
摘 要:经典的视觉里程计系统提取稀疏或密集的特征并匹配以执行帧到帧的运动估计,但是都需要针对它们所处的特定环境进行仔细的参数调整。受深度网络的最新进展和以前关于应用于 VO 的学习方法的启发,探索了使用卷积神经网络来学习视觉位姿估计任务。通过对公开数据集进行实验,验证方法性能。最后,对算法进行总结分析并对展望其发展趋势。
关键词:视觉里程计;位姿估计;深度学习; 卷积神经网络
DOI:10.16640/j.cnki.37-1222/t.2019.21.083
0 引言
视觉里程计[1],也称为帧间估计,是视觉SLAM[2](simultaneous localization and mapping)中的核心内容。经典的基于几何的视觉里程计方法分为特征点法与直接法。但是其依据于大量的计算,并且估计结果对相机参数极为敏感。近年来,人工智能、深度学习再次掀起了热潮,基于深度学习的视觉任务丰富多样,在分类、跟踪等问题上都取得了很好的效果。但是多学习外观特征,而视觉里程计需要学习图片的几何特征。
本文提出了一种基于卷积神经网络的视觉里程计方法,将数据集进行预处理,将图片序列中相邻的两张RGB图片进行串联,每张图片的通道数为3,得到一个通道数为6的张量,输入到神经网络中。参考Vgg网络结构进行特征提取工作。将提取的特征输入到全链接层将张量压缩为位姿特征向量。通过KITTI数据集进行实验,输出图片之间的相对位姿,并转化为绝对位姿和地面真实轨迹进行对比。
1 相关内容
1.1 经典的几何方法
经典的几何帧间估计方法有着悠久的解决方案设计的历史。最开始是基于稀疏的特征跟踪,研究者们设计了很多具有鲁棒性的角点、边缘点、区块等比较有代表性的点的特征提取与匹配的算法,在这些特征的基础上估计相机的运动,如SIFT,SURF,ORB等。Eigel[3]等人开发了最经典的直接方法之一LSD-SLAM。直接方法在过去几年中得到了最多的关注,Mur-Artal等人的ORB-SLAM[4]算法进行稀疏特征的跟踪也达到了令人印象深刻的鲁棒性和准确性。
1.2 深度学习法
深度学习采用端到端的方式进行大量的自动学习,并尝试从数据中推断它们。从学习方式分为有着明确标签的有监督学习(supervised learning)与没有明确标签采用聚类的思想的无监督学习(unsupervised learning)。Posenet[5]利用卷积神经网络(CNN)实现相机姿态估计,训练卷积神经网络从一个单一的RGB图像回归相机的姿态,并在大型室外场景与室内场景进行实验。Walch[6]在其去掉全连接层2048维的输出向量基础上加入循环神经网络架构实现相机姿态回归,捕捉像素关系。DeepVO[7]由两个并行AlexNet的级联卷积层组成并在末端串联,提取图片的低级特征到高级特征。
2 算法结构
2.1 基于CNN的特征提取部分
将连续的两张图片串联为6个通道进行特征提取,卷积层卷积核全部使用3×3的卷积核和2×2的池化核,其中两个3×3卷积层的串联相当于1个5×5的卷积层,3个3×3的卷积层串联相当于1个7×7的卷积层。其中3个3×3的卷积层参数量只有7×7的一半左右,有效的减少了参数量。由捕捉大的特征逐渐到捕捉小的特征进行过渡。
通过多个小的卷积核堆叠来替代大的卷积核,增加了非线性激活函数,这有效的增加了特征学习的能力。
2.2 全连接层
