安晓宁 王智文 张灿龙 庚佳颖 李秋玲

摘要:传统的基于隐马尔可夫模型的人脸识别方法需要对原始人脸图像进行光照补偿、人脸旋转等预处理,而且模型对人脸姿势、表情、局部特征变化等非常敏感,为解决此问题,提出一种基于高斯隐马尔可夫模型的人脸特征标注方法,该方法假定人脸图像中人脸和人脸特征两个区域的灰度值服从两个不同的高斯分布,并将这两个分布作为隐马尔可夫模型的状态集合,同时,将灰度人脸图像转换为一维的灰度值序列作为观测序列,通过模型预测状态序列以实现人脸特征的标注和定位,并基于该模型建立人脸数据库,对未知人脸进行识别,在ORL人脸库和自建人脸库的测试中,均取得较高的标注准确率和识别准确率,
关键词:高斯隐马尔可夫模型;特征标注;人脸识别;ORL人脸库;自建人脸库
中图分类号:TP391.4DOI:10.16375/j.cnki,cn45-1395/t,2020.02.017
0引言
人脸识别是人工智能和计算机视觉的重要应用领域之一,目前人脸识别技术己经被广泛应用于公共交通、移动支付、智能监控、身份验证等方面,人脸识别由人脸检测和人脸识别两个过程组成,其中人脸检测是指检测采集图像中是否含有人脸并检测人脸范围;人脸识别是指在人脸检测的基础上根据提取到的人脸图像,标记和提取人脸的面部特征,并与人脸库中人脸数据进行匹配以认定身份;而人脸识别中较为关键的一步是人脸特征提取,近年来人脸特征提取的方法不断被提出,主要有samaria等提出基于隐马尔可夫模型的人脸识别方法,该方法能够自动分割人脸图像并提取人脸特征进行识别;Li等提出了基于主成分分析和线性判别分析的组合特征提取方法,主成分分析(PCA)用于特征提取和降维,线性判别分析(LDA)用于进一步改善子空间中样本的可分离性并提取LDA特征;Rotation等提出局部二值模式(LBP)算法,该方法是一种衡量中心像素与周围像素关系的纹理特征提取算法;还有基于中心对称梯度幅值相位模式的单样本人脸识别算法Gabor滤波、卷积神经网络等,这些算法在人脸特征提取上都取得了较好的效果,但是这些算法也存在对光照、姿势、表情等敏感、训练时间长、识别速度慢等缺点,本文使用的基于图像灰度值的高斯隐马尔可夫模型对测试人脸图像的姿势、表情等不敏感,而且该模型训练时间短、计算量小,不需要大量的训练数据便可以达到较高的标注精度。
1隐马尔可夫模型简介
1.1隐马尔可夫模型基本概念
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态序列,再由各个状态生成一个可观测随机序列的过程,其中由马尔可夫链随机生成的状态变量的序列称为状态序列,表示为I={i1.i2.i3.…};其中T为状态序列长度,i1.i2.i3…,ir分别表示每一个时刻的状态变量,由每个状态生成的一个观测变量所组成的序列称为观测序列,表示为O={o1.o2.o3…oT},其中,T为观测序列长度,o1.o2.o3…,oT分别表示每一个时刻的观测变量,在隐马尔可夫模型中,系统通常在多个状态之间转移,因此,状态变量是离散型的,状态集合表示为Q={q1.q2.q3…gN},N表示可能狀态数;观测变量可以是离散的,也可以是连续的,但本文所建立的高斯隐马尔可夫模型的观测变量是连续的。
隐马尔可夫模型是一种典型的有向图模型,其图结构如图1所示,其中箭头表示变量间的依赖关系,根据齐次马尔可夫性假定和观测独立性假定,观测变量的取值只依赖于该时刻的状态变量,即对于观测序列中间某一时刻t的观测变量ot由其对应时刻t的状态序列的状态变量it决定,与其他状态变量和观测变量无关;系统的下一时刻状态仅由当前时刻状态决定,即it仅依赖于it-1.
