张云洋
摘 要: 通过分析藏文网站中藏文字符的编码特点,结合搜索引擎的特点对藏文网页搜索的关键技术进行了研究。对藏文网页的URL处理技术、限定爬虫、藏文网页倒排索引的建立、网页的检索和结果排序等进行了详细地阐述,提出了较完整的藏文网页搜索方法,对于藏文网页信息的搜索和利用有一定的实用价值。
关键词: 藏文编码; 搜索引擎; 倒排索引; 网页爬虫
中图分类号:TP393.4 文献标志码:A 文章编号:1006-8228(2017)06-22-04
Research on key technologies of Tibetan web search
Zhang Yunyang
(Library of Tibet University, Lhasa, Tibet 850000, China)
Abstract: Through analyzing the characteristics of the Tibetan characters' coding in Tibetan website, and introducing the characteristics of the search engine, this paper studies the key technologies of Tibetan web search. The technologies of URL processing, the qualified crawler, inverted index, words' retrieval, sorting for results and the others for Tibetan web are discussed in detail. This paper proposes a relatively complete method for Tibetan web search, which has certain practical value for Tibetan web's information search and use.
Key words: Tibetan coding; search engine; inverted index; Web crawler
0 引言
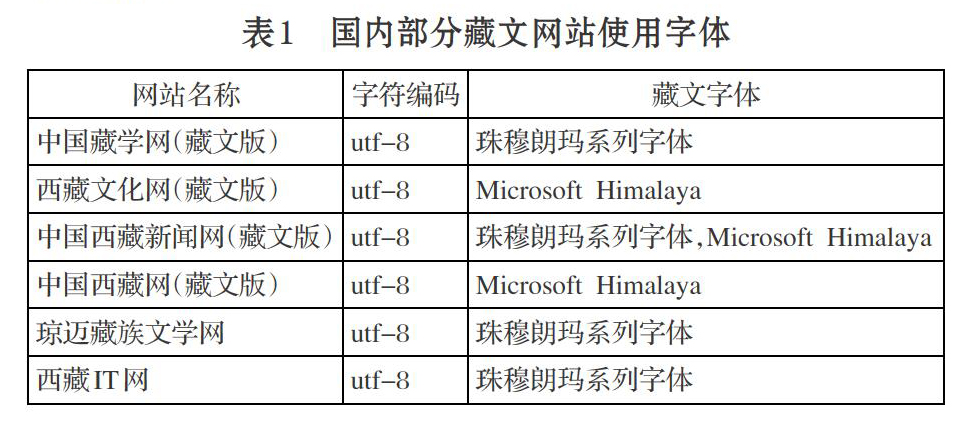
藏族是我國民族大家庭的重要成员,藏语言文字是藏族同胞在日常工作/生活中广泛使用的文字。几千年以来,藏文字作为信息文化的传播载体,对于传承藏民族传统文化、传播现代科技知识和促进地区经济的发展都发挥着重要的作用。在计算机世界中,藏文字区别于汉字和英文的最主要特征是字符编码,目前国内网站多数使用GBK编码存储信息,使用基于GBK的字体显示文字。而目前的藏文网站,为了方便兼容和统一检索,主要使用基于国际标准编码的Microsoft Himalaya字体和珠穆朗玛系列字体。
1 藏文网站字符编码技术
藏文在计算机和国际互联网的使用,在输入法和字体方面采用基于Unicode字符集的方法较为合理,方便信息共享,方便藏文广泛交流。互联网世界的藏文网站和网页,现在都倾向于使用基于Unicode的藏文字体。
通过对国内比较著名的藏文网站源码分析发现,主要的藏文网站均采用utf-8编码,即藏文字符采用国际标准编码Unicode字符集,而藏文字体采用基于Unicode的珠穆朗玛系列字体和 Microsoft Himalaya字体。国内部分藏文网站和网站的字符编码及字体分析如下。
2 网页URL处理
2.1 URL简述
URI:Universal Resource Identifier,通用资源标志符。URI通常由三个部分组成:访问资源的命名机制,存放资源的主机名,资源自身的名称[1]。