在卷积层后面加入全连接层,将特征张量的维度降下来。以输出6维度的相机位姿。隐藏单元数为4096,1024,512,128,最后压缩为6维的表示图片之间相对位姿的特征向量。全连接层后面也连接着非线性激活函数。整体的网络结构如图1所示。
2.3 损失函数
3 实验
3.1 实验平台与特征提取过程
实验平台为显卡RTX2080ti一块,ubuntu16.04操作系统。在开源框架pytorch上实现。
选择KITTI数据集进行实验,采用有监督的学习方法。将数据集中gps等采集的变换矩阵表示的位姿转化为3维的平移与3维的欧拉角表示,更利于反向梯度传输。首先将数据集计算图片的均值与标准差,对其进行归一化处理。
3.2 訓练过程
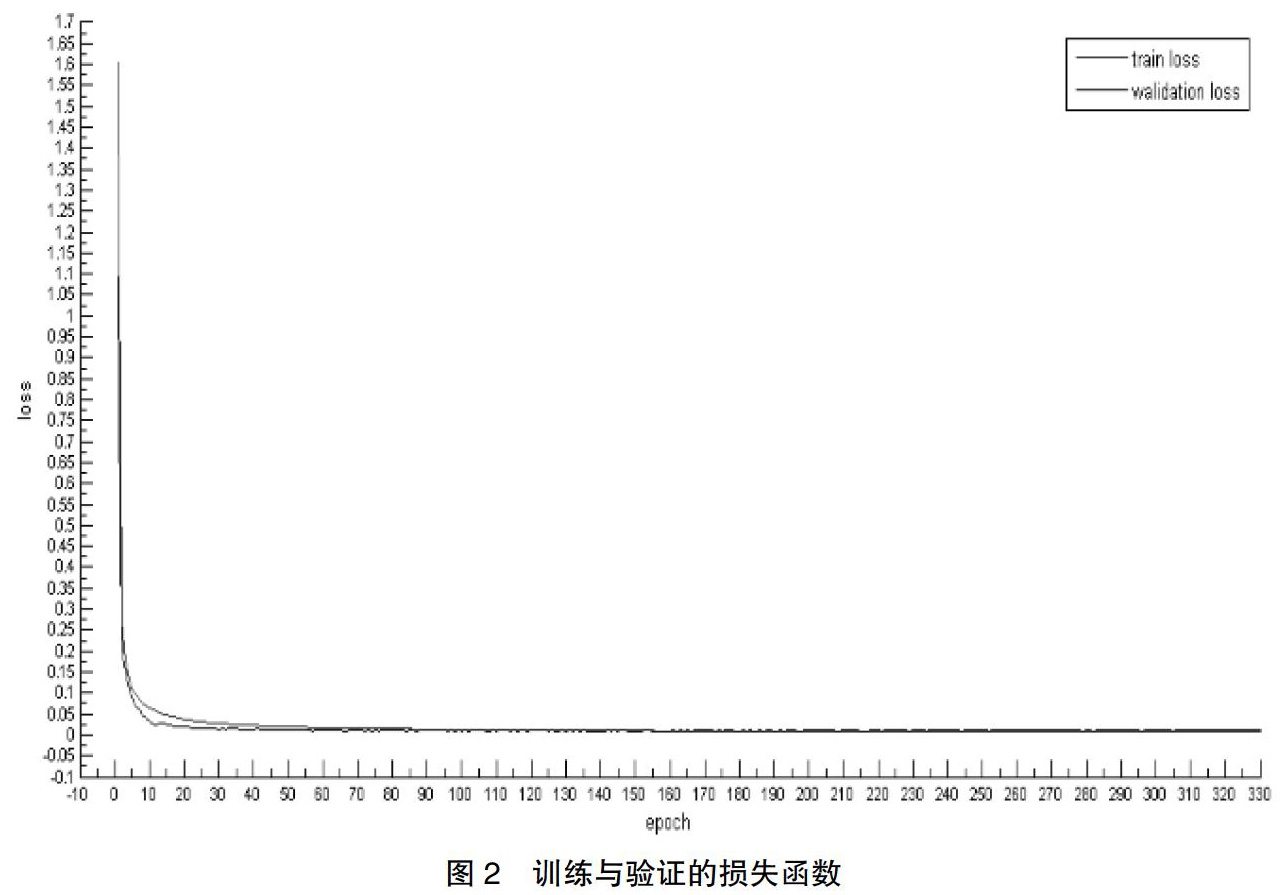
网络在00,01,02,08上进行训练,验证数据集按照0.2的比例分割来源于训练集的。采用Adam优化算法,设置初始学习率为0.0005。batch梯度下降方法,Batchsize为16。网络训练一个epoch大概需要5分钟,模型的验证误差与训练误差整体收敛到一个较小的范围大概需要130epoch,约26小时。训练与验证的损失曲线如图2所示,其中红色代表随着迭代次数增加的训练损失,蓝色代表随着迭代次数增加的验证损失,可以从损失函数曲线看出,两个损失都可以收敛到较好的范围并且相差不多。
3.3 测试过程
按照场景由训练得到的模型进行测试,在每个文件夹所处的序列图像中,将图片堆叠输入到网络中,得到预测的相对姿态,有姿态解算将得出的相对姿态转化为绝对姿态,并计算平移损失、旋转损失以及总损失。
如图3所示。绿色的为KITTI上GPS等得出的位姿作为真实地面轨迹。红色的为KITTI数据集通过深度神经网络测试得到相对姿态并进行姿态解算得到的相对于第一帧的绝对姿态。
随着训练epoch的增加,测试模型的误差一直在减少,画出的轨迹收敛性也有明显的提升,图3中的轨迹是训练到130epoch时,得到的均匀较好的轨迹曲线。从几个测试的序列看出,基于卷积神经网络的位姿估计方法都获得了准确的轨迹形状,但都存在轨迹漂移的现象,和经典的位姿估计方法如ORB得到的轨迹准确度还有差距。基于深度神经网络的视觉位姿估计精度仍需提升。
4 结论与发展趋势
本文提出了一种基于卷积神经网络的视觉位姿估计方法。将两张原始的RGB图片以串联的方式输入到神经网络中。经过实验发现在训练过程的参数设置很重要,合适的参数会使得网络得到好的收敛,并测试出好的结果。在训练保存出较好的模型及优化器下性能较优,位姿估计较为准确。但是其和经典的几何方法算法性能还有待提高,但是可以作为其有效的补充。
实验可以将数据集进行扩充,使得在相机面临丰富运动时更加准确。可以采用新的视觉传感器,如对光线或天气变化十分敏感,探索新的传感器融合。将后端优化,闭环检测或整体过程基于深度学习实现的研究还相对更少,但是其是提高基于深度学习的相机位姿估计性能的有效途径。
参考文献:
[1]NISTER D,NARODITSKY O,BERGEN J R.Visual odometry[C].Computer Vision and Pattern Recognition,2004.CVPR 2004.Proceedings of the 2004 IEEE Computer Society Conference on.IEEE,2004.
