

摘 要: 为了提高机器英语翻译的准确性和合理性,提出一种基于模糊语义最优解选取的机器英语翻译方法。构建机器英语翻译的信息抽取模型,建立机器英语翻译的模糊语义主题词属性表,采用灰色关联特征匹配方法计算英语翻译的语义相似度,实现英语翻译中前后文的语义模糊映射。建立语义映射关系,计算得到模糊语义最优解。实验测试结果表明,采用该方法进行机器英语翻译,语义信息的召回性能较好,主题词的特征匹配度较高。
关键词: 机器英语翻译; 语义选取; 语义模糊映射; 信息抽取
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2017)12?0031?03
Abstract: In order to improve the accuracy and rationality of English machine translation, a machine translation method based on semantic fuzzy optimal solution selection is proposed. An information extraction model and an attribute table of fuzzy semantic subject words are made for English machine translation. The semantic similarity of English translation is calculated with the grey correlation feature matching method to realize the semantic fuzzy mapping of semantic context in English translation. The semantic mapping relation is established. The fuzzy semantic optimal solution is obtained by means of calculation. The experimental results show that the proposed method has better recall performance of semantic information for the English machine translation, and high feature matching rate of subject words.
Keywords: English machine translation; semantic selection; semantic fuzzy mapping; information extraction
隨着智能翻译技术的发展,采用机器翻译进行英语翻译,逐渐取代人工翻译,且翻译的准确度不断提高和改进[1]。在采用机器软件进行英语翻译中,需要进行语义识别和特征分析,采用机器智能识别方法进行英语上下文和前后文的语义信息抽取,构建英语的英语信息模型,结合模糊语义识别技术提高英语翻译的智能化水平[2?3]。采用模糊语义最优解计算方法从语义上对英语翻译的内容进行合理性组织和内容创作,从主题内容上体现了原文创作者的主观性,提高英语翻译的智能化和自动化水平。为了提高机器英语翻译的智能化水平,本文提出一种基于模糊语义最优解选取的机器英语翻译方法,构建机器英语翻译的信息抽取模型,进行模糊语义最优解选取,得出有效性结论。
1 机器英语翻译的语义模型
1.1 机器英语翻译的自然语言处理
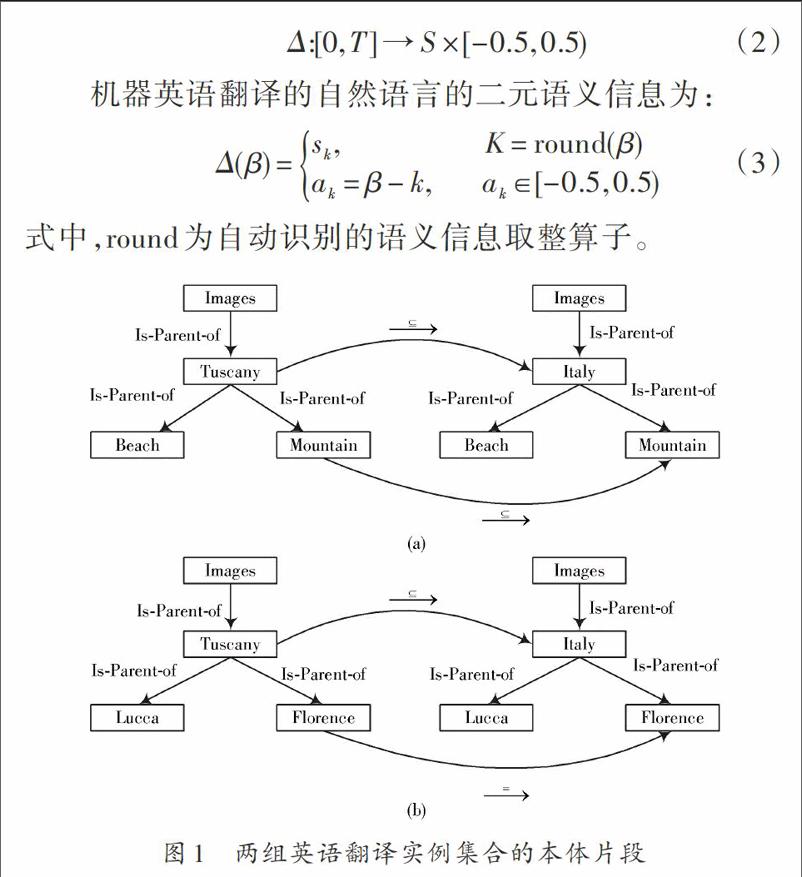
在构建机器英语翻译的语义模型[4]之前,首先考虑图1所示的两组英语翻译实例集合的本体片段。
以图1为例,进行机器英语翻译的自然语言处理,英语单词“image”可以表示一张图片,同义词“image”和“picture”具有模糊映射关系[5],英语翻译中同义词与语义信息相关的可能的语义映射关系描述为:
结合图1(a)机器英语翻译的自然语言处理中左侧的“Mountain”节点的两个标签,使用概念之间的泛化关系(Is?less_than)对自然语言的上下文进行处理和分析,改善机器语言翻译中的智能化水平。
1.2 机器英语翻译的语义本体映射模型建立分析
在上述进行了机器英语翻译的自然语言处理的基础上,针对不同本体的概念之间的目标(或对象、准则)进行模糊评价,分析领域知识中的最大语义相关度值符号集合,由二元组(sk,ak)来表示任意词汇Wi和Wj之间机器英语翻译的置信度。
