柴伟

摘要:句法分析是对一个句子成分进行分析的过程,主要分为短语结构句法分析和依存结构句法分析,句法分析的结果对后续语义分析等产生重要影响,因此句法分析是自然语言处理中十分重要的一个环节。短语结构句法分析研究的基本发展过程是从利用语言规则进行句法分析到使用统计的方法进行句法分析,目前,在神经网络的基础上进行短语结构句法分析,对语言形态研究具有重大意义。
关键词: 句法分析; 短语结构; 自然语言处理
中图分类号:TP391? ? ? ? 文献标识码:A
文章编号:1009-3044(2020)16-0026-02
Abstract: Parsing is a process of analyzing a sentence component. It is mainly divided into constituency parsing and dependency parsing. The result of parsing has an important impact on semantic analysis. Therefore, parsing is a very important in natural language processing. The basic development of constituency parsing is from rule-based parsing to statistical parsing. At present, parsing based on neural networks is of great significance to the language morphology.
Key words: parsing; constituency parsing; natural language processing
1 引言
句法分析在自然語言处理中起着承上启下的作用,句法分析是在句子分词之后,对分词后的句子成分之间的关系进行进一步分析,将句子成分中短语成分使用树状或依存关系的形式表示出来,不论在汉语还是其他少数民族语言的句法分析原理基本一致,但各语言间存在特殊的语法结构,因此在短语结构句法分析研究中,需要结合语言特点进行句法分析研究。
2 短语结构句法分析基本理论
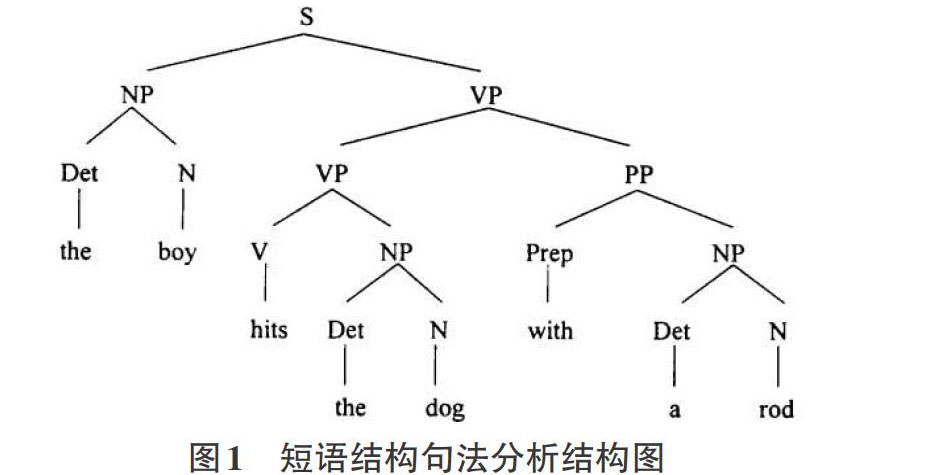
短语结构句法分析主要研究的是将句子中的成分使用标记集进行标注,标记集一般分为:词性标记,如名词(N),动词(V)和短语类型标记,如:名词短语(NP)、介词短语(PP)。短语结构句法分析的结果一般使用树形结构进行表示,例如句子the boy hits the dog with a rod,其短语结构句法分析结果如图1所示。
短语结构句法分析主要经历了几个阶段:
第一阶段(1950年初—1990年左右):使用语法规则进行短语结构句法分析,这个阶段主要是基于语言学家提供的语法规则形成规则库后,根据规则库中的已有规则进行句法分析,规则库并不能完全涵盖所有语言规则,例如在汉语中存在大量歧义现象,基于规则的句法分析速度慢,准确率较低。
第二阶段(1990年—2010年左右):将统计的方法引入句法分析过程中,利用大量已经将短语成分标注好的语料作为基础,使用统计的方法将短语成分的概率进行计算,在句法分析时,采用上下文关系以及语料库得出的概率进行计算后,找到概率最大的短语标注,就是句法分析的结果,相较于基于规则的方法其分析速度及准确率大大提高。
第三阶段(2010年—至今):在基于规则和基于统计方法的基础上将神经网络引入句法分析中,将RNN、LSTM等神经网络应用在句法分析中,通过神经网络计算得到的模型更加符合语言规则,大大提高了句法分析的准确率及分析速度。
3 短语结构句法分析方法
3.1 基于规则的短语结构句法分析
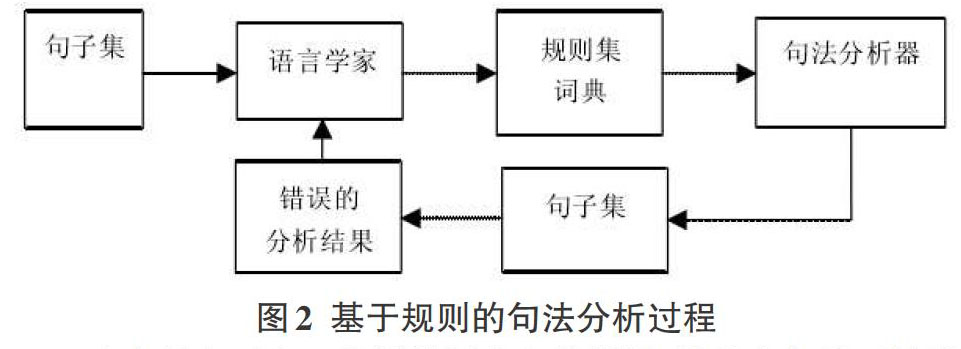
基于规则的短语结构句法分析方法主要是根据语言学家提供的规则库推导出句子的句法结构如图2所示,基于规则的方法主要分为以下几种为:
1)自顶向下法。根据规则库中的规则,从整个句子开始进行短语结构的分析,首先查看顶层结构(句子和子句)的规则,然后考察顶层结构的下属各成分的规则,如此进行直到一个完整的句子结构被建立起来为止,如果这一句子与输入数据相匹配,分析便结束,否则,它便从顶层重新开始,生成另外一种句子结构,最终就可得到一个完整的句法树。
2)移进-规约方法。移进-规约方法也叫作自底向上法,是由Ullman[1]等人提出,主要分为四个动作:移进(shift)、规约(reduce)、标记短语(label-X)和不标记(nolabel)。移进-规约法需要一个栈对当前词进行存储。主要过程为在句子分词及标注词性后,从句子的第一个词开始,进行移进动作存入栈中,在移进操作完成后根据规则库中规则判断是否可以标记为短语,若不能标记为短语继续进行移进入栈操作,在每次移进入栈操作完成后需要判断当前栈中是否可以根据规则组成一个短语,如果可以组成短语则根据规则标记为相应短语,若句子中有n个词,那么需要2(2n-1)步可得出句法树。
