米永宁+耿志杰
摘要:近年来,档案界对大数据技术的研究较热,但整体来看在目前条件下应用大数据技术开发数字档案信息资源存在现实困境,数字档案信息资源开发中的数据化、结构化不足等问题与大数据技术的应用条件之间有一定距离。本文认为应该从完成数字档案数据化、结构化,捕获档案数据流建立档案数据资源库,强化档案数据流的分析处理等方面将大数据技术应用于数字档案信息资源的开发。
关键词:大数据数字化数据化数字档案信息资源开发
Abstract: In recent years,Archives academia has been keen to research Big data technologies. But all things considered,some realistic predica? ment really exists in applying Big Data technologies to develop Digital Archive Resources under the cur? rent conditions,the unfinished Datamation,Structur? alization,along with other problems cant meet the conditions of the application of Big Data technolo? gies.This article argues several strategies should be taken to apply Big Data technologies to develop Dig? ital Archive Resources,e.g.Continue to work for the Datamation and Structuralization,then capture the Archival data stream and build the Archival data re? pository,enhance analysis and processing of Archi? val data stream etc.
Keywords: Big data; Digitalization; Datamation; Digital archive resources development
一、引言
随着大数据技术的兴起,档案界的研究工作正在逐步深入。笔者在中国知网(CNKI)上,以“大数据”为关键词进行检索,检索时间为2013年1月1日至2015年12月31日,得到相关文章共计152篇。再将这些文章按照主题范畴进行分类,发现其主要涉及档案大数据概念、内涵与特点,大数据时代档案馆建设、应用技术和信息服务,档案工作机遇和挑战,档案大数据价值,数字档案大数据存储,档案管理,档案信息安全和资源管理等领域。
在上述相关研究中,政府和商业界普遍认识到大数据技术和大数据思维带给电子商务、电子政务以及IT行业的冲击和挑战,档案界亦持有相同观点,认为在大数据技术背景下的档案信息化工作面临着新技术、新理念带来的机遇和挑战,亟待转型和创新。对于这一趋势,本文认为,在大数据技术的热潮下,档案界更需要保持冷静的头脑,理性认知大数据技术的同时,还需要认识到档案信息资源开发工作有其自身的规律、特点和任务,不必为了贴上大数据标签而透支大数据概念。[1]
二、大数据技术应用于数字档案资源开发的现实困境
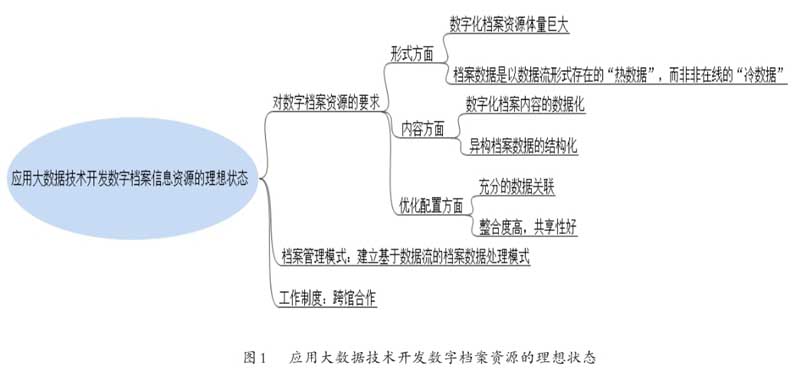
