郭亚菲 樊超 闫洪涛
摘要:粮食产量的预测研究在粮食安全方面具有重要意义,神经网络可以较好地反映粮食产量这一复杂的非线性动态系统。但是传统的BP神经网络预测模型存在学习收敛速度慢、易陷入局部极小值等缺陷,为了改善这一缺陷,提出了一种基于主成分分析(PCA)和粒子群(PSO)優化神经网络的预测模型。首先计算各影响因素与粮食产量之间的相关系数,利用主成分分析方法降低影响因子的维度,将降维后的因子作为神经网络的输入,然后采用BP神经网络建立粮食产量预测模型,其中引入PSO算法对BP神经网络的权值和阈值进行优化,最后使用训练过的BP神经网络预测粮食产量值。预测结果表明,该模型可有效提高预测精度,且收敛速度快,全局收敛性好,为粮食产量预测提供了一种新的途径。
关键词:粮食产量;预测模型;主成分分析(PCA);粒子群(PSO)算法;BP神经网络;影响因素;预测精度
中图分类号: TP399;TP391.4文献标志码: A
文章编号:1002-1302(2019)19-0241-05
收稿日期:2018-07-04
基金项目:河南省科技攻关项目(编号:162102210198);国家粮食公益性行业科研专项(编号:201413001);河南省自然科学基金(编号:162300410062)。
作者简介:郭亚菲(1994—),女,河南鹤壁人,硕士研究生,主要从事粮食信息处理研究。E-mail:guoyafei0029@163.com。
通信作者:樊 超,博士,副教授,主要从事粮食信息处理研究。E-mail:anfan2003@163.com。
粮食安全在促进经济发展方面发挥着重要作用,粮食产量预测是一个重要的研究课题。由于粮食产量通常受到许多因素影响,其序列具有复杂性、随机性和非平稳性,所以对粮食产量的准确预测十分困难。那么,采用合理的方法和模型预测粮食产量变化趋势值具有重要意义。目前,粮食产量预测研究方法主要集中在2个方面:一是基于传统的统计原理的预测模型,包括遥感技术预测法、气象产量预测法[1]、动力学生长模拟法、多元回归分析法和神经网络预测法等预测模型[2-4]。这些方法虽然在一定程度上能够对粮食产量作出预测,但均不同程度地存在着所需数据量大、预测成本高、预测周期短以及预测精度不理想等缺点。事实上,即使有大量样本数据,寻找数据间的关联关系依旧困难。一是人工智能方法,如人工神经网络、遗传算法以及许多混合智能算法等[5-7]。其中,混合智能算法有更大的灵活性来解决复杂的模型,所以越来越多的研究人员倾向于使用它们来处理预测问题[8-9]。因此,本研究提出了一种基于主成分分析和粒子群优化神经网络的预测方法。BP神经网络具有非线性映射、自学习性、自适应性,采用BP神经网络预测模型可以较好地反映粮食产量的变化趋势,但是BP神经网络的误差函数存在局部极小值且收敛速度较慢等问题。考虑到影响粮食产量的因素众多,且各因素之间有一定的耦合性特点,如果直接将所有影响因子作为输入,会导致BP神经网络缺点更加明显[2-3],所以利用主成分分析从众多影响因素中挑选出主要成分[10-13],再采用粒子群(PSO)算法来优化神经网络,PSO算法结构相对简单,收敛速度比较快,用PSO算法优化BP神经网络的权值和阈值,从而提高BP神经网络的收敛速度与预测精度。这种基于主成分分析和粒子群优化神经网络的预测模型具有收敛速度快、全局收敛性好的优点,从而较好地改善了BP神经网络的收敛性能,提高了预测精度。
