

摘要摘要:有效检测程序设计类课程作业抄袭现象具有重要的现实意义。传统的代码相似度检测方法主要利用代码属性或结构信息判定代码之间的相似性。基于已有的属性度量与最长公共子序列算法,提出一种代码相似度检测算法,算法将属性度量的结构无关性与最长公共子序列算法的结构依赖性有机结合。实验结果表明,该算法可以有效降低程序源代码的评测难度,得到较为可信的综合相似度值,增强了评测人员对抄袭现象的监测力度。
关键词关键词:相似度;属性度量;LCS;权值
DOIDOI:10.11907/rjdk.151921
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2015)011004305
基金项目基金项目:金陵科技学院2013年校级教育教改项目(金院字〔2013〕176号);江苏省教育科学研究所/现代教育技术研究所项目(2015R41285)
作者简介作者简介:王爱侠(1975-),女,山东高密人,硕士,金陵科技学院软件工程学院讲师,研究方向为教育管理、数据库与数据挖掘技术、图像处理。
0引言
当前的大学教育中学生作业抄袭现象比较普遍,尤其是程序设计类课程,作业是以电子文档方式存储的,学生可以直接将互联网上或其他同学的作业拷贝过来,作一些简单修改就直接交给老师,抄袭容易。国外很多教育机构针对程序设计课程的源代码抄袭现象进行的调查显示, 高达85.4% 的学生承认抄袭过别人的编程作业。教师在大量的程序作业中人工判别抄袭将是一项繁重的工作,也无法确保考核的正确性和客观性。因此,检测程序代码的相似度具有重要的现实意义,可以帮助教师检查学生中的抄袭现象,还可以辅助实现作业批改或者试卷评阅的自动化[67]。
程序代码相似度检测早在20世纪70年代初就有学者对此进行了研究。1976年,Purdue大学的Ottenstein[8]首次提出了基于属性计数法度量相似度算法——An Algorithmic Approach to the Detection and Prevention of Plagiarism。Ottenstein首次使用Halstead程序度量方法进行程序相似度识别,其开发的某系统可直接统计M.Halstead[9]提出的衡量程序长度的4个基本软件科学参数:n1,n2,N1,N2。Ottenstein认为两个程序具有相同的4个属性值的可能性是非常小的。这4个程序的参数,构成一个向量vi,设另一程序4个参数构成向量vj,则可通过计算这两个向量的夹角余弦作为其相似度。1992年,Komondoor和Horwitz提出使用切片技术进行检测[10],把语句完全相同的代码中间夹杂的不相关语句放到该部分代码的前面或后面,如此就会使两段相似的代码连成一体,形成一个更大规模的相似代码,进而能够识别出程序中的非连续完全相似代码。1996年,Verco和Wise[11]指出,对于仅仅使用属性计数法的检测算法,增加向量位数并不能改善错误率。改进属性计数法的措施就是加入程序的结构信息,结合结构度量(structure metrics)来检测相似度。
本文在已有研究的基础上,基于属性度量与最长公共子序列算法,将属性度量的结构无关性与最长公共子序列算法的结构依赖性有机结合,巧妙避开了两个算法原有的缺点,取长补短,从而得到源代码较为可信的综合相似值。
1.2相似代码分类
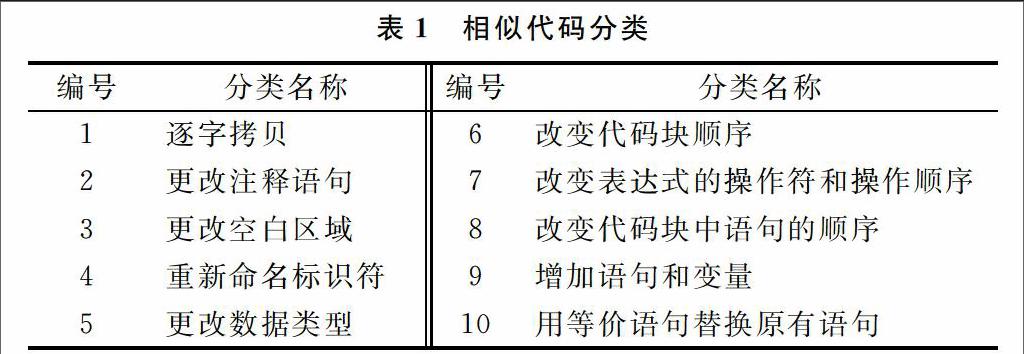
2001年,Edward L.Jones对程序相似代码之间的更改手段重新总结,在不影响程序结果的前提下,将相似代码分为10类情况[14],如表1所示。
这10种情况相对简单的解决策略如下:
(1)对于逐字拷贝产生的代码,由于源代码未作改动,或只有细微改动,对两部分代码使用最长公共子序列算法(以下简称LCS算法),将可以准确得出两代码的相似程度。
(2)对于更改注释语句后形成的代码,由于注释语句与程序功能无任何关联,只具有说明功能,去掉注释对程序的实际运行无任何影响。因此,将需要比对的两段程序去掉注释,即可得到类似于逐字拷贝产生的相似代码,对其使用LCS算法即可得出相似程度。
