


摘要:数学主观题自动阅卷既无法直接采用长文本计算中的TF- IDF等统计方法,又因为缺少相关知识库而无法使用语料库、知识库、语言学等短文本的方法。本文根据数学主观题的特点,提出了一种将人工制定评分标准和双向长短时记忆神经网络相结合的数学主观题自动阅卷方法,在高二年级数学真实考题上进行实验,准确率达到83.17%。
关键词:数学主观题 自动阅卷 文本相似度 深度学习 Bi- LSTM
中图分类号:TP311 文献标识码:A
Bi- LSTM Based Automatic Marking Method for Mathematical Subjective Test
Liu Yixue1, Lu Yuxuan1, Ding Liang2, Wang Xingming1(1.Beijing National Day School, Beijing, 100039; 2. Institute of Scientific and Technical Information of China, Beijing, 100038)
Abstract:Mathematical subjective questions can not use directly long text similarity calculation methods, such as TFIDF. They lack relevant knowledge base and also can not utilize short text similarity calculation method, such as corpus methods, knowledge base methods and linguistic methods. This paper proposes a method of calculating the similarity by combining human marking standard and Bi-LSTM neural network. The result of experiment shows that Bi-LSTM based automatic marking method achieved the accuracy rate of 83.17% on real mathematics test in the 11th grade. Key words:Mathematical subjective questions Automatic marking Text similarity Deep learning Bi-LSTM
1 引言
考試是一种严格的知识水平的鉴定方法,是教师在教学过程中检测学生知识掌握情况的重要手段。在中小学的教学中,各个科目的考试通常是书面形式,类型包括客观题和主观题。客观题多为选择题、填空题或者判断题,其答案较为明确、缺少歧义,阅卷较为容易;而主观题多以简答题或者论述题的形式,人工阅卷的方式居多。两种题型中,主观题是比客观题更为重要的检测手段,然而由于考生人数通常较多、考试次数频繁,如果只依赖人工阅卷,教师的工作量非常繁重,阅卷质量极容易受人的主观因素影响。利用计算机技术实现主观题自动阅卷,可以缓解这种问题,至少能辅助教师快速而客观地给出得分,从而提高教学效率。
主观题自动阅卷属于自然语言处理的技术范围,主要目的是计算考生答案和试题标准答案之间的语义相似程度。相似度越高,考生得分越高。目前已有的文本相似度的计算方法将文本分为短文本和长文本。长文本相似度的计算通常在文档级别上,利用TF-IDF和VSM等统计手段能够很好地表达文本的相似程度。短文本的相似度计算多为句子级别,与长文本不同之处在于短文本具有词语稀疏、语义离散等特点,无法直接使用长文本相似度计算的方法,多采用相同字符计算、语料库或者知识库、语言学等方法。