1 基于主成分分析的粮食产量预测模型输入序列的选择
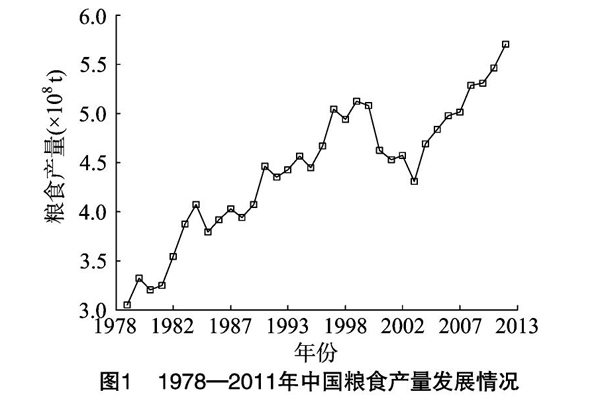
粮食产量数据属于非平稳序列,波动较大,且呈负增长性趋势。由图1可以看出,1978—2011年中国粮食总产量经历了从上升到下降再上升的变化趋势,其中1985—1996年呈现上升趋势,经过1997—1999年3年保持基本稳定后,2000—2002年又出现了快速下降趋势。因此在对粮食产量建立预测模型时,须要充分考虑其非线性与随机性特征。粮食产量的影响因子众多,借鉴其他学者的研究分析结果,选取以下几个影响因子进行研究:粮食作物播种总面积(x1)、总劳动力(x2)、化肥总用量(x3)、有效灌溉面积(x4)、用电总量(x5)、机械总动力(x6)、受灾面积(x7)、居民粮食消费量(x8)。由表1可以看出,粮食产量的不同影响因子之间有着一定的相关性,且所选取的影响因子在反映粮食产量上存在着信息重叠的现象。所以直接将以上影响因子作为输入,则有可能使神经网络更易陷入局部最小的局面。通过主成分分析可以把关联的多因子进行简化,用1个或者少数几个综合因子取代原来的影响因子,并且尽可能充分地反映影响因子的信息。
采用主成分分析方法削弱变量间的耦合,去除冗余的信息。其基本过程如下:
(1)原始粮食产量影响因子数据向量可表示为
X=(x1,x2,…,xp)。(1)
原始粮食产量影响因子数据矩阵表示为
Xmp=[JB((][HL(4]x11x12…x1px21x…x2pxm1xm2…xmp[HL)][JB))]。(2)
式中:p=8;m表示各影响因子数所对应的数。由于不同标量常存在不同的量纲,而具有不同量纲的指标之间不能进行比较,因此须要将原始数据标准化,将原始数据转化为均值为0、方差为1的无量纲数据。标准化计算公式为
rij=(xij-xi)/si。(3)
式中:i=1,2,…,m;j=1,2,…,p,且
xi=1m∑[DD(]mk=1[DD)]xki。(4)
求出p个标准化相关系数,得到相关系数矩阵R[WTBZ]
R[WTBZ]=(rij)8×8。(5)
式中:i、j=1,2,3,…,p,p=8。
(2)计算R[WTBZ]的特征根为λ1≥λ2≥…≥λp,(e1,e2,…,ep)为对应的标准正交基向量,则第i个主成分为
yi=e′X=e1ix1+e2ix2+…+epixp,i=1,2,…,p。(6)
此时有
Var(yi)=e′Rei=λi,i=1,2,…,p;(7)
Cov(yi,yk)=e′Rek=0,i≠k。(8)
(3)x1,x2,…,xp的主成分是以R[WTBZ]的特征向量为系数的线性组合,它们互不相关,其方差为R[WTBZ]的特征值。设第k个主成分的方差占总方差的比值为pk,则
pk=λk/∑[DD(]pi=1[DD)]λi,k=1,2,…,8。(9)
即为第k个主成分的贡献率。前k个主成分的累计贡献率为
lk=∑[DD(]ki=1[DD)]λi/∑[DD(]pi=1[DD)]λi。(10)
由此可计算得到上述主成分对粮食产量的贡献率和累计贡献率,结果见表2。由表2可以看出,前3个主成分的累计贡献率已经达到94%以上,表明前3个主要成分可以充分反映影响粮食产量的信息,所以可以用前3个主成分取代原来的影响因子。