在借鉴有关文献的基础上,笔者发现档案界在应用大数据技术开发数字档案信息资源的研究方面,持有的观点集中体现为:他们认为档案大数据时代已然到来,大数据技术能够应用于数字档案资源的开发。其依据一是大数据技术在商业领域较广泛的应用实践,应用成本逐渐降低且商业价值大幅提高,能够推动该技术不断成熟,因而有望进行大范围推广。二是我国数字档案资源存量和增量均较为庞大,因而大数据技术在这一领域有用武之地。本文认为,上述观点有其合理性,即我国的数字档案资源存量和增量庞大确是事实,但是更应该看到数量庞大的数据并不一定就是可用于大数据技术开发的数据。换句话说,该观点的持有者简单地将大数据的“4V”(Volume—数据体量巨大;Variety—数据类型繁多;Value—数据价值密度低和Velocity—数据处理速度快)特征等同于“数量庞大的数字档案信息”的特征。在综合相关文献研究及实际调研的基础上,我们认为应用大数据技术开发数字档案资源的理想状态应如图1所示。
事实上,目前的档案工作条件与数字档案资源的大数据开发尚有一定距离。从现实角度来看,大数据技术应用于数字档案信息资源开发存在以下困境。
(一)数字档案资源的建设方式无法满足大数据开发的要求
数字化,不是数据化。[2]数字化和数据化之间的关系可以这样界定:数字化的重点在“技术”上,而数据化的重点在“信息”本身。“数字化带来了数据化,但是数字化无法取代数据化,数字化是把模拟数据变成计算机可读的数据,和数据化有本质上的不同”。[3]比如,谷歌公司和亚历山大图书馆合作对所有版权条例允许的书本内容进行数字化,这种数字化就是纸质书页的扫描,但是这些扫描(数字化)后的数字文本只是一些图片。虽然可以通过图片的标引条目对其进行检索利用,但是难以对具体的文本信息进行分析处理,因此需要进行进一步的数据化处理。基于此,谷歌公司使用了能识别数字图像的光学字符识别软件来识别数字化文本的字词句和段落,将数字化图像转化成数据化文本之后,才能对这些文本信息进行开发利用,并通过多种语言对其进行分析和处理。
笔者通过网络和实地调研发现,目前我国档案部门进行的档案资源建设方式就是将纸质档案进行扫描,其实质和上述案例中纸质图书数字化的“工序”类似,数字化后的“产品”同样只是图片,数字化内容未进行数据化处理,是无法进行大数据处理的。因此乐观地认为完成馆藏档案的数字化,便会使档案工作进入“大数据”时代是一种误区。此外,纸质图书基本上是正规的印刷体,只要字迹没有脱落,书页无污损,数字化(扫描)之后,就可以较为方便地借助光学字符识别软件将其进行数据化处理。而纸质档案的数据化处理难度要远远大于纸质图书,比如大量的手写体字迹档案(如名人手稿,信函),识别软件的辨别能力有限,难度较大。另一方面,为了保证档案的凭证价值,数据化过程要求务必精确,就目前而言需要大量人工进行反复校对。由此可见,数字档案信息资源的数据化处理任重而道远。
(二)数字档案资源的内容结构无法满足大数据开发的要求
数据宇宙中的数据按其结构化程度分为结构化数据、半结构化数据和非结构化数据。结构化的数据即行数据,存储在数据库里,可以用二维表结构来逻辑表达,计算机可以直接进行处理;非结构化的数据没有正规的预定义结构,特别是被数据库广泛采用的关系型数据结构,如文本、图像、音视频等。[4]大数据不是大规模数据的简单堆砌,而是强调数据的关联结构性,数据从获取、汇集到分析处理要通过建模和运算。也就是说,目前的大数据处理只能处理结构化数据,而非结构化、半结构化的数据需要通过有效的方式进行格式化转变为结构化数据,才能使用计算机程序进行分析和处理。
目前,通过纸质档案数字化和电子文件归档系统形成的大量数字档案资源很大一部分都属于非结构化的数据,这些数据难以运用大数据技术进行分析和处理,与大数据处理仍有较大距离。其一,由纸质档案扫描得到的数字档案图片,仍需进一步数据化和结构化处理后才能得到结构化的数据。其二,由电子文件生成系统形成的电子文件,由于缺乏协同合作,电子文件形成部门并没有使用统一技术标准的数据库系统,因而这些数据都是异构的,大量异构数据的存在无疑加大了使用大数据技术处理非结构化数据的难度。
