
摘 要:随着互联网中网页数量的激增,网页自动分类已经成为互联网技术中亟待解决的问题。提出一种领域向量模型的设计与构建方法,设计并实现一种针对新闻网页的基于领域向量模型的网页分类TSC(Topic Sensitive Classify)算法,从新的角度解决网页自动分类问题。首先,对大量的新闻网页URL进行分析,提取新闻网页的URL特征;然后,设计一个领域向量模型,对特定领域的新闻网页内容特征进行提取;最后,结合新闻网页URL特征和内容特征对新闻网页进行自动分类。实验结果表明,TSC算法分类效果比传统SVM和ID3等文本分类算法更优。
关键词:领域模型; 网页信息模型; 网页分类
DOIDOI:10.11907/rjdk.151342
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2015)007-0057-04
0 引言
随着互联网的快速发展,网络中的信息量呈爆炸式增长。根据CNNIC调查,截至2014年12月,中国网页数量已经达到1 899亿个,年增长率为26.6%。面对如此庞大的信息量,如何让用户从中得到对自己有价值的信息是当今互联网技术发展面临的挑战之一。
当前,大多搜索引擎在检索过程中使用关键词匹配技术,或者在关键词匹配的基础上加入链接分析以提高检索质量。该技术虽然可以提高检索的覆盖面,但无法提供更加深入、精确的检索结果。同时,由于互联网中的网页数量越来越多,对全网进行检索显然会降低检索效率。因此,在检索之前对网页进行分类尤为必要。新闻具备真实性、时效性、可读性的特点,作为获取及时信息重要途径的新闻网页更是受到了更多研究者的关注,针对新闻网页的研究具有更加广泛的应用价值。
1 文献综述
传统网页分类算法由人工方式完成,即由各领域的专家进行网页属于哪个类别的评审工作,这种方式虽然分类精度很高,但是,随着网页规模的增大,这种方式效率很低。因此,利用机器进行自动分类逐渐取代了人工分类方式。
网页分类的大部分算法是文本分类的经典算法在网页领域中的应用,主要有朴素贝叶斯、支持向量机、K近邻等。由于网页并没有统一的组织结构,导致网页中的噪音数据相对较多,给网页分类带来了挑战。近年来,诸多学者对网页的结构信息进行了研究。Furnkranz[1]使用Ripper算法对文本进行分类,准确率比使用网页局部文本提高了20%;Oh等[2]结合网页局部文本和链接网页的文本表示网页,并且基于文本相似性选择了部分于原网页较为接近的网页文本,也提高了网页分类效果;Kan等[3]提出可以使用URL作为分类特征,不将网页下载到本地,从而节省了大量时间和空间资源。
国内学者范焱等[4]提出一种用朴素贝叶斯协调分类器综合网页纯文本和其它结构信息的分类方法,实验结果证明组合后的分类器性能有一定程度的提高;董静等[5]提出了基于网页风格、形态和内容对网页分类的网页形式分类方法。
已有研究将网页特征提取工作作为网页分类的重点,然而并没有提出一种独立的特征表示方式进行拓展性研究。本文提出一种基于领域向量模型的网页特征表示方法,从一个新的角度来对网页进行分类,使得网页分类具有较强的可扩展性。
2 面向特定领域的新闻网页分类算法
2.1 领域表示方法
2.1.1 领域概述