(4)根据相关系数矩特征值λi及特征向量{αi},得到主成分荷载{βi}及其对应的得分{γi}。
βi=∑[DD(]pi=1[DD)][KF(]λi[KF)]αi;(11)
γi=xiβi。(12)
主成分值为
γ1=0.821 0x1-0.418 0x2-0.781 6x3+0.457 3x4+0.854 2x5-0.501 2x6-0.818 8x7+0.282 1x8;(13)
γ2=-0.412 2x1-0.781 2x2+0.440 2x3+0.790 4x4-0.420 1x5-0.806 8x6+0.341 5x7+0.810 5x8;(14)
γ3=-0.346 4x1+0.409 8x2-0.359 1x3+0.291 9x4+0.291 3x5-0.271 5x6-0.380 0x7+0.408 4x8。(15)
主成分分析将影响因子通过线性变化转换为一组互不相关的变量,从而达到降维的目的,且降低维数后的变量仍能反映原有因子的大部分信息,有利于作出更加客观、科学的评价。由图2可以看出,主成分γ1、γ2和γ3包含了影响粮食产量变化情况的主要信息,已经能够充分反映影响因子的信息。因此,将γ1、γ2和γ3 3个主成分作为预测模型的输入。
2 基于PCA和粒子群优化BP神经网络预测模型
由于粮食产量序列具有复杂性、随机性和非平稳性等特点,导致使用传统的预测方法对其进行预测时会受到很大的
影响和制约。因此,本研究提出了基于主成分分析和粒子群算法优化神经网络的方法。BP神经网络是一种利用误差反向传播训练算法的前馈型网络,是至今为止应用最为广泛的神经网络[4]。图3给出了应用最普遍的单隐层神经模型,它包括输入层、隐含层和输出层,因此也通常被称为3层感知器。
BP学习法的实质是求取网络总误差最小值的问题,具体采用“最速下降法”,按照误差函数的负梯度方向进行权系数修正。BP神经网络是由输入信号的正向传播和误差信号的反向传播2个过程组成。正向传播时,输入信号经过输入层、隐含层和输出层,前1层神经元只会影响后1层神经元的状态。如果输出层的输出与期望输出之间存在误差,则进行误差信号的反向传播。这2个处理过程交替进行,按照梯度下降的迭代更新网络的权值问题,最终使误差函数最小,从而完成信息的提取和记忆过程。作用函数通常采用S型函数,常用的激活作用函数为可导的Sigmoid函数,f(x)=11+e-x;BP神经网络通常使用的误差函数是均方差,其定义为Ek=1/2∑j(yjk-ojk)2,式中:Ek是第k个输出响应矢量的误差;yjk是第j个输出神经元的期望值;ojk是第j个输出神经元的实际值。
传统的BP神经网络预测模型存在收敛速度慢、学习效率低、对参数选择较敏感、易陷入局部极小值等缺陷;而采用粒子群算法优化BP神经网络的权值和阈值,可以改善BP神经网络的缺陷,PSO算法能够保存个体以及全局种群的最优信息,且具有算法结构相对简单、易于实现、收敛速度较快的优点。PCA-PSO-BP神经网络模型构建过程如下:(1)数据预处理。采用主成分分析对影响因子降维之后,将主成分数据γ1、γ2和γ3用于输入,对用于输入的数据进行归一化处理。
λi=0.1+0.9×γi-min(γi)max(γi)-min(γi),i=1,2,3。(16)
