陈萱 徐美佳 王文涵


摘要:基于物联网与图像识别技术的智能停车服务平台,采用区域已覆盖的摄像头对车位进行图像识别或增设地磁感应设备以轻松获取实时车位状况,以实时服务器数据为依据制定停车方案。用户在复杂环境寻找车辆时,系统同样提供了基于对地面停车号进行文字识别的导航服务,极大减少了寻车时间。系统集搜集、预定、找寻、预测车位服务一体化,在相当大的程度上解决了停车难的社会问题。
关键词:智能停车;图像识别;文字识别;物联网;管理系统
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)10-0187-03
1背景
居民汽车保有量迅速增长,停车泊位不足的问题日益突出。新建的地下停车场,常配有车位地磁传感器,可精确检测每个车位的占用情况。而老旧的大型地面停车区域,缺乏检测传感器,时常出现乱停乱放的情况。车主需占用主干道路不断寻找空余车位,极易造成交通拥堵。若对每个车位部署传感器,需要较高的资金成本。
我们将监控与图像识别技术结合,获取停车场的监控信息与感应器产生的数据,基于图像识别技术产生相应的判别结果,实时上传车位信息。根据对车位信息的智能化判断,引导用户前往空闲停车场。当用户面对陌生复杂的停车场环境时,通过扫描地面车位号码,系统将自动定位用户并对用户所泊车辆位置进行导航。
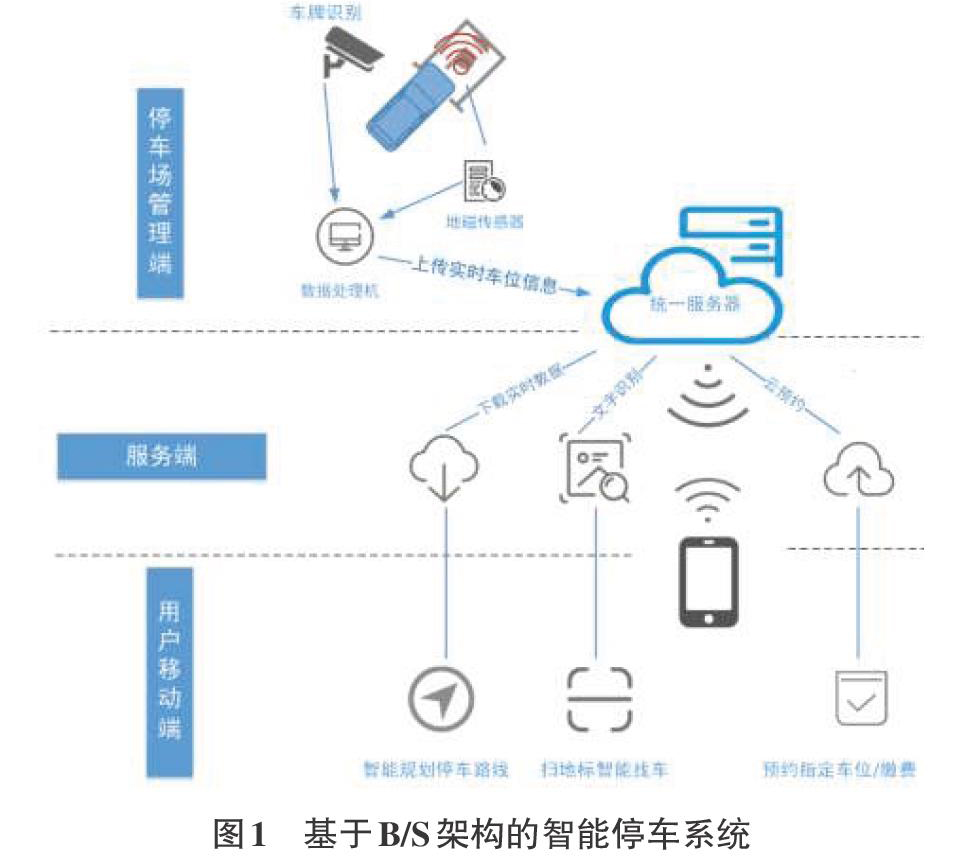
2智能停车系统
传统停车场系统存在无法实时提供位置信息、无法显示空余车位及无法车位资源共享等问题,智能化停车管理系统也必然会成为未来社会的必备设施。区别于只通过使用地磁传感器、RFID读卡器埘、摄像头等进行监控检测,本文利用了基于图像深度学习的停车位识别及查询方法。图像采集服务采集停车场图像,图像识别服务采用深度学习算法,对新采集的图像进行识别预测,在服务查询数据库中获取信息,根据空余车位的相对位置在车位平面图标注出空余车位。
3智能停车服务系统的开发
3.1管理員端
管理员注册并登录后,可上传自己需要管理的停车场相关信息、查看停车场地图、查看停车场监控、上传停车场数据并设置监测区域、查看自动生成的停车场平面图。
3.1.1停车场信息管理
管理员将所需管理的停车场有关信息上传至系统数据库中保存,并通过实时监控和图像识别技术,对停车场的剩余车位信息进行实时更新。
3.1.2停车场的实时监控
管理员需将停车场摄像头的IP、密码及端口号录入系统。此后可在系统中查看实时的监控画面,下载录像和查看历史记录。
3.1.3停车场的车位信息
对于无框露天停车场,管理员需上传一张该停车场的平面图,并手动勾勒可用车位边缘,上传车位信息。当管理员进行查询时,系统可根据预存的车位信息,进行车位检测,并将结果生成该停车场的平面图。
3.2小程序端
用户可查询某一停车场的空位信息和使用停车场导航,我们正在开发模拟室内导航功能。用户在停车后,扫描车位前的字母,系统会记录车位所在位置,也可通过室内导航功能寻找自己已停放的车。
4算法描述
4.1基于VGGl6的图像识别
图像分类识别是计算机视觉的一个应用,其研究也是打开视觉应用大门的必经之路。本文在现有的13层卷积的神经网络VGGl6模型和迁移学习技术的基础上构造了一个小规模的汽车分类的卷积神经网络模型,将图像特征向量作为输入,图像分类结果作为深度学习算法的输出,在样本容量较小的情况下也取得了较好的成果。