数学主观题的长度介于长文本和短文本之间,数学符号居多,语句较为单调,文本歧义较少,既无法直接采用长文本计算中的TF-IDF等统计方法,又缺少相关数据而无法使用语料库、知识库、语言学等短文本的方法,需要根据数学题目的具体特征制定针对性的文本相似度计算方法。
本文根据数学主观题的特点,分别从统计角度和语义角度,提出了一种基于双向长短时记忆(Bi-LSTM)神经网络方法,进行数学主观题自动阅卷,并在包括11道高二年级数学真实考题以及1018份学生答案的数据集上进行实验,采用自动阅卷与人工阅卷分数的偏差程度来衡量自动阅卷的质量,实验结果显示,基于Bi-LSTM的数学主观题自动阅卷准确率为83.17%。
2 相关工作
主观题阅卷的关键是文本的相似度计算。通常的文本相似度计算针对的是长文本或者文档,由多个段落组成。最直接的度量方式是计算文本间共现的字符串,区别在于不同的计算方式。针对字符串或者其拼音,寻找最长公共子序列、最小编辑距离等。这种方式简单有效,但是没有考虑文本的语义信息。更为复杂的方式是将文本内容的处理转化为向量空间中的向量运算,然后采用编辑距离、汉明距离、欧式距离、Jaccard相似性、余弦或者曼哈顿距离等来度量相似度。向量空间模型利用TF-IDF方法将文本内容的向量化 [1,2]。隐性语义标引(LSI)将词频矩阵转化为奇异矩阵,通过奇异值分解,剔除较小的奇异值,将文档向量和查询向量映射到一个子空间中,在该空间中,来自文档矩阵的语义关系被保留,将文档特征空间变为文档概念空间。概念向量之间使用内积的夹角余弦相似度计算,比原来基于原文本向量的相似度计算更可靠。该方法的效果依赖于上下文信息,过于稀疏的语料不能很好地体现其潜在的语义[3]。基于Hash方法是一种基于概率的高纬度数据的维度消减的方法。SimHash [4]为Google处理海量网页的采用的文本相似判定方法,它将高维的特征向量映射成f-bit的指纹,通过比较两篇文档指纹的汉明距离来表征文档重复或相似性。
短文本通常指的是蕴涵内容较少的短小文本,例如论坛留言和回复、手机短信、即时聊天记录等,短至十几字,多则一百字左右。短文本相似度计算与长文本有相通的地方,也有迥异之处。可以通过比较文本间的公共词汇来衡量其相似度 [5],也可以通过语料库来计算[6,7]。知识库中的语义路径也可以帮助短文本相似度计算,如 WordNet、HowNet、《同义词词林》、知网 [8,9,10]等。 基于语言学的方法主要考虑词汇间的语义关系以及句子的语法成分来确定句子间的相似度,通常与其他相似度计算方法结合使用[11]。在深度学习盛行之后,词向量(Word embedding)、卷积神经网络(CNN)、长短时記忆(LSTM)、注意力模型等也被用于进行文本相似度计算,其基本思想是通过神经网络的方式将文本向量化后计算相似度[12,13,14, 15],目前主要应用于文本分类中。
在已有的主观题阅卷系统中,Project Essay Grade系统[16]和E-rater系统[17]针对英语写作试题进行自动阅卷,能够从句法多样性和用词能力等多个方面评判考生的文章,但是他们只是评判考生的文笔好坏,通常没有对错之分。美国教育考试服务中心采用词汇-语义技术针对短文本答案自动阅卷[18],但系统对词典所涵盖词语的数量要求较高。Automated Text Marker (ATM)系统[19]对答案进行了语法分析和语义分析并引入同义词词典。AutoMark系统 [20]利用模板考虑了所有可能出现的正确或错误答案。高思丹等提出了基于动态规划的语句相似度计算方法,对句子进行浅层句法结构分析用于主观题阅卷[21]。张添一等运用基于知网的词汇语义相似度计算方法比较学生答案与标准答案文本的语义相似度,并针对政治学科主观题自动阅卷进行实验[22]。张均胜等[23]结合人工制定文本相似标准,利用统计方法设计并实现短文本主观题阅卷系统。
