| 范文 |
王年丰+费潇潇

摘要:新闻正文信息提取对信息检索、存储和舆情监测等具有极其重要的意义。为实现新闻信息的正确提取,考虑到DOM等几种技术的优势,结合DOM技术、动态型网页信息抽取技术和行块分布算法等技术优点,重点研究了新闻信息的提取方法,尤其针对动态网页的信息提取,设计了一套有效的新闻正文信息提取方法。实验结果表明,该方法能有效实现新闻的正文信息抽取,准确率高,具有一定推广价值。
关键词:信息抽取;DOM技术;动态型网页;行块分布算法(DOIBP)WT9.5HZDOI:WTHT9.5SS10.11907/rjdk.162557中图分类号:TP301
文献标识码:A(文章编号BP)文章编号:16727800(2017)004000905
0引言 当前,互联网资源丰富,如何从海量信息中获取所需信息已经成为Web智能信息处理研究领域面临的重大问题之一。由于实际的新闻网页往往包含很多与主题无关的导航区、超链接、广告信息、版权信息等噪声信息,设计搜索引擎按主题搜索相关信息的工具时,应采用新闻信息抽取技术剔除网页中的噪声信息,从而获取整个新闻的正文信息。新闻信息抽取技术是将Web作为信息源的一类信息抽取,即从新闻页面所包含的无结构或半结构化的信息中识别用户所需的数据。为了提高Web新闻信息抽取的准确度和效率,许多学者提出了各自的方法而且不断加以完善,主要可以分为4类:基于统计理论的技术、基于文档对象模型的技术、基于模板的技术和基于视觉特征的技术。
(1)基于统计理论的方法利用统计方法和规律,将网页HTML文档作为一个整体或去除网页标签,获取网页正文信息。该方法克服了数据源的限制,具有通用性。Arias等
[1]从网页标签序列中找出对应的文本序列,由于网页正文与非正文长度和标签数量存在差异,可以此为基础构建网页文本密度图,以统计的方法识别出网页正文部分;而参考文献[2]提出了一种基于行块分布的方法,该方法摆脱了网页结构的限制,可高效准确地抽取网页正文,但需要人工干预,且对网页上其它信息的提取不够。
(2)基于文档对象模型的方法,通过将HTML文档解析成一棵DOM树,利用节点特征来制定相应的抽取规则。目前已有许多成型的系统和经典算法,如 RoadRunner系统、DSE算法、MDR算法等
[3]。很多学者在此基础上进行了深入研究。如王琦等
[4]基于DOM规范,将HTML文档转换为含有语义信息的STU-DOM树,进行基于结构的过滤和基于语义的剪枝,提取网页主题;Gupta等
[5]使用启发式规则来构造过滤器,以对DOM树中的无用节点进行过滤删除,对于广告的过滤使用的是黑名单策略。该方法依靠文档本身的结构优势,不需要复杂技术和人工干预,但通用性不好。
(3)基于网页模板的提取算法。这类算法可以大致分为两类,一类是从同种结构的网页集中提取出模板作为参考,这种模板一般从同一网站的不同网页中提取;另一类是从各种不同的网页中归类,并分别提取抽象层次更高、归纳性更强的通用模板。Reis等
[6]使用一种树的类正则表达式pe-pattern,以RTDM算法对样本网页进行聚类,并从聚类结果的DOM树中提取出ne-pattern作为该聚类的模板;Vieira等
[7]对RTDM算法进行拓展,使用树的最小编辑距离,实现对DOM树模板的检测和删除。这些方法从模板角度提供了比较新颖的思路,但是计算量非常大,在处理海量数据时效率较低。
(4)基于视觉分块的提取算法。这类算法从用户对网页的视觉感受出发,依照网页中节点的样式特点对页面分块,再从分块结果中找出正文所在的块来达到提取正文的目的。黄文蓓等