VGGNet相比AlexNet采用连续的3x3的卷积核代替AlexNet中的较大卷积核。对于给定的感受野,采用堆积的小卷积核优于大的卷积核,因为多层非线性层可以用更小的代价来增加网络深度来保证学习更复杂的模式。在VGGl6中使用3个3x3卷积核来代替7x7卷积核,使用2个3x3卷积核来代替5x5卷积核,在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。参数数量由49xC2减少到27xC2(C指的是输入和输出的通道数),且小卷积核更好地保持图像性质,提高了神经网络模型的性能。
4.2模型结构
VGG16是基于大量真实图像的ImageNet图像库预训练的网络。我们将学习好的VGGl6的权重迁移到自己的卷积神经网络上作为网络的初始权重,避免从头开始从大量的数据里面训练,显著提高训练速度和模型精度。此外我们又添加了两层Dense层,用于进一步对汽车的特征进行学习,最后Softmax层用于输出分类结果。
模型中使用了RELU修正线性单元作为激活函数,相比于传统的神经网络激活函数,能够更有效地梯度下降以及反向传播,避免梯度爆炸和梯度消失的问题。同时用RELU替代复杂的指数函数,也简化了计算过程。
4.3实时获取车位信息
构建该车位检测模型主要有两个步骤:
1)从前端获取待检测区域信息;
2)使用我们预训练的模型检测每个停车位,并预测是否有人停车。
通过使用旋转、对称等方式来扩充数据集,将数据分成15批,训练后得到的模型准确率达到94%,如图2:我们对学院楼下停车位进行了实地检测,结果如图3:
5自然场景文字检测及识别
5.1自然场景下文字识别
场景图像中的文本区域与通用物体不同,不仅具有更多的尺度,而且可以分布在图像的任意区域,容易受类似文字的背景的干扰。本文针对以上问题,结合深度学习的相关技术,使用YOLO模型进行文本定位,在定位的文本上使用CRNN+CTC模型进行文字识别,解决了在自然场景下对停车位上相关文字进行识别的难题。
5.2文本定位模型
YOLOv3是到目前为止,速度和精度最均衡的目标检测网络。通过多种先进方法的融合,避免了YOLO系列不擅长检测小物体的问题。
5.2.1多标签分类预测
YOLO中使用逻辑回归预测每个边界框的对象分数。与YOLOv2不同,我们的系统只为每个ground truth对象分配一个边界框。如果先前的边界框未分配给grounding box对象,则不会对坐标或类别预测造成损失。每个框使用多标签分类来预测边界框可能包含的类。在训练过程中,我们使用二元交叉熵损失来进行类别预测。对于重叠的标签,多标签方法可以更好地模拟数据。
5.2.2跨尺度预测
YOLOv3采用多个尺度融合的方式做预测。采用类似FPN的上采样和融合做法,在多个规模的特征图上做检测,对于小目标的检测效果提升较为明显。由于采用了多尺度的特征融合,所以边界框的数量大幅增多。
5.2.3网络结构改变
使用新的网络来实现特征提取。相比于Darknet-19中添加残差网络的混合方式,将其扩充为53层并称之为Darknet-53。其浮點运算少,速度快,可实现每秒最高的测量浮点运算和更好地利用GPU进行有效评估。
5.3文本识别模型
CRNN(Convolutional Recurrent Neural Network)是一种卷积循环神经网络,用于解决基于图像的序列识别,如场景文字识别问题。
网络结构包含三部分,从下到上为:
1)卷积层。作用是从输入图像中提取特征序列。由标准的CNN模型中的卷积层和最大池化层组成。
2)循环层。由一个双向LSTM循环神经网络构成,循环层的误差被反向传播,最后会转换成特征序列,再把特征序列反馈到卷积层,这个转换操作由自定义网络层完成,作为卷积层和循环层之间连接的桥梁。