定义2 设是一个语义修饰目标的二元特征组合,其中为集合S中第k个元素,,则在简单语义单元中存在英语翻译的定语修饰函数为:
假设和为两个二元语义,在进行机器英语翻译中,将定语从句划入到主句,在从句范围选择时得到一个关于二元语义的语法本体映射模型描述为:
(1) 在语义分析时,若,那么;
(2) 若,那么有:,则; ,则;,则。
2 模糊语义最优解选取实现
2.1 英语翻译的语义相似度计算
在上述构建了机器英语翻译的语义模型和进行自然语言信息抽取处理的基础上,进行模糊语义最优解选取方法改进设计,提高机器英语翻译的智能化水平,建立机器英语翻译的模糊语义主题词属性表如图2所示。
图2 模糊语义主题词属性表
在图2建立机器英语翻译的模糊语义主题词属性表中,采用灰色关联特征匹配方法计算英语翻译的语义相似度,设整个主题词表中的语义二元组和为任意直接上位词的英语翻译信息,对各分向量的欧氏距离为:
式中:。根据语义相似度计算结果,实现英语翻译中前后文的语义模糊映射,建立语义映射关系。
2.2 模糊语义最优解选取计算
在计算了语义相似度的基础上,根据前述建立的机器英语翻译的模糊语义主题词属性表,进行英语翻译过程中的主题词语义最佳匹配搜索,采用循环堆栈控制搜索方法进行模糊语义匹配控制,英语翻译的语义配准搜索的示意图如图3所示。
结合图3给出的英语机器翻译的语义搜索过程,对文档di进行英语翻译的综合权重的相似度计算,设是一组二元语义信息,设X,Y是两个待比较的词语,计算出词Y的语义抽取向量为, ,则二元语义加权算术平均算子φ2定义为:
式中:。
在英语翻译中,将一些常用的短语被划分为几个词语,根据词语在文本中的位置,计算出词Y在文本中的语义中心向量C(Y),则X,Y在英语翻译过程中的相似度为:
通过机器语言识别方法对英语翻译的用词进行特征过滤和位置标注,对各分向量进行标准化,得到机器英语翻译的前后文的语义模糊概念集R(X)的中心向量C(X),两个词语的可靠性翻译的联合特征概率密度为:
机器英语翻译中模糊语义最优解选择的实现伪代码算法描述为:
BEGIN
Word Formal t = NEW emantic fuzzy; //初始化短文档集合
grey correlation = NEW semantic topic;
//初始化向量空间及主题词(叙词)款目
Word = English translation (WordList); //语义信息抽取
WHILE(semantic context IS NOT NULL){
IF(Word emantic fuzzy optimal){
Word = feature matching (semantic information);
}
//若不在主题词表中,调整系数进行翻译的整体性搜索
ELSE{
Node = semantic information (reasonable);
//翻译合理性分析
Sim = matching calculation (Word, Node);
//语义相似度度量
Sim_List.put(lauygdbgfOf(Sfgr));
sefrhtje = lagthte(selhtjhtdNgthde);
//选择文本内容最大相似度值的翻译语义映射
}
Word.rfregvface(lf(Simregrfist).Nbtjuke); // 统计分词
Word = Nfrgvrrd(Wdefggfgrthgbtt);
}
END
3 实验测试分析
最后在Matlab仿真环境中进行实验分析,分析通过模糊语义最优解选取机器英语翻译的准确性和合理性建模的性能。实验中,采用标准度量指标:语义信息的召回率、主题词的特征匹配度为测量值,通过综合决策,采用10个本体实例进行英语机器翻译,得到不同阈值下的机器英语翻译的特征匹配度如图4所示,为了对比性能,采用不同方法得到机器英语翻译的信息召回率对比结果如图5所示。
分析上述仿真结果得知,本文方法进行机器英语翻译的语义特征匹配性能较好,调整阈值系数进行翻译的整体性和合理性修正,提高了英语翻译的准确度;本文方法进行机器英语翻译的召回率较高,说明英语翻译的上下文映射能力较强、翻译的整体质量较高。
4 结 语
针对传统的选取方法存在选取精度低的问题,提出基于模糊语义最优解选取的机器英语翻译方法,并进行了实验分析,结果表明,采用该方法进行机器英语翻译,语义信息的召回性能较好,主题词的特征匹配度较高,说明翻译的合理性和准确性较好。
参考文献
[1] 辛宇,杨静,汤楚蘅,等.基于局部语义聚类的语义重叠社区发现算法[J].计算机研究与发展,2015,52(7):1510?1521.