(3)更改空白区域与更改注释信息的行为类似,只需对源代码进行空格缩进处理,进而使用LCS算法得出相似程度。
(4)重新命名标识符后的源程序,经过编译后与修改之前的源程序产生同样的可执行程序,只对可读性有影响,因此可以对用户自定义变量进行统一替换后使用LCS算法。
(5)通常数据类型的修改都会影响到程序的执行结果,但也有部分数据类型之间存在隐式转换,绝大多数情况下对此类数据类型的修改将不影响运行结果。因此,将所有可以隐式转换的数据类型统一替换成指定的数据类型后使用LCS算法。
(6)对于更改各类语句、语句块顺序的做法,可以通过Halstead属性统计的方法来计算相似程序,该方法只统计属性的数目而不讨论其出现的位置,因而得出的结果也不受语句顺序的影响。
(7)若用户增加无用语句与变量,则需使用程序切片技术处理,在此不作深入研究。
(8)若用户使用等价语句重新书写源程序,则单从对字符数据处理已无法解决,需对程序进行语法分析处理。若用户对整个源程序重写,即使通过语法分析得出其相似,也很难将其归为抄袭,因为即使正常的代码书写,若逻辑过程一致,则其最终代码与等价重写代码也相似。
学生作业中最常见的相似代码类型为表1中的前8种,本文所研究算法将对后两种情况不予考虑,认可其中的改动部分为不相似。
由前面所述应对策略可以看出,Halstead程序度量法可有效识别出代码语句块顺序错乱的相似代码。而LCS算法则可有效识别出对于代码语句块顺序未发生改变的相似代码,若将两者优点结合,则可较为准确地识别出上述几类相似情况。
1.3解决相似的办法
目前,相似代码的检测所针对的对象主要分为两种:一种是源代码文件,另一种是将源代码进行某种形式的转换,将其转换成某种内部信息形式,例如:目标文件(.obj),然后运用检测方法分别进行比较。已有的识别方法主要分为以下3类:基于String、基于Token和基于ParseTree[15]。
(1)String:源程序以字符串为单位划分,最典型的就是按照行来划分,将这些String相互比较来发现重复的字符串序列。
(2)Token:由词法分析程序将源文件转换成Token,查找相似的Token流。
(3)ParseTree:基于源程序文件或者目标文件,建立完整的语法树,搜索树中相似的子树。
三类识别方法特性如表2所示。
本文将Halstead与LCS结合,且算法实现用于编程教学,代码量不会过大,在教学过程中,偶尔也会穿插其它编程语言。因此,使用基于String的处理方式更加合理、更易于实施。
2算法改进
基于对代码相似判定算法进行的一系列研究,以及对各种编程风格进行分析,得出下列要素:
(1)不以行为单位对源码进行分解。在用户编码风格出现差异时,若行内语句过多,行内语句间并无任何内部关联。此种情况下,以行为单位将可能导致某种极端情况,即所有语句都写在同一行上,此时,算法将退化为对整个程序进行相似分析操作,达不到预期的分块目的。因而,本文算法采取以语句为单位对源码进行处理,各编程语言普遍以“;”为语句结束标志,算法将以分号对源码进行分割处理,此举有效避免了上述的极端情况。
(2)只度量属性个数。Halstead程序度量计算法在统计整个源程序文件时,获得的度量属性频度较高,而在采取基于字符串的子句分割处理条件下,度量属性的频度取值往往较低,通常为1。为简化子句的相似度计算,提高程序运行效率,算法将只对度量属性的种类进行考量。对于频度不为1的度量属性,在本算法的处理方法下亦可得到体现。
(3)对单条语句使用LCS算法度量其结构相似度。Halstead程序度量法无法识别程序结构,但可以识别语句顺序发生改动的源码,LCS对程序相似长度进行统计,达到对结构的度量,但对于语句顺序发生变化的源码,LCS计算的相似长度将大为降低。
(4)抄袭程度计算。由于在预处理过程中去掉了注释、头文件信息,对用户变量进行统一替换,使得源程序丢失过多信息,导致判定算法对修改了此类信息的源码与未修改此类信息的源码进行同等处理。然而,对代码未作修改与稍作修改,这两种做法代表的抄袭心态有巨大差别。虽然都为抄袭,前者的行为更为恶劣。
