摘 要:为解决学生管理信息系统课程学习中存在的问题,结合微课程教学,提出大数据环境中管理信息系统个性化学习机制,以提高学生学习兴趣。通过对学习用户行为数据的获取、存储、清洗、挖掘,由改进的余弦相似度算法计算出微课程的相似度,向用户推荐其喜欢的微课程。实验证明,该机制可以有效提升管理信息系统学习中微课程推荐的准确性,增强用户黏性,达到个性化学习的目的。
关键词:管理信息系统;大数据;个性化学习
中图分类号:TP303
文献标识码:A 文章编号:1672-7800(2015)005-0017-04
作者简介:余小高(1969-),男,湖北咸宁人,博士,湖北经济学院信息管理学院教授,研究方向为大数据、管理信息系统、商务智能。
0 引言
当前,管理信息系统课程成为我国各大院校经管类专业的核心课程。在实际教学中,学生普遍觉得该课程学习难度较大;同时,教师无法针对不同专业、不同学生进行个性化教学。研究管理信息系统课程教学改革方案成为亟待解决的问题[1]。大数据为这一愿望实现提供了条件[2]。
本文结合笔者长期从事管理信息系统课程教学及微课程平台研发和数据分析的经验,提出大数据环境中管理信息系统个性化学习架构。首先,将学生海量学习行为数据进行存储;然后,利用Hadoop框架对存储数据进行处理,计算微课程之间的相似度矩阵,运用Redis存储中间
结果和最终推荐结果;最后,向用户提供微课程学习列表。
大数据发展带动了微课程迅速发展。目前,微课程已逐步影响我国信息化教学实践。湖北、广东、上海等十多个省、市、自治区纷纷开展了微课程实践。微课程实践的积累,将促进微课程群的形成,微课程群的应用又会形成新的应用数据,从而有利于大数据分析与挖掘、发现与预测的创新应用[3]。
在国内,诸多高校学者、区域教育研究者、一线教师等对微课程进行了相关研究或实践,大多关注其概念、资源设计和教学模式[4]。
近年来,国外越来越重视微课程、微视频的研究,但其核心组成资源不统一,呈现方式主要为教案或视频;课程结构较为松散,主要用于学习及培训等方面,应用领域也有待扩充;在课程资源的自我生长、扩充性还不够成熟[5]。
管理信息系统个性化学习是将管理信息系统课程制作成海量的微课程,利用个性化推荐技术,根据用户的兴趣特点及行为向用户推荐其感兴趣的学习内容。主要解决如何在海量管理信息系统微课程资源中发现用户感兴趣的内容。对于管理信息系统学习平台来说,基于大数据挖掘技术构建个性化学习系统,能有效帮助用户发现所喜欢的微课程,进行精细化和个性化学习。
1 个性化学习算法分析
1.1 算法选择
微课程相似度有如下几种算法:
(1)基本计算
Cij=|U(i)∩U(j)||U(i)|(1)
其中,Cij是微课程i和微课程j的相似度,分母|U(i)|是喜欢微课程i的用户数,而分子|U(i)∩U(j)|是同时喜欢微课程i和微课程j的用户数。
(2)余弦相似度(cosin_base) 计算
Cij=|U(i)∩U(j)||U(i)||U(j)|(2)
该算法通过降低微课程j的权重,能减轻热门微课程和很多微课程相似的可能性,从而提升推荐的质量。
(3)余弦相似度a (cosin_alph) 计算
Cij=|C(i)∩C(j)||C(i)|a|C(j)|1-a(3)
该算法进一步降低了微课程j的权重,可以根据实际应用效果指定a的取值。
(4)改进的余弦相似度(cosin_mod) 计算。
对于微课程平台来说,存在部分恶意下载用户,为了保证微课程之间相似度的可靠性,需要修正活跃用户对微课程相似度的贡献,即对同一微课程来说,已经下载了50次微课程的用户的贡献度要小于只下载了10次微课程的用户,调整后如式(4)所示。