3)CYK方法。Kasami[2]等人提出CYK方法,其基本原理为:对于一个长度为n的句子,首先第一步从i=1开始,确定句子中每个词Wi对应的词性标记bi1;第二步是在确定完成词性标记后,对于1 ≤h 在以上基于规则的方法上还衍生出一些改进的方法:例如欧雷分析算法(Earley parsing)[3]、左角分析法以及富田算法[4]等。 3.2 基于统计的短语结构句法分析 基于统计的句法分析分为两个步骤:训练(train)和解码(decode)。训练步骤是在语料库的基础上通过统计学建立句法分析模型,解码是在根据模型预测找到概率最大值得到句法分析结果,分析过程如图3所示,基于统计的句法分析主要分为以下几种方法: 1)PCFG方法。PCFG是概率上下文无关文法是由Charniak[5]提出,在基于规则的基础上根据语料库计算每一条规则的概率,在进行句法分析时,根据规则的概率计算每棵句法分析树的概率,那么最终句法树就是所有规则的有序集合。PCFG方法无法利用上下文信息,因此难以解决句法分析中的歧义现象。 2)条件随机场(CRF)方法。John[6]等人为解决序列标记中的偏置问题,提出了CRF方法,CRF是一种基于概率无向图模型的方法,对于给定一个句子x=x1x2…xn作为输入序列,则无向图中有n个节点,假设y=y1...yn为句法分析输出序列,那么根据条件随机场其概率计算为: 其中参数λk和μk是通过语料库中计算得到,序列fk(yi-1,yi,x)是输入序列对应的位置i-1与i的标记特征函数,gk(yi,x)是位置i的输入序列和输出序列的状态特征函数,最终求得概率无向图模型的概率最大值后,通过解码算法就可得到句法分析的结果,可以看出CRF可以利用句子中词的上下文信息,解决了句法分析中的歧义现象。 除了以上两种较为常见的分析方法,还有一些方法如:最大熵方法[7]、基于歷史的句法分析[8]、分层渐进式句法分析[9]、头驱动的统计句法分析[10]以及一些将基于规则的方法与基于统计的方法相结合,解决的句法分析中的歧义问题。 3.3 基于神经网络的短语结构句法分析 基于神经网络的句法分析主要是在生成句法分析模型时,借助神经网络获得句法分析中所需的上下文信息以及词性等影响句法分析准确率的因素。因此绝大部分基于神经网络的句法分析都是在基于统计的方法上进行改进。因此基于神经网络的句法分析的一般过程为:将大量已经标注好短语标记的句子作为训练集,通过神经网络生成模型,将需要标记的句子输入模型预测后,使用分析算法将模型预测的最好结果输出作为句法分析的结果。 在基于神经网络的句法分析中,使用较多的神经网络类型为LSTM(Long Short-Term Memory) 是具有长期记忆能力的一种时间递归神经网络RNN(Recurrent Neural Network)。LSTM中能向单元状态中移除或添加信息的结构称为门限,包括:遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。当输入训练集后,将句子转化为向量序列,输入门决定当前输入向量序列的被采纳的程度,遗忘门决定记忆被遗忘的程度,输出门决定记忆中的在当前输出的程度。LSTM其相较于CNN、RNN优势在于能获得较长距离的上下文信息。如James Cross[11]等人通过使用2个双向的LSTM与移进-规约句法分析相结合,提高了句法分析的准确率。 短语结构神经网络句法分析还有一些方法,例如Greg Durrett[12]等人在CRF句法分析的基础上加入了神经网络,利用神经网络特定获得句法分析中的特征,从而进一步提高句法分析的准确率。Jiangming Liu[13]等人提出了在移进-归约短语句法分析中使用Bi-LSTM获得句子全局特征,使得句法分析过程充分利用了句子的上下文信息。这些方法都是在基于规则或基于统计的方法上,利用神经网络特点,对句法分析中特征提取等方面进行改进。 4? 总结与展望 句法分析作为自然语言处理中的重要一环,基于短语结构的句法分析更是句法分析中的重中之重,随着神经网络的发展,利用最新的神经网络技术提高短语结构分析的准确率也成为当前研究的重点,目前的短语结构句法分析研究多在模型的训练阶段进行改进,在今后的研究中还需要对句法分析的解码准确率进行进一步的提高。从而使得短语结构的句法分析水平有更大的提升。 参考文献: [1] Aho AV, Ullman JD. The Theory of Parsing, Translation and Compiling[J]. Englewood Cliffs, NJ: Prentice-Hall. [2] Kasami T. An Efficient Recognition and Syntax Analysis Algorithm for Context-free Language[R]. Technical Report AFCRL-65-785. Bedford, MA,1965. [3] Earley J. An efficient context-free parsing algorithm[M]. Readings in natural language processing. 