URL是URI的一个子集,它是Uniform Resource Locator的缩写,译为“统一资源定位符”,即通常说的网址。URL是Internet上描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上。采用URL可以用统一的格式来描述各种信息资源,包括文件、服务器地址和目录等[2]。URL的格式由三部分组成:第一部分是协议(或称为服务方式);第二部分是存有该资源的主机IP地址(有时也包括端口号);第三部分是主机资源的具体地址,如目录和文件名等。
2.2 URL处理流程
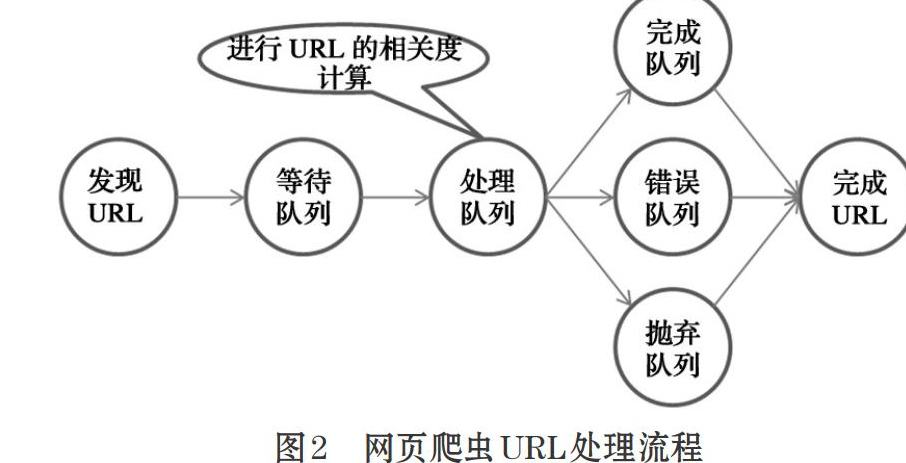
网页搜索并不是对实时的网站信息进行检索,在用户提交检索提问词后,实际上是转入搜索引擎的索引数据库检索,这些索引数据库通常是由网络搜索引擎的爬虫进行采集、更新从而建立起来的。爬虫最主要的处理对象是URL,它根据URL地址取得所需要的文件内容,然后对它进一步处理,网页爬虫URL处理流程如图2所示。
3 藏文网页爬虫
3.1 爬虫“黑洞”
爬虫在搜集藏文网页的过程中,必须考虑可能出现的“黑洞”情况。爬虫黑洞是指,在抓取一张网页的链接时,链接本身是一个无限循环,导致爬虫抓取时跟着循环,浪费资源。有时一些URL看起来不同,但实际指向同一张网页,也会使爬虫陷入重复抓取的境地。
为了避免爬虫误入黑洞,一般采取两种策略。一是爬虫回避动态网页,因为动态网页常常会把爬虫带入黑洞。识别动态网页时,只需要判断URL中是否出现问题,含问号的就是动态网页。二是使用Visited表记录已经访问过的URL,凡是遇到新的URL存在于Visited表,就放弃对该URL的继续处理。例如:当遇到a→b→c→d→c→e这样的环路链接,爬虫就会掉进去,反复抓取c、d对应的页面。使用Visited表,就能避免这个问题。
3.2 限定爬虫
藏文网页搜索使用的爬虫,是一种限定爬虫,在爬虫的功能定位上只抓取藏文的网页,本质是对网页文本所用语言的限定。藏文网页的限定爬虫,表面上是限定语言,具体操作层面需要通过限定IP、限定URL、限定charset来实现。
限定爬虫就是对爬虫所爬取的主机的范围做一些限制,通常,限定爬虫包含以下几个方面[3]:①限定域名的爬虫。比如,只抓取edu.cn结尾的域名;②限定爬取层数的爬虫。比如,限定只抓取2层的数据;③限定IP的抓取。比如,只抓取西藏自治区内的IP;④限定语言的抓取。比如,只抓取中文汉字页面。
抓取藏文网页一方面要设计限定爬虫,另一方面建立动态更新的藏文网站域名库、藏文网站主机IP库,配合限定爬虫工作。目前已有部分藏文网站在页面中加入了标记,如中国藏学网采用的是,西藏IT网采用的是,琼迈藏族文学网采用的是。可以根据网页代码中的标记来识别判断藏文网站。藏文网站域名库和藏文网站主机IP库,需要人工操作,人为添加一些地址,这方面参照现在互联网广泛使用的“纯真IP数据库”实现。
3.3 藏文网页倒排索引
藏文网页倒排索引的建立流程如下。
第一步:抽取网页正文。网页正文是相对网页噪声而言。当今的互联网网页上,页面的很多篇幅用在广告、搜索推荐和其他链接上。网页搜索工具关注的是网页本身要表达的信息,所以在通过爬虫获取到页面源码之后,要去除那些与本文无关的噪声,抽取到网页正文。
第二步:分字。藏文文字区别于汉文,汉文是一个字使用一个编码,而藏文是对组成字的基字编码,一个完整的藏文字可能存在多个编码,这些编码按组成藏文字的方法顺序排列。藏文的分字通过藏文字分隔符 ‘ 来实现,如
第三步:对全文以字建索引。以字建索引,虽然检索过程的匹配计算量会更大,但考虑到目前藏文网页总体数量不大,应该是一种可行的提高查全率的办法。根据上一步得到的字,记录每个字在文中出现的位置,计算每个字出现的次数,建立链表。位置用于检索时的准确定位,次数用于计算字对文档的重要性,也用于相关性排序计算。