[8]以TVPS算法为参考,構建DOM树,以等容器标签为基准,寻找最低层容器节点的各个文本节点进行合并,计算信息量并比较最低层容器节点与其兄弟节点、父节点的信息量,从而选择出能够构成文本块的节点。该方法考虑到了DOM中包含文本节点的结构性,相比于原有算法,准确率得到了一定提升,但算法的运算量依然较大。 这些方法抽取正文信息的前提是所有正文信息都在网页内,但新闻图片网页的正文信息一般不是全部在网页内,例如:腾讯、搜狐、新浪、凤凰等新闻图片频道,大多需要用户点击翻页获取更多信息,因而传统方法很难准确地获取这种新闻网页信息。因此本文在研究现有抽取技术的基础上,利用动态网页信息抽取方法、行块分析算法和DOM技术,实现了针对大型新闻门户的新闻网页正文信息抽取系统。该系统不仅解决了正文信息在网页上的正文抽取问题,而且解决了正文信息不全在网页上的正文抽取问题。
1系统概述
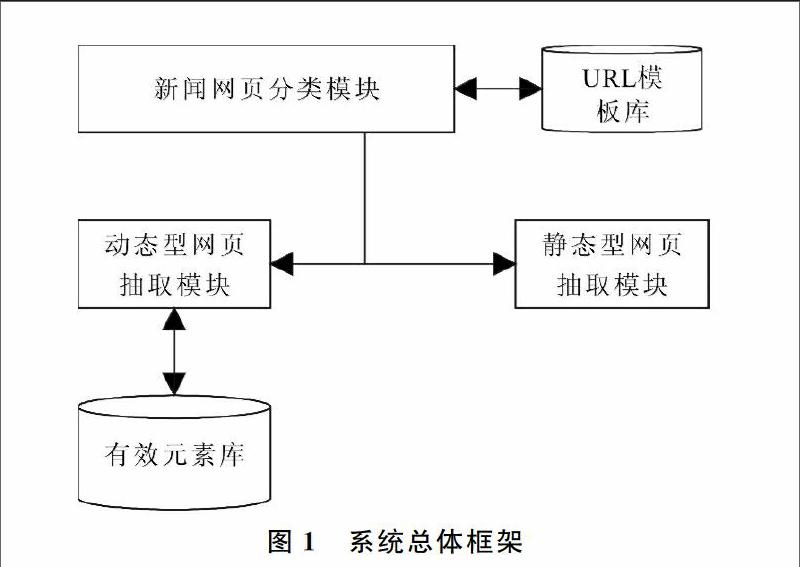
本系统总体分为3部分:预处理模块(Pretreatment)、动态型网页信息抽取模块(Dywebextract)、新闻普通网页信息抽取模块(Stwebextract)。系统总体框架如图1所示。 预处理模块(Pretreatment):Pretreatment模块是正文信息提取预处理模块,可提前获取新闻标题、发布时间等信息;对不同的新闻网页进行分类,对于动态型网页则采用动态型网页抽取模块,对于新闻普通网页则采用静态型网页信息抽取模块。 动态型网页信息抽取模块(Dywebextract):该模块的主要功能是对新闻图片网页进行解析、识别翻页符和获取正文信息。 新闻普通网页信息抽取模块(Stwebextract):该模块是对普通新闻网页进行解析,其基于行分块分布算法来提取正文信息,通过中文语法规范来减少噪声。
2各模块算法设计与实现
2.1预处理模块 在新闻正文信息抽取系统中,为保证新闻正文信息的抽取质量和抽取效率,在抽取相关信息时应按照网页类型采用不同的抽取方法(即大部分新闻图片网页采用动态抽取方法,新闻普通网页采用行块分布方法)。由此可以看出,在抽取信息之前应对网页进行分类,根据抽取目的,采用预处理模块完成新闻网页分类工作。又由于行块分布算法不依赖于网页结构本身,对于新闻标题等信息提取明显不足,因此需要在预处理模块中利用DOM技术提取新闻标题、发布时间等信息,并将新闻标题、新闻网页HTML文档、新闻URL等信息打包分别传给下级模块。因此,预处理模块的功能是网页分类和利用文档对象模型提取新闻标题等信息。
2.1.1Web新闻分类 新闻网页一般分为两种类型:导航型网页、主题型网页。主题型网页通常通过成段的文字、图片等信息描述新闻主题,为了便于处理又可将其分为两小类:①新闻普通网页。这类网页类似静态网页,当网页加载完之后,要采集的信息都在网页上,大部分新闻网页属于这一类;②动态型网页。即图片新闻(指有相同事件主题的图片及简短文字描述的数据集合),当网页加载完之后,要采集的信息不都在网页中,需要翻页才能更新网页内容,大量新闻图片网页属于这一类,如图2所示。 通常,网络上的每一种资源,例如网页、图片、视频等,都有一个唯一的URL,其信息包含了文件位置和浏览器对其如何处理。URL的一般格式为:协议类型://服务器地址(一般情况下,默认不写端口号)/路径名/[?查询][#信息片段],其中方括号[]为可选项,例如:http://news.qq.com/a/20160714/048155.htm#p=1 通过观察验证,属于同一新闻网站动态网页的内容布局与样式外观比较相似。与此同时,同一网站的动态网页的URL相似度也高,这一点从网页开发和网站管理的高效性和便捷而言也是十分合理的,因此利用URL相似度进行新闻网页分类。Qi等
