漫谈大数据时代的数据架构设计
金琦 刘宗凡 邱元阳 倪俊杰 杨磊 邵建勋

编者按:在大数据技术的帮助下,一个全新的世界正向我们敞开大门,随着形态各异的数据的日益增多,大数据管理成为大数据发展中的一大挑战。上期我们对大数据及其代表处理架构Hadoop做了技术流介绍,本期各位老师将解构数据领域(数据仓库、数据湖、数据中台)相关概念,引导读者能据此有的放矢地构建自己的大数据体系观。
金琦:在上一期中,我们对大数据的基本概念和大数据处理的代表框架Hadoop进行了介绍。Hadoop分布式文件系统(HDFS)是大数据技术典型代表。这个开源软件框架的设计初衷就是解决在分布计算集群中的存储和处理大量数据集的难题。随着大数据的蓬勃发展,数据管理工具得到了飞速的发展,相关概念如雨后春笋一般应运而生,如数据仓库、数据湖、数据中台等,这些概念特别容易混淆,本期对这些名词术语及内涵进行系统的解析,便于读者对数据平台相关概念有全面的认识。
数据仓库
刘宗凡:包括教育在内众多机构的数据建设经历了分散建设、主数据集中和大数据平台多个阶段,大数据重在挖掘,提到数据挖掘不能不谈数据库和数据仓库。数据库主要是针对事务的,数据仓库主要是针对主题。例如,露天市场与超市都在卖菜,它们的区别是市场里摊主自己卖菜,所以他会把青菜、萝卜、冬瓜等放在一起销售。换个角度说,市场里的蔬菜相当于计算机里的数据,摊主相当于应用程序,蔬菜按照摊主的要求归堆,就相当于数据按照应用程序即事务去处理。但在超市里,青菜、萝卜、冬瓜各自在一块,也就相当于超市里蔬菜是按照同一类型放在一起的,这里的同一类型就相当于软件里的主题。
邱元阳:刘老师的比喻很形象,我们再来谈一下两者的特性吧,首先数据仓库具有时间属性,因为出于决策的需要,仓库中的数据必须表明它是什么时间建立的,但数据库保存信息的时候并不强调一定有时间信息。此外,数据仓库的另一个特性是不可修改。数据仓库中的数据来源于历史数据,所以其中的数据不一定是最新的,而数据库中的数据都是日常事务,是时时更新的。例如,我们查询的当月话费都是实时数据,这个数据库是可以变化的,但电信服务器中存储大量客户信息以及他们过去时段所用的话费就是历史数据,从这些历史数据中我们可能会向分析师提供哪些是优质客户,哪些是大型客户,这时库里的数据就不可更改了。数据仓库里的数据是过去的,数据库里的数据是实时的,数据库是为了捕获数据,数据仓库是为了分析数据。
倪俊杰:我们再对数据仓库进行技术性描述,数据仓库使用ETL(Extraction,提取;Transform,转换;Load,加载)过程来摄取新数据,在将数据加载至数据仓库前,需要使用预定义好的模组(Schema)将其结构化处理(或称建模),即所谓的“写入时建模”(Schema-on-Write),使用时再根据特定需求进行结构化处理,即所谓的“读出时建模”(Schema-on-Read)。上期我们讲的Hadoop上就包含Hive这一数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce的开发者开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
