高建平 董东
摘要:针对高校一卡通系统中大量消费数据和图书馆系统的访问数据,设计并实现了学生日常行为聚类模型,根据行为习惯将学生划分为五大类,利用Microsoft顺序聚类算法实现了学生行为序列的挖掘,发现了“体弱”人群存在不规律饮食习惯等有意义的行为序列模式,最后针对体弱人群在两个模式上的共性和差异进行总结。
关键词:一卡通;智慧校园;校园数据;数据挖掘;行为分析
中图分类号 ?TP311 ? ? ? 文献标识码:A
文章编号:1009-3044(2020)25-0052-03
Abstract: In order to find interesting patterns from a large amount of consumption data accumulated in campus card systems and history data from library access control systems, a daily behavior clustering model for college students was designed and implemented. It is found that students can be divided into five categories based on behavioral habits. Moreover, by the Microsoft sequential clustering algorithm for mining of student behavior sequences, several meaningful patterns of behavioral sequences, such as "weak" people have irregular eating habits, is discovered, and finally the commonalities and differences between the two groups of weak people are compared.
Key words: campus card; smart campus; campus data; data mining; behavioural analysis
1 引言
一卡通系统在高校应用范围越来越广,使得一卡通产生大量真实反映学生在校情况的数据,毫无疑问这些数据蕴含着有价值的信息。面向校园数据的挖掘分析也逐渐成为及时把握学生情况,正确引导学生学习生活,提高高校管理水平的重要研究方向。