[2] 匡桂娟,曾国荪,熊焕亮.关注用户服务评价反馈的云资源再分配方法[J].计算机应用,2015,35(7):1837?1842.
[3] LI Chenliang, SUN Aixin, ANWITAMAN D. TSDW: two?stage WSD using Wikipedia [J]. Journal of the American Society for Information Science and Technology, 2013, 64(6): 1203?1223.
[4] 吴江,唐常杰,李太勇,等.基于语义规则的Web金融文本情感分析[J].计算机应用,2014,34(2):481?485.
[5] 邹亮,徐德智,郭维.基于参考点的大规模本体扩散映射算法[J].小型微型计算机系统,2013,34(7):1507?1513.
[6] 黄果,周竹荣.基于领域本体的概念语义相似度计算研究[J].计算机工程与设计,2007,28(10):2460?2463.
[7] 石倩,陈荣,鲁明羽.基于规则归纳的信息抽取系统实现[J].计算机工程与应用,2008,44(21):166?170.
[8] 粟千.弱化語法规则下英文机器翻译的优化仿真[J].计算机仿真,2016,33(11):414?417. 技术文
- “读·写·考”三维构建高中语文高效课堂
- 生本理念下高中语文高效课堂的构建
- 新课程标准下高中散文教学的有效性策略探究
- 高中体育“趣味、互动、竞争”课堂构建分析
- 高中化学课堂的结束模式构建
- 基于STEM教育模式的高中物理教学设计
- 数学课堂学生合作学习小组的组建策略
- 思维导图在高中数学教学中的应用
- 刍议高中历史导学案教学模式的应用
- 基于“翻转课堂”的高中历史教学活动探讨
- 问题引领式教学在高中政治教学中的运用探析
- 浅议问题引领式教学在高中政治教学中的运用
- 简析探究式学习在高中英语词汇教学中的应用
- 思维导图在高中英语教学中的运用分析
- 思维导图在英语书面表达中的实践研究
- 高中语文教学中的合作学习教学组织策略探析
- 关于高中音乐鉴赏教学的几点思考
- 新高考背景下化学分层教学走班教学思考
- 浅谈高中物理教学中的问题与解决方案
- 新形势下高中数学教学策略思考
- 高中数学教学中存在的问题及改进策略
- 高中数学课堂中探究性学习的思考
- 优化中学英语课教学导入的几点建议
- 浅谈高中学生英语书面表达存在的问题及解决策略
- 农村高中语文教学传承传统文化的实践思考
- oxbow
- oxbows
- oxen
- oxen's
- oxes
- oxidable
- oxidation
- oxide
- oxides
- oxidic
- oxidise
- oxidised
- oxidises
- oxidising
- oxidizabilities
- oxidizability
- oxidize
- oxidized
- oxidizement
- oxidizes
- oxidizing
- oxidizings
- oxids
- oxlike
- ox's
- 一…就…
- 一…而…
- 一、一般用语
- 一、丁、万、中、本、百、利、妾、孩、唐
- 一、为人
- 一、五、九月
- 一、任职(参与、调动)
- 一、企业生产文字工作常用概念
- 一、体育宣传常用概念
- 一、信件处理办法
- 一、借入
- 一、公共关系文体写作的基本知识
- 一、军事写作常用概念
- 一、受赠用语
- 一、古代汉语语法著作
- 一、向上级或尊长陈述
- 一、启程
- 一、品格
- 一、商品推销常识
- 一、因内容而得名
- 一、图书出版文字写作基础知识
- 一、天文气象
- 一、寿辰
- 一、常用轻声多义多音词
- 一、干求