任女尔 魏金津 蔡建军

摘要:汽车行业会产生大量数据,需要对这些数据进行存储与分析。基于ApacheAmbari搭建大数据基础设施,通过Nifi可以将各种型式的数据进行处理、整合并导入大数据存储。通过Kylin可以对存储的大数据进行降维,提高查询速度。基于springCloud与开发计算模块并,对外提供Rest接口,实现大数据查询功能。
关键词:Amabri;Nifi;Kylin;SpringCloud
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)31-0001-05
1概述
汽车行业的软件项目中,经常有这样的业务场景。比如新能源汽车数据采集,一辆车一天的运行数据量为0.375G,这样一年的运行数据量可达136.875G,车的数量越多数据量就越多,能达到T级甚至更大。这些数据经常是以txt、CSV等形式提供的,有结构化的也有非结构化的,我们需要对这些数据进行存储和分析。
为了突破数据存储的瓶颈上限,为数据资源中心未来的数据仓库构建做一定的技术储备,所以我们基于Ambari建设了一个数据处理平台,实现了:
1)使用Nifi,数据可配置导入,无须开发即可接入txt、CSV或是其他数据源,将CSV文件导入Hive存储;
2)海量数据的存储;
3)通过Kvlin将数据降维存储到Hbase,计算模块再调用Kvlin查询数据,效率高;
4)代码开发计算模块实现SQL的管理,能够在uI上写新的查询语句,直接暴露Rest接口,供外部程序调用。
计算模块基于SpringClould开发,使用JHipster生成微服务基础代码,可连接Kvlin、Groovy执行计算。支持通过docker容器运行,方便横向扩展。
目前经测已成功导入一份3500万行的文件(6.4GB)。
2系统架构
2.1系统结构
该项目基于Hortonworks的HDP搭建了大数据的基础設施。基于HDF实现基本的数据ETL,用于系统问的数据集成。通过Kvlin抽取、聚合Hive中的数据,构建低维Cube表存储与Hbase,形成降维索引层,用于支持MOLAP场景。最后,通过基于SpringClould开发的计算模块,管理计算,该模块可连接Postgres、Kvlin、Sqlite、Oracle、Groovy执行计算逻辑,可实现链式计算,从而满足复杂计算场景,为大数据可视化、机器学习、人工智能等提供支持。
2.2功能划分与流程处理
2.3大数据基础设施管理
大数据基础设施的搭建是极为麻烦的,Hadoop的安装、调试往往需要苦苦耗费好几天,更别提Hbase、Nifi、Kylin等Ha-doop组件,所以我们通过Apache Ambari去搭建。
Ambari是开源的,作用是创建、管理、监控Hadoop整个生态圈(例如Hive、Hbase、Zookeeper等)的集群,让Hadoop以及相关的大数据软件更容易使用的一个工具。Ambari现在所支持的平台组件也越来越多,例如流行的Spark、Storm等计算框架,以及资源调度平台ARN等,我们都能轻松地通过Ambari来进行部署。通常场景,会登录Ambari进行故障排查、服务重启、配置查找/修改等工作。