杨磊:就教育系统而言,《国家教育管理信息系统建设总体方案》指出国家教育管理信息系统建设要以“两级建设、五级应用”体系为重点,其中的“两级建设”指国家级和省级两级云数据中心。在智慧教育生态系统中,这两级数据中心(Data Center)分别部署于教育公有云和区域混合云中。着眼于省级以下的各级自制系统管理发展水平不一,两级数据中心是各自治系统互联互通的外部接口,它对各级自治系统传来的数据进行数据规整和数据清洗等处理,将数据转换为统一的或合乎某一特定系统的标准格式,以便为各自治系统提供数据服务。而私有云配备数据仓库是面向主题的、单一的、完整的、一致的数据存储。数据仓库中的数据来源于本地架构根据开放政策或协议公开的数据,同一数据一次、一处进入私有云(保证数据的准确性、及时性和完整性),其数据结构和存储方式与系统具体功能或数据流无关(保证数据的共享性)。这样的设计为各自治系统从两两互相调用的耦合向数据松耦合转变创造了基础条件。在基于数据中心的松耦合中,所有自治系统的简单关联均通过数据中心实现,目前比较典型的是用东方通中间件来完成各级系统的数据共享交换和协同运作。
数据中台
金琦:随着技术的进步,特别是存储硬件价格的下降与分布式计算的发展,数据仓库得到了广泛的应用,但数据仓库也遇到了一些問题,大家也可以对此探讨一下。
邵建勋:是的。例如,数据实时性问题:由于数据仓库是基于历史数据的,它无法满足现代机构管理需求,原来数据仓库基于历史数据设计主要是为了提高查询效率,但是现代的硬件技术与分布式计算早已提供了更好的解决方法。数据共享问题:数据仓库以主题方式组织数据,如学校就有不同主题诸如教师管理、学生管理、资源管理数据,就使得在解决数据孤岛的问题上又形成了一个个“数据烟囱”,各部门在使用数据时,仍然会面临数据不一致的问题,且数据仓库与业务之间高度耦合,也使得数据仓库难以维护,修改起来工作量巨大,跟不上管理变革。数据分析对业务的支撑不足:由于数据分析是基于历史数据的分析,而业务是实时的,所以两者之间存在一定的时间差,导致数据分析只能起到对业务的“支撑”作用,而无法起到对业务的“驱动”作用。
刘宗凡:为了解决这些问题,阿里提出了“数据中台”概念,现在这个概念已经被很多机构所接受,“中台”这个概念,是相对于前台和后台而生,是前台和后台的链接点,将业务共同的工具和技术予以沉淀。同时,以Hadoop等分布式技术和组件为核心的“计算和存储混搭”的数据处理架构,能够支持批量和实时的数据加载以及灵活的业务需求。另外,数据的预处理流程正在从前面提及的ETL结构向ELT(Extraction,提取;Load,加载;Transform,转换)结构转变。传统的数据仓库集成处理架构是ETL结构,这是构建数据仓库的重要一环,即用户从数据源抽取出所需的数据,经过数据清洗,将数据加载到数据仓库中去。而大数据背景下的架构体系是ELT结构,其根据上层的应用需求,随时从数据中台中抽取想要的原始数据进行建模分析。