(三)数字档案资源的整合共享无法满足大数据开发的要求
真正意义上的数字档案信息资源大数据开发应该强调跨馆际资源联合开发,保障档案数据的相关性和共享性,从而提高档案大数据开发的质量,因此需要相关档案部门具备跨馆际合作的意愿,建立保证合作正常进行的体制,制定相关规划,并具有执行能力。而目前我国档案资源跨馆际整合共享方面还存在明显不足:(1)档案信息化组织工作体制不完善。从全国范围内档案信息化组织工作来看,目前尚无统一的机构来组织档案馆之间数字档案信息资源整合与共享、明确各馆的职责任务与权益权限的工作,档案部门之间缺乏合作意愿;(2)档案信息化工作缺乏规划。从全国档案系统来看,档案信息化建设各自为政,缺乏统一、系统的规划,各馆建设独立的档案信息检索系统和数据库管理系统,横向(地区之间)和纵向(行业之间)均缺乏交流合作,跨馆际合作力度不够,难以完成数字档案信息资源的整合与共享。
三、大数据技术应用于数字档案信息资源开发的策略
截至2012年,Farecast利用将近十万亿条机票价格记录来预测美国国内航班的票价,准确率高达75%,每张机票节约50美元,这项技术后来迅速应用到宾馆预定、二手车购买等诸多领域,应用前景越来越广泛。[5]该案例中“以往大量机票价格波动数据”事实上就是一种数字档案信息资源,其预测结果所显示的准确率和节约的成本则表明将大数据技术应用在数字档案资源开发中是可行的,且市场价值巨大并被广泛认可。据此,我们应该坚定数字档案信息资源大数据开发的信心和前景,重点从深化数字档案馆建设建立档案资源库、加强馆际合作建立档案资源库连接池和树立新思维转变档案管理模式三个方面出发,将大数据技术应用于数字档案信息资源的开发实践。
大数据技术应用于数字档案信息资源开发的关键是解决档案数据流(即以非常高的速度输入和输出档案系统的档案数据)的问题,其实质是建立档案数据的关联问题。深化数字档案馆建设从而实现档案数据化、结构化,建立档案资源库是前提和基础,加强馆际合作建立资源库连接池促进档案资源整合共享是资源准备,树立新思维转变传统档案管理模式是管理保障,解决好这三个问题才能真正实现档案数据的关联,大数据技术应用于数字档案信息资源的开发才有实现的可能。
(一)深化数字档案馆建设建立档案资源库
大数据时代的档案工作实践需破除既有的档案工作思维,真正用大数据思维来思考问题。这就需要改变传统档案资源建设方式,深化数字档案馆建设建立档案资源库为真正意义上的数据关联做准备。传统档案管理严格按照收集、整理、保管、鉴定、统计和利用的先后顺序进行,近年来关于电子文件“在线归档”和“离线归档”的方式也只不过借助网络传输、数据库等辅助方式进行,本质上沿用了纸质档案归档存储模式,仍然将档案管理各环节按顺序割裂处理,二者均偏离了档案大数据思维。
真正意义上的档案大数据要求档案数据是动态的、实时的、相关联的。电子政务的快速发展,物联网技术的应用和智慧城市的建设,促使数字档案以数据流的形式产生、处理并归档。尽管目前档案仍以传统载体为主进行呈现,但是档案记录内容从文字、声音到视频的发展过程,说明档案内容包含信息量更为巨大,表现形式更多元、生动,信息技术的发展会加快数字档案产生,生产力的提高要求档案读取解析更便捷、快速。未来数字档案将以数据流的形态动态地生成、快速地甄别、实时地存储,数据的采集、处理将具有较强的时效性。[6]这样的档案数据符合大数据“4V”特征,“实质上是一种基于发展的、动态的、数据流的档案观;基于数据的处理和知识挖掘过程;是一种基于数据全面性、复杂性、相关性的思维分析方法”。[7]因此,应用大数据技术开发数字档案信息资源的条件之一就是深化数字档案馆建设建立档案资源库。