Cij=∑u∈U(i)∩U(j)1lb(1+|U(u)|)|U(i)||U(j)|(4)
对过于活跃的用户,为了避免相似度矩阵过于稠密,在实际计算中,一般直接忽略其兴趣列表,不将其纳入相似度计算的数据集中。
(5)改进的余弦相似度的归一化
Cij=CijmaxCijj(5)
为进一步提高推荐准确度,在改进的余弦相似度计算式的基础上进行归一化,也可以提高推荐的覆盖率和多样性。在微课程平台中,选择该算法进行个性化学习。
完成微课程相似度计算后,通过式(6)计算用户u对微课程i的兴趣:
Iij=∑i∈U(u)∩S(i,k)Cijrui(6)
其中,U(u)是用户喜欢的微课程集合;S(i,k)是与微课程i最相似的k个微课程的集合;Cji是微课程j和微课程i的相似度,rui是用户u对微课程i的兴趣(对于微课程平台来说rui=1)。结合用户历史感兴趣的微课程,通过该算式,越相似的微课程,越有可能在用户的学习列表中获得比较靠前的排名。
1.2 算法评价指标
(1)精度指标:召回率(Recall Rate)/准确度(Precision)。
用户u推荐N个微课程记为N(u),用户u在测试集上喜欢的微课程集合为L(u),通过准确度/召回率评测算法的精度。召回率描述在最终学习列表中,用户数与微课程下载记录数的比例;而准确度描述在最终学习列表中,使用过微课程的用户数与微课程下载记录数的比例。召回率定义如式(7)所示,准确度如式(8)所示。
RecallRate=∑uN(u)∩L(u)∑uL(u)(7)Precision=∑uN(u)∩L(u)∑uN(u)(8)
(2)覆盖率指标(Coverage Rate)。
覆盖率表示最终推荐列表中微课的比例。如果所有微课程都被推荐给至少一个用户,那么覆盖率就是100%。覆盖率反映推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的微课程推荐给用户。采用最简单的覆盖率定义如式(9)所示。
RoverageRate=|Uu∈UN(u)||I|(9)
其中,|Uu∈UN(u)|表示对推荐给用户的微课程去重数。|I|指“微课程”平台中所有的微课程数。
(3)多样性指标(Diversity)。
多样性用来描述推荐列表中两个微课程之间的不相似性。多样性和相似性是对应的,如式(10)所示,其中S(I,j)∈[0,1]定义微课程i和微课程j之间的相似度。
Diversity=∑i,j∈N(u),i≠j(1-S(i,j))|N(u)||N(u)-1|(10)
个性化学习系统的整体多样性可以定义为所有用户学习列表多样性的平均值,如式(11)所示。
Diversity=1|U|∑u∈UDiversity(N(u))(11)
2 体系架构
2.1 数据获取与存储
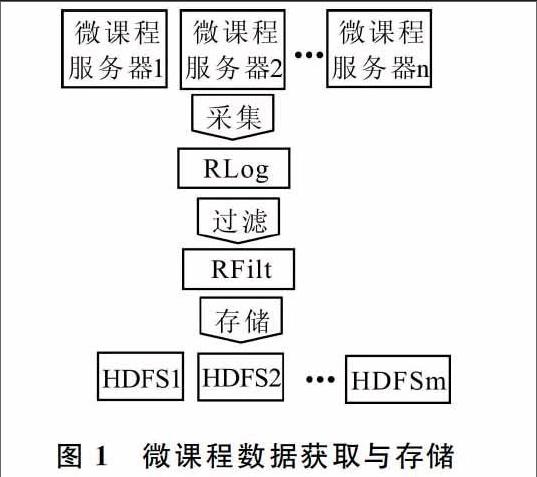
对上述个性化学习算法在湖北经济学院管理信息系统学习平台进行了实践,利用该校教研项目(2014015)“大数据背景下管理信息系统课程教学改革研究”的成果,建成了管理信息系统微课程资源库。目前,校内外用户数超过20 000户,日均数据增量1 000MB左右,数据分析需要获取数据并存储数据。微课程平台的个性化学习系统一般采用用户下载行为作为用户的行为数据,一旦用户下载了一个微课程,则视该用户对微课程产生了一个正向喜欢。数据获取与存储的架构如图1所示。
微课程下载功能由微课程下载服务器提供,当用户发出微课程下载请求时,下载服务器在本地日志上记录一条用户下载记录。采集系统RLog对日志数据进行实时、高效采集;然后传递给实时计算系统RFilt ,RFilt按照设定的规则进行数据过滤;最后将有效数据存入Hadoop分布式文件系统(HDFS )[5]进行固化。
