

摘要 关联数据技术的发展增强了语义网技术的可行性。学位论文元数据是一种具有代表性、富含语义的图书馆数字资源。研究语义网技术在学位论文元数据上的应用,不仅有助于改善其管理、服务模式,为拓展基于知识的决策支持服务提供新的契机,而且可以反映图书馆数字资源语义化的一般模式与效果。通过建立面向关联数据的学位论文元数据语义化原型,研究评估了语义网技术在学位论文元数据上的应用效果:在满足学位论文资源发现需求的基础上,提供了更丰富的资源导航与浏览功能;具备了更强的数据互联性;获得了更明确的语义感知与内在的语义互操作支持。
关键词 关联数据 语义网 学位论文 元数据
1 引言
学位论文是学生为获取学位资格,在导师指导下对科研课题进行论述总结形成的一次文献。由于其研究对象多为学科关键、前沿问题,部分论文亦是国家各级重大科研课题成果,因而具有重要的科研价值。与普通科研论文相比,学位论文有选题新颖、理论性及系统性较强、阐述详细等特点。作为学位论文资源建设的附属产物,学位论文元数据不仅承载着学位论文的揭示功能,还能够通过完整描述揭示对象内涵,从而在知识管理中发挥作用。基于对学位论文元数据价值与语义网技术特点的认识,华东师范大学图书馆在国家社科基金项目“社会网络环境下学位论文信息的开放获取与共享模式研究”中提出了以语义网技术拓展学位论文元数据服务的设想。
伯纳斯·李在1994年提出了语义网概念,并在2001年的《科学美国》杂志上刻画了一个由文档网络演化到数据网络的语义网发展进程。文档网络代表目前的万维网,它以HTML格式为主,包含了丰富的、互相链接的资源,人们能够轻易理解资源的内容,但机器却很难自动识别资源中数据的语义。在数据网络中,数据以RDF模型组织,其语义更加形式化,机器可以自动识别数据语义并进行推理计算。2006年,伯纳斯·李在原语义网理念的基础上提出了关联数据概念。一般认为,它是语义网的一种简化实现方案,增强了语义网的可行性。目前,W3C引领着语义网标准的建设,并致力于构建语义网技术栈。2010年,W3C成立了图书馆关联数据孵化小组以帮助提高图书馆关联数据的全球互操作性。截止2014年,关联开放数据项目统计显示,已有1014个关联数据集加入关联数据云图,其中包括图书馆领域的美国国会主题词表(LCSH)、瑞典国家联合目录、英国国家书目等代表性关联数据项目。
学位论文元数据不仅承载着揭示论文文献的功能,它本身亦包含了前沿的科学知识信息,反映了科研教学机构、科研工作者、科学研究对象之间的关系,蕴含了丰富的语义。探讨语义网技术在其上的应用,有助于探索改善现有学位论文元数据管理、服务的模式,探索新的知识管理、决策支持服务契机,而且可以反映图书馆数字资源语义化的一般模式与效果。研究通过建立面向关联数据的学位论文元数据语义化原型,根据对原型化过程及结果的观察与评估,在三个维度上探讨语义网技术在学位论文元数据上的应用效果:第一,对学位论文资源的发现功能的支持;第二,与原关系型元数据相比,在数据互联上的优势;第三,与原关系型元数据相比,在数据语义感知及语义互操作上的优势。
2 相关研究
目前,图书馆界对语义网技术的研究以基础概念的介绍辨析、本体创建、关联数据发布流程与技术、书目数据的语义化居多,对于数字资源,特别是学位论文上的研究也多为演示关联数据发布技术与流程而做,效果评估相对不足。与本研究较为密切的、有代表性的研究概述如下。
考特索米特洛普洛斯等探讨了语义网技术在机构库中的应用。研究指出,从语义网的角度看,用于描述数字资源的元数据是半结构化的。此类元数据不利于数字资源隐含语义的揭示,难以提高资源的可发现性。研究者基于DSpace开发了一个插件原型,以完成佩特雷大学机构库的语义化改造。并从检索的相似性、查准率、查全率以及知识发现四个维度与原系统进行了比较,认为语义化的机构库能够提供与原系统相似的检索功能,并在后三个维度上超越了原系统。