Ambari使大数据基础设施安装,官方说法是从数人天降低到一人天,运维人数从数十人降低到几人。如图3所示。
3Nifi
因为企业数据来源是多元化的,需要经过整合后接入ha-doop生态圈以及各种存储分析组件,我们希望这个过程是平滑、可视的。
Nifi是一个开源的数据处理与分发系统,可以通过简单的Processor对数据流进行处理,他提供可视化的uI界面,各个模块组件之间可配置,各个数据处理模块之间的数据流转情况。可以将各种数据源的数据导入Hive、Hbase存储。
4KyLin
Kylin简单说就是做大数据查询的,可以对大数据进行降维,可以帮助我们对大数据进行多维度的分析,提高查询效率。
对于海量数据,每增加一个维度,数据量就是笛卡儿积,减少维度能够大量减少数据量,大多数计算不需要用到所有维度的。
以近SQL语句,查询T级别大数据秒级可完成。
5数据集成
5.1创建Hive表
登录Ambari集群任一服务器,执行hive命令进去Hive命令行模式,即可运行SQL语句创建/查询数据表。如图4所示。
5.2创建Nifi数据流
Nifi是一个开放的数据集成开发平台,数据处理平台通过Apache Nifi实现数据ETL,通过Ambari的QuickLinks进入Nifi-uI界面,通过对图形化数据处理流程的设计及配置,实现数据的ETL流程。
下图样例流程实现了:1)CSV数据文件的到达监听;2)CSV数据文件的解析;3)Hive的流导入;41KylinCube的增量构建。
如图5所示。
5.3kylin多维交互查询
通过Apache Kylin抽取、聚合Hive中的数据,构建低维Cube表存储与Hbase,形成降维索引层,用于支持MOLAP场景,如图6所示。
KvlinCube(低维表)的创建过程大致过程为:创建project、同步Hive表、创建Model、创建Cube。
6计算模块
6.1系统介绍
计算模块可连接Postgres、Kylin、Sqlite、Oracle、Groovy等执行计算逻辑,可实现链式计算,从而能够满足大多数场景的BI计算需要。
Kvlin是基于hive构建低维表,低维表就是抽取部分列,聚合度量值,形成一个小的内存表,数据处理平台就可以连Kylin执行查询了,在低维表上运行sql,返回结果,查询速度快。
计算模块通过Rest接口,被外部系统调用。为了满足系统对吞吐量,性能,稳定性的需求,而在技术上选择基于Spring-Cloud的微服务架构与Docker容器。这个架构的好处是,服务可以开任意多实例进行横向扩展,还可以保持服务的独立性,屏蔽底层物理平台的差异。为了加快开发速度,我们选用了JHipster,一个开源的SpringCloud代码生成脚手架,可以自动化生成前后台一套完整的微服务体系代码,包括监控、日志、权限等,正常情况下可以减少一半以上工作量。