邱元阳:好的,这时我们可以给出数据中台的定义,即通过机构内外部多源异构的数据采集、治理、建模、分析、应用,使数据对内优化管理提高业务,对外可以数据合作价值释放,成为机构数据资产管理中枢。数据中台建立后,会形成数据API,为机构和客户提供高效的数据服务。数据中台整体技术架构上采用云计算架构模式,将数据资源、计算资源、存储资源充分云化,通过多租户技术进行资源打包整合,并进行开放,为用户提供“一站式”数据服务。利用大数据技术,对海量数据进行统一采集、计算、存储,并使用统一的数据规范进行管理,将机构内部所有数据统一处理形成标准化数据,挖掘出对机构最有价值的数据,构建机构数据资产库,提供一致的、高可用的大数据服务。数据中台不是一套软件,也不是一个信息系统,而是一系列数据组件的集合,机构基于自身的信息化建设基础、数据基础以及业务特点对数据中台的能力进行定义,基于能力定义利用数据组件搭建自己的数据中台,其架构如上页图1所示。
倪俊杰:我来说一说数据中台带来的价值。数据中台对一个单位的数字化转型和可持续发展起着至关重要的作用。数据中台为解耦而生,为单位建设数据中台的最大意义就是应用与数据解耦,这样单位就可以不受限制地按需构建满足业务需求的数据应用。数据中台构建了开放、灵活、可扩展的机构级统一数据管理和分析平台,将机构内、外部数据随需关联,打破了数据的系统界限;利用大数据智能分析、数据可视化等技术,实现了数据共享、日常报表自动生成、快速和智能分析,满足集团总部和各分子公司各级数据分析应用需求;深度挖掘数据价值,助力机构数字化转型落地;实现了数据的目录、模型、标准、认责、安全、可视化、共享等管理,实现数据集中存储、处理、分类与管理,建立大数据分析工具库、算法服务库,实现报表生成自动化、数据分析敏捷化、数据挖掘可视化,实现数据质量评估、落地管理流程。
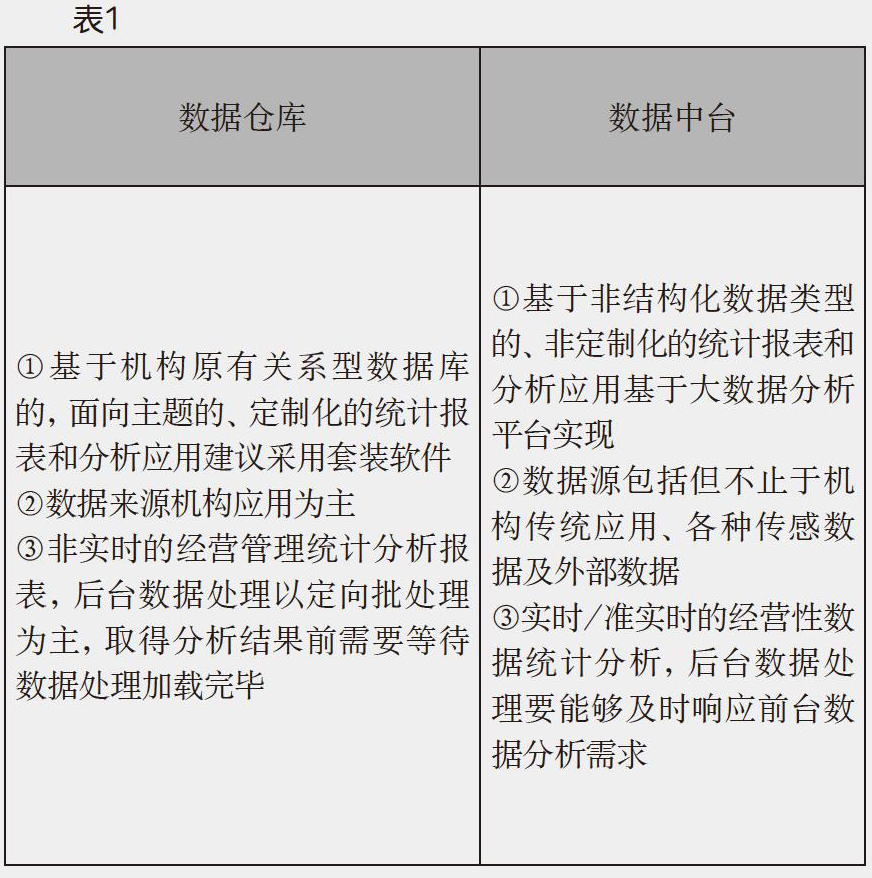
杨磊:我来列个表做个总结,同时也可以看一下数据仓库与数据中台的差异点(如表1)。
数据湖
金琦:数据仓库得到了广泛的应用,但随着技术的进步,建设大数据平台为平台上其他应用需要提供通用的数据存储服务,需要支持存储用户数据、业务数据、元数据、预测分析结果等传统关系型数据和日志数据、图片视频、影像数据等非结构化或半结构化数据。许多机构开始面临储存大量不同形态数据的问题。这里我有两个疑问:所有的数据都会进入数据中台吗?目前看来“没用”的数据是否真的没有用处呢?
邵建勋:一般遵循有用的数据才会进入数据中台,同时会为进入数据中台的数据完成模型定义。但有用无用依赖的是业务人员的经验判断,这明显不符合大数据的价值发现原则,大数据方法希望尽可能摄取各种来源的“粗数据”,甚至暂时不知其用途,也得收藏起来,而这些需求传统的架构可能无法负荷,由此诞生了“数据湖”。数据湖的概念最初是由大数据厂商提出的,是一种数据存储的理念,相较于将数据以数据仓库模式储存,数据湖被广泛视为大数据快速演进的下一步。其最主要的特点有两个:数据是以原始格式存储,不同于数据中台的结构化存储方式;数据湖以自然格式存储数据,数据不需要提前进行定义,在准备使用数据时,再定义即可,提高了灵活性与可扩展性。