(2)初始化神经网络,构建神经网络。拓扑结构是神经网络基本的网络结构,基于输入数据为λ1、λ2和λ3,则神经网络的输入层设为3个神经元,输出层设为1个神经元,隐含层节点数的设定在理论上没有很好的依据,只能根據经验进行选取,因此初始值的设定将会决定网络的收敛速度和精度、局部最优解及全局最优解。
(3)对初始化参数进行设置,包括粒子的位置和速度、学习因子c1和c2等算法所需的各种参数。PSO算法将群体中的个体看作在D维搜索空间中没有质量和体积的粒子,由N个粒子组成1个群落
Qi=(qi1,qi2,…,qiD),i=1,2,…,N。(17)
式中:第i个粒子表示为一个D维的向量Qi;其速度也是一个D维的向量
Vi=(vi1,vi2,…,viD),i=1,2,…,N。(18)
位置和速度用来表示粒子的特征。
(4)采用PSO算法对种群N寻找最优粒子。不断更新粒子的位置、速度,第i个粒子迄今为止搜索到的最优位置称为个体极值,即
pbest=(pi1,pi2,…,piD),i=1,2,…,N。(19)
整个粒子群迄今为止搜索到的最優位置为全局极值,即
gbest=(gi1,gi2,…,giD)。(20)
(5)计算适应度值。适应度用于判断粒子的好坏。每个粒子以一定的速度在解空间运动,并向自身历史最佳位置p[WTBZ]best和g[WTBZ]best聚集,适应度函数设置为
fitness=k∑hi=1(ti-yi)2+b。(21)
式中:fitness为适应度函数;k和b为常数;ti表示神经网络的期望输出值;yi表示神经网络的实际输出值。本研究所采用的适应度值是预测值与实际值之间的均方误差和倒数的线性函数,其误差越小,相应的适应度值就越大,其适应性就越好。
(6)更新个体极值与群体全局极值。首先,比较计算后的每个粒子的当前适应度值与个体极值p[WTBZ]best的适应度值,如果当前粒子的适应度值优于个体极值的适应度值,则将当前粒子的位置赋值给p[WTBZ]best。然后,比较每个粒子的个体极值p[WTBZ]best的适应度值与群体全局极值g[WTBZ]best的适应度值,如果当前粒子的个体极值p[WTBZ]best的适应度值优于群体全局极值g[WTBZ]best的适应度值,则将当前粒子个体极值p[WTBZ]best赋值给g[WTBZ]best。粒子i根据以下公式来更新速度和位置
vij(t+1)=w·vij(t)+c1r1(t)[pij(t)-xij(t)]+c2r2(t)[pgi(t)-xij(t)];(22)
xij(t+1)=xij(t)+vij(t+1)。(23)
式中:c1和c2为学习因子,也称加速常数;r1和r2为[0,1]范围内的随机数;i=1,2,…,D;vij是粒子速度,vij∈[-vmax,vmax],vmax是常数;w为惯性权重。
(7)判断是否满足终止条件,即达到预期收敛精度。将得到的全局最优解应用于BP神经网络的权值和阈值;否则,重复步骤(4)~(6),直到终止准则满意为止。
(8)仿真预测。采用构建好的、具有最优权值和阈值的BP神经网络进行预测。PCA-PSO-BP神经网络预测模型原理如图4所示。
3 结果与分析
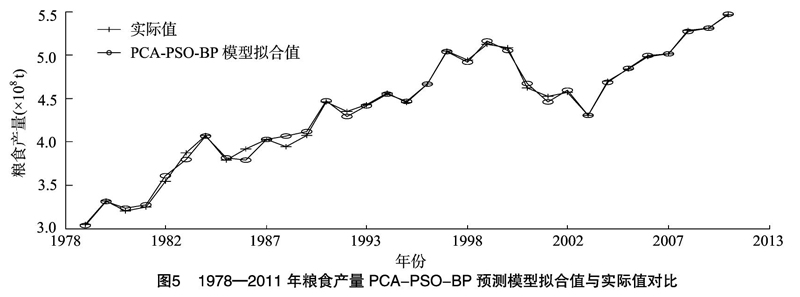