与上述方法不同的是,本文面向的对象是数学主观题,其长度介于长文本和短文本之间,蕴涵多个字母符号、语言表达灵活等数学特性较为突出,缺乏与之相关的语料库或者知识库可以使用,其句式或者语义表达也难以应用自然语言处理中常用的句法分析或者语义分析。因此需要针对性地采取措施来衡量学生答案和教师答案之间的语义相似性。本文将人工评分标准中的关键短语与Bi-LSTM相结合来计算学生答案和教师答案之间的相似度,既考虑了人工阅卷的标准,又利用深度学习来捕获隐含的语义信息,通过Bi-LSTM对文本进行字符级编码,设计目标函数,完成数学主观题的自动阅卷。
3 基于Bi- LSTM的数学主观题阅卷方法
数学主观题的自动阅卷可以归结为标准答案和考生答案语义相似度计算问题。如果考生答案文本和试题标准答案文本语义对等,则相似度为1;如果考生答案和试题标准答案语义上毫不相干,则相似度为0;通常考生的答案和试题标准答案语义相似度介于0和1之间,两者之间相似度越高,则考生得分越高。对于具体的题目而言,若题目总分为10分,通过进行相似度计算,得到0.7,则该学生答案判定为7分。
3.1数学主观题的特点
3.1.1多种解法并存
数学主观题经常存在多种解题思路。例如考察立体几何的主观题,可以使用综合分析法,也可以采用向量法。即使是一种解题思路的某一个步骤也经常有多种证明方法。为此在主观题阅卷时要考虑到多种标准答案的评分。
3.1.2符号文字掺杂,公式分布广泛
数学主观题中,通常会使用各种大小写的字母来表征几何图形中的点、线、平面,或者代数中的函数及其运算。在几何题目中,无论是学生答案还是教师答案,其中的每个语句中都掺杂着符号和文字,其中等式或者方程能占50%的篇幅以上。
3.1.3数学公式多样表达
数学主观题中,各类数学公式的表达多种多样。例如几何题目中,同样一条直线,表达可以多个版本,对于学生自己添加的辅助线,经常由不同的字母来表征,即使是题目中给出的线段,虽然使用了相同的字母,也有顺序和逆序两种表达。有的公式经常具备二维的特性,例如分式、矩阵等,需要采用一定的规则使其线性化,才有利于后续的提取特征和相似度计算。
3.1.4文本长短不一
数学主观题的答案,其文本长度没有定式,有的只需十几个字,有的需要写满半篇试卷。因此,直接使用神经网络的方法来模拟其中的语义是困难的,需要采取针对性的手段。
3.2线性化规则
为了方便后续的文本处理,对于学生答案和教师答案都需要制定规则,去掉其二维的特性,使其线性化又保证没有歧义。线性化规则中,对于数学符号,尽量使用文字表示,同时了结合Latex的某些规则。表1列出了部分线性化规则。
3.3人工评分关键短语
数学主观题进行评分之前,通常需要教师给出标准答案,每道题会有多种解题思路,每种解题思路有多个得分点,每一个得分点由于语言表达的多样性可能会有多种不同的表示。针对某一特定题目,将每个标准答案的编号分别记为a1,a2,……at。对于某一标准答案at,存在多个得分步骤,每个得分步骤分别记为at-1,at-2,… at-n。针对每个得分步骤的重要程度给出其相应的分值比重,所有得分步骤的分值比重和应小于或等于100%。每一得分步骤at-n,提取出多个关键短语, 每个关键短语的编号分别为at-n.1,at-n.2,……at-n.m (m>=1)。对于关键短语at-n.m,采用其等价陈述来扩展其多样表达,用 at-n.m-1,at-n.m-2,…at-n.m-s(s>=1)形式编号。
3.4多种解法选择方案
针对一题多解问题,在进行主观题评分之前,必须为该题目的不同学生的答案选择对应的参考答案,目的是为每个学生答案确定出唯一的参考答案。
在此处笔者利用每个标准答案的关键短语作为不同解法的特征,采用一元文法(uni-gram)+分词方法将学生答案和不同标准答案的关键短语做模糊匹配,选择匹配最佳的解法作为该学生答案唯一的参考答案。
例如标准答案有两个,这两个标准答案的关键短语如下:
解法1:角BAC等于角DCE、AC垂直于DE……
解法2:AC平行于FG、DE垂直于FG……
学生答案:由于AC平行GF,DE又垂直于GF,故AC垂直于DE得证