1.档案部门制定规划,明确权责。档案行政领导部门和业务部门都要明确数字档案数据化和结构化的宏观目标和阶段性目标,制定相关档案馆之间的合作规划,分清相关档案馆的职责任务和权益权限,加强配套资金、人员和设备的投入,并对数字档案数据化和结构化的质量进行监督和评估。
2.业务部门在具体执行时要明确任务,抓紧落实。档案业务部门强化数字档案数据化和结构化工作计划,先完成纸质档案的扫描工作,再进行数字档案数据化和非结构化档案数据的处理,协同建立电子文件在线归档、存储、分析等技术标准规范,研究数据包传输、转换规范。
(二)加强馆际合作建立档案资源库连接池
资源库连接池(亦称资源池),是为了资源整合共享而设计的一种复杂的数据库引用模式。其功能在于通过建立数据库连接池,提供一套高效的连接分配、使用策略,解决资源频繁分配、释放所造成的系统消耗问题,最终目标是实现资源复用、提高系统响应速度和稳定性,对数据库进行统一的连接管理,避免数据库连接泄漏。
大数据不是简单的信息量巨大,信息种类繁多,要求更深层次的数据关联,即数据的高度整合、真正共享。当前档案信息“孤岛”现象与应用大数据技术开发数字档案信息资源的要求相矛盾,要求加强馆际合作,通过档案资源库连接池的方式实现各行业、各系统档案资源库的连接,强化数据关联,实现数字档案信息资源的整合共享。
数字档案信息资源库连接池有助于建立和强化数字档案信息关联性,减少档案信息孤岛现象,扩充档案数据规模,降低数据冗余性,优化档案数据质量;有利于多个档案信息需求者同时访问档案数据资源库,释放档案系统压力、避免档案数据资源库连接遗漏,在行业之间和地区之间都能进行数字档案资源库的连接,为档案大数据开发准备条件。
(三)树立新思维转变档案管理模式
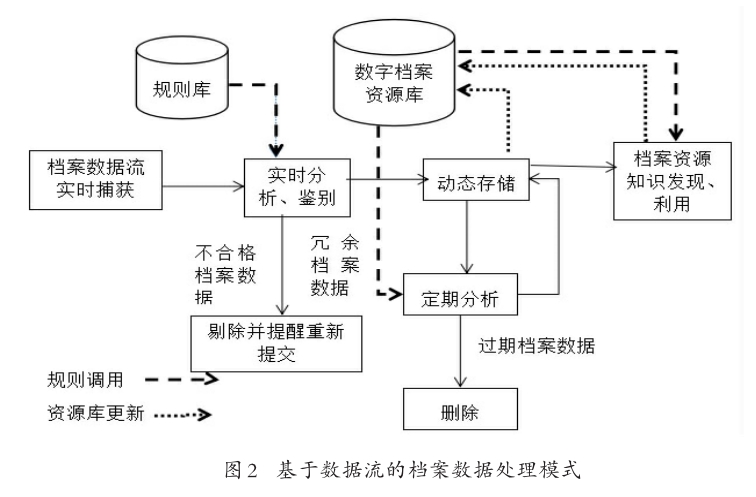
数据流的分析处理是大数据技术应用的重要特征。但传统的档案管理思维明显与现实要求相脱节,需要树立新思维转变档案管理模式。基于数据流的数字档案信息的产生、收集是实时的,动态的,档案数据需要实时存储,动态更新,其分析与鉴定同样是实时的,分析、鉴定和档案数据资源开发(即档案资源知识发现)都需要借助一系列数据分析规则的支持。其真实性、完整性的界定维护面临技术和法律双重问题。可见,大数据时代,数字档案信息的管理需要打破传统档案管理以收集、整理、保管、鉴定、统计和利用为先后顺序的思维惯性,将档案数据流的分析、处理作为管理的重要内容。这其实就是一种基于数据流的档案数据处理模式。如图2所示。
基于数据流的档案数据处理模式,是一种区别于传统的档案管理模式。档案数据的产生、采集、鉴别、存储和利用都是实时的、动态的,需要依赖强大的规则库和操作命令,主要通过计算机完成,档案数据的分析和利用产生的新规则和知识将及时更新到规则库和知识库中。档案数据的提交、接收需要预设规则协议存入规则库中,并体现在系统设计中。档案数据的分析和鉴别(在意义上相当于传统的档案鉴定)需要实时调用规则库中的相关规则,以检验档案数据是否合格,合格的数据准备存储,不合格或者冗余的档案数据则将被剔除,但须反馈给档案数据提交者,反馈内容应包括数据不合格原因并提供建议,此操作可能重复多次,直至数据通过接收检验。数据被存储后,也需要定期进行再分析(在意义上相当于传统的档案定期鉴定),目的是删除无需继续保存的档案数据,维护有价值的档案数据,同时对数字档案资源库进行动态更新,档案用户可以通过相关利用规则访问档案资源库。
注释及参考文献:
[1]于英香.档案大数据研究热的冷思考[J].档案学通讯,2015(2):4-7.