领域一词来源于人工智能学科[6]。本文设计领域向量模型来表示领域知识。领域向量模型是判断一个网页是否属于某个领域的依据,也是网页重排序算法的基础。领域向量模型应满足以下几个特征:①能够表示该领域的基本特征,其中的元素不能再分割为更细的元素;②能够最大限度地表示该领域的大部分特征,其中每个元素都可以表示领域某一方面的特征;③领域模型中的元素不能有二义性。使用中文词汇来表示领域特征的一个挑战就是同一个中文词汇在不同领域有不同的含义,这一点在模型构建阶段需避免。
2.1.2 表示方法
通过对大量网页的分析,可以发现属于同一领域的网页文本中往往包含着一些类似的领域特征词。例如在学术领域中,“教授”、“报告”、“学院”等领域特征词有较高的出现频率,而相对应的,网页文本中如果出现了“教授”、“报告”、“学院”等词,那么网页就可能属于学术领域。于是,使用领域特征词向量的形式来表示领域,称为领域向量模型,具体表现形式如下:
Topic=(t1,t2,...,tn)(1)
其中,Topic=(t1,t2,...,tn)表示某个领域的向量模型,ti(i=1,2,...,n)是其中的元素,描述特征,每一个特征的具体表现形式为一组关键词。利用向量表示的好处如下:①表示方法较为简单;②可以很明确地看出领域的特征;③领域向量模型为网页重排序工作打基础,有利于实现相似度计算,且计算效率高。通过以上分析,特征词向量是一种合适的领域表现形式。
2.1.3 领域向量模型建立方法
领域向量模型的表示形式是特征词向量形式。其中的关键技术有网页文本提取、中文分词、统计词频、添加同义词、赋予权重等。由于中文具有一词多义的特殊性,机器剔除的效果往往达不到要求,于是在领域向量模型构建过程中加入了人工操作。步骤如下:
步骤1: 利用网络爬虫爬取特定领域的网页,提取网页内容文本,并对内容文本作中文分词。
步骤2: 对分词结果进行词频统计,并剔除其中的停用词和对于领域没有贡献的词。停用词如“的”、“啊”等,利用停止词列表将分词结果中的停止词剔除,对领域没有贡献的词,使用人工剔除方式。词频统计用平滑的方法,如式(2)。
Wtf=1+log(tf)(2)
其中,tf指词频。使用对数是为了避免词频差距太大而造成贡献值的差距过大,数字1是为提供一种平滑机制,避免出现一次的词被过滤掉,符合领域模型的特征。
步骤3:对余下的高频词进行人工处理,选取那些符合条件的词条,并根据词频来考虑是否加入到领域向量模型中,人工处理是为了消除领域模型中特征的二义性。至此,初步建立领域向量模型。
步骤4:对于领域向量模型中的每一个特征加入与领域相关的近义词,近义词的数量一般不止1个。利用哈工大信息检索研究中心同义词词林扩展版对领域中的词条加入近义词,并人工去掉与领域无关的近义词。
步骤5:为领域向量模型中的关键词赋予权重。
领域向量模型容量较小,本文设计为100维,存储载体可以选择数据库、XML文件、文本文件等。在此后的网页排序算法中需要频繁利用领域向量模型进行计算,因此将领域向量模型在系统运行时装入内存,I/O读取效率会更高。
2.2 面向特定领域的新闻网页分类算法
为面向特定领域的新闻网页重排序算法进行数据预处理,需要构建一个以领域模型和新闻特性为特征空间的新闻网页分类器。由于是针对特定领域进行网页重排序,在数据准备阶段将网页进行分类,可以让检索过程更具针对性。同时,在部署新闻聚合系统时,可以将网页分类器加入其中,在爬取过程中对网页进行归类。此外,还可以用来设计面向特定领域的主题爬虫,更加有针对性地进行爬取。