对两个解法的关键短语以及学生答案分别进行单字符分词和普通分词,再进行模糊匹配,则解法1匹配成功的元素有“于、A、C、AC、D、E、DE”,解法2匹配成功的元素有“A、C、AC、平行、平、行、F、G、D、E、 DE、垂直于、垂、直、于”,解法2的匹配率大于解法1,故该学生答案选择解法2作为唯一标准答案。
3.5 多策略融合的相似度计算
评分过程实际上是对考生答案和教师答案进行相似度计算的过程。
利用关键短语可以计算相似度,将考生答案和教师答案中的关键短语分别进行匹配计算得分,作为最终评分结果。其评分公式为:
4 实验与讨论
数学主观题自动阅卷实验的目的是考察自动评分算法的效果,将自动评分结果与教师手工阅卷评分结果相比,评价自动评分结果的准确率。评价的指标是自动评分分值与教师手工阅卷分值之间的差距。在实验中,总分为5分的试题,评分分值相同或差1分,即认为评分结果准确。
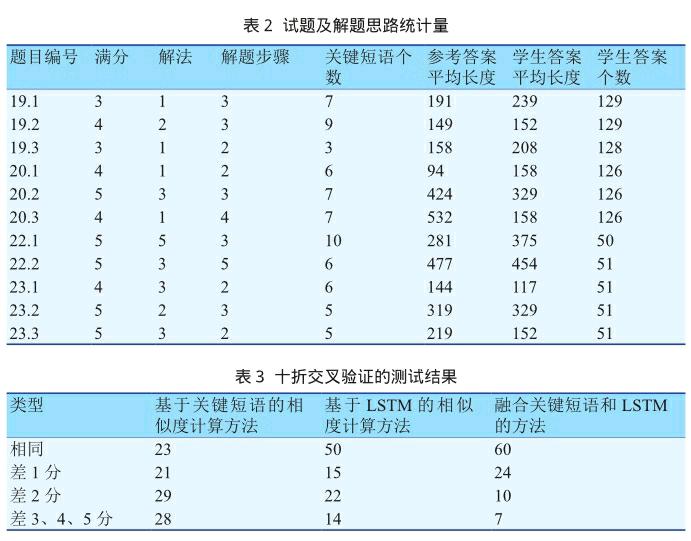
实验数据包括:从北京十一学校高二年级第二学期(2017年春季)期末数学考试的试题中,抽取立体几何类型的题目共11小题,人工制定多种解题思路及评分标准。试题及教师答案的统计量见表2。

将上述共1018个学生答案进行模糊匹配,得到每个答案唯一对应的参考答案,并将其与得分率一并作为总数据集。笔者采用十折交叉验证法,按顺序每次取1/10的样本(101条)作为测试集,其他的答案作为训练集,按照第3节中的相似度计算方法进行评分,最终取十份测试集阅卷结果的平均值用来衡量自动阅卷方法的有效性。自动评分结果如表3所示。评分结果显示,仅仅利用关键短语进行相似度计算,评分相同或者差一分的题目数量为44个,占43.56%。利用LSTM的相似度计算方法,评分相同或者差一分的题目数量为65个,占64.36%。两者融合的相似度计算方法,评分相同或者差一分的題目数量为84个,占83.17%,见表3,表3说明:
第一,仅仅使用关键短语的相似度计算方法由于考生答案和关键短语匹配成功不是特别高,造成比较多的误判,因此偏差2、3、4、5分的数量较多。尽管如此,这种显性知识是对自动判卷极为有用的。
第二,使用Bi-LSTM的相似度计算方法在阅卷中可以充分挖掘出句子的语义信息,从而得到较好的结果。可以看到“相同”和“差1分”的比例已经明显增加。
第三,将前两种方法融合起来,有效利用显性知识和深度学习的隐形语义知识,得到了很好的阅卷结果,其中错判的现象明显减少。
通过对评分差异较大的题目进行分析,发现由于考生答案长度过大,同时参考答案长度也比较大,句子太长导致LSTM效果“失灵”,造成误判以及评分差异较大。因此需要改进LSTM模型,尤其针对长句子进行层次结构的编码。其次当前训练样本数量仍然较小,需要增加数据量。同时可以考虑为关键短语构建同义词库,从汉语的语义角度进行研究,考虑句法分析和逻辑表示等。
文本主观题自动阅卷具有很强的应用需求,在各类考试考核中都具有巨大的市场。该研究的关键是提高考生答案文本和试题标准答案文本之间的相似度计算准确率,这种相似度应该包括语法、语义以及语用各个层面。本文从数学主观题的基本特性出发,提出了一种基于Bi-LSTM的数学主观题阅卷方法,将人工制定得分关键短语与深度学习相融合,并在高二年级数学期末考试的真实考题数据集上,收集学生答案进行了自动阅卷与人工阅卷结果比对实验,自动阅卷的准确率达到83.17%。本方法虽然仍需要人工制定评分标准,但对于大批量考试阅卷工作来说,该方法已经大大减少了人工的工作量,因此在辅助人工阅卷上具有较好的应用价值。
参考文献:
[1] L. X u, D. Wang, and M. Huang.“Improved Sentence Similarity Algorithm based on VSM and its application in Question Answering System.” Intelligent Computing and Intelligent Systems (ICIS), 2010 IEEE International Conference on IEEE, 2010, pp. 368- 371.