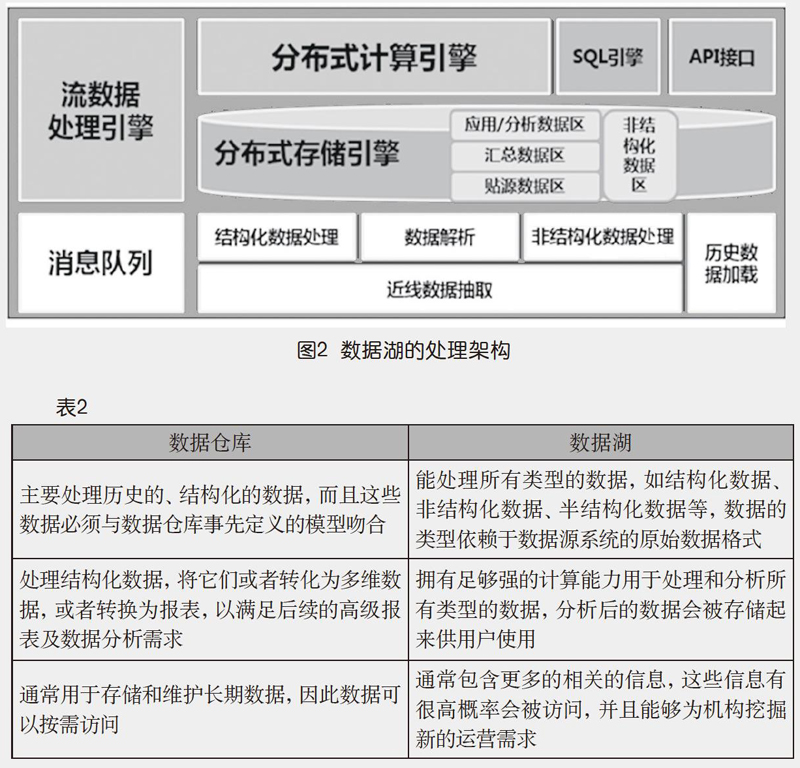
刘宗凡:一般数据湖架构有别于传统的数据仓库,传统的数据仓库的数据通常是品质较高且预先处理过的数据;而数据湖架构的设计是可撷取大量的、各种类型的数据作为数据素材的储存管理,以便于分析应用。因为数据湖架构范围更广、在数据分析上拥有更多弹性,所以它很适合作为导入巨量数据分析应用的架构蓝图。数据湖数据可包含各式的大规模并行处理数据库、内存数据库及HDFS分散式储存数据库,各种来源、各类型的数据在数据湖经由不同方式的储存、处理、净化、管理后,有弹性地产出各种分析数据。不同的是,数据湖可同时包含“未被清理的数据”,保持其最原始的形式,故分析者可取得最原始模式的数据,以减少资源上处理数据的必要,让来自各机关的数据来源更易于结合。数据湖主要有四点特性:以低成本保存巨量数据、维持数据高度真实性、数据易取得及数据分析富有弹性。最常用的部署数据湖的技术就是我们之前讲的Hadoop技术,而数据湖作为第二数据平面最重要的数据平台,与Hadoop技术的融合越来越紧密,相辅相成。例如,HBase可以让数据湖存储海量数据;基于内存处理数据的Spark(上期我们讲过通过磁盘处理数据的MapReduce)使得数据湖可以更快地批量计算和分析海量数据;Storm、Flink、NiFi等使數据湖能够实时接入和处理物联传感数据。Hadoop本身更多地聚焦于数据的处理与应用,但是对于底层的数据存储工作并未过多地关注。例如,传统的Hadoop使用三副本技术保存数据,数据利用率只有百分之三十三,数据保存成本较高;同时客户对Hadoop承载的数据可靠性要求也越来越高,数据保护(备份、容灾等)需求越来越多,Hadoop3.x开启了存储和计算分离的趋势,但这些还不能完全满足用户需求,数据湖需要从数据存储、数据治理等方面继续发展。目前的数据湖架构如图2所示。
杨磊:我再来列个表,看一下数据仓库与数据湖的差异(如表2)。
总结
金琦:感谢各位老师参与这次对数据领域相关概念的讨论。虽然部分人将数据湖作为数据仓库的替代品,但许多专业人士也认为这两种技术是互补的,不同应用程序的业务数据通过数据湖汇聚到一起,之后在数据湖的基础上建构数据仓库和高级分析环境,将这些应用与技术全部云化后,拥抱第三方平台,从而实现系统与第三方平台的数据整合。数据湖这种“存储一切数据、分析一切数据”的技术以及数据湖与数据仓库相连接的理念,为企事业单位数据中心的松耦合架构设计提供了新思路。在这样的混搭结构中,数据统一以原始格式存储于数据湖内,确认有用的数据从数据湖内转为结构化存储,进入数据中台使用,让数据中台能更好地支撑数据预测分析、跨领域分析、主动分析、实时分析、多元化结构化数据分析,而数据中台建设为各级数据部门提供数据服务和共享奠定重要的基础,可以加速从数据到价值转变的过程,提高相应业务能力。