综合以上结论,改进的算法实现具有以下特性与功能:①对输入源码进行空格紧缩处理;②将源码中的头文件信息、注释信息按照指定格式及顺序移动到冗余信息链表上,供后续处理;③将获取的用户自定义变量及数据类型进行记录后再对其统一替换;④采用基于字符串的子句分割处理,以分号作为分割条件;⑤对度量属性种类进行权值计算,以方便比较;⑥各语句片段权值逐一比较,找出最匹配的相似语句;⑦对权值相似语句排序,计算排序后的最长公共子序列长度,得出单句语句的相似程度;⑧对所有相似语句进行数据统计,得出最终代码相似度;⑨对于相似度过高的代码,将继续对其冗余信息采用类似手段考核。
改进的算法能够综合解决相似种类及解释:①逐字拷贝:由于此类程序不论在整体上、局部上以及待度量属性上都未作修改,算法能够有效识别出,而最终得出的相似度必然接近100%;②更改注释语句:由于算法将注释信息添加到冗余队列,在对程序考核之后,若程序主体相似过高,则对注释信息亦会考量,进而得出代码注释部分的相似程度,其结果与程序相似结果独立;③更改空白区域:对于空白区域,算法不对其个数进行统计从而加以区分,多个连续空格将视为一个。因而,用户对空白区域的添加或删除将不对相似程度产生影响;④重新命名标识符:程序主体相似过高时,对标识符列表进行考量,结果与程序相似独立;⑤更改数据类型:若程序主体相似过高,将对数据类型列表进行考量,结果与程序相似独立;⑥更改代码块顺序:由于算法采用局部逐一比对,更改代码块顺序将对结果无影响;⑦改变表达式中的操作符和操作数顺序:Halstead属性只对表达式中的操作符种类统计数量,改变操作符顺序对此无影响;⑧改变代码块中语句的顺序:原理同⑥;⑨增加语句和变量:算法未进行相关的程序切片处理,该做法将降低程序的相似程度;⑩用等价语句替换原有语句:算法未涉及源程序的语法分析,该做法将降低程序的相似程度。
3改进后的算法流程
在对源码进行比较前,源程序将经过预处理,剔除源码中无用信息并将此信息附加到冗余信息列表中,将源码分解成符合处理要求的形式。
单条语句的权值由操作符与关键字构成,每个操作符与关键字都具有唯一权值,所有操作符与关键字进行逻辑或操作即可得出该条语句的最终权值。
预处理流程中使用的操作符权值计算索引如表3所示。
语句以分号或大括号作为分割符,分割后的语句块作为本算法的基本处理单元。关键字被记录在指定数组中,计算模块获得待计算字符串后,设置初始权值为1,将待计算字符串逐一与数组中关键字比较,同时权值进行左移1位运算,即等效的权值乘以2,找到匹配字符后返回权值,若无匹配,返回-1表示该字符串非关键字。待判定源码与目标源码预处理结束后,程序将对两份源码的每条语句操作符权值与关键字权值逐一比较,计算出待判定源码与目标源码的关键字权值与操作符权值的最佳匹配。对于匹配值较高的源码,将语句中包含的自定义变量进行统一替换,对替换后的语句执行最长公共子序列算法,计算出公共子序列长度,然后将其值与待定源码和目标源码中长度较长的语句长度计算比值,最终获得待定源码与目标源码间的每条相似语句,程序根据代码量计算相似度,并根据用户需要,将详细结果以指定形式反馈给用户进行人工分析。流程如图2所示。
5结语
算法基于已有的属性度量与最长公共子序列算法,将属性度量的结构无关性与最长公共子序列算法的结构依赖性有机结合,得到程序源代码较为可信的综合相似值。实验结果表明,改进后的算法可以有效降低程序源代码的评测难度,提高评测结果的准确性,得到较为科学的总体相似度值,从而增强评测人员对抄袭现象的监测力度,据此对抄袭者给予警告。
参考文献参考文献:
[1]王晓英, 靳力, 王晓青, 等. 基于序列匹配的作业相似度检测系统[J]. 计算机工程, 2012, 38(24): 5356, 61.
[2]赵长海, 晏海华, 金茂忠. 基于编译优化和反汇编的程序相似性检测方法[J]. 北京航空航天大学学报, 2008, 34(6): 711715.