[2] 孙宏纲,陆余良,刘金红等.基于HowNet的VSM模型扩展在文本分类中的应用研究[J].中文信息学报,2007,21(6):101- 108.
[3] Peter W. Foltz, Walter K intsch, and T homas K Landauer. “T he measurement of textual coherence with latent semantic analysis.”Discourse Processes 25.2- 3(1998), pp.285- 307.
[4] Moses S.Charikar. Similarity estimation techniques from rounding algorithms. In STOC, pages 380–388, Montreal, Quebec,Canada,2002.
[5] 刘宏哲.文本语义相似度计算方法研究[D].北京交通大学,2012.
[6] Lin X ,W ang D.W ord semantic similarity research based on latent relationships[C ]//International Symposium on Instrumentation & Measurement, Sensor Network and Automation.2013:168- 171.
[7] Islam A,Inkpen D.Semantic text similarity using corpus- based word similarity and string similarity[J].ACM Transaction on Knowledge Discovery from Data, 2008,2(2): 1- 25.
[8] X u L H,Sun S T ,W ang Q.T ext similarity algorithm based on semantic vector space model[C ]/ / Ieee/ acis, International Conference on Computer and Information Science. IEEE,2016:1- 4.
[9] Mihalcea R ,Corley C,Strapparava C.Corpus- based and knowledgebased measures of text semantic similarity [C]//Proceedings of the 21st National Conference on Artificial Intelligence. Boston: AAAI Press, 2006:775- 780.
[10] 刘群,李素建.基于《 知网》 的词汇语义相似度计算[J].中文计算语言学, 2002.
[11] 李春梅,徐庆生.基于多特征的汉语句子相似度计算模型的研究[J].计算机技术与发展,2014(6):136- 139.
[12] Hu Baotian, Zhengdong Lu, Hang Li, et al. C onvolutional neural network architectures for matching natural language sentences. Advances in Neural Information Processing Systems.2014.
[13] Wang Shuohang,and Jing Jiang. Learning Natural Language Inference with LST M.[C]// Proceedings of NAACL- HLT 2016, pages 1442–1451.
[14] Ming Tan, Cicero dos Santos, X iang Bing etc.Lstm- based deep learning models for non- factoid answer selection.[J]//C omputation and Language.
[15] T im R ockt¨aschel, Edward Grefenstette, Karl Moritz Hermann, etc. R easoning about entailment with neural attention [C]//ICLR , 2016.
[16] R udner L, Gagne P. An overview of three approaches to scoring written essays by computer[J].Practical Assessment, R esearch & Evaluation, 2001,7(26).
[17] Burstein J, Leacock C, Swartz R . Automated evaluation of essay and short answers[C]//Proceedings of the 5th International C omputer Assisted Assesment C onference. Loughborough:Loughborough University,2001.
