基于LabVIEW的人民币冠字号识别系统研究
杨美程
摘要:系统的工作方式主要是对人民币采集图像,然后进行包括图像灰值化、滤波、倾斜校正及对冠字号目标区域提取的图像预处理,随后利用LabVIEW中Vision Assistant工具里的OCR功能对冠字号中出现的字符进行训练并建立模板数据库,与提取出的冠字号区域进行匹配从而识别出字符并转换成文本。系统用户操作界面简洁,具有較高的识别准确率及速度。
关键词:LabVIEW;字符识别;匹配;冠字号
人民币纸币上的冠字号具有唯一性,对人民币冠字号进行识别并统一管理可以用于人民币的真伪鉴别,从而在某种程度上有效打击伪钞犯罪。如今,在人民币冠字号识别技术领域存在着神经网络、二值化法及模板匹配等识别技术,人们大都利用这些技术基于visual C++或MATLAB平台进行研究,设计出的系统具有一定的稳定性及准确率,但是过程大都比较复杂,对于用户来说操作不是很方便。为此本文基于LabVIEW图形化编程语言及其可视化用户操作界面的特点,研究了一种人民币冠字号识别系统,以另一个编程开发平台的角度为进一步研制国产纸币冠字号识别机提供参考。
1.图像采集及预处理
1.1图像采集
采用高清工业相机对放置的人民币纸币进行拍照,在拍摄图像时要注意图像不要因为镜头而畸变,将相机对准与纸币垂直的位置,避免相机获取的图像带有角度而产生透视误差。同时还要注意光照能够提供被检测纸币与背景之间有足够的对比度,以便从图像中获取信息,使图像采集过程中保证图像的质量。
1.2图像预处理
1.2.1图像灰值化
采集到彩色图像后需要进行灰值化处理,本文利用视觉与运动选板中的IMAQ Create控件进行灰值化,使用此控件时将其图像类型接线端连接常量为Grayscale(u8),则控件输出端即可得出灰度图像。
1.2.2图像滤波
图像滤波常使用快速傅里叶变换将图像变换到复频域,然后利用工作在复频域的算法除去图像中不期望的频率达到滤波的效果。在LabVIEW中常使用IMAQ FFT模块将图像变换到复频域,形成代表图像的频率信息的复数图像。然后使用IMAQ Complex Attenuate选择低通或高通频域滤波器在频域改善图像。
1.2.3图像倾斜校正
拍摄图像时图像会出现倾斜的情况,要进行图像倾斜校正。首先找出倾斜图像边缘像素点连成的基线,基线的方向角大小即对应图像的倾斜角大小,通过像素遍历的方法找出这些特征点并将坐标值存储在数组中,然后通过最小二乘法将这些数组中的数据拟合成直线并得到斜率即可求出角度,以此便可以将图像进行校正。
在LabVIEW中利用IMAQ Get Row-col函数可得到图像一行或一列的像素值,并通过构建for嵌套循环遍历像素,将循环结果不为0的像素点对应i值索引出来,此值即为该像素点的坐标值。随后利用IMAQ Line Fit函数进行线性拟合,推导出图像倾斜的角度,最后使用IMAQ Rotate函数进行图像的旋转校正。
1.3冠字号目标区域提取
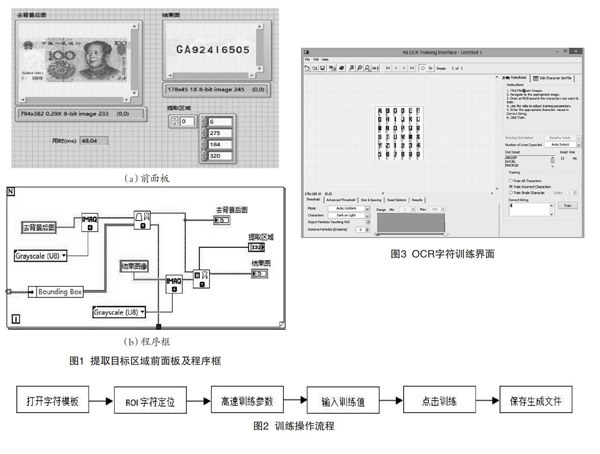
旋转校正后的图像其背景为纯黑色灰度值为0,而其余部分灰度值都大于0,由此设定阈值将背景除去得到完整的纸币图像。由于冠字号字符区域相对于整张纸币来说其相对位置固定,因此可以使用IMAQ Extract函数实现对目标区域的提取。在Optional Rectangle接线端创建提取区域输入控件。提取目标区域的基本思想为以图像左上端顶点为原点,其余像素点相对于原点的位置为其坐标点,由于目标区域位置相对固定,因此可通过提取区域输入控件创建一个最合适的裁剪矩形框选中目标区域,而矩形框是通过其左上端顶点及右下端顶点确定的,因此要在前面板的提取区域数组中分别输入两个顶点的横坐标与纵坐标。确定了裁剪的矩形框,运行程序后便能将目标区域提取出来。图1为提取目标区域前面板及程序框图,其中图1(a)前面板中显示了提取目标区域前后的图像,图1(b)则为该步骤的程序框图。值图像,因此必须先对图像灰值化处理才能够在该平台下操作,可以调用LabVIEW IMAQ函数库中的IMAQ Extract Single Color Plane函数进行图像灰度化处理保存。