计算模块还提供了一个可输入Kylin、Groovy等大数据操纵脚本的uI界面,将脚本传递到Java后台执行,并返回结果。
6.2进入计算模块的数据处理界面
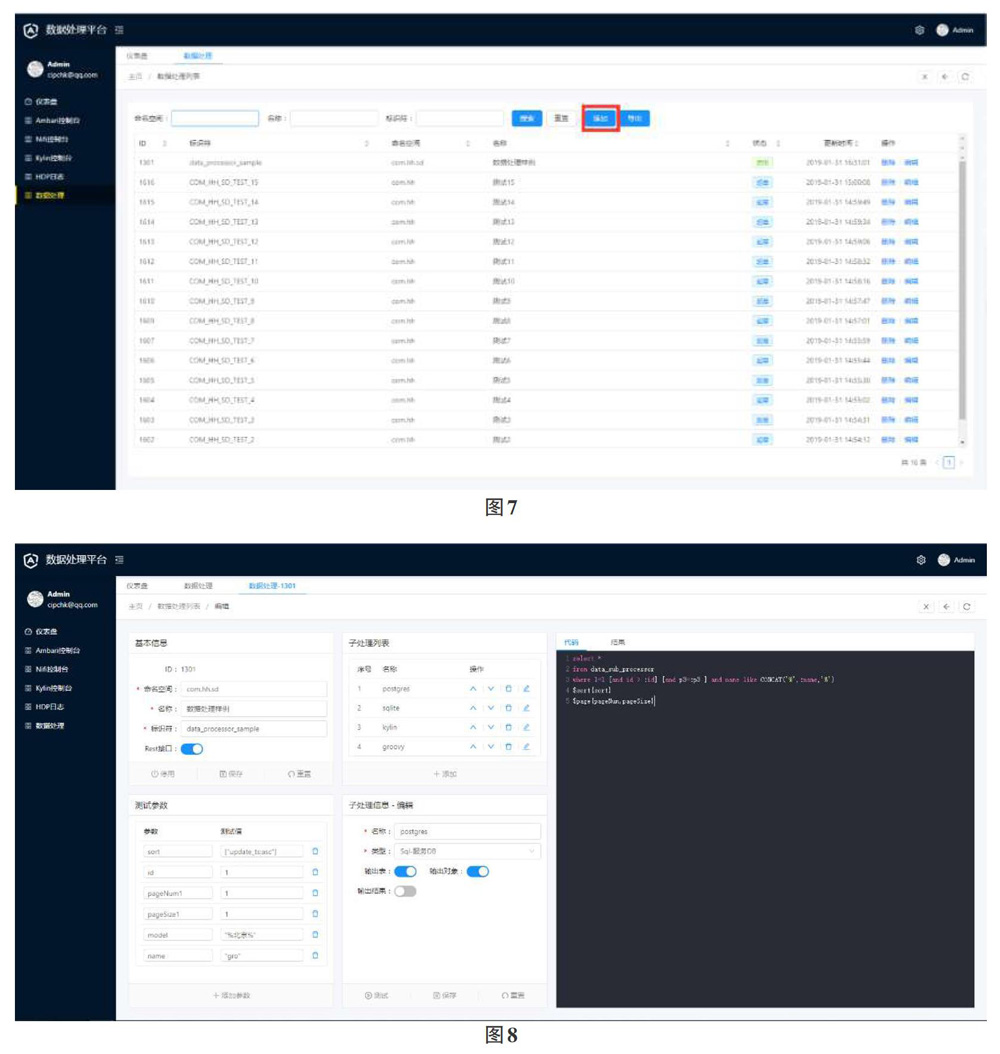
进人计算模块前台数据处理界面,点击“添加”按钮。
如图7所示。
填写基本信息:
命名控件:用于将计算分组,方便排序/搜索。
名称:中文名称,方便阅读。
标识符:需全局唯一,用于外部系统调用该计算。
6.3计算开发
数据处理(计算)是通过顺序执行“子处理”实现的。
uI元素介绍:
1)基本信息:数据处理的基本信息;Rest接口决定该数据处理是否支持外部系統的Rest调用;“停用”/“启用”按钮可停用/启用该数据处理。
2)测试参数:方便子处理的开发,可随时测试运行。
3)子处理列表:用于添加/排序删除子处理。
4)子处理信息:
名称:子处理名称,在该数据处理范围内唯一,计算结果中将用该名称作为结果键值
类型:目前支持以下类型
[Sql-服务DB]代码类型为PostgresSQL,用于查询计算服务本身的数据库。
[Sql-Kylin]代码为KvlinSQL,用于查询Kylin中的Cube表。
[Sql-Oracle]代码为Oracle SQL,用于查询配置中指定Ora-cle实例的数据表。
[Sql-中间结果]查询内存Sqlite数据库,前置子处理需开启“输出表”,表名为子处理名称。
[脚本Groovy]前置子处理需开启“输出对象”。
输出表:若子处理开启该项,结果将存储与内存sQLite数据库,表明即为该子处理名称,后续的“Sql-中间结果”子处理可编写sql访问该数据。
输出对象:若子处理开启该项,数据结果将存储与内部数据结果(HashMap),键值为该子处理名称,后续“脚本-Groovy”子处理可编写Groovy脚本访问该数据集。
输出结果:若子处理开启该项,结果将最终返回给调用者。
代码:子处理的具体代码,根据子处理“类型”,填写SQL或Groovy脚本。
如图8所示。
5)测试子处理:
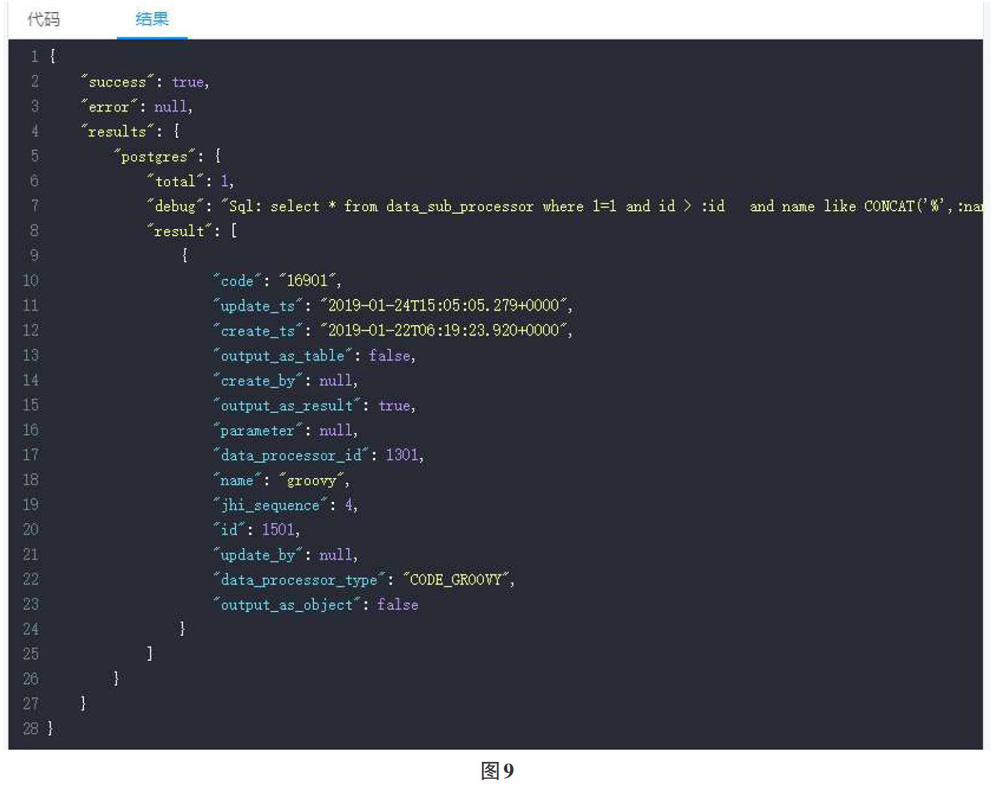
测试子处理将顺序执行子处理至“当前”子处理,传人参数为“测试参数”,结果JSON字段说明:
success:是否成功。
error:若失败,返回具体错误信息。
results:结果集,键值为子处理名称,包含开启了输出结果的前置子处理结果和当前子处理结果。
如图9所示。
6)外部系统调用
identNer:数据处理的标识符
paramMap:输人参数,类型为JSON,例:
{“paraml”:“valuel”,“param2”:100}
7总结