2018年6月7日,国家标准《智慧校园总体框架》的发布[1],将“智慧校园”(Smart Campus)定义为“物理空间和信息空间有机衔接,使任何人、任何时间、任何地点都能便捷地获得资源和服务。”高校也逐步从数字化校园迈向智慧校园,通过校园内一切可以利用的数据来为高校和师生提供服务,真正实现以人为本,可见校园数据是实现智慧校园建设的基本条件[2]。校园信息系统[3]是一个封闭的环境,数据只准写入,不允许修改,历来以准确性和真实性为准绳,而且还存在着相互校验的可能,校园数据来源于多个业务系统并经过长时期的数据沉淀,数据总量存在显著的海量特性,同时存在显著的人、财、物、时间等多维特征,各有不同的数据尺度又呈复杂的关联性,所以校园数据具备充分的数据挖掘分析的潜力和应用建设的基础,以校园数据为抓手,在校园数据分析的建设和应用方面,能够产生显著的应用效果。
因此本文主要通过大量校园数据及对智慧校园的建设需求,设计并实现了学生日常行为聚类模型和行为序列模型,发现了有价值的行为模式,并从不同模型中發现体弱人群的共性和差异,为高校提出可靠的管理建议。
2 数据预处理
数据清洗的干净程度决定数据质量,高质量的数据会提高后期数据挖掘和分析的效率。
2.1 数据采集
数据来源是数据挖掘分析的基础。通过在一卡通管理平台和制卡中心的专业实习体验及对智慧校园的建设需求,确定数据来源和主题。本文主要是由S高校提供的数据,具体来源于一卡通管理平台和图书馆系统。主题是2017级学生的行为数据,采集的源数据主要包括:学生信息表、消费记录表、学生部门表、图书馆访问表。
2.2 数据清洗
针对数据中存在的缺失值(空值)、不满足业务需求和约束、数据不一致、重复行和键值、表和字段名称晦涩难懂等问题,通过指定值替换空值或不一致的值、修改不满足业务约束的值、删除不满足业务需求、去除重复行、清晰易懂的表和字段的名称替换晦涩难懂的名称、验证数据行数不变等技术,完成数据清洗转换与验证[4]。经过清洗后,消费记录表由11708467行减少到7112272行数据,图书馆访问数据由11738025行减少到854664行数据,学生部门表239行,学生信息表7427行。
3 数据挖掘模型设计和方法
数据挖掘分析模型包括数据挖掘结构和数据挖掘算法。其中数据挖掘结构中定义了作为输入的事例表,数据挖掘算法是从训练集中寻找知识,算法要求定义输入列和预测列[5]。
3.1 挖掘工具
本文主要采用SQL Server 2008数据库,挖掘工具是由商业智能解决方案(Business Intelligence Development Studio)提供的组件SQL Server Analysis Service(SSAS)。SSAS提供了包括Microsoft聚类分析、关联分析、时序等在内的9种数据挖掘技术,其中重点利用的数据挖掘技术为Microsoft聚类和Microsoft顺序聚类。SSAS不仅仅提供了一组行业标准的数据挖掘算法,而且通过数据挖掘设计器能够创建、管理和可视化浏览数据挖掘模型,在挖掘模型查看器中通过多种分类关系图查看聚类和顺序聚类的结果。
3.2 挖掘算法