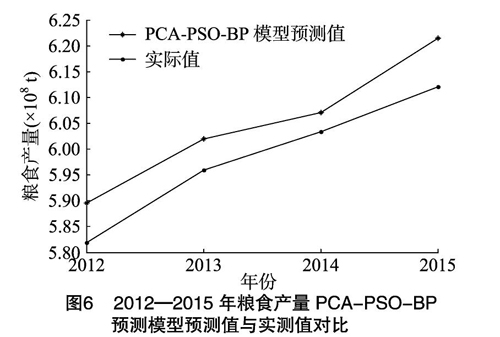
本研究以1978—2015年的粮食产量数据为基础,将样本数据分为训练样本和检验样本2个部分。选择1978—2011年的粮食产量作为训练样本,以2012—2015年的粮食产量数据作为检验样本,使用神经网络工具箱的功能newff实现BP网络的建设、训练和仿真。由图5、图6可以看出,PCA-PSO-BP预测模型较好地拟合了粮食产量的动态发展过程,并较好预测了未来粮食产量的发展趋势。
本研究同时建立了BP神经网络预测模型、PSO-BP神经网络预测模型、PCA-PSO-BP预测模型对粮食产量(2012—2015年)进行预测,3种模型的试验结果如表3所示,相较于前两者预测模型,本研究所采用的PCA-PSO-BP预测模型在预测效果上更好。
从图7和表4可知,BP神经网络预测模型的精度在每个预测年份都是最低的,4年的平均相对误差为4.1%。PSO-BP 神经网络预测模型对BP神经网络模型进行了优化,
预测精度有所改善,相对误差为3.7%;但是相对误差波动较大,在0.8%~2.4%之间变化。PCA-PSO-BP神经网络预测模型因为输入节点减少,较好地处理了模型的复杂程度和适用范围能力的联系,不仅训练速度提升,预测精度也得到了较好的提升。在3个网络模型中,PCA-PSO-BP网络模型的预测精度是最高的,且预测效果最优,平均相对误差为1.1%。说明PCA-PSO-BP网络模型能更好地拟合出产量数据曲线,且预测精度最好,平均相对误差最小,整体结果最佳。
4 结论
粮食安全对国民经济和社会发展具有重要作用,粮食产量的预测研究在粮食安全方面意义重大。由于粮食产量序列具有复杂性、随机性和非平稳性,导致使用传统的预测方法对其进行预测会受到很大的影响和制约。粮食产量是一个复杂的非线性动态系统,而神经网络具有强大的非线性映射能力,可以达到任何复杂的因果关系。本研究提出的模型很好地改善了传统的BP神经网络预测模型存在学习收敛速度慢、易陷入局部极小值等缺陷。通过对粮食产量的影响因子进行分析,使用主成分分析将影响因子降维,获得影响粮食产量的主要影响因子,并且引入PSO算法对BP神经网络的权值和阈值进行优化,用于粮食产量的预测。仿真试验结果表明,PCA-PSO-BP神经网络模型比单一的BP神经网络模型和PSO-BP神经网模型具有更快的收敛速度和更高的预测精度,改善了传统的BP神经网络预测模型存在学习收敛速度慢、易陷入局部极小值等缺陷,论证了可行性及其有效性。
参考文献:
[1]王建林,王宪彬,太华杰. 中国粮食总产量预测方法研究[J]. 气象学报,2000,58(6):738-744.
[2]张成才,陈少丹. BP神经网络在河南省粮食产量预测中的应用[J]. 湖北农业科学,2014,53(8):1969-1971.
[3]樊 超,郭亚菲,曹培格,等. 基于主成分分析的粮食产量极限学习机预测模型研究[J]. 粮食加工,2017,42(2):1-5.
[4]曾维军,张建生,郑宏刚,等. 粮食生产投入与产量关系的协整分析[J]. 生态经济,2016(2):127-132.
[5]丁 华,杨耀旭. 河南省粮食产量影响因素的实证分析——基于多元线性回归计量经济模型[J]. 粮食科技与经济,2015,40(3):10-13,19.