[18]Burstein N J, Kaplan R , Wolff S, et al. Using lexical semantic technicues to classify free- responeses [C ]// Proceedings of Annual Meeting of the Associatiion of Computational Linguistics. Santa Cruz: University of California, 1996:227- 246.
[19] Callear D,Jerrams- Smith J,Soh V.CAA of short non- MCQ answers[C]// Proceedings of the 5th International CAA Conference. Loughborough: Loughborough University, 2001.
[20] Mitchell T, Russell T, Broomhead P, et al. Towards robust computerized marking of free- text responses[C]//Proceedings of the Sixth International Computer Assisted Assessment C onference. Loughborough:Loughborough University, 2002.
[21] 高思丹,袁春風.语句相似度计算在主观题自动批改技术中的 初步应用[J].计算机工程与应用,2004,40(14):132- 135.
[22]张添一.基于文本相似度计算的主观题自动阅卷技术研究[D].东北师范大学,2011.
[23]张均胜,石崇德,徐红姣等.一种基于短文本相似度计算的主观题自动阅卷方法[J].图书情报工作,2014(19):31- 38.
[24] Paul Neculoiu, Maarten Versteegh and Mihai R otaru. Learning T ext Similarity with Siamese R ecurrent Networks, in Proceedings of the 1st Workshop on R epresentation Learning for NLP, pages 148–157, Berlin, Germany, August 11th, 2016.
- 基于Kinect传感器和HOG特征的静态手势识别
- 基于混沌时间序列的模糊神经网络预测研究
- 传统情感分类方法与基于深度学习的情感分类方法对比分析
- 触发词扩展、神经网络及依存分析相结合的事件研究
- 移动机器人目标物体识别研究
- 基于自动编码器与概率神经网络的人体运动行为识别方法
- 基于平滑A*人工势场法的机器人动态路径规划
- iOS开发中多线程技术的研究和实践
- 基于WF State Machine的UML Communication Diagram动态构建及测试
- 基于社会性软件的知识获取行为研究
- 大数据时代下关联规则兴趣度挖掘在就业分析中的应用
- 基于小波变换与数学形态学的图像边缘检测方法
- 基于窗口滤波与均值滤波的深度图像实时修复算法
- 基于KeilC51和Proteus花样流水灯系统的设计
- 基于学习行为和内容的网络学习论坛分析模型
- 基于改进SIFT和RANSAC的物体特征提取和匹配的研究
- 联邦搜索中基于词向量的多样化信息源选择算法
- 计算机信息技术课程在线考试系统的设计与实现
- 大型开放式网络课程在计算机教学中的应用研究
- EDA技术课程职业化的教学改革思考
- 基于OBE—TC的《面向对象系统分析与设计》双语课程教学设计
- 基于Zigbee和微信平台的智能家居系统的研究与实现
- 商业银行数据仓库系统中ETL的设计与实现
- 基于Android系统考证APP设计与开发
- 基于知识图谱的个性化学习资源推荐研究
- predominations
- predominator
- predominators
- predonate
- predonated
- predonates
- predonating
- predonation
- predonations
- predonor
- predonors
- predoomed
- predooming
- predooms
- predoubt
- predoubted
- predoubter
- predoubters
- predoubtful
- predoubtfully
- predoubting
- predoubts
- predraft
- predrafted
- predrafting
- 床帏
- 床帏事
- 床帐
- 床席
- 床帮
- 床帷
- 床幮
- 床底下关鸡
- 床底下养仙鹤——一世不得抬头
- 床底下吹号——低声下气
- 床底下吹喇叭
- 床底下堆宝塔
- 床底下堆宝塔——纵高也有限
- 床底下打斧头——不碍上就碍下
- 床底下抡大斧
- 床底下拜年——伸不直腰
- 床底下拜年——抬不起头来
- 床底下支张弓
- 床底下放风筝
- 床底下放风筝——飞不高
- 床底下放鸢子——大高而不妙
- 床底下的夜壶——难登大雅之堂
- 床底下练武
- 床底下练武——施展不开
- 床底下鞠躬