沈志宏等以科学数据关联网络为研究对象,分析关联数据在科学数据库中的需求、适用性、实施原则、框架、应用效果以及所面临的挑战,认为关联数据是科学数据库开放访问机制的最佳选择。
欧石燕提出了一个面向关联数据的语义数字图书馆资源描述与组织框架。其框架由元数据、本体、关联数据、应用四个层次组成。研究者以图书情报与档案学领域的数据为例实现了数据关联的语义数字图书馆原型,分析了数字图书馆各种资源的语义化描述和语义检索与数据关联问题。
马吉特与夏尔马调查了当下用于将遗留数据发布为关联数据的方法与工具,并从数据溯源处理、数据输出类型、转换的自动化、可逆性四个方面进行了评估。针对遗留数据发布为关联数据,研究者提出了抽取、转换以及序列化的一般模式。
沈志宏等提出了关联数据发布过程中可参考的标准化流程,并详细分析了其中的关键问题。研究者提出数据建模、实体命名、实体RDF化、实体关联化、实体发布、开放查询六个关联数据发布关键步骤,并以中国科学引文数据库和中国生态系统研究网络通量数据为例展示了关联数据的发布与服务。
卡茨等探讨了主流的人工智能编程语言Lisp在语义网编程中的使用。研究者认为,Lisp在人工智能、知识表示编程中的稳定性与灵活性为业界所公认,这一优势使其成为理想的语义网构建工具。通过对现有语义网项目的调查,研究者肯定了Lisp在语义网编程上的能力与可用性,并建议在未来的语义网编程中采用该工具。
另有沙若丽,伊,游毅等人对关联数据、语义网技术在书目数据上的应用进行了探讨,主要涉及技术的适用性与数据发布流程和方法。
相较而言,本研究选择学位论文元数据作为语义化对象,以Lisp及关联数据技术为手段,实现了学位论文元数据语义化原型,重点探讨语义网技术在学位论文元数据上的应用效果,加强了基于语义化学位论文元数据的编程探讨,阐述了面向本体编程的优势与价值。
3 建立原型的方法与技术
关联数据发布是目前语义网技术的最佳实践方案。伯纳斯·李提出了关联数据发布的四项指导原则:一是使用URI命名事物;二是使用HTTPURI,以使人们可以查找这些事物;三是当人们查找URI时,以RDF、SPARQL等标准方式提供有用信息;四是包含到其他URI的链接,以便发现更多的事物。
发布关联数据需要使用一项新的语义网技术,即资源描述框架(RDF)。它提供了一种灵活的途径来描述事物以及事物之间的关系,是语义网得以实现的基本机制。RDF以主体一谓词一客体的模型组织数据,谓词的角色通常由词表扮演。词表也称为本体,是语义网环境下的重要数据描述工具,它提供了对特定论域进行刻画和限定概念间关系的词项,是消除歧义、达成论域共识、提供语义互操作性的基础。
关联数据发布的最终结果是将以三元组形式表示的实体数据集通过HTTP、SPARQL方式提供访问。这通常由HTTP服务器与SPARQL端点实现。AllegroGraph是一款基于Common Lisp技术的语义应用开发平台。它包含了一个底层Triple数据库和一套应用开发框架,提供了基本的HTTP访问以及SPARQL、Prolog等查询接口。Allegro-Graph提供专门的数据导入器agload,并支持RDF/XML、Turtle、TriX、N-Triples和N-Quads多种序列化格式。研究中的原型选择在CentOS 6上以AllegroGraph 5.1实现发布平台。
考虑到语义网与人工智能的紧密联系,研究希望探索成熟的人工智能技术在语义网应用上的优势。Lisp作为一门高等级语言已经成功地应用于人工智能、图形、用户接口等领域的快速原型开发[23]。因此,利用基于Lisp技术的AllegroGraph平台,不仅能获得Lisp在知识表示、推理表达上的优势,也能实现快速的原型开发。