[6]樊 超,杨 静,杨铁军,等. 基于小波变换灰度模型-人工神经网络(GM-ANN)组合的粮食产量预测模型[J]. 江苏农业科学,2016,44(12):390-393.
[7]樊 超,曹培格,郭亚菲. 灰色极限学习机预测模型[J]. 江苏农业科学,2018,46(5):212-214.
[8]曹培格,樊 超. 基于灰色ARIMA组合模型的小麦产量预测[J]. 粮食加工,2017,42(6):1-4.
[9]何延治. 基于时间序列分析的吉林省粮食产量预测模型[J]. 江苏农业科学,2014,42(10):478-479.
[10]候彦林,郑宏艳,刘书田,等. 粮食产量预测理论,方法及应用[J]. 农业资源与环境学报,2014,31(3):205-211.
[11]张 浩,王国伟,苑 超,等. 基于AIGA-BP神经网络的粮食产量预测研究[J]. 中国农机化学报,2016,37(6):205-209.
[12]郑建安. 主成分和BP神经网络在粮食产量预测中的组合应用[J]. 计算机系统应用,2016,25(11):274-278.
[13]申瑞娜,曹 昶,樊重俊. 基于主成分分析的支持向量机模型对上海房价的预测研究[J]. 数学的实践与认识,2013,43(23):11-16.
- 旅游电商网站评价体系构建及实例分析
- 廊坊市创新型城市指数比较分析研究
- 粤港澳大湾区背景下广州国际灯光节的协作与发展
- 以开发盛京文化加快沈阳历史文化名城建设的思考
- 北部湾沿海地区生产性服务业空间布局研究
- 泉州市人才集聚中的政府行为研究
- 浅谈国际湾区经验对粤港澳大湾区建设的启示
- 石狮服装产业建立共享工厂平台的必要性研究
- 加快特色小镇建设推动广西县域经济发展
- 公共经济视角下江苏省乡村建设问题研究
- 基于电商扶贫的农村电商发展现状分析
- 基于陆路交通格局的休闲农业发展研究
- 高速公路人力资源管理体系的构建途径思考
- 商业地产企业人才激励机制创新分析
- 转型高校市场营销人才培养模式创新研究
- 民族节庆旅游资源保护意愿的影响因素研究
- 重庆市奉节县白帝镇脐橙产业发展现状调查研究
- 改革创新构建大格局旅游发展贡献新动力
- 江苏省文化旅游产业结构优化策略研究
- “大花园”建设背景下浙江全域旅游竞争力评价及融合发展研究
- 精准扶贫导向的欠发达地区生态旅游促发展调研报告
- 旅游特色小镇游客感知形象与投射形象对比研究
- 闯关东影视基地乡村智慧旅游顾客满意度研究
- 中国旅游创新与旅游经济增长的关系
- 以文兴业:文旅融合时代下旅游特色小镇建设路径探究
- unrespectfulness
- unrespectfulnesses
- unrespirable
- unrespired
- unrespited
- unresplendent
- unresplendently
- unresponding
- unresponsible
- unresponsibleness
- unresponsiblenesses
- unresponsibly
- unresponsive
- unresponsively
- unresponsiveness
- unrest
- unrestfully
- unrestfulness
- unrestfulnesses
- unrestitutive
- unrestorable
- unrestrainable
- unrestrained
- unrestrainedly
- unrestrainedness
- 隐谷
- 隐豹
- 隐贼
- 隐赈
- 隐跃
- 隐跃其词
- 隐跃其辞
- 隐跃跃
- 隐身
- 隐身技术
- 隐身符
- 隐身符儿
- 隐身草
- 隐身避害,苦练功夫
- 隐身飞机
- 隐车族
- 隐轸
- 隐辚
- 隐辟
- 隐过
- 隐进
- 隐迹
- 隐迹埋名
- 隐迹潜踪
- 隐迹藏名