1986. [4] Tomita M.Left-to-right on-line parsing[M]//Efficient Parsing for Natural Language. Boston, MA: Springer US, 1986: 95-102. [5] Baayen R H,Charniak E.Statistical language learning[J].Language, 1997,73(3):588. [6] John L. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[J]. 2001. [7] A.Ratnaparkhi. Learning to Parse Natural Language with Maximum Entory Models[J]. Machine Learning, 1999,34:151-178. [8] Marcus. Linguistic Theory and Computer Application[J]. New York,Acsdemic Press, 1980:69-112. [9] Steve Abney. Rapid Incremental Parsing with Pepari[C]. In Preceeding of the 6th New OED Conference: Electronic Text Research, 1990:1-9. [10] Collins M.Head-driven statistical models for natural language parsing[J].Computational Linguistics, 2003,29(4):589-637. [11] Cross J , Huang L . Incremental Parsing with Minimal Features Using Bi-Directional LSTM[J]. 2016. [12] Durrett G, Klein D. Neural CRF Parsing[J]. Computer Science, 2015. [13] Liu J M,Zhang Y.Shift-reduce constituent parsing with neural lookahead features[J].Transactions of the Association for Computational Linguistics, 2017,5:45-58. 【通联编辑:唐一东】
- 就业优先政策面临“三大难题”
- 我国中长期人口结构变化及社会风险分析
- 抢抓“一带一路”机遇打造创新创业之都
- 进一步扩大对港澳服务贸易开放的思路与对策
- 武汉打造全国审批服务最优和营商环境最好城市
- 全球供应链的变化趋势和对策建议
- 推动我国第四次工业革命及颠覆性技术创新的分析和建议
- 全面提升家政服务质量打造民生经济新增长点
- 坚持以人民为中心的发展思想推动家政服务业高质量发展
- 养老服务上半年工作进展、问题及下半年建议
- 当前制约我国高技术产业高质量发展的突出问题和对策举措
- 上半年地区经济形势的三个亮点和三个隐忧
- 上半年新型城镇化工作成效及未来推进的四个着力点
- 2019年上半年经济形势分析及政策建议
- 我国经济运行延续总体平稳、稳中有进态势
- 最后一个工厂1
- 宁夏利用外资的一些回忆
- 以基层党建引领脱贫 以脱贫夯实基层党建
- 深化合作 促进草牧业共同发展
- 社区养老服务业发展的两个角度和五个判断
- 石化产业高质量发展要把集约高效放在首位
- 建设现代化产业体系要处理好六大关系
- 深化要素市场化配置改革的思路
- 相关领域供给侧结构性改革稳步推进
- 以质量提升推动品牌建设 以品牌建设引领现代农业发展
- semiexecutive
- semiexperimental
- semiexperimentally
- semiexposed
- semiexposure
- semiexposures
- semiexternal
- semiexternally
- semi-fabricated
- semi-feral
- semiferine
- semifiction
- semifictionally
- semifictions
- semifictitious
- semi-field
- semifigurative
- semifiguratively
- semifigurativeness
- semifigurativenesses
- semifinal
- semi-final
- semi final
- semi-finalist
- semi-finished
- 抡吧
- 抡圆
- 抡才
- 抡择
- 抡拳
- 抡搭
- 抡杀威棒
- 抡材
- 抡枪
- 抡棍乱夯
- 抡眉竖眼
- 抡着
- 抡粪
- 抡荤
- 抡起
- 抡选
- 抡魁
- 抢
- 抢上风
- 抢人主顾,如杀父母
- 抢修
- 抢元
- 抢先
- 抢先一步,赶在前头
- 抢先不按次序