合中部分进行标注,还需要确保集合中的每一个字符都是{A.B.C.D)字母符号集合中的一种。
2.2 建立特征模板和函数
在条件随机场训练模型中,选择和建立合适的特征模板将对模板的性能产生十分重要的影响[9]。特定领域中的文本将有其文本自身的特定性,为了使得所建立的模板适用于各个特定的领域中,这篇文章将使用以下四种基本特征建立特征模板和函数。
(1)选择合适的词特征。分词后的每一个词都可以作为模板的特征,因为词特征本身的特征就可以很好的反映出该文本独有的特性,所以选择合适的词特征就能够代表已经选择了选择合理的模板特征[10]。
(2)词性特征。这篇文章在对词特征进行分类的过程中也对词特征进行了标注。经过一系列列的实验研究表明,用词性特征来建立条件随机机场可以很好地提高模板的计算性能。
(3)英文字母以及数字的特征。在很多特定的领域进行实体命名的过程中都会有一些数字[9]。比如:在医学领域中的“化学药物1.2”、城轨交通领域中的“飞驰号CRH381B”等。因为在实体命名的过程中加上一些数字可以有利于区分同一领域中的不同事物,所以使很多特定领域在进行实体命名的过程中,都会加入英文字母和一些数字。
(4)上下文特征。通过观察序列的数值来看清序列本质,序列本身可以包含很多语言和文本信息。通过大量的实验研究表明,在实验范围大的条件下,只运用训练的上下文特征也能够训练出性能比较好的模型。
本文将上面所提到的四种文本普遍含有的特征融合在一起构成了还有特殊性能的特征模板。建立特征模板的目的就是为了获得所需要的可以普遍使用的函数,而获得特征函数的性能在一定程度上也将取决于本篇文章对城轨交通文本的识别效果。
3 将半监督学习和自动学习相融合所获得的命名实体的识别办法
在现有的命名实体识别的范围中,以条件隨机场和半监督算法相结合的命名实体方式非常的多见[11-13]。正如这篇文章所提及的半监督算法会从没有标记的本集U中选出一个置信度高于阈值一个的u来加入没有被标注的样本L中。正在计算的理论角度来看,当所选中集合中的数量扩大之后,就需要建立新的数据模型Dn。但是在新添加的训练样本中有一部分的数据对提高新建的数据模型Dn性能没有起到任何作用。因为这些数据是在原有的样本中被标记出来的,所以所添加的数据在原有的数据模型中属于多余部分。除此之外,因为已经有了特定领域缺乏丰富的分词标注,所以使得现有的分词领域系统不在适用于特定领域系统,进而导致特定领域系统的分词出现准确性低的现象[14]。根据上面讲述的两点来看,若在命名实体识别的过程中仅应用半监督学习和自动学习相融合的方法,模型在反复循环计算的过程中不仅会降低计算的速度,而且会使计算的错误反复的积累。然而,如果将半监督学习和主动学习算法进行结合,可以很好地克服在计算过程中出现的这种不良现象[15]。因为主动学习算法可以将不能被原模型进行标注的数据进行人工标记,然后再将标记好的数据重新放入到新的训练模型中。这样不仅能够减少分类器在分类过程中出现的错误,而且也能够实现原有的模型在特定领域中的使用。
3.1 在置信度基础上的主动学习
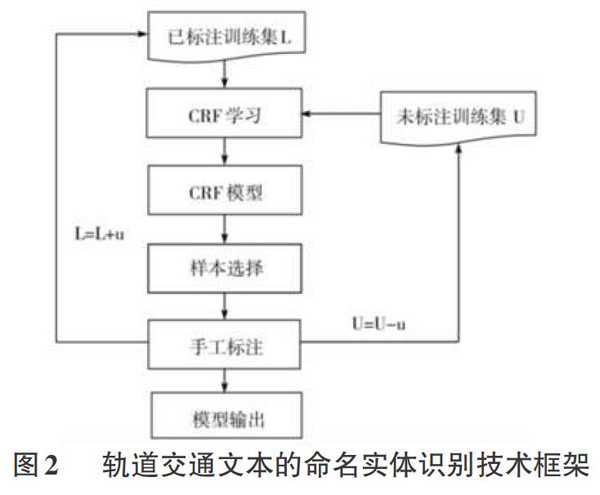
这篇文章将不能被原有模型进行标记的数据称为有效数据,并且这些样本存在于没有被标记的数据中。在这里我们可以使用置信度将这些数据选择出来作为有效数据。通过一系列的就算得到图2所示的计算结构模型。
该结构模型的算法流程图如下所示:
输入已获得标记的样本集为L;没有被标记的样本集称为U。
(1)获取少量已经被标注的语料看作为l。
(2)使用条件随机场对L进行训练练习,产生条件随机场模型Dn。
(3)使用条件随机场模型Dn对U命名实体进行命名识别,并对U命名实体进行标注结果的置信度估算,即获得一个条件概率为P(YIU)。
(4)选择由U本集中置信度低于阈值的数据作为有效数据,并将这些有效数据标记为useful。
(5)然后再对有效数据useful进行标记,标记好的数据称为u。
(6)再把这些标记好的数据又加入样本集中L,并从没有被标记的样本集U中删除。
(7)将上面所阐述的六个过程进行反复的计算,直至所计算的模型Dn处于收敛状态。
最后输出的数据模型为Dn。
4 该实验的结果以及实验结果分析
为了能够有效地验证该实验结果是科学和准确的,这篇文章采用了城轨交通的方式来进行了验证。相对交通的方式包括地铁、高铁和磁悬浮列车等。并且因为目前国内没有统一的城轨交通语料库,所以就需要通过人工进行语料库的收集。这篇文章所需要的数据来源于很多的新闻报道和报纸以及网络信息,一共设计了200片科学性的文章。并且本次实验所采用了非常著名的条件随机场开源工具和实验方法,而且还使用了半监督学习计算方法和主动学习计算方法,虽然实现了对城市交通轨道的命名实体识别。
这次实验采用了四组实验对比,分别使用了半监督学习计算方法和主动学习方法以及三种学习计算方法相结合的方式进行反复重复的计算。
5 结束语
本文提出的是在条件随机场的条件下,将半监督学习和主动学习计算方法相结合的方法对特定的领域进行命名识别。这种方法使用半监督学习中的半监督算法的条件随意机场进行反复的运算,并且在其反复运算的过程中选择出置信度低于阈值的有效数据,并将这些有效数据加入已经被标注的样本中。这种计算方法结合了主动学习算法的理论。并且该计算方法在城轨交通命名方面得到了很好的命名实体识别结果。这篇文章不仅使用了最基本的本特征和基础构建对特定的领域我们进行随机训练,而且选择和增加不同领域的多种特征是下一次实验的研究重点。为了使特定领域的命名实体识别方法研究得更加深层入,这需要研究人员结合不同领域的多种特点进行研究。总而言之,将特定领域的命名实体识别方法不断地进行突破与创新是推动特定领域命名实体识别方法的快速进步的基础。
参考文献:
[1]张磊,特定领域的命名实体识别方法的研究[J].计算机与现代化,2018(3):60-64.