一个隐马尔可夫模型由初始概率分布、状态转移概率分布和观测概率分布这3个要素确定,状态转移概率矩阵与初始概率向量确定了隐藏的马尔科夫链,生成不可观测的状态序列;观测概率矩阵和状态序列确定了可观测的观测序列。
A是状态转移概率矩阵,表示为:
3)解码问题,即己知模型参数λ=(A,B,π)和观测序列D={o1.o2.o3.…,oT},求对给定观测序列条件概率P(D λ)最大的状态序列,该问题使用Viterbi算法解决,
2基于高斯隐马尔可夫模型的人脸识别
2.1人脸特征标注算法
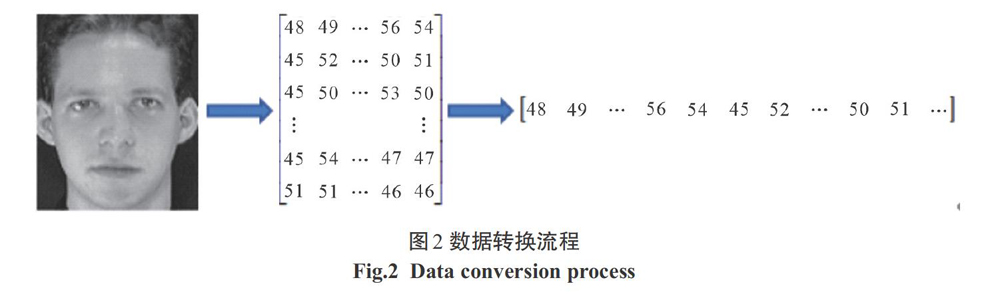
人脸特征提取是在己经通过人脸检测获取的人脸图像上进行的,对于一张灰度人脸图像,其不同部位的灰度值有很大的区别,如脸部的灰度值的均值一般大于眉毛、眼睛等部位的灰度值均值,而眼睛、鼻子、嘴巴等部位的灰度值均值相对来说更为接近,这样就可以通过灰度值的差别将脸部特征从人脸图像中分离出来;另一方面,对于一张简单的正面人脸图像,其特征分布在垂直方向固定,从上到下依次为眉毛、眼睛、鼻子、嘴巴由于人脸图像为二维数据,需要将二维数据转换为一维数据,作为模型的观测序列,考虑到人脸特征分布的稳定性,可将一张图像灰度值矩阵的每一行从上至下依次首位串联起来,组成一维序列,如图2所示,这种方法不会改变特征的分布,而且实现了数据降维。
人脸图像可以分为两个明显区域,一个是人脸,另一个是人脸特征,包括眉毛、眼睛、鼻子、嘴巴等部位,在人脸灰度图像中,两个区域亮度存在明显的差别,而且每个区域的灰度值会分别集中在某一个数附近,也就是该区域灰度值均值,因此,假定每个区域的灰度值服从某一个高斯分布,这两个区域也即这两个高斯分布为隐马尔可夫模型中的两个状态,分别生成不同部位的灰度值。
基于这种思想,以人脸灰度图像的灰度值序列作为观测序列,以两个高斯分布作为状态集合构建一个高斯隐马尔可夫模型,通过Viterbi算法推断观测序列的状态序列,以状态序列还原原始图片,若某一像素点来自第一个状态即第一个高斯分布,那么该像素点的灰度值设定为0.若某一像素点来自第二个状态即第二个高斯分布,那么该像素点的灰度值设定为255.这样就把状态序列替换为0和255两个数,根据状态序列还原原始图片,这两个状态即可以标记人脸和人脸面部特征,并可以通过0和255两个值定位人脸面部特征在图像中的位置,也可以通过状态转移确定特征的边界。
在正常光照的情况下,每张人脸灰度图像人脸和面部特征的灰度值都存在着较大的差距,因此,只使用一张人脸图像作为训练集来训练模型,使用此模型去标记测试集的人脸图像,为了排除图片像素对模型的影响,使用同样为92x 112像素的图像作为模型的训练集和测试集,具体算法流程如图3所示,
2.2人脸识别算法
为了将人脸识别出来,必须提前建立人脸数据库,即将每个人的一张或多张人脸图像作为训练数据训练模型,并将模型参数λ=(A,B,π)保存,即形成人脸的统计模型,人脸图像训练完成意味着人脸库已经建好,对于要识别的人脸图像,如图2所示,首先将像素矩阵转换为一维数据作为观测序列,然后通过前向算法或者后向算法分别计算在不同人脸模型下的条件概率P(O λi),取最大概率值所对应的人脸模型作为匹配人脸。
2.3实验结果分析