3)转录层。在双向LSTM网络的最后连接上CTC模型,做到端对端的识别。所有样本点的概率传输给CTC模型后,输出最可能的标签,再经过去除空格和去重操作,可得到最终的序列标签。
5.4基于yolov3和CRNN实现文字识别
构建该检测模型主要步骤:
1)文字检测:首先检测方向,基于图像分类,在VGGl6模型的基础上,迁移训练0、90、180、270度的文字方向分类模型,训练图片100000张,准确率95.10%。yolo文字训练和其他对象检测训练方式类似,唯一不同的是,后续有一个box聚类,原理参考了CTPN相关代码。
2)文本识别:CRNN+CTC训练就是支持不定长识别,首先CNN提取图像卷积特征,然后LSTM进一步提取图像卷积特征中的序列特征,最后引入CTC解决训练时字符无法对齐的问题。
我们用模型对实验室的门牌做了测试,结果如图5。
6结束语
针对现代社会停车难问题,本文利用基于VGGl6的卷积神经网络,快速对停车场内车辆及可用停车位数量等信息进行获取,并实时将信息传至服务器,同步至客户端,使用户可远程获知附近停车场当前车位状况。利用深度学习技术对车牌的自动识别实现了车辆管理的自动化,可降低停车场运营成本。通过多种技术整合,解决了停车场的管理和用户的停车难题,提升了用户的出行体验,既具有创新性又有很强的实用价值。
- 小学数学教学方法分析
- 探讨小学数学教学中学生独立思考能力的培养
- 如何在小学数学教学中培养学生的自主学习能力
- 浅议“举一反三”策略在小学数学课堂中创新思维的作用
- 希沃白板在小学数学教学中的应用
- 信息技术与小学数学课程整合研究
- 小学数学教学中有效应用思维导图的分析研究
- 小学数学“参与式”课堂教学的实践与思考
- 浅谈小学数学概念教学
- 试论小学生数学计算能力的提高
- 用好现代教育技术促进数学教学改革
- 浅谈数学教学中的几种变式训练
- 试论初中数学课堂教学中的常见问题及优化策略
- 浅谈在初中数学教学中培养学生的应用意识
- 微课在小升初数学衔接中的作用分析
- 初中数学教学中培养学生主动提问能力的有效途径
- 试题命制情境化思维视角
- 初中数学教学中渗透数学思想的探索
- 互联网背景下初中数学分层教学研究
- 试论中学数学课堂教学的有效性
- 中职数学中一元二次不等式的解题思路探析
- 中职数学三角函数最值问题分析
- 职业中专数学高效课堂教学策略
- 讨论中专生数学的思维特点及教学对策
- 中专数学教学中学生问题意识培养
- overrife
- overrigged
- overright
- overrighteous
- over-righteous
- overrighteously
- overrighteousness
- overrighteousnesses
- overrigidities
- overrigidity
- overrigidly
- overrigidness
- overrigidnesses
- overrigorous
- overrigorously
- overrigorousness
- overrigorousnesses
- overripen
- overripened
- overripening
- overripens
- overrise
- overrisen
- overroasted
- overroasting
- 荼毒笔墨
- 荼毗
- 荼火
- 荼炭
- 荼缓
- 荼苦
- 荼蓼
- 荼酷
- 荼锦
- 荼首
- 荽
- 莂
- 莂秧
- 莅
- 莅临
- 莅临查考
- 莅事风生
- 莅任
- 莅任前晋谒辞行
- 莅会
- 莅官
- 莅政
- 莅教
- 莅止
- 莅正