在需要被训练的字符周围选中一个ROI区域,选中区域后OCR能够根据字符大致轮廓特征对字符进行自动分割并根据字符的长宽大小用红色矩形框将字符选中定位,对于易分辨的字符可以进行连续选中,对不易分辨的字符进行单独选中训练。
在参数设置区域可以对字符设置高速训练参数,如设置灰度级范围、移除微粒、样条运算等。
对字符选中ROI区域时,Text Read文本框中会显示?符号表示待训练,此时需要在Correct String文本框中输入正确的训练值。
点击Train便自动完成对字符进行训练,Text Read文本框中也会显示训练的结果,右侧会提示完成训练所需时间。
对所有的字符完成训练后需要保存为ABC文件类型以供程序调用。图3为利用NI OCR对字符模板完成训练的界面。
2.冠字号字符识别
2.1字符训练
2.1.1OCR功能实现
本文中字符训练是在NI视觉核心工具包VDMY的视觉协助(Vision Assistant,VA)平台下进行的。由于人民币冠字号字符由固定的26个英文字母和10个阿拉伯数字共36个字符组成,这些字符的特征完全固定,因此可以使用OCR技术实现冠字号的识别。NI VA中的OCR技术采用模式识别算法分析字符形态特征。首先根据模板字符外部轮廓如对称、拐点的特征对不同字符进行初步的学习,然后由字符像素灰度级相对背景不同确定字符像素的大致分布及疏密情况进行深度的学习,对于一些难以区分的字符,在VA平台上可以通过对这些字符进行单独的搜索模式、长宽依赖比等设置来进行区分。对模板字符训练后再将需要识别的字符进行自动模式识别,找出特征量最为接近的结果。
2.1.2字符训练过程
利用NI VA平台下的OCR功能完成对字符的训练构成模板,其主要操作步骤流程如图2所示。
2.2冠字號字符识别
字符识别过程主要是调用模板文件进行匹配过程。LabVIEW中首先调用IMAQ Crate函数为提取出的冠字号区域图像设立暂存空间,调用IMAQ OCR Create Session函数给OCR创建会话。然后调用文件对话框函数为用户创建打开字符识别模板文件路径的对话框,同时调用文件对话框函数为用户创建打开图像文件选择路径并确定格式的对话框,供用户选择图片。再使用IMAQ OCR Read Text函数进行模板文件及冠字号图像字符的匹配并识别出结果,并设置时间计数器来计算识别所需的时间。
LabVIEw是基于图形化编程的语言,可用来方便地创建用户界面,用户界面在LabVIEW中也被称为前面板,用户可通过操作前面板形象化的控件简便地完成相应的处理。
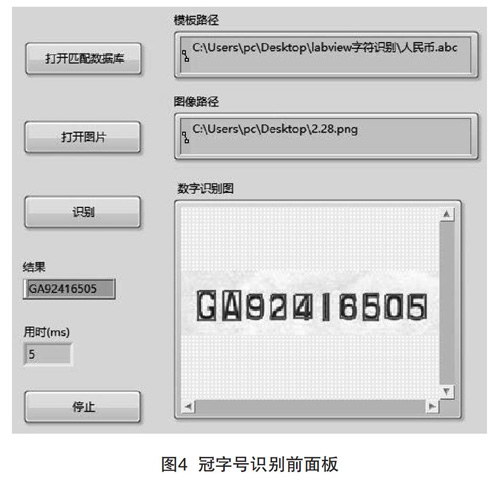
图4为进行冠字号识别供用户操作的前面板。用户运行程序后,点击打开数据匹配库控件,会弹出请用户选择模板ABC文件路径的对话框,用户选定文件后,模板路径控件会立即显示用户所选择的模板路径;点击打开图片控件后,也会弹出请用户选择图像路径的对话框,用户选定后,图像路径控件则会立即显示用户所选择的图像路径,并且在下方显示所选择的图像。最后点击识别控件,程序立即进行字符的匹配过程,并第一时间将识别结果及用时显示出来。
3.实验结果
本实验中选取了30张百元人民币纸币作为样本进行实验,将这些样本进行灰度化、滤波、倾斜校正及目标提取后产生了30张含冠字号字符待识别区域的图像。这30张图像中一共有300个字符,其中大写英文字母字符60个,数字字符240个。将这些图像分别与模板进行匹配识别,结果为纸币整体识别成功率为93.3%,其中字母识别成功率为98.3%,数字识别成功率为98.8%,识别过程平均用时7 ms,字符识别错误的原因大致为某些纸币存在老旧或破损、褶皱的情况,导致字符本身不完整或者不清晰使识别过程出现了不匹配的情况。
4.结语
本文在是LabVIEW开发环境下对人民币冠字号字符进行识别研究的,设计了一种用户操作简洁,准确率较高,识别速度进一步提升的人民币冠字号识别系统。相关研究不仅可以用于冠字号的识别,还可以用于产品序列号检测、智能化仪表等领域。但是根据本文的实验结果表明,本系统虽然能够识别大多数字符,但依然存在着某些纸币上的冠字号字符识别错误的情况,因此需要进一步的改善,使得系统在纸币本身条件不佳的情况下也能够对冠字号字符做准确的识别,提高系统的性能。