2.2.1 网页信息模型建立
网页信息通常用HTML语言描述,是基于HTML语言的半结构化文本[7]。这类文本的特点是结构清晰、内容较为丰富。本文中网页信息模型的操作对象是网页标题文本以及网页内容文本,这两类文本能够对网页的内容起到非常明确的表示作用。为方便相似度计算,使用关键词向量的形式来表示网页信息模型。具体步骤如下:
步骤1:利用网络爬虫爬取领域相关网页,提取网页内容文本,对其作中文分词。
步骤2:建立一个与领域向量模型维度相同的网页信息向量,向量中每一项初始化为0。将网页标题和网页文本的分词结果与领域向量模型进行比对,如果领域向量模型包含分词结果中的某个词,就将网页信息向量中此位置的值设置为非零项。
步骤3:根据网页文本中词出现的频率,对向量中的非零项进行加权,出现频率较高的词拥有较高的权重。
2.2.2 相似度度量方法
使用余弦相似度计算网页信息模型和领域向量模型之间的相似度,使用BM25检索模型计算用户检索关键词语网页信息的相似度。
(1) 针对所有网页,计算网页信息模型和领域向量模型的相似度。网页模型和领域向量模型可以表示为如下形式:
Topic=(t1,t2,...,tn)Web=(s1,s2,...sn)
其中,n是模型维度,ti,si(i=1,2,...,n)可以是0,若为非零项即为相应权值,网页信息模型与领域向量之间相似度计算利用余弦相似度方法,如式(3):
score2=∑ni=1ti*si∑ni=1t2i*∑ni=1s2i(3)
(2) 针对所有网页,计算用户检索关键词和网页信息之间的相似度。利用BM25检索模型,如式(4)和式(5):
score1=∑ni=1IDF(qi)*f(qi,D)*(k+1)f(qi,D)+k*(1-b+b*Davgdl)(4)IDF(qi)=lgN-n(qi)+0.5n(qi)+0.5(5)
式(4)中,qi是检索的某个关键词,f(qi,D)是在网页D中,qi出现的频率,D是网页D的长度,avgdl是网页D的平均长度,k和b用来调整精度,一般分别取2和0.75。式(5)中,N表示网页的总数目,n(qi)表示包含qi的网页的总数目。
2.2.3 网页分类特征提取
网页的特征主要包含网页内容特征、网页URL特征、相邻网页特征等。由于我们在的工作环境中,网页是由网络爬虫爬取下来的,并且进行了人工干预,这样会破坏网页的链接结构,因此不能使用相邻网页特征,本文考虑的特征主要是内容特征和URL特征。
(1) 新闻网页URL特征。表1中列出了新浪、网易、腾讯、凤凰和搜狐等5个门户网站中体育版块一条新闻的URL。
表2中列出了新浪、网易、腾讯、凤凰和搜狐这五个门户网站中几个主要板块的URL。
通过对新浪、网易、腾讯、凤凰和搜狐等门户网站URL的分析,发现这些门户网站的URL具有以下的规律:①都包含时间,在利用网络爬虫爬取的这5个门户网站17 585个网页中,含有类似时间特征的网页有17 374个,占比98.8%;②具有类似的结构;③都有相应的二级域名,并且二级域名中相应领域包含的词汇大同小异。因此,可以从这五大门户网站新闻网页的URL中得到一些可以区别一个网页是否为新闻网页的特征,从而判定一个网页是否为新闻网页。