4 原型的设计与实现
4.1 RDF数据建模
数据建模主要涉及对原有数据集进行整理,以选择适合于用RDF表示的实体,确定实体间的关系。通过对原有学位论文数据库中50个字段进行筛选,原型去除了如入学时间、保密期限等对当前语义原型意义不大的字段。在剩余的字段中,抽取了学位论文、学生、导师、学院、系所、专业、学科、研究方向以及学位9个实体。抽取出的实体及它们之间的关系如图1所示。
图1中的实体使用词表中的词项进行描述,原有数据库中的字段转换为实体的属性。为了获得更广泛、明确的数据语义解读,原型尽量重用了普及程度高、相对成熟的词表,包括RDFS、DCMI-Terms、PRISM、SKOS、FOAF、ORG6个相对成熟的词表。
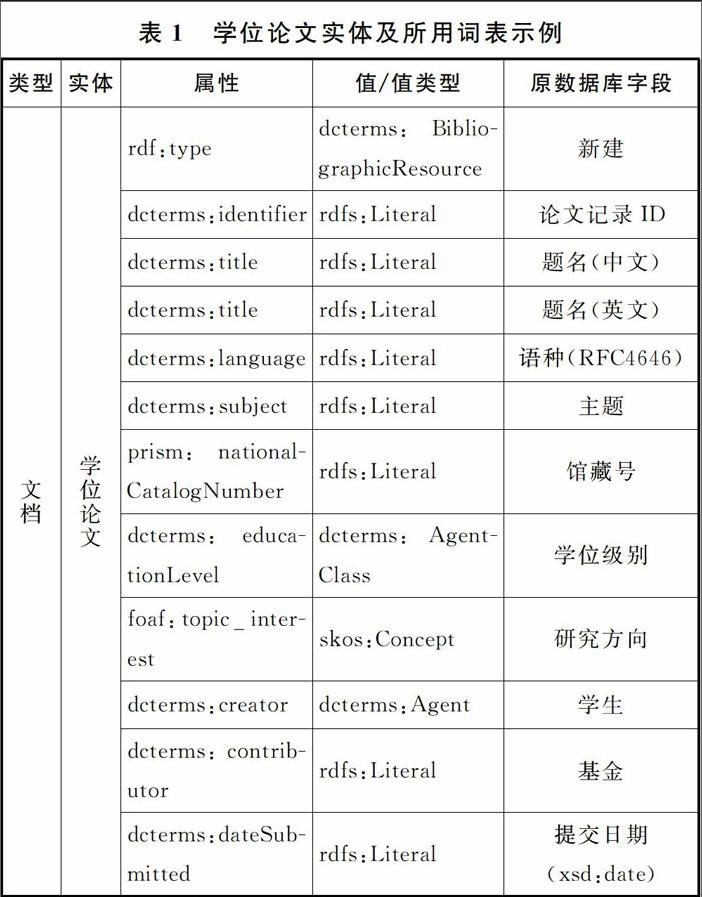
表1列举了学位论文实体部分重要属性值,同时也指明了实体所使用的词表及其类与属性。表的最后一列说明了该属性在原有关系数据库中的字段名称,同时提供了取值的说明。原型所涉及的实体分为文档、人物、机构、概念四个大类。作为示例,这里仅列举了学位论文实体及其部分属性。
4.2
RDF实体命名
实体命名通过URI实现。使用URI命名事物能带来两个好处:一是使得事物URI的创建去中心化,由于域名是唯一的,其拥有者能够自由地创建该域名下的URI引用;二是URI不仅提供了事物的命名方式,同时也提供了事物信息的访问途径,可以重用现有的HTTP URL访问机制。
通常使用模式
4.3 实体RDF化
实体RDF化是指使用主体一谓词一客体三元组模型来表示实体以及实体间关系。原型中的实体抽取自原学位论文元数据表,它们原有的存储机制是关系表。从关系理论的角度看,一张表就是一种关系,对应着一个实体类。表中的字段即是实体类的属性,一条记录对应一个具体的实体对象。实体RDF化需要选择词表中的词项作谓词,用表中实体对象的字段值来填充三元组的客体部分,完成遗留数据的抽取、转换。以表2为例,该记录中所包含的学位论文实体的RDF化效果如图2所示。
4.4
RDF数据序列化
RDF是一个数据描述模型,而非数据格式。为了将以RDF模型描述的数据持久化存储,需要选择合适的格式来表示数据,即RDF数据的序列化。目前主流的RDF序列化格式有RDF/XML、RDFa、Turtle、N-Triples以及RDF/jSON。每种格式的设计目的有所不同,其中Turtle使用了较为简洁的格式来表示RDF数据,便于人阅读与手工编制RDF数据文件。考虑到原关系数据库记录中有许多数据需要手动调整,原型选择使用Turtle格式来序列化实体RDF数据。
案例中,除学位实体较少可以手工编制外,其他数量相对庞大的实体需要编写SQL及PHP脚本扫描原有关系表中的数据生成。在SQL编程中,主要解决实体抽取,包括实体字符表示的净化与规范、实体关联,以及多条记录中同一实体的去重。PHP脚本部分主要解决字符集的转换、实体字符表示到RDF对象的转换,以及RDF数据序列化。
4.5 RDF数据发布
通过将上一阶段的实体序列化文件经agload工具入库到AllegroGraph中后,原有的46097条SQL Server数据库记录转换为AllegroGraph中的1022855条三元组,并产生了5个实体类、21个谓词。借助AllegroGraph,原型在HTTP协议上提供了学位论文元数据的关联数据存取服务。Allegro-Graph提供了对RDF标准查询语言SPARQL的良好支持,目前支持SPARQL版本1.1。Allegro-Grpah通过集成的AllegroGraph Web View接受用户的查询输入,并提供了SPARQL查询构造辅助,在查询接口的下方输出查询结果。利用AllegroGraph的SPARQL查询结果导出接口,检索结果可以输出为SPARQL JSON、SPARQL XML、SPARQL TTL、SPARQL CSV、CSV- NTriple等序列化形式。