数据挖掘算法的选择是挖掘型分析的核心。根据数据的特点和结构,选择合适的算法对数据进行挖掘分析。
3.2.1 K-Means算法与Microsoft聚类分析
通过分析学生日常行为数据,发现数据量大且数据类型普遍是数值型,因此综合考虑选择动态聚类算法中最普及的K-Means算法。通过大量未分类的学生日常行为数据,利用K-Means算法自动串行聚成不同的组,从而将学生划分为不同的类别,配合使用Microsoft聚类算法的分类图观察聚类结果,将分类进行特征标注和挖掘分析。
3.2.2 Microsoft顺序聚类分析
Microsoft顺序聚类算法将马尔科夫链和聚类结合,主要目的是发现异常的序列。针对学生每天的行为进行排序形成学生行为序列,进而发现异常的行为序列模式,主要挖掘过程包括建立数据源、数据视图和数据挖掘模型,最后通过观察挖掘模型和钻取等操作发现行为序列的疑点。
3.3 模型设计
3.3.1 学生日常行为聚类模型
从不同的日常行为出发,利用PIVOT函数实现不同行为次数和金额属性的行转列,最终完成包括就餐、淋浴、购物、就医、图书馆访问等日常行为的次数或金额[6],共计9种挖掘属性,形成学生日常行为事实表,然后结合学生基本信息属性进行聚类,发现学生的日常行为习惯,从而将学生划分为有特点的几类,并对聚类结果进行分析[7]。具体设计方案如下:
(1)创建学生日常行为聚类的数据源和数据视图;
(2)定义挖掘结构:
数据挖掘技术:K-Means算法和Microsoft聚类分析;
数据源视图:学生日常行为聚类,通过学生序号建立两个表之间的关联;
事例表:学生日常行为表,学生序号作为事例键;
输入列:就餐次数和金额、购物次数和金额、淋浴次数和金额、医疗消费次数和金额、图书馆访问次数、性别、所在学院、学生类别。
3.3.2 学生行为序列模型
从不同行为次序出发,将学生从早到晚的刷卡行为进行排序,即每个学生每天均对应一个行为序列,最后利用Microsoft顺序聚类算法发现有意义的学生行为序列模式[8]。首先根据每个学生每天在不同时段对应的行为利用SQL语句进行排序,形成学生行为序列,其次将学生序号与刷卡日期组合形成新的字段作为一次行为的编号。最终形成学生行为序列嵌套表和刷卡学生行为信息事实表,且两表之间是一对多关系。具体设计方案如下:
(1)创建学生行为序列分析的数据源和数据视图;
(2)定义挖掘结构:
数据挖掘技术:Microsoft顺序聚类分析;
数据源视图:学生行为序列分析,通过刷卡码与刷卡ID建立两个表之间的关联;
事例表:刷卡学生信息表,刷卡ID作为事例键;
嵌套表:学生行为序列表,行为序列作为嵌套键;
输入列及预测列:行为序列、刷卡码。
4 数据挖掘分析
4.1 日常行为聚类结果分析
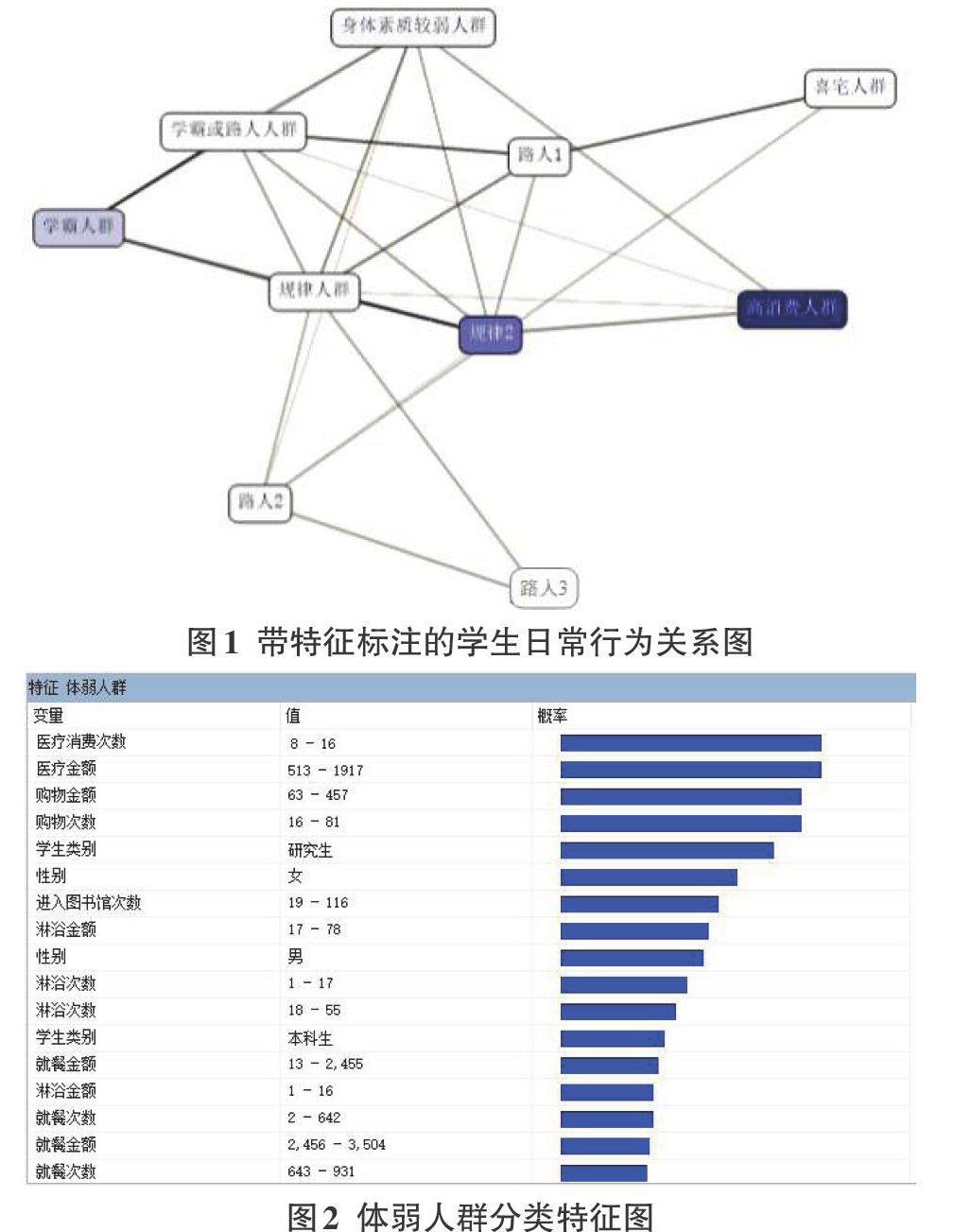