(2) 特定领域内容特征。根据对上述门户网站主要板块新闻内容进行比较,尽管门户网站不同,但是相同板块中有很多词汇出现的次数相对来说很高,并且这些词汇对于该领域具有相对较高的区分度。因此,使用领域向量模型的构建算法,对相应板块构建相应的领域向量模型,作为网页分类的内容特征。该特征的主要作用是判定一个网页属于哪个模块。网页特征如表3所示。
3 分类实验及结果
3.1 实验数据集及评价标准
本文选取的实验数据集是由自主爬取的新浪、网易、腾讯、凤凰和搜狐五大门户网站的娱乐、体育、财经和科技板块的新闻网页。其中,使用新浪网的网页数据作为训练集,使用余下的4个门户网站的网页数据作为测试集。评价标准为分类正确率,即正确分类网页数目占所有网页数目的百分比,对比实验为传统文本分类算法ID3和SVM。
3.2 实验步骤
步骤1:建立领域向量模型。首先,利用网络爬虫crawler4j2对新浪不同领域新闻进行爬取;然后利用Java中的Jsoup3库根据标签提取网页内容文本,并利用Python中的jieba4中文分词库对提取的内容文本进行分词;然后,统计词频,并根据停止词列表去除停止词;最后,利用哈工大信息检索研究中心同义词词林扩展版加入近义词,建成合理的领域向量模型。每个领域为100维,每一维是领域的一个特征。针对娱乐、体育、财经和科技4个领域,分别构建4个领域模型,存储方式为TXT文件。
步骤2:爬取实验数据。利用网络爬虫对余下的4个门户网站的相应版块进行爬取,具体爬取的网页数目如表4所示。
步骤3 :利用URL特征判断网页是否属于新闻。使用表中的新闻网页URL特征对网页进行二元分类,如果包含时间特征和二级域名信息,就认为是新闻网页,如果只包含其中一项或者都不包含,认为不是新闻网页,并将其类别置为非新闻类。
步骤4 :使用余弦相似度计算网页信息模型与4个领域模型之间的相似度,取其中最高的相似度所属类别作为网页的类别。
3.3 实验结果
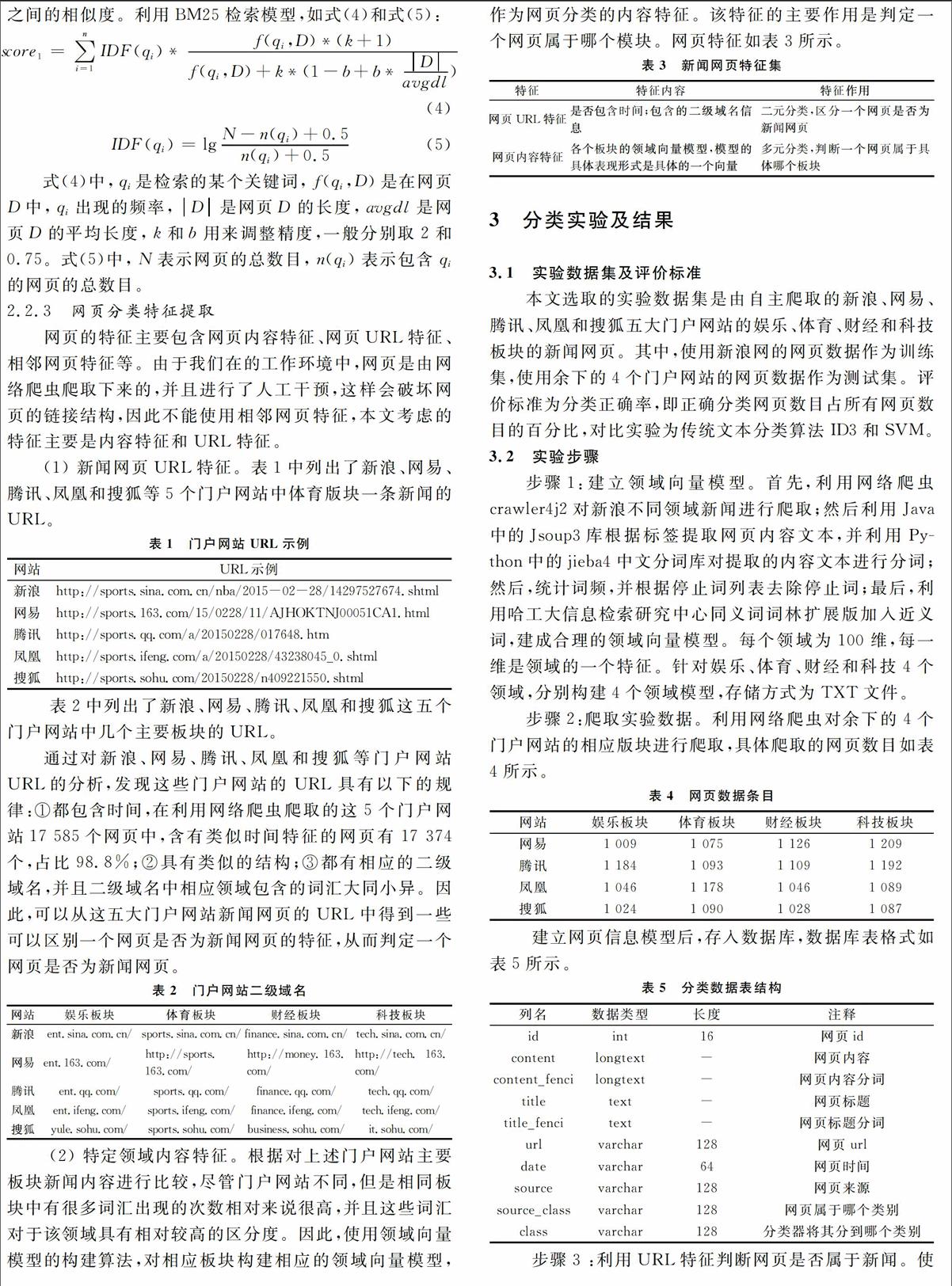
针对不同领域,分别利用TSC算法和传统文本分类算法ID3以及SVM进行对比试验,使用准确度作为评价标准,为直观起见,利用图的形式展示实验结果,如图1和图2所示。
3.4 结果评估
在娱乐领域,4个门户网站的网页分类平均准确率达到99.03%,传统文本分类算法SVM平均准确率提高0.75%,比ID3平均准确率提高0.4%;
在体育领域,对4个门户网站的网页分类平均准确率达到了99.4%,比传统的文本分类算法SVM平均准确率提高0.63%,比ID3平均准确率提高1.2%。
时,说明本文选择的特征在对新闻网页分类方面是十分有效。
4 结语
本文提出了一种领域模型的表示方法,并且通过对大量网页数据的分析,得到了属于同一领域的新闻网页所共同具有的特征,在提取特征的基础上,提出并实现了一个基于领域向量模型的新闻网页分类算法TSC。实验结果表明,TSC算法在准确率上比传统的文本分类算法有所提高。然而,本文的算法依然具有改进的余地,具体为:①可以在为领域模型赋予权重时考虑关键词的先后顺序;②可以考虑爬去具有良好链接效果的网页数据集,这样可以在特征选择时考虑网页之间的链接关系。
参考文献:
[1] FRNKRANZ J. Exploiting structural information for text classification on the WWW[M]. Berlin Heidelberg:Springer,1999:487-497.