[2][3]维克托·迈尔—舍恩伯格大数据时代[M].浙江:浙江人民出版社,2013.105-109.
[3]David Ferrucci.uima- spec- wd- 05.Unstructured InformationManagement.Architecture(UIMA)Version 1.0 Working Draft 05[S].
[5]中国经济网.大数据如何变革商业一张机票成就了Farecast[EB/OL]. [2015-8-10].
http://book.ce.cn/xw/jj/201212/21/t20121221_ 23964663.shtml.
[6][7]叶大凤,黄思棉,刘龙君.当前档案大数据研究的误区与重点研究领域思考[J].北京档案,2015(7):14-17.
[8]耿志杰.数字档案馆个性化服务研究[D].南宁:广西民族大学,2007.
- 课堂教学中应让学生充分经历“猜想与验证”的过程
- 初中阶段尺规作图教学的反思和建议
- 中小学数学计算题衔接教学的策略研究
- 谈初中数学勾股定理的探究性学习
- 合作探究式教学法在初中数学教学中的应用策略
- 初中数学教学中学生逆向思维的培养
- 探索翻转课堂教学模式在初中数学教学中的应用路径
- 运用微课拓展初中数学教材的探索
- 问题导学法在初中数学教学中的应用
- 浅谈数学教学中分层教学策略与方法
- 基于“6+1”教学模式初中数学课堂教学的研究
- 精准教学视野下初中数学分层教学策略探究
- 初中数学教学中怎样培养学生的思维能力
- 高中数学高考总复习的教学指导方法研究
- 如何巧用多媒体优化高中数学课堂教学效果
- 中职数学“乐趣教学”的探索与实践
- 信息技术条件下的高中数学实验教学
- 运用小组合作学习模式提升高中数学教学实效的探讨
- 数学公共课课程效果分析
- 向量法在高考数学中的应用
- 高等数学课程线上教学的研究与实践
- 管窥高考数学文化题的取材视角
- 数学概念获得阶段概念教学策略思考
- 深入反思,拓展思维,提升素养
- 浅谈小学数学教学生活化的误区及应对策略
- luminous
- luminously
- luminousness
- luminousnesses
- lump
- lumped
- lumpest
- lumpier
- lumpiest
- lumpily
- lumpiness
- lumpinesses
- lumping
- lumps'
- lumps
- lumpsum
- lump sum
- lump sum payment
- lump sums
- lump-together
- lumpy
- lump²
- lump¹
- lunacies
- lunacy
- 听事只容旋马
- 听人使唤
- 听人劝,吃饱饭
- 听人劝,得一半
- 听人家的
- 听人家的喝,砸自己的锅
- 听人穿鼻
- 听人讲授或讲演
- 听人说百遍,不如亲眼见
- 听从
- 听从主人指挥的狗
- 听从佛法,饿断肚肠;听从官法,打断脊梁
- 听从使唤
- 听从别人指挥
- 听从劝告
- 听从劝谏而改易过错
- 听从命令
- 听从善言
- 听从差遣
- 听从支配和控制
- 听从放任
- 听从熟悉情况者的意见
- 听从能者的意见
- 听从谏言
- 听从采纳