HDFS对硬件要求比较低,能在一般服务器集群上运行,充分利用计算机的存储能力。通过HDFS的“一次写入、多次读取”机制[5],用户海量访问数据能够快速处理;通过分布式文件存储机制,能够长久地存储用户的历史访问记录,为用户行为分析提供数据支撑。
2.2 数据清洗与挖掘
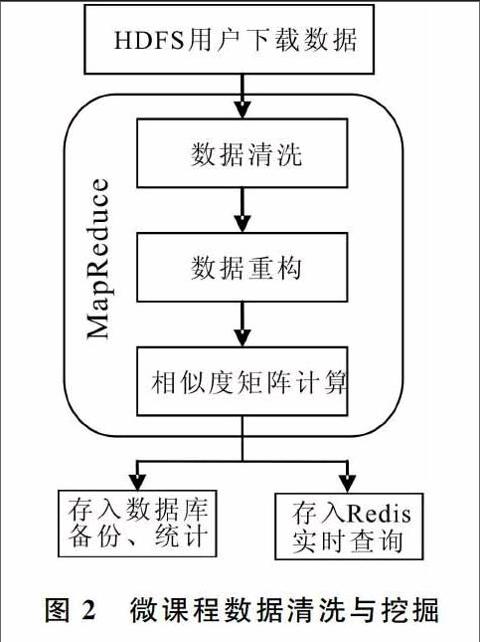
管理信息系统微课程数据清洗与挖掘如图2所示。
存储数据后,采用MapReduce计算框架[8],可以快捷地对大型数据矩阵进行计算,从而为个性化学习系统提供计算支持。首先,进行数据清洗,过滤掉非法的用户和微课程;然后,进行数据重构,将用户和微课程的标识唯一化,同时生成用户下载数表和微课程被下载次数表;最后,进行相似度矩阵计算,计算结果存储两份,一份存储在Oracle数据库中,供系统评测和统计使用,另一份存储在Redis高速缓存服务器中,为各类应用提供查询。
2.3 个性化学习流程
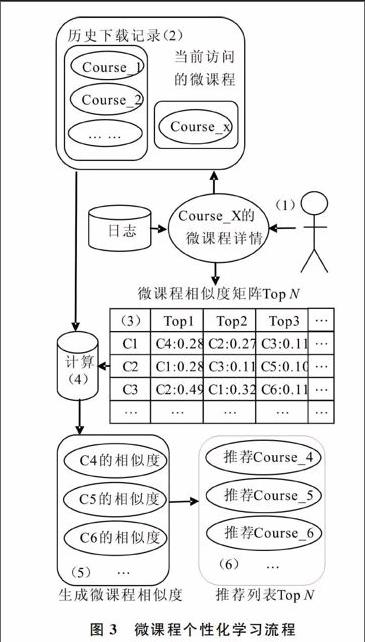
面向用户的管理信息系统微课程个性化学习流程如图3所示。
(1)用户通过客户端访问微课程平台,点击进入任意微课程详情页面。
(2)客户端发送用户访问请求至后台程序。
(3)后台程序获取用户当前访问的微课程ID,并根据用户ID来获取用户历史记录。
(4)通过Redis获取该微课程的相似度矩阵。
(5)使用个性化学习算法,根据用户相似度矩阵、当前访问微课程ID、用户历史访问微课程ID,计算用户可能喜欢的微课程列表。
(6)对用户可能喜欢的微课程列表按照相似度排列。
(7)取前TopN个微课程,并返回结果给客户端,客户端将相应的微课程显示在学习栏目中。
3 算法验证
管理信息系统学习平台目前每天的下载用户数为10 000户左右,人均下载3~5个微课程,累计3个月的用户下载数据为370万条左右,微课程相似度矩阵规模为5 000*5 000。应用余弦相似度推荐算法,对数据进行计算,结果如表1所示。
从表1可以看出,改进的余弦相似度的归一化推荐算法相对基本算法在准确率、召回率等指标上均有所提升。通过降低热门微课程的权重,能有效提升准确率和召回率。通过降低活跃用户的权重,能有效提升微课程覆盖度和多样性,从而强化个性化学习系统发掘长尾的能力。
推荐算法还有一个重要的影响因素,即向用户推荐的微课程个数,针对该因素影响情况进行针对性的效果分析,分析结果如表2所示。
由图4可知,随着微课程推荐数的增加,微课程的准确率、覆盖率明显上升,召回率则逐步下降,与实践情况相符,从而说明了算法的正确性和实用性。
4 结语
本文研究了大数据环境下,如何利用数据挖掘技术,结合管理信息系统微课程资源库,构建管理信息系统个性化学习平台,进行个性化学习。采用Hadoop框架处理数据,计算微课程之间的相似度矩阵,将中间结果和最终推
送结果存储在Redis中。根据计算结果,分析了相应算法,构建了一种适用于管理信息系统学习平台的个性化学习机制和方法,为其它平台大数据分析提供了良好的参考和借鉴。随着用户行为和微课程数据趋于多样化和复杂化,下一步研究方向是进一步拓展数据源,包括用户访问、用户已安装的应用软件、微课程的描述信息等,采用复合权重相加的方式拟合微课程相似度矩阵,并考虑不同数据
源的权重,提升个性化学习效果。
图4 余弦相似度的归一化算法效果
参考文献:
[1] 王靖.大数据时代下管理信息系统课程教学改革研究[J].中国管理信息化,2014,8(16):135-136.