5 应用效果评估
5.1 资源发现功能支持
传统学位论文元数据提供的检索点数目取决于元数据关系表中的字段数。以关联数据发布的学位论文元数据可以将原有的字段转换为三元组中的客体,完整保留原有的学位论文著录信息,提供与传统学位论文元数据同等的检索点数量。由于SPAR-QL内在地支持联邦检索,能够在SPARQL查询结果生成前将外部的RDF数据与本地的RDF数据汇聚成查询目标,这为提供新的检索点创造了机会(参见图5)。
从检索方式上看,原有学位论文数据库提供了以字符串匹配及布尔逻辑运算为基础的检索实现,以及按中图法、专业浏览的功能。原型的SPARQL查询接口不仅提供了字符串匹配与布尔运算,而且支持更加强大的正则表达式运算。原型中,RDF模型表示下的学位论文元数据产生了新的实体类与谓词,它们所表示的实体及实体间关系构成了一幅有向图(参见图1),这为浏览式的资源发现提供了良好的支持。
在SPARQL查询结果中,通过结果集中实体谓词所表达的实体间语义关系,可以索取到更多相关资源。图3给出的示例以检索谓词prism: keyword包含“语义网”的学位论文实体集SPARQL查询开始,在获取到学位论文实体后,浏览ID为6771的论文实体,通过该实体的foaf:topic_interest谓词,可以获取研究方向“教育测评与信息处理”实体,通过研究方向实体谓词skos: borader,可以浏览上一级概念“教育技术学”专业实体,然后通过专业实体谓词skos:narrower查看另一研究方向“教育信息化理论与实践”实体,最终找到另一ID为46003的学位论文实体。
对于信息检索的两个基本指标查准率与查全率,由于关联数据在检索点与检索运算实现上涵盖了传统学位论文数据库,两者应该是等同的。以检索题名中含有“法国文学”一词的学位论文为例,两者的结果一致,如图4所示。
5.2 数据互联上的优势
传统的学位论文数据库是一个相对封闭的系统。元数据存储在关系数据库中,它们通过模式(表定义)的定义进行聚合,其关联主要是表间关联或文件关联,数据很少指向外部资源。关联数据作为一种强调数据互联的数据描述模型,数据互联是其内在本质。以原型为例,资源类、谓词属于一种由第三方提供的外部数据资源,可以通过URI访问它们,这是原有学位论文数据库所缺乏的。
SPARQL支持从多个数据源进行查询,包括从多个本地RDF图的查询以及从多个SPARQL端点的联邦查询。这项机制是SPARQL自身实现的一部分,不需要额外的支持。通过联邦查询,图5中的示例将本地RDF数据集中实体谓词skos:prefLa-bel包含“法律”的研究方向实体与DBpedia中包含“law”的概念实体进行了汇集。SPARQL的这项机制为以关联数据发布的学位论文元数据提供了动态的数据互联能力。
图5所示的数据互联链接了DBpedia中归类为概念(skos:Concept)的实体,它只是实体互联的一个实例。以关联数据发布的学位论文元数据而言,还存在其他的实体关联点,其中的导师实体可以关联到一个提供知名学者关联数据服务的数据集,学位论文主题也可以关联到类似LCSH的中文主题词表。显然,数据互联是关联数据技术的最突出优势之一,它有利于丰富和充实本地数据集。对于资源使用者而言,它提供了更多的资源发现手段、丰富的知识扩展途径;对于语义消费程序而言,它提供了更多的知识信息源,为推理提供了支持。
5.3 数据语义感知与互操作上的优势