[3]石陆魁, 张军, 陈飞, 等. 汇编语言程序相似性检测混合算法[J]. 河北科技大学学报, 2011, 32(2): 138142.
[4]GEORGINA C, MIKE J.Sourcecode plagiarism:a UK academic perspective, RR422[R]. Coventry, England: Department of ComputerScience, University of Warwick, 2006.
[5]SHEARD J, DICK M, MARKHAM S, et al.Cheating and plagiarism:perceptions and practices of first year IT students[C].Proc of the 7th annual SIGCSE conference on innovation and technology in computer science education.New York: Association for Computing Machinery, 2002: 183187.
[6]钟美, 张丽萍, 刘东升. 基于XML的C代码抄袭检测算法[J]. 计算机工程与应用, 2011, 47(80): 215218, 235.
[7]刘呈龙, 贾胜颖, 张丽萍, 等. 基于AST的代码抄袭检测方法研究[J].计算机工程与设计, 2012, 33(4): 16601664.
[8]K J OTTENSTEIN. An algorithmic approach to the detection and prevention of plagiarism [J]. ACM SIGCSE Bulletin, 1976, 8(4): 3041.
[9]HALSTEAD M H. Elements of software science[M]. New York: North Holland, 1977.
[10]SUSAN HORWITZ. Identifying the semantic and textual differences between two versions of a program[C].The ACM SIGPLAN 90 conference on programing language design and implementation,South Carolina, 1990, 25(6): 234245.
[11]VERCO K L, WISE M J. Software for detecting suspected plagiarism comparing structure and attributecounting systems[C]. Proceedings of the 1st Australian conference on computer science education, 1996:35.
[12]HIRSCHBERG D S. Algorithms for the longest common subsequence problem[J].Journal of the ACM 1977, 24(4): 664675.
[13]R E BELLMAN. Dynamic programming[M]. Princeton:Princeton University Press, 1957.
[14]EDWARD L JONES. Metric based plagiarism monitoring[C]. The Consortium for Computing in Small Colleges, Vermont, 2001: 253261.
[15]J H JOHNSON. Substring matching for clone detection and change tracking[C]. In: Proceedings of the International Conference on Software Maintenance, 1994(10): 120126.
责任编辑(责任编辑:杜能钢)
- 略论自媒体新闻和传统新闻的融合发展
- 新媒体环境下广播电视媒体运营研究
- 基于技术视角下的媒体融合研究
- 融媒体时代报纸行业发展策略
- 新媒体时代电视民生新闻的转型分析
- 融媒体时代新闻采编工作的若干思考
- 数字时代报纸新闻采编营造特色的方法思考
- 媒介深度融合背景下如何创新报纸宣传
- 新媒体背景下短视频制作创新研究
- 融媒体时代电视记者转型策略探析
- 关于融媒体时代广播发展转型的几点思考
- 移动短视频新闻应用与实践探究
- 融媒时代如何为传统广播赋能
- 以全媒体融合促进媒体转型的策略分析
- 节日报道策划应拓宽内涵谋突破
- 广播电台新闻记者综合素质的提升方法思考
- 新媒体微信公众号的内容编辑研究
- 透过抗疫广告探索公益传播新趋势
- 新媒体时代电视节目编辑制作的方法分析
- 媒体融合背景下的圈层化传播探析
- 试析科技期刊编辑综合素质与期刊的可持续发展
- 创新广播戏曲节目编辑工作的思考
- 记者新闻采写能力的提高策略
- 基于全媒体环境下新闻记者的角色定位探讨
- 广播新闻采访报道贴近听众的途径探微
- bulletin-board-systems'
- bulletined
- bulleting
- bulletining
- bulletins
- bulletless
- bulletlike
- bulletpoint
- bullet point
- bulletproof
- bulletproofed
- bulletproofing
- bulletproofs
- bullets
- bullfight
- bullfighter
- bullfighters
- bullfighting
- bullfights
- bullhorn
- bullhorns
- bullied
- bullier
- bullies
- bulliest
- 宋有子韦
- 宋朝
- 宋朝人物第一
- 宋朝小报
- 宋朝的秦桧,明朝的严嵩
- 宋末三忠
- 宋本玉篇
- 宋杂剧
- 宋株
- 宋株聊守
- 宋江
- 宋江的军师——吴用
- 宋江的绰号
- 宋江的绰号——及时雨
- 宋江起义
- 宋清
- 宋濂
- 宋玉
- 宋玉东墙
- 宋玉东家
- 宋玉东邻
- 宋玉制汛兰之曲
- 宋玉含凄
- 宋玉墙
- 宋玉微辞