[2] 陈川.基于微课程的自主学习支持系统设计与开发[D].华中师范大学,2014.
[3] 金陵.大数据与信息化教学变革[J].中国电化教育,2013,10(321):8-13.
[4] 姜玉莲.微课程研究与发展趋势系统化分析[J].中国远程教育,2013(12):64-73.
[5] 海浪,钱锋,黄祥为.基于大数据挖掘构建游戏平台个性化推荐系统的研究与实践[J].电信科学,2014(10):27-32.
[6] 梁文鑫.大数据时代—课堂教学将迎来真正的变革[J].北京教育学院学报:自然科学版,2013,3(1):14-16.
[7] SHIN-GYU KIM,JUNGHEE WON,HYUCK HAN,et al.Improving Hadoop performance in intercloud environments[J].Performance Evaluation Review,2011,39(3):107-109.
[8] FANGW,PAN W B,CUI Z M.View of MapReduce:programming model,methods,and its applications[C].IETE Technical Review,2012.
(责任编辑:陈福时)
- 让学生在快乐中感悟生命
- 巧用地理故事,优化初中地理课堂
- 利用区域地理课堂读图训练 培养学生必备地理学科素养
- 探究式教学模式在地理教学中的应用探究
- 探究高中地理教学中如何培养学生的问题意识
- 人教版高中地理必修一“太阳对地球的影响”教材分析
- 高中地理新课程案例教学探索研究
- 问题超市下,高中历史课堂教学有效性探索
- 巧寻历史与社会教学的思路
- 创新是推动高中历史教学开展的核心动力
- 高中历史课堂教学实践中的人文精神培养策略
- 当前课改背景下历史教学的改进研究
- 高中历史教学中的课堂讨论价值研究
- 浅谈初中历史魅力课堂的创设
- 浅议如何培养学生学习历史的兴趣
- 生动活泼,历史课堂不可缺少的“元素”
- 穿插图像资料 优化历史教学
- 高中历史教学中社会主义核心价值观渗透方式研究
- 如何提高初中历史课堂教学的有效性
- 浅谈历史教材中的美育资源
- 对合作学习下的高中历史课堂教学的点滴思考
- 浅谈初中英语分层教学
- 功夫在“课外”,构筑实用型英语课堂
- 英语有效合作探学模式运用的几点尝试
- 回归语言符号实践
- snakeskins
- snakewise
- snake²
- snake¹
- snaking
- snap
- snap at
- snap back
- snapback
- snapdragon
- snapdragons
- snap-freeze
- snapless
- snap out of it
- snap out of sth
- snappable
- snapped
- snapper
- snappers
- snappier
- snappiest
- snappily
- snappiness
- snappinesses
- snapping
- 四五六不懂
- 四五十岁的时期
- 四五子
- 四五点
- 四五运动
- 四京
- 四亭八当
- 四人帮
- 四人轿
- 四仙桌
- 四仰八叉
- 四仲
- 四伏
- 四休
- 四伙
- 四会五达
- 四伟人
- 四伯
- 四体
- 四体不勤
- 四体不勤,五谷不分
- 四体二用
- 四体大字典
- 四佞
- 四借