第四步:对标题建索引。大部分的Web文档有文档标题TITLE,标题反映了文档的主要内容,是搜索和导航的重要依据。标题索引以词、短语或句子为索引单位,具体根据词表匹配情况确定,如果标题匹配词表中的规范词则使用规范词,如果没有则直接以标题建索引。藏文规范词表是动态更新的。检索时以匹配标题索引为优先策略,先查询标题索引库,再查询全文索引库。
第五步:索引庫更新。网站的页面信息是动态更新的,由网络爬虫抓取得到的藏文网页倒排索引库也需要更新。搜索引擎的倒排索引更新有多种方式,包括修改更新、覆盖更新和添加更新。鉴于目前上线的藏文网站数量少,网络爬虫工作周期短,藏文网页的倒排索引库更新可以采取添加更新加覆盖更新的策略。每次爬虫工作完成后,建立新的索引库,将查询引擎链接指向新的索引库,同时保留近两期的索引库,将更早的索引库删除。每次添加新的索引库后,先将之前近两期的索引库保留一段时间备用。
4 检索
藏文网页搜索工具为用户提供检索藏文网页信息,先根据用户提交的检索提问标识,去匹配索引库中的网页信息标引标识[4],然后将匹配上的结果按相关系数降序排列,匹配出的每一项条目直接指向网页源地址,同时在结果页显示每条结果的网页快照,以高亮显示匹配字符。
4.1 检索词审阅
我国于2004年和2008年先后通过的《藏文编码字符集扩充集A》、《藏文编码字符集扩充集B》两套国家标准,收录藏文字符7205个,包括现代藏文、古藏文和梵音转写的藏文字符,藏文覆盖率达到99.99%[5]。在藏文网页搜索过程中,有必要对用户输入的藏文字进行拼写检查,确认输入的每个字是正确的藏文字。将这两套国家标准收录的藏文字逐一列出,查出对应的国际编码,建立藏文国际编码字表,在用户输入检索词时使用此表来进行文字审阅。
4.2 文字匹配
藏文网页搜索,实质是将用户输入的检索提问标识与索引库中的网页标引标识进行比对,找出匹配的条目。现有的字符编码体系,对汉字是以整字编码,如“汉”的GBK编码是“BABA”,“汉”的unicode编码是“6C49”;藏文字是对构成字的每个构件进行编码,因此一个藏文字的编码实际是由一个或多个构件的性,藏文字符匹配相对汉文和英文需要更大的计算量,比对一个字实际需要比对多个编码。
文字匹配采取精确匹配和模糊匹配两种策略。优先采用精确匹配,将理论上最相关的结果反馈给检索用户。如果精确匹配命中条目很少或者没有命中条目,采取模糊匹配策略,将近似相关的结果反馈给检索用户。精确匹配是找出完全包含检索词的结果集,模糊匹配是找出语义上近似的相关结果集。应用检索理论中的缩检与扩检,当命中结果很多时,筛选最相关结果集;当命中结果很少或完全没有时,逐步减小相关系数阈值,或多或少地为用户提供一些近似相关结果集,尽量满足用户的检索需求。
4.3 结果排序
检索结果排序是网页搜索的重要一环,一般的全文检索系统,是按更新时间和点击率对结果集排序,如利用文献管理系统查阅图书时,查询结果根据图书出版时间降序排列,或者根据外借次数降序排列,突出显示热门图书。但是,用户的网页搜索需求不完全是将时效性排在第一位,网页爬虫在抓取网页更新索引时对每个网站的更新周期不一样,等级高的网站被爬取的频次高,等级低的小型网站被爬取的频次低。因此,网页搜索结果不能按网页发布时间排序,用户普遍更关注的是相关度[6]。
Google等大型搜索引擎使用复杂的PageRank算法进行链接分析,递归地计算网络上的全部站点排名[7]。藏文网页搜索的规模较小,可以采取简单的策略。以检索词的匹配程度作为主列排序,以信息发布时间作为次列排序,按相关度从大到小排序,相关度相同的按更新日期从晚到早排序。
5 结论