传统人脸识别算法会受到人脸表情、姿势、位置、光照、遮挡物等因素影响,因此,实验分别对正面人脸图像、不同表情、不同姿势等情景下的人脸图像进行标注,验证算法的有效性,部分标注结果如图4所示,人脸识别系统基于Python编写,在64位Windows10系统运行,算法使用ORL人脸数据库进行验证,ORL数据库共有400张人脸图像,包含40个人的不同角度、光照、表情,每个人对应10张图像,每张图像的大小为92×112.使用一张正面人脸图像训练模型,分别对不同人脸进行标注,其中模型训练用时0.22s。
为了测试算法在均匀光照下的对正面人脸标注准确率,实验从ORL人脸库中选取40张光照均匀的正面人脸图像,其中一张作为训练数据训练一个模型(见图5),并保存模型参数,其他图像作为测试数据,实验结果显示,在40个不同人的正面人脸图像中,标注正确的图像有35张,部分标注结果如图6所示;错误标注或标注不清的图像有5张(见图7),算法测试的准确率为89.5%。
从ORL人脸库中选取62张光照均匀的侧脸图像和不同表情的人脸图像,以测试人脸姿势对标注算法的影响,实验结果显示,在62张图像中,标注正确的图像有56张,部分标注结果如图8所示;标注错误或标注不清图像有6张(见图9),算法测试的标注准确率为90.32%,相比于正面人脸图像标注准确率来说,人脸的姿势和表情并不会对标注算法产生很大的影响。
验证人脸识别算法,需要建立人脸数据库,人脸数据库的建立就是使用不同的人脸图像去训练模型,建立不同的人脸统计模型,本实验使用ORL人脸库,首先,将每个人的前5张图像作为训练数据训练模型,建立一个包含200个人脸模型的人脸库,使用每个人的最后一张图像组成一个包含40張图像的测试数据进行人脸识别测试,然后,逐次增加训练数据,即依次将每个人的前6张、7张、8张、9张图像作为训练数据分别建立人脸模型的人脸库,将每个人的最后一张图像作为测试数据,该测试集包含40个人脸图像,其中每张图像训练平均用时0.3629s。
首先使用包含200个人脸模型的人脸库进行测试,测试集40个人脸中,正确识别32张,错误识别8张,人脸识别算法的识别准确率为80%;当增加人脸库中人脸模型,使用包含360个人脸模型的人脸库进行测试时,40个人脸图像中识别正确37张,识别错误3张,算法的识别准确率为92.5%(见表1),增加人脸库使得算法的识别准确率有了显著的提高。
2.4自建人脸库测试
为了验证算法在实际应用中的可行性,建立了包含10个人共计100张人脸图像的人脸库,采集其中每个人在光照均匀条件下的不同角度、不同姿势的10张图像,每张图像是大小为112×112的灰度图像,首先,使用一张人脸图像训练模型(见图10),模型参数如图11和表2所示,使用训练好的模型并对自建人脸库的部分人脸数据进行标注,测试标注算法实际应用中的效果,其标注结果如图12所示,其次,实验将每个人的前6张不同角度的、不同姿势的人脸图像作为训练数据,后4张作为测试数据进行人脸识别,并依次增加训练数据,测试不同训练集规模下人脸识别的准确率(见表3),部分示例如表4所示。
2.5实验对比
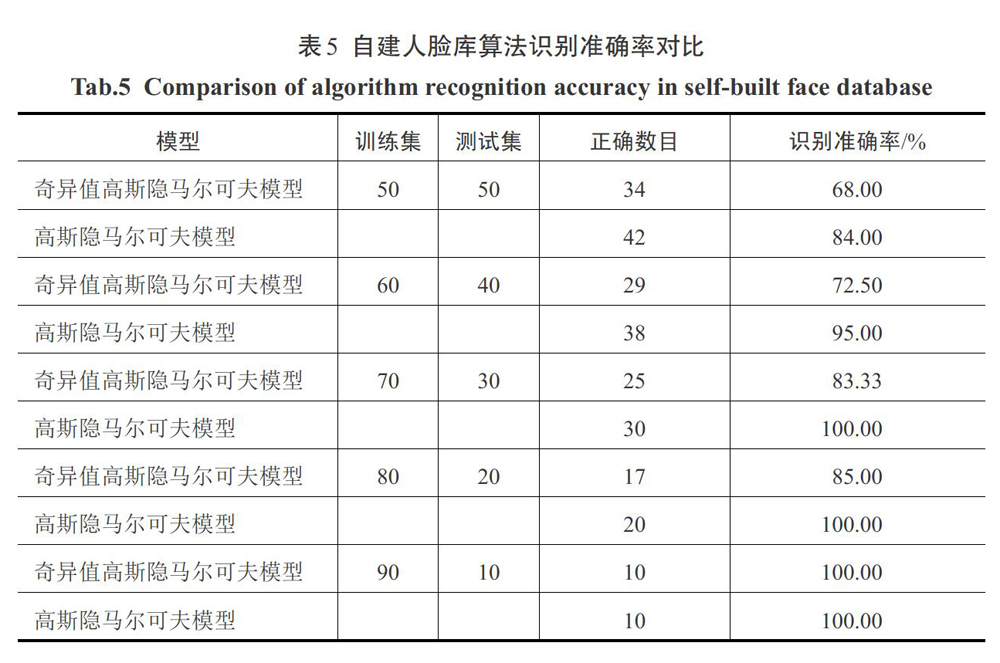