如图1所示,通过筛选敏感度变量和状态来观察各个分类的特征,并将划分好的类别进行特征标注,方便观察和分析。
如图2所示,通过进一步观察分类特征图发现体弱人群中女生最多,且因S高校中研究生人数与本科生悬殊较大,此类人群中研究生群体特征显著。
根据以上对学生日常行为聚类结果的综合分析,将学生划分为以下五类:
(1)高消费人群:消费较高,无论是就餐还是购物消费均为最高,很少去图书馆,喜欢洗澡并且洗澡花费的金额较多,这类人群中本科生最多且多为女生;
(2)喜“宅”人群:消费很低,无论是就餐、购物、淋浴、医疗消费均很低,可见这类人群消费较少,几乎不出门,这类人群中博士生和研究生居多,且多为男性,可见此类人群中很可能有较多“宅男”类型的博士生和研究生;
(3)学霸人群:爱去图书馆,就餐次数和消费比较高,喜欢洗澡,且多为女生。可见此类人群中女学霸居多,并且饮食和起居生活都十分规律;
(4)体弱人群:医疗次数和金额均为最高,不爱洗澡且就餐毫无规律,此类人群中研究生特征最为突出;
(5)一般人群:各个变量的平均值占比较高的人群,说明无论是就餐、淋浴、购物、图书馆访问、医疗等消费金额和次数均为平均水平,此类人群的消费很正常,生活和学习也十分规律。
针对“体弱”人群的聚类结果可以推断出:
(1)不规律就餐和洗浴的学生经常去医务室;
(2)研究生群體普遍身体素质偏弱。
4.2 行为序列聚类结果分析
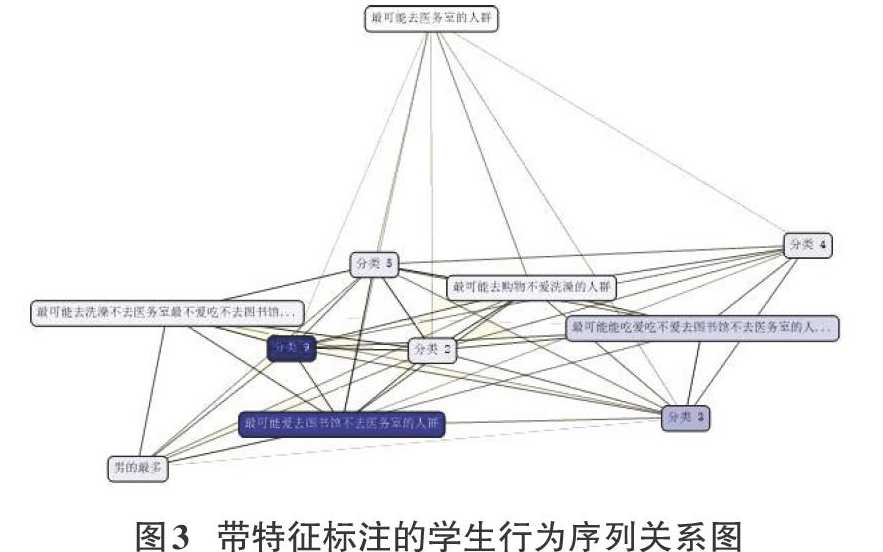
如图3所示,通过筛选明暗度变量和状态,将五种行为序列人群分别进行特征标注(最可能去或最不可能去)。
如图4所示,通过进一步观察学生行为序列聚类结果和刷卡行为.samples属性状态的图例进行综合分析,发现以下挖掘结果:
(1)存在最可能去餐厅就餐但不爱去图书馆和医务室的人群;
(2)此类人群的行为序列中餐厅就餐最多且十分规律。
针对此类人群的聚类分析结果可推断出:
(1)规律饮食的人群普遍不会去医务室;
(2)规律饮食与身体健康有着密不可分的联系。
5 结论
本文利用学生消费数据和图书馆访问数据设计并实现了聚类挖掘模型,通过聚类发现学生的日常行为习惯从而将学生划分为五类:一般、高消费、“宅”、学霸、体弱,发现了不就餐不洗浴的同学往往经常去医务室、研究生群体偏体弱等模式;通过Microsoft顺序聚类分析实现学生行为序列的挖掘,发现了规律饮食的人群普遍不会去医务室等学生行为序列模式。最后通过对比两个模型的挖掘结果,发现其分别从规律和不规律饮食两个相反行为习惯推出结论,但均证实“体弱”人群存在不规律饮食习惯。可见养成良好的饮食习惯有益于增强体质,同时高校应加强对不规律饮食人群的关注和管理,正确引导学生加强锻炼的同时也更应注重自身的饮食习惯。
参考文献:
[1] 国家市场监督管理总局中国国家标准化管理委员会.智慧校园总体框架:GB/T 36342-2018[S].北京:中国标准出版社,2018.6.
