数据压缩问题
李晓明


在以数字化和网络化为技术标志的信息化社會,数据越来越多,单个数据体的规模越来越大。30年前,谈到数据文件的大小,人们主要谈KB;20年前,MB流行起来;10年前,GB已进入日常视野;现在,TB也不是望尘莫及。
与应用数据规模日益扩大相生相伴的是存储技术和通信技术的改进。在它们之间缓冲的,则是数据压缩技术。日常人们接触多的,当数各种文件压缩工具软件了。每个文件压缩软件背后都是某种压缩技术,常常是基于某种公开的规则。文献【1】是关于这方面的一本相当全面的参考书。
数据压缩的目的,是要用较小的空间(数据量),准确或近似地表达原本在一个较大空间里表达的信息。各种压缩技术中的规则从本质上讲都是算法。它们将输入数据,变换为规模较小的输出数据(如图1)。无损压缩,意味着可以从结果中完整恢复原始数据,如文本的压缩。有损压缩,则允许原始信息在结果中有所丢失,当然应该在可以接受的范围内,如图像或视频的压缩。本文只讨论无损压缩。
数据是信息的表达或编码。一个数据可以被压缩,一定是它表达所蕴含信息的效率不够高,或者说有冗余。本文讨论文本数据的压缩,所谓文本数据,即有一个预先知道的有限字符集C,任何文本T都是由该字符集中的字符构成的字符串,可能很长很长。压缩的对象是T,但可以运用C的知识(如其中有多少个字符)。例如本篇文章,除去插图,就是一个字符串(T),它其中的字符源于一个包含汉字、英文字母、标点符号、空格、换行等字符的字符集(C)。
数据压缩概念的出现及其实践,至少已有500年历史,文献【1】中有相关介绍。由于数据压缩既有实用性,也呈现出引人入胜的智力挑战,几百年来不断有人尝试新的思路。有些思路简单奇妙,开脑洞。文献【1】中有下面这样一个例子:
设字符集C有40个字符(别看很少,但已经相当实用了,如可包含26个英文字母、10个数字、3个标点和1个空格)。在不考虑压缩的情况下,常规就是每个字符用1个字节编码。如果注意到403=64000<65536=216,会发现有机会了:对于任何字符串T,总是可以将它的字符按顺序三个三个一组,那么全部可能有403<216种。于是我们可以用2个字节,即16位,给这种“三元组”完整编码。也就是说,本来需要3个字节表示的信息,现在用2个就够了,于是压缩比为3/2=1.5,而且与T的具体内容无关。是不是相当不错?
现在人们谈计算思维,计算思维有一个特征叫“系统观”(或系统思维),它对有效理解一些具体技术很有帮助,有些类似于树木和森林的关系。有了这种观念,在理解林林总总数据压缩算法细节的时候就不会迷失方向。下页图2是理解数据压缩问题的一种系统观。理解一个算法为什么能有效工作,与对这样一个“系统”的理解直接相关。例如,其中的“相关知识”指的是什么?它为什么既和编码有关,也和解码有关?从上面讨论的例子来看,它至少要包括字符集C,以及2个字节与3个连续字符的对应关系。一般地,就是要有字符集和“码表”(code book)。就这一点而言,是不是和本专栏上一期介绍的加密解密算法有相似之处?
前面例子的一个重要特点是它的压缩比是固定的(1.5)。好处就是它提供了一个保证,无论什么文本,都会是这个样子。不尽如人意之处就是它没有利用文本自身可能对压缩有帮助的特点。例如,叠字联:“重重喜事,重重喜,喜年年获丰收;盈盈笑语,盈盈笑,笑频频传捷报。”32个字,我们能感到某种“冗余”。其中有些字(符号)多次用到,有些则只用了一次。如果按照每字符1字节编码,需要32字节=256位,若按照前面例子中的算法编码,这里是11组,于是需要22字节=176位。下面我们将看到,作为本文介绍的重点——哈夫曼编码算法,充分利用文本自身的特点,对这个例子能给出如表1所示的压缩编码结果,总共只需4*3+4*3+4*3+3*3+3*4+2*4+2*4+10*5=123位。
哈夫曼编码是David A. Huffman于1952年发明的一种无损编码方法,当时他还是MIT的一个学生。观察表1中第三行的编码数据,我们能看到不同字符用到的位数有所不同,这种方式称为可变字长编码,与前面讨论的例子不一样。即便是那种用2个字节表示3个字符的方式,也可以看成是固定字长的。
该方法的思想很自然,它依据符号在文本(T)中出现的概率(频率)来编码,让概率较高的编码较短,概率较低的编码较长,以期获得最短的平均编码长度。下面来看,给定一个文本T,如何生成其中符号的哈夫曼编码的算法。为方便起见,我会用一个比上述叠字联更小一些的例子来解释其过程。
一般而言,给定文本T,先要对它做一个扫描,统计其中每个符号出现的频次。这个过程很简单,用哈希表来做这件事,时间效率相对于T的长度就是线性的。哈夫曼编码算法,则是基于上述过程的结果展开的。
● 问题
给定字符集合C={C1,C2,…,Cn}和对应出现的频次f={f1,f2,…,fn},要将C中的字符编码,使得总码长尽量短,即若以Li表示Ci的编码长度,追求∑fi*Li的极小化。
例如,文本串“SHA HGH SHS HSH HAA”中一共有19个字符(空格也是字符)。若用ASCII码,每个字符1字节,整个码长就是19*8=152(位)。有办法提供一种不同的编码,缩短总码长吗?