实验使用自建人脸库对比基于奇异值分解的隐马尔可夫模型和高斯隐马尔可夫模型在实际人脸识别中的应用效果,实验结果显示,若每个人的前9张作为训练集,最后1张作为测试集时,两个算法识别的准确率都为100%;但是,当训练数据较少时,高斯隐马尔可夫模型具有较高的识别准确率,故在同等条件下基于高斯隐马尔科夫模型的识别效果优于基于奇异值的隐马尔科夫模型,具体的实验结果如表5所示。
3总结
本文利用高斯隐马尔可夫模型对人脸进行特征标注和识别,并在ORL人脸库测试中都取得了较好的效果,该模型不需要大量的训练数据,便能够有效地对人脸特征进行标注和提取,兼具训练时间短、标注和识别速度快、准确率高等特性;同时该模型对人脸的姿势、表情、局部特征变化有较强的鲁棒性,在真实的自建人脸库测试中,该模型能快速有效地对人脸图像进行标注和识别;在同等条件下该模型的识别准确率比基于奇异值的隐马尔可夫模型更高,总体来说,该模型符合工程应用的要求,可以应用于真实场景下的离线人脸识别。
- 大体积混凝土的裂缝产生的可能原因与预防措施
- 岩土工程勘察中几个常见问题的分析
- 浅议集中供热的外网水力工况
- 轻型井点降水技术的应用研究
- 浅谈沥青路面水损害及其治理措施
- 浅谈沥青混凝土路面摊铺离析控制
- 浅谈红砂岩路基的施工方法及其质量检测方法
- 浅谈公路工程造价控制与管理
- 商品住宅三种采暖方式的比较分析
- 深基坑工程的特点及存在的问题
- 水库除险加固建议与实施
- 我国工程造价管理的思考
- 浅谈城市道路沥青路面不平整的原因和防治
- 浅谈GIS在水利现代化中的应用和发展
- 高空作业安全防护设计
- 中压供配电在道路照明中的应用
- 高职院校“计算机应用基础”分层教学方法初探
- 《计算机应用基础》课程教学的心得
- 高职院校《计算机应用基础》课程改革初探
- 高职《计算机应用基础》课程教学改革
- 大数据时代高职计算机应用基础教学改革探讨
- 面向职业教学的计算机应用基础课程改革的探讨
- 高效近红外光谱分析技术在药物分析中的应用
- 特种加工技术及其应用研究
- 光催化反应器数学模型研究刍议
- unimpertinent
- unimpertinently
- unimpinging
- unimplanted
- unimplicated
- unimplicitly
- unimplorable
- unimplored
- unimportance
- unimportances
- unimportant
- unimportantly
- unimported
- unimporting
- unimportunate
- unimportuned
- unimposed
- unimpounded
- unimpoverished
- unimpregnated
- unimpressed
- unimpressive
- unimpressively
- unimprinted
- unimprisonable
- 娱目骋怀
- 娱神悦目
- 娱老
- 娱耳悦目
- 娱肠
- 娱记
- 娱谈
- 娱谑
- 娱适
- 娱酒
- 娲
- 娲后余石
- 娲皇
- 娲皇劫灰土
- 娲皇氏
- 娲皇炼石
- 娲补
- 娴
- 娴于辞令
- 娴娴
- 娴婉
- 娴淑
- 娴熟
- 娴穆
- 娴良