[2] 潘胜玲.智慧校园数据中心建设研究[J].电子世界,2020(2):41-42.
[3] 李增福.高职院校校园管理信息系统结构体系构建[J].科技资讯,2019,17(17):111,115.
[4] 董东,王艳君,陈玉哲.审计分析:从关系到大数据[M].北京:清华大学出版社,2019.
[5] 审计署,数据挖掘技巧(审计技巧丛书),北京:中国时代经济出版社,2016.5.
[6] 苏兆兆,栾静.高校本科生就餐数据挖掘分析[J].电脑知识与技术,2018,14(5):24-26.
[7] 游香薷,王业,杨抒,等.学生消费行为的聚类分析优化研究和应用[J].计算机系统应用,2017,26(6):232-237.
[8] 李蒙.基于校园大数据的学生行为挖掘方法应用研究[D].西安:西安电子科技大学,2019.
【通联编辑:王力】
- 新财务制度实施后如何加强医院财务管理
- 激励机制在医院人力资源管理中的合理应用
- 公立医院绩效管理误区分析及改进策略
- 现代医院后勤精细化管理的应用探析
- 供给侧改革下的医院财务精细化管理思考
- 医院人才培养和人才梯队建设方法探索
- 纵横质控模式在基层医院病房管理中的应用
- 湖南省社科优秀成果评奖的经验及优化建议
- 哈尔滨市新材料产业集群发展研究
- 工程总承包中的设计责任
- 新零售背景下连锁餐饮企业如何转型与发展
- 池州市民营企业大学生人才流失分析
- 对吉利控股集团跨境并购的研究
- 工程项目成本管控策略探讨
- 建筑工程项目成本控制研究
- 研发投入对创新绩效的影响
- 水泥制造业的成本控制研究
- 关于团队管理中沟通问题的探讨
- 对比分析法和趋势分析法在加油站开发中的探究
- 电池制造企业供应链管理的相关重点问题
- 基于电力企业人本管理的思考
- 人力资源培训开发与企业可持续发展
- 基于大数据的企业培训管理创新思考
- 农村义务教育公费管理使用中的问题与对策
- 企业内部控制在财务风险管理中的应用研究
- holiest
- holiness
- holinesses
- holing
- holing-up
- holing up
- holistic
- holistically
- holistic-medicine
- holler
- hollered
- hollerer
- hollering
- hollers
- hollies
- hollow
- hollowed
- hollower
- hollowest
- hollowing
- hollowly
- hollowness
- hollownesses
- hollow out
- hollows
- 国均
- 国基
- 国境
- 国境之内,全国
- 国境之外
- 国境以内之地
- 国士
- 国士无双
- 国外
- 国外外语教学法主要流派
- 国外来的商人
- 国外汉英语法对比研究
- 国外的中秋节
- 国外的端午节
- 国奥
- 国奥队
- 国姝
- 国威
- 国娃
- 国子
- 国子学
- 国子监
- 国子监祭酒
- 国字
- 国字号