基于Ambari搭建大数据基础设施,将汽车行业的大量结构化、非结构化的数据经处理后导入Hive或Hbase存储。基于SpringCloud脚手架JHipster开发计算模块,开发效率可以高出50%,可以发布为Docker容器根据访问量自由做横向扩展。使用Kvlin对数据进行降维处理,计算模块的大数据检索效率更高。该项目可以被外部系统用来做数据分析,大数据可视化,机器学习,人工智能等。
- 卫星结构装配过程中的多余物控制
- 老年人健康监测手表设计
- 基于机械手的硅片搬运浸泡应用研究
- 基于FANUC Series Oi Mate—TD系统的恒线速车削应用
- 工业自动化控制技术的发展与应用
- 新能源车辆检测线计量检定测试系统设计
- 四旋翼无人机轻量化结构改进设计
- 飞行器蒙皮多点拉形研究分析
- 机床主轴振动测试分析
- 飞机复杂零件的超声检测分析与无损检测
- 试析配网自动化建设对供电可靠性的影响
- 飞机大部件装配中干涉问题研究
- 无人机遥感监测在水土保持监测中的应用
- 基于显示器亮度提升对强光对比率的影响研究
- 基于深度学习技术在专利图像审查中的应用
- 基于自抗扰技术的热压控制系统研究
- 矿产地质勘查理论及技术方法研究
- 深床反硝化滤池在市政污水深度处理中的应用
- 建筑弱电工程的管理问题分析
- 生物制药技术在制药工艺中的应用
- 概念车外观件注射成型模的简化设计
- 高强聚酯纤维整体柔性网在串草圪旦煤矿综放工作面收尾应用
- 预拌混凝土搅拌站绿色生产技术探讨
- 一种大吨位小台面精密液压机框架设计
- 离子注入后氧化层BOE腐蚀工艺优化
- intersubstitutabilities
- intersubstitutability
- intersubstitutable
- intersubstitution
- intersubstitutions
- intersyllabic
- intersystem
- intersystematic
- intersystematical
- intersystematically
- intertalk
- inter-talked
- intertalked
- inter-talking
- intertalking
- intertalks
- interteam
- inter-team
- intertentacular
- interterminal
- interthronging
- intertinge
- intertinged
- intertingeing
- intertinges
- 风流动或消逝
- 风流千古
- 风流博浪
- 风流司马
- 风流子
- 风流尔雅
- 风流座
- 风流张敞
- 风流张绪
- 风流才子
- 风流才调
- 风流放浪
- 风流放荡
- 风流放荡的人
- 风流文人的优雅意趣和情思
- 风流旖旎
- 风流淹雅
- 风流潇洒
- 风流潇洒的样子
- 风流潇洒,温文含蓄
- 风流的女子
- 风流缊借
- 风流罪
- 风流罪犯
- 风流罪过