互联网世界的藏文字符已经趋向于使用基于Unicode的字符集和基于utf-8编码的字体,这有利于人们更多地使用藏文进行交流。目前,Google搜索已经开发了针对藏文网页的搜索功能,国内多家单位也正在研发本地化的藏文网页搜索引擎。总体来讲,藏文网页搜索还处在探索阶段,究其原因,主要有三个方面:一是多年来藏文字符编码不统一,一些藏文软件还沿用着基于国家标准的藏文字体,不兼容当前国际标准编码;二是藏文网页/网站数量较少,用藏文记述的文献信息体量巨大,但目前“搬”上网的还很少;三是藏文与汉文的混排、混检技术还处于发展中,最直接的解决办法是平台上的藏文和汉文都使用基于Unicode的字符编码,但会额外增加大量的汉文字符存储开销和网络流量开销,这也是一些大型站点保持使用GBK的原因。目前针对藏文信息处理的研究有很多,我们期待将来藏文在互联网世界更广泛更灵活的应用。
参考文献(References):
[1] 谢玉开.基于JAX-RS的面向资源架构应用研究[D].浙江理
工大学硕士学位论文,2011.
[2] 范剑波.网络数据库技术及应用[M].西安电子科技大学出版
社,2004.
[3] 王娟,吴金鹏.网络爬虫的设计与实现[J].软件导刊,2012.4:
136-137
[4] 王沣.运用信息技术保护莽人语言文化的研究[J]. 科技情报
开发与经济,2014.11:144-145
[5] 普顿.移动电话上实现藏文信息处理的方法研究[D].西藏大
学硕士学位论文,2009.
[6] 吕月娥,李信利.基于信息类别的网页过滤算法[J].福建电脑,
2007.2:99,122
[7] 周浩.基于决策树的搜索引擎恶意网页检测研究与实现[D].
湖南大学硕士学位论文,2013.
- 以资质管理助推施工企业良性发展的研究
- 基于消费者满意的C2C网店营销策略分析
- 风险管理视角下中小企业内部控制相关问题探讨
- 供电企业电费管理的风险及应对措施
- 合肥燃气集团文明单位创建的实践及前瞻
- 企业经营管理工作的探索与实践
- 浅论新形势下我国国企档案管理的有效途径
- 在新形势下企业管理创新方案分析
- 基于全面风险管理的“一体化”监督机制构建
- 地铁运营企业物资采购规范化管理探析
- 新时期企业管理中沟通理论的有效应用探究
- 金隅股份并购冀东水泥动因及效果探析
- 互联网与企业管理创新
- 终端提升出新招?移动课堂进店堂
- 创业过程视角下创业能力对企业绩效的影响研究
- 基于全息技术的服装品牌全新营销模式初探
- 国企经营管理中电子商务的重要性
- 企业负债经营的风险及防范措施
- 探讨关于石化企业物资仓储管理规范化
- 加强国有企业战略管理的几点思考
- 基于新形势下的油田档案管理信息化建设
- 加强企业餐厅成本管理的思考
- 浅谈石油企业基层的自主管理途径与措施
- EDI技术在企业中的应用
- 基于完善企业集团内部控制制度的分析
- downloaded
- downloader
- downloading
- down-loading
- downloads
- down/low
- downmarket
- down-on
- down-payment
- downpayment
- down payment
- down-payments
- down payments
- downplay
- downplayed
- downplaying
- downplays
- downpour
- downpours
- nutritional
- nutritionalist
- nutritionally
- nutritionary
- nutritions
- nutritious
- 斗篷式的外套
- 斗米尺布
- 斗粟
- 斗粟尺布
- 斗粟尺帛
- 斗粮
- 斗精
- 斗紫吴干
- 斗纲
- 斗纷
- 斗纹
- 斗纽
- 斗经济
- 斗绝
- 斗绝一隅
- 斗罐
- 斗美夸丽
- 斗羽
- 斗而铸兵
- 斗而铸锥
- 斗耸
- 斗聚
- 斗胆
- 斗胆豪心
- 斗胆进言