[2] OH H J, MYAENG S H, LEE M H. A practical hypertext catergorization method using links and incrementally available class information[C].Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval,ACM, 2000:264-271.
[3] KAN M Y. Web page classification without the web page[C].Proceedings of the 13th international World Wide Web conference on Alternate track papers & posters,ACM,2004:262-263.
[4] 范焱, 郑诚. 用 Naive Bayes 方法协调分类 Web 网页[J]. 软件学报, 2001, 12(9):1386-1392.
[5] 董静, 林鸿飞, 杨志豪. 中文网页形式自动分类[C]. 第三届学生计算语言学研讨会论文集,2006.
[6] 于楠, 朱靖波, 陈文亮. 领域知识库的构建机制[C]. 第二届全国学生计算语言学研讨会论文集,2004.
[7] GLOVER E J, TSIOUTSIOULIKLIS K, LAWRENCE S, et al. Using web structure for classifying and describing web pages[C].Proceedings of the 11th international conference on World Wide Web. ACM,2002:562-569.
(责任编辑:陈福时)
- 幼儿园区域活动开展的问题与对策研究
- 浅谈农村家庭道德教育
- 基础教育学校评价:从传统模式到创新力导向
- 小学数学课堂教学与学业评价一致性研究
- 浅析师范生幼儿教学活动设计能力的训练模式
- 初中英语课堂教学中情景化教学的有效应用分析
- 关于提高小学生课外阅读有效性策略的思考
- 基于项目学习的小学语文教学初探
- 试论幼儿园食品安全管理的对策
- 运用板书提高小学语文课堂教学质量
- 高中数学学困生的成因及其转化策略分析
- 小学英语教学中的作息式记忆及其运用策略
- 新时期语文教学方法与策略探索研究
- 品质化理念下的学校治理体系与内容构建
- 厚植家国情怀,培育时代青年
- 疫情防控常态化下学生心理健康问题的缘起与应对
- “浸入式”理念下的家校协同共育实践
- 基于天津地域资源的美术教师教学塑造力研究与实践
- 党组织在教育信息化战“疫”中的作用研究
- 在高校思想政治教育中加强生命教育的研究
- 线上线下双向融合模式在小学数学教学中的应用
- 如何让小学数学课堂教学趣味化
- 初中数学教学中教师的角色定位探究
- 小学数学深度学习有效性教学研究
- 小学数学教学中实施数学理趣课堂的策略研究
- shoe²
- shoe¹
- shone
- shoo
- shooed
- shoogly
- shoo in
- shoo-in
- shooing
- shoo-ins
- shook
- shooker
- shookest
- shooks
- shoos
- shoot
- shoot down
- shoot down/bring down
- shootee
- shooter
- shooters
- shoot for
- shoot for sth
- shooting
- shootings
- 节俭则不贪,宽厚则不酷
- 节俭刻苦
- 节俭力行
- 节俭有助于养成美好的品德
- 节俭朴素,人之美德;奢侈华丽,人之大恶
- 节俭紧缩
- 节俭者能够长存,奢侈者必然败亡
- 节俭而不宽裕
- 节俭躬行
- 节俭,省俭
- 节候
- 节候不正常
- 节候更易
- 节候的流转变化
- 节假日
- 节养
- 节减
- 节创
- 节删
- 节制
- 节制之兵
- 节制之师
- 节制享乐
- 节制度量
- 节制忧愁