在基于关系数据库的学位论文数据库中,模式虽然在一定层度上表明了数据的语义,但由于字段命名是在应用域内的局部行为,缺乏共识,难以为外部的机器识别。以原学位论文数据库为例,学位论文表中类似“指导教师”、“中文论文题名”这样的字段名在另一个应用中很可能以“导师”、“题名(中文)”等不一致的形式出现。这对机器的数据语义自动识别带来了障碍。对于文档网络而言,数据甚至缺少模式的描述,这个问题会更加突出。
关联数据的RDF模型本身即是知识表述的一种模式。由于三个元素中的主体、谓词是基本事物或属性,因而由他们构成的陈述是细粒度的表述,语义较为明确。随着本体的发展,三元组中的谓词与客体可以使用普遍认可的词项或资源,整个陈述能获得更好的语义感知度与语义互操作性。本体的成熟与发展为面向本体进行编程提供了机会,既有的智能代理可以在消费以已知本体发布的关联数据基础上提供语义分析服务。
以提供科研决策支持服务为例,假设机构需要了解本单位培养博硕士所研究的热点分布,则基于原学位论文数据库中面向关系数据库的编程和基于原型面向本体的编程的查询逻辑如图6所示。
图6中,两者都首先通过统计、倒排序找出热门的研究方向,然后迭代排序后的数据集,找出研究热点的研究教师与所在系所。不同的是,关系SQL中包含了特定的表信息与字段信息,而SPARQL中则以本体代替。对于其他的数据集,面向关系数据库的编程缺乏普适性,往往需要面对表的变化与字段命名的不一致性。而面向本体的编程则完全可以自动消费以相同本体进行标识的数据源。由于本体也使用如RDF、OWL等更基本的本体描述,并提供HTTP访问,因而可以在程序中追溯本体的语义。显然,关联数据实现了数据语义的形式化,增强了数据的语义感知度与语义互操作性。
语义互操作能力的增强对领域内数据集间的集成与领域间数据集的集成亦有重要的促进作用。以领域内的数据集为例,在分布于各科研教学机构的学位论文元数据集间,使用统一的词表描述的学位论文元数据可以无缝地集成为一个全国范围内的学位论文元数据集,以供相应的程序消费;对于现有的学位论文数据收割工作,以关联数据发布的学位论文元数据可以减少个别数据集间的不一致性,有利于数据收割工作顺利进行。对于其他领域而言,以关联数据发布的学位论文元数据也更容易被集成消费,通过标准的HTTP、SPARQL方式,本地的其他应用服务以及网络上的数据消费程序可以轻易地以离线或在线的方式集成学位论文元数据,如图书馆集成系统集成学位论文元数据。
对于用户资源使用而言,以关联数据发布的学位论文元数据能提供更好的语义感知度。由于关联数据中的链接是类型链接,链接所使用的本体充分表达了其所指向资源的内涵。当使用SPARQL检索或通过类型链接浏览资源时,用户对操作所包含的语义较传统关系型数据库支持下的类似功能更明确。
6 结语
以学位论文元数据为代表的图书馆数字资源管理与利用模式革新是其价值最大化的内在需求。语义网技术的出现为探讨这种管理与利用模式革新提供了机会。对以学位论文元数据为代表的图书馆数字资源上的语义网技术应用研究,不仅有助于探索新的图书馆资源管理与利用模式,也为图书馆发掘基于知识的决策支持服务提供了契机。
面向关联数据的语义化学位论文元数据,可以提供与传统元数据相媲美的资源发现途径、查准率与查全率。得益于关联数据对外部数据的自然集成,面向关联数据的语义化学位论文元数据可以提供更加丰富的资源发现途径。关联数据中的RDF有向图以及本体所建立的规则为基于数据语义与逻辑推理的资源导航与浏览提供了机会。在由面向关联数据的,语义化学位论文元数据支持的发现平台中,用户能从良好的数据语义感知中获益,其资源搜索行为能够得到更多的信息反馈,从而更加高效。