[2]BIRK A,PFINGSTHORN M.Simultaneous Localization and Mapping (SLAM)[M].Wiley Encyclopedia of Electrical and Electronics Engineering.John Wiley & Sons,Inc.2016.
[3]ENGEL J,THOMAS Sch?ps,CREMERS D.LSD-SLAM:Large-Scale Direct Monocular SLAM[C].European Conference on Computer Vision.Springer,Cham,2014:834-849.
[4]MUR-ARTAL R,MONTIEL J M M,Tardos J D.ORB-SLAM: a versatile and accurate monocular SLAM system[J].IEEE Transactions on Robotics,2015,31(05):1147-1163.
[5]KENDALL A,GRIMES M,CIPOLLA R.PoseNet:A Convolutional Network for Real-Time 6-DOF Camera Relocalization[C].IEEE International Conference on Computer Vision.2015.
[6]WALCH F,HAZIRBAS C,Leal-Taixé,Laura,et al.Image-based Localization with Spatial LSTMs[C].2016.
[7]MOHANTY V,AGRAWAL S,DATTA S,et al.DeepVO: A Deep Learning approach for Monocular Visual Odometry[C].2016.
基金項目:武器装备军内重点科研项目资助
作者简介:吴凡(1995-),女,河北保定人,硕士研究生,主要从事机器视觉与深度学习方面的研究。
- 小学数学教学中渗透模型思想的思考
- 小学数学教学中数形结合思想的渗透研究
- 数学教学方式与小学生学习心理状态适应性研究
- 基于核心素养下的小学数学计算教学
- 培养数学核心素养观念下的概念教学
- 小学数学教学生活化策略
- 小学数学差异性教学实践性研究
- 关于如何提高低段学生数学口算能力的研究
- 浅议高中美术如何有效实施模块教学
- 拓展训练在中学体育教学中的应用探究
- 将“实践”进行到底
- 生命教育在个案社会工作课程教学中的运用
- 基于自媒体的职校生篮球运动精准教学研究
- 基于Android的移动端测试环境搭建
- 数学游戏在初中数学课堂教学中的作用
- 浅谈数学思想对初中数学教学的重要性
- 互动式教学在高中数学教学中的应用
- 数学建模对经济发展促进作用的探究
- 谈提高初三学生数学运算能力的有效方法
- 浅谈高中数学教学中对学生创造性思维能力的培养
- 基于创新的初中数学教学思考
- 导学互动在初中数学教学中的实际应用
- 初中数学应用题的审题技巧指导
- 立足数学课堂维度,培养学生核心素养
- 中职数学解题教学策略
- x-ray crystallographer
- x-rayed
- x-raying
- x rays
- x-rays
- x-ray²
- x-ray¹
- xtn
- x, x
- xylem
- xylems
- xylophone
- xylophones
- xylophonic
- xylophonist
- xylophonists
- y
- ya
- yacht
- yachted
- yachter
- yachters
- yachtier
- yachtiest
- yachting
- 湖广熟,天下足。
- 湖广话
- 湖底的鱼
- 湖底的鱼——打不起来
- 湖心落石——圈套圈
- 湖水
- 湖水封冻
- 湖水演沔
- 湖水的反光
- 湖水虽然能照出月亮和星星,却不知道自己的深浅
- 湖沼
- 湖泊
- 湖泊水文学之父
- 湖泊沼泽
- 湖泽
- 湖海
- 湖海元龙
- 湖海气
- 湖湘
- 湖滨
- 湖田
- 湖畔
- 湖畔派
- 湖畔诗社
- 湖目