[2]张宁.面向特定领域的命名实体识别技术研究[D].杭州:浙江大学,2018.
[3]张磊.特定领域命名实体识别通用方法的研究[D].北京:北京交通大学,2018.
[4]何晓艺.面向领域文本知识实体识别及关系抽取的关键技术研究[D].石家庄:河北科技大学,2018.
[5]刘璟.中文命名实体识别方法研究[J].电脑知识与技术,2019,15(9):179-180.
[6]张晓海,操新文,高源.基于深度学习的作战文书命名实体识 别[J].指挥控制与仿真,2019,41(4):22-26.
[7]王路路,艾山·吾買尔,吐尔根·依布拉音,等.基于深度神经网络的维吾尔文命名实体识别研究[J].中文信息学报,2019,33(3):64-70.
[8]赵鸿阳.基于深度学习的电子病历命名实体识别的研究与实现[J].软件,2019,40(8):208-211.
[9]张祥伟,李智.基于多特征融合的中文电子病历命名实体识别[J].软件导刊,2017,16(2):128-131.
[10]高甦,金佩,张德政.基于深度学习的中医典籍命名实体识别研究[J].情报工程,2019,5(1):113-123.
[11]宋希良,韩先培,孙乐.面向新类型人名识别的数据增强方法[J].中文信息学报,2019,33(6):72-79.
[12]原旎,卢克治,袁玉虎,等.基于深度表示的中医病历症状表型命名实体抽取研究[J].世界科学技术一中医药现代化,2018,20(3):355-362.
[13]张海楠,伍大勇,刘悦,等.基于深度神经网络的中文命名实体识别[J].中文信息学报,2017,31(4):28-35.
[14]祖木然提古丽·库尔班,艾山·吾买尔,中文命名实体识别模型对比分析[J].现代计算机,2019(14):3-7.
[15]徐梓豪.基于统计模型的中文命名实体识别方法研究及应用[D].北京:北京化工大学,2017.
【通联编辑:唐一东】
- 中国城市形象片的研究现状
- 媒体如何保持文字的纯正与纯洁
- 基于OBE教育理念构建传媒人才培养“第二课堂”的探索
- “合作学习”视域下广播电视编导专业实践教学体系构建研究
- 如何讲好新闻故事
- 处处留心皆“线索”
- 新媒体时代传统媒体时政新闻报道如何创新
- 深度报道彰显党报核心竞争力
- 树立精品意识 创办一流党刊
- 让“三农”声音更响亮
- 新媒体时代粉丝群体乱象成因及应对之策
- 基于抖音短视频的大学生媒介素养现状研究
- 都挺好!地方新闻网站这样做正能量报道
- 视频博客在新闻报道中的应用及其发展方向
- 新媒体语境下传统媒体传播力构建研究
- 我国体育赛事短视频传播研究
- 全媒体时代网络舆情治理三要素
- 断裂与连接:“综N代”网络综艺节目的发展思考
- 微信健康类谣言的传播特征及治理策略
- “短视频+扶贫报道”的实践与思考
- 健康新闻报道的全媒体互动传播探析
- 虚拟现实技术在新闻媒体应用中面临的挑战与前景
- 从“人造锦鲤”看新媒体时代的媒介崇拜现象
- 四个维度推动新媒体高质量的内容生产
- 讲好历史上黄河治理故事应关注的几个问题
- amazedness's
- amazeful
- amazement
- amazements
- amazer
- amazers
- amazes
- amazing
- amazing/incredible
- amazingly
- amazingness
- ambassador
- ambassadorial
- ambassadorially
- ambassadors
- ambassadorships
- amber
- amberlike
- amberous
- ambers
- ambers'
- ambery
- ambi
- ambiance
- ambiances
- 洗浣
- 洗浴
- 洗浴中心
- 洗涤
- 洗涤剂
- 洗涤器物
- 洗涤拂拭
- 洗涤擦拭
- 洗涤清除
- 洗涤溺器
- 洗涤衣物
- 洗涤,清洗
- 洗涮浣衣
- 洗清
- 洗清冤屈
- 洗清卖白
- 洗清污名
- 洗湔
- 洗溉
- 洗漱
- 洗漱、沐浴
- 洗澡
- 洗澡的地方
- 洗濯
- 洗濯磨淬