传统的图书馆数据,包括书目数据、本地的电子资源元数据,常常处于数据孤岛的尴尬局面。它们难以在各个异构的数据源之间共享,也不能被谷歌等发现系统访问。面向关联数据的语义化学位论文元数据,能够更好地关联外部数据源,也更容易为外部数据源所链接,使图书馆数据可以顺利地融入全球数据网络。
数据的语义能为机器所理解并进行推理以提供智能化服务,是语义网技术出现的基本动机。虽然语义网技术当前还处在一个初级阶段,但借助于关联数据技术,面向本体的语义编程已经显示了这种可能性。在面向本体的编程中,本体中类所反映的继承、整体与局部等关系,本体中属性所反映的传递、逆等关系为智能代理基于规则的推理提供了数据级的支持机制。
作为一项原型化实验,研究并未建立本地的词表,词项foaf: knows用于表达学生与导师间关系,词项foaf:topic_interest用于表达论文等实体与研究方向实体间关系只能是一个折衷选择;在数据的规范与准确性处理,以及实际的数据集互联与语义编程上,亦未做深入的探讨。研究尝试采用成熟的人工智能技术,基于Lisp技术平台,实现学位论文元数据语义化原型的构建,侧重于探讨语义化学位论文元数据的效果,希望可以为进一步的、以学位论文元数据为代表的图书馆数字资源语义化研究实践提供参考。
- 宗庆后:高质量发展要靠企业深化改革来实现
- 李晓鹏:创新协调发展 建设世界一流企业
- 刘明忠:紧紧抓住改革“牛鼻子” “老国企”重焕“新青春”
- 袁兵:专业机构和市场化基金是国企下一步改革的催化剂与黏合剂
- 肖亚庆:国企要进一步加大开放力度
- 重新定义生命医疗,用科技敬畏生命
- 安徽四建牢记安全生产使命
- 军熙枣业:让贫困地区百姓生活“红起来”
- 中国质量新闻网直销频道正式上线
- 科技社团在工程师职业发展中的作用
- 邹倩:扎根工作一线 解小微金融难题
- 南京新侨鑫环保科技有限公司 立足环保研发 造福建筑节能
- 江苏宏力新能源发展有限公司 开发清洁能源展光伏发电愿景
- 四川怡升环保科技有限公司 以人为本 执着净水行业可持续发展
- 湖州健塑塑业科技有限公司 创新驱动安全饮水梦想
- 北京科润盛达供热投资有限公司 深耕低耗环保 创新节能供热
- 重庆穗通新能源汽车制造有限公司 整合新动力 深度研发新能源
- 苏州工业园区世普瑞环保科技有限公司 辐射四大工程建设 开发净化新工艺
- 扬州意匠轩园林古建筑营造股份有限公司 营造国际意匠轩铸筑百年老字号
- 鞍钢集团鞍千矿业有限责任公司 集中一贯制管理创“精益”精细化管理
- 山西桦桂农业科技有限公司 时刻牢记企业责任先行充分发挥企业示范作用
- 江苏宁国耐磨材料有限公司 发扬新工艺 造福子孙后代
- 常州第二电子仪器有限公司 电子激光开拓者 行业领域创先进
- 格盟国际能源有限公司 应用高尖新技术践行多元化发展
- 姚俊杰 美锦能源集团有限公司总裁
- plug/plug up
- plugs
- plug sth in
- plug sth in / plug sth into sth
- plug sth into sth
- plug sth ↔ in/into
- plug-up
- plug²
- plug¹
- plum
- plumage
- plumages
- plumber
- plumbers
- plumbers'
- plumbing
- plumbings
- plume
- plumeless
- plumelike
- plume-like
- plumery
- plumes
- plumification
- pluming
- 驋
- 驌
- 驌騻
- 驍
- 驎
- 驎角
- 驎骥
- 驏
- 驐
- 驒
- 驒騱
- 驓
- 驔
- 驕
- 驕傲
- 驕美
- 驕驁
- 驖
- 驗
- 驘
- 驙
- 驚
- 驚女
- 驚霧
- 驛