● 算法基本思路
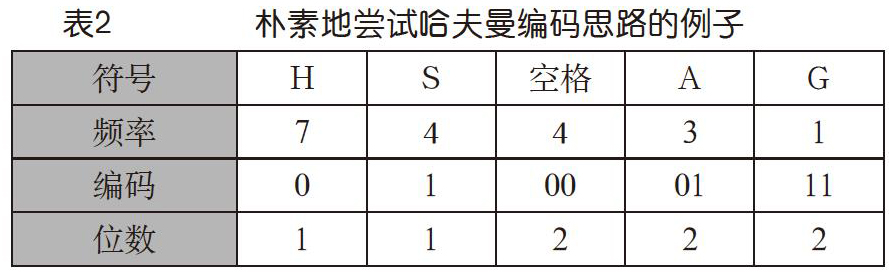
前面已经提到,哈夫曼编码的基本思想是让出现频率高的用较短的码,低的用较长的码。从而希望能减小∑fi*Li。对上面这个例子而言,有5种不同的字符,S出现4次,H出现7次,A出现3次,G出现1次,空格出现4次,可得字符频度对应表如表2头两行所示。不妨让我们来立刻尝试应用一下这种基本思路,给出表2第三行所示编码。
没错,每个符号对应一个唯一的编码,于是上面例子的总码长就是:
7*1+4*1+4*2+3*2+1*2=27
这可比按照ASCII编码的152位省多了。即便我们不用ASCII编码,对这5个符号用3位定长编码,总码长也需要19*3=57,比27大不少。但是,细心的读者马上会意识到一个问题!按照这个编码,那个文本“SHA HGH SHS HSH HAA”的编码就是:
100100011000101000100000101
回顾图2所示的系统观,如果其中的“相关知识”就是表2第一和第三行给出的码表,你能从这个0/1串中解码出“SHA HGH SHS HSH HAA”吗?你会说,那第一个1不就代表S吗?可是,后面连着的两个0到底是代表两个H还是代表一个空格呢?这真的是没法回答。
这就出现了所谓“前缀码”问题,即有些字符的编码是其他字符编码的前面一部分(前缀),如H的编码0就是空格编码00的前缀。这样的编码,单个看没问题,放在一起就有问题了,解码就有二义性,是不能接受的。这是不定长编码必须克服的一个基本问题。所给出的码字,不能出現一个是另一个前缀的情况。因此,我们上面的朴素尝试失败了,下面看哈夫曼编码是怎么做的。
给定字符集合和频数集合,哈夫曼编码的过程可以形象地看成是自底向上建立一棵二叉树的过程。每个叶节点对应一个待编码的字符,该二叉树的每一条边用0或1标记。一旦这棵树建立完成,叶节点(也就是字符)的编码就是从根到达它的每一条边上标记的序列。这样,一个叶节点离根越远,它的码字就越长。因此,建树过程是哈夫曼编码算法的核心,如下所述。
从字符频数集合f={f1,f2,…,fn}开始,不妨想象它们是某一棵二叉树的n个叶节点,每一次取其中两个最小的——fi和fj,向上形成二叉树的一个“内部节点”,命名为fij,让它也有一个频数fij=fi+fj,放到f中,同时从f中去掉fi和fj。如此这般继续考察f,不断形成新的内部节点,可以由两个叶节点、两个内部节点或一个叶节点和一个内部节点产生,这完全取决于f中元素的频率值,直到最后剩两个元素,构成树根。在这个过程中,不难想象每次都有两条向上的边,将它们一个标记为0,另一个标记为1。
● 算法的描述
为了强调二叉树建立的意象,在图3所示的算法描述中引入了“节点”(node)的概念,将它看成是一种抽象数据,包括node.value,node.left和node.right几个要素。哈夫曼树,就是由若干相互关联的节点构成的集合,记为H。这样,图3描述的算法就离程序实现很近了。
树建好之后,就可以来生成每个字符的编码了。从根节点开始,采用数据结构课上学过的深度优先搜索即得。例如,约定从一个节点到左子节点的边的标号为0,往右子节点的为1,按序记住搜索路径边上的编号,每到达一个叶节点就相当于完成了一个字符的编码。
● 算法运行例子
我们用表2的例子,“SHA HGH SHS HSH HAA”,根据表中头两行符号与频次的对应关系,运行上述算法,得到的哈夫曼树如图4所示。
基于该树,得到每个符号的哈夫曼编码(码表)如表3所示。按照这样的编码,“SHA HGH SHS HSH HAA”就是:
101100101110001101101110011110110111001001
其长度=7*2+4*2+4*2+3*3+1*3=42,比前面那个有问题的27要长不少,但与最节省的3位等长码相比也要好不少(42/57≈73.7%)。现在你要想的是,如果给你这样一长串码和表3前两行所示码表,你能准确无误地给出(解码出)“SHA HGH SHS HSH HAA”吗?
● 算法性质的分析与讨论
这是一个正确的算法吗?看建树过程,那个while循环为什么能够结束?假设n≥2,那么开始总能在f中找到两个元素,使循环的第一轮进行下去。我们看到,每一轮循环,在第13、14行,f都是增加一个元素,减少两个元素,即净减少一个元素,做了n-1次后,其中就剩下一个元素了,循环不再执行,程序结束。也就是说,恰好执行n-1次,创建了n-1个非叶节点(这与满二叉树的性质是相符的,即n个叶节点的满二叉树有n-1个非叶节点)。最终在H里面就有2n-1个节点。循环中新节点的创建部分让我们看到那些节点之间的关系是满二叉树。
取决于具体实现细节,得到的哈夫曼编码可能不唯一,但其∑fi*Li是一样的,而且都有高频字符编码不长于低频字符编码的性质。也就是说,对同一个字符串T,不同的人对其中的符号做哈夫曼编码,给出的码表可能是不同的(从而对T的编码也就不同),但都是正确的!例如,表4也是一个对我们例子中的符号进行哈夫曼编码得到的码表。
此时,“SHA HGH SHS HSH HAA”的编码就变成(长度还是42):
011011100101101000011001001001100010111111
我们还需要问哈夫曼编码为什么是无前缀码。这从哈夫曼编码树的定义及编码生成的过程容易看到。首先,由于二叉树的节点有层次,以及每个节点两个分支上的标记不同,每一个叶节点的编码就是唯一的。由于编码都是针对叶节点的,于是从根节点到一个叶节点的路径就不可能另一条路径的前缀。即一个字符的编码不可能是另一个的前缀。正确性的另一方面是问如此产生的编码是否最优?即在无前缀码的条件下,∑fi*Li是否不可能更小。结论是肯定的,证明超出了本文范畴。有兴趣的读者可参阅文献【2】。
这个算法的效率如何呢?在建树部分,基本就是一个两重循环。外循环执行n-1次,内循环就是在f中找两个最小的元素。于是可以说复杂性为O(n2)①。在码字生成部分,深度优先遍历一棵有n个叶节点的二叉树,复杂性为O(n)②。这里,也可以请读者考虑,如果在生成哈夫曼树的过程中保留适当的信息,一旦完成,就可以直接输出码表,后面这个码字生成的步骤就可以省去了。这样的做法在本栏目前面的文章中曾多次用到,是算法设计的一种技巧。
另外,前面提到应用哈夫曼编码还有一项前期预处理工作,即对原始数据(字符串)进行扫描,得到字符集C和频次集f,其时间消耗与原始数据量(T的长度)成正比。
从上面的讨论中,读者可能得到了哈夫曼编码“很好”的印象。的确,哈夫曼编码有很好的性能(编码长度和算法效率都很好),也应用在许多实际软件中(如zip)。我们能否也看到一點“缺点”呢?此时,值得回到图2所示的系统观。假设有A和B两个人,A总会有一些文本发送给B,他们决定采用数据压缩的方式,A将文件压缩,发送给B,B解压后得以看到原文。如果采用哈夫曼编码,每次A发给B的,除了压缩后的文件,还要有类似于表3或表4前面两行那样的码表。这是因为,按照我们描述的算法,输入是字符出现的频次表,那是取决于具体文本的。这意味着,同样的字符,在文本T1和T2中对应的编码很可能不一样!于是,B为了能够解压,既需要有压缩后的文本,也需要有与该文本相适应的码表(对应图2中的“相关知识”)。由于码表本身也要占存储占带宽,若T不足够大,综合起来就不一定合适了。这种情况在最开始提到的那个例子中就不会出现。在那里,B只要最开始收到一次码表就可以了,今后用的都是相同的。
在实践中应对这样一种状况的方法是假设人们生成的文件中有各种各样的内容,但用字的频率分布是基本稳定的(大量统计表明的确也是)。于是就可以一次性确定字频表,生成哈夫曼编码,用于后面所有文件的压缩。这样,哈夫曼树只需要构建一次生成一个码表,而接收方也就不用每次都需要接收新的码表了。可以想到,这里的代价就是损失一些压缩比。
注释:①利用先进的数据结构实现频数集合f,便于查找其中两个最小的数,能做到O(nlogn)。
②对于一般的图,深度优先搜索的复杂度是O(n+m),其中n为节点数,m为边数。这里因为是二叉树,m=n-1,因而就是O(n)了。
参考文献:
[1]David Salomon.Data Compression(The Complete Reference),4th ed[M].Berlin:Springer,2007.
[2]王晓东.算法设计与分析(第3版)[M].北京:清华大学出版社,2014,11.
注:作者系北京大学计算机系原系主任。