[9]在计算URL相似度上使用了Dice系数并结合使用了统计方法完成URL的相似度量。这种方法从字符串处理的角度出发,又由于URL的格式特点,在协议、服务器名、域名相同的情况下,本文利用新闻URL特征来判断动态型网页,详细介绍如下:①若新闻url字符串中,其路径中包含有“pic”、“photo”等关于图片的英文字符串,则表示该新闻URL为动态型网页。例如:人民网、新华网等网站中的URL包含这些关于图片的字符串;②若新闻url其后缀符合数字递增或字母递增,则该新闻网页是动态型网页,例如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀有极强的规律,为数字递增。2.1.2〓文档对象模型 文档对象模型(DOM)是一种处理HTML和 XML文档的标准应用程序接口(API),它将文档表示为一个树形结构,HTML标签、属性或文本都被作为树的一个节点。基于DOM的信息抽取技术利用网页的结构特点,能够简单、高效地从网页中提取所需内容,其克服了行分块算法对新闻标题、发布时间等信息提取不足的缺点。因此本文在正文信息抽取之前,使用HtmlUnit
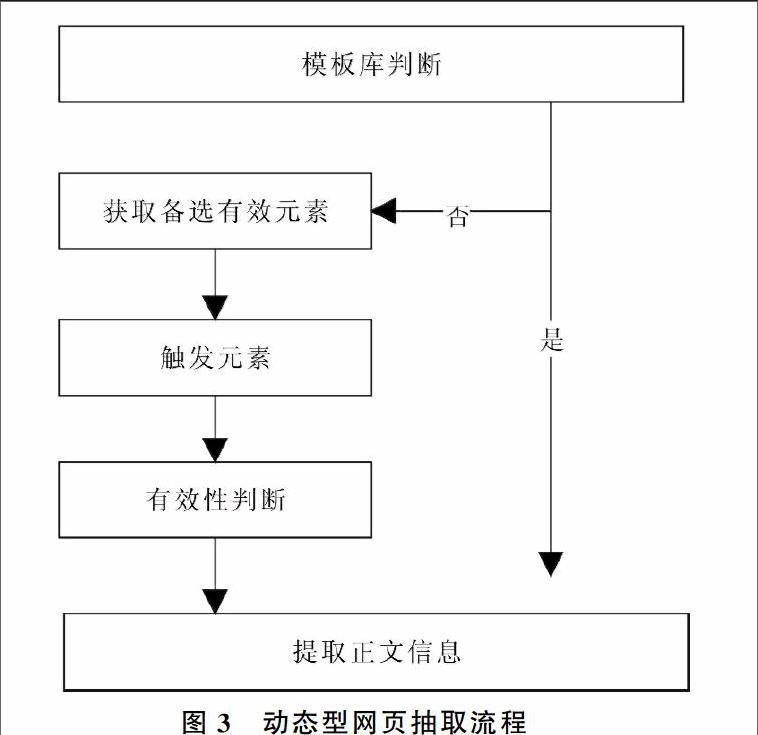
[10]渲染新闻网页获取HTML源码,然后使用Jsoup中的DOM对象抽取新闻标题、发布时间等信息。例如:新闻标题抽取时,首先提取标签中的 标签内容,然后截取‘—、‘_、‘/等标记(<TITLE>内容常常用来分割标题与新闻来源)之前的内容为新闻标题。2.2动态型网页信息抽取模块 Dywebextract模块接受了Pretreatment模块的数据,其主要功能是动态型网页翻页识别和正文信息抽取。对于动态型网页翻页识别,采用两种策略:①若该新闻网页有本地url pattern模板(系统在初始化时根据各大新闻网站动态型网页url的特点,添加url pattern)或者XPath模板(有效元素路径),则按照url pattern模板自行翻页(url后缀数字递增或者字母递减)或触发点击XPath。在新闻网页标题相同的情况下,循环翻页直到抓取不到有效页面(出现重复页面或者死链接);②若本地没有相应的url pattern模板或者XPath,则获取HTML中的备选有效元素,然后将其触发,最后通过触发有效性来筛选出有效元素。 对于正文信息提取,本文利用同一个新闻门户里的动态型网页结构高度相似的特点,采用两个策略:①若本地有XPath pattern模板庫,则按照XPath pattern模板提取正文信息;②若没有,则利用布局相似性的网页正文内容提取方法<br>[11]提取正文信息。对于XPath pattern模板库的管理采用计时的管理方式,若XPath pattern模板库中的一个XPath连续一个星期没用到,则认为该模板为失效XPath,将其删去。本模块算法流程如图3所示,下面重点介绍其中的几个主要环节。<br>2.2.1备选有效元素集合 动态型网页中含有有效元素,有效元素触发之后会异步生成动态信息,而静态型网页不需要触发有效元素来获取信息。但动态型网页中含有很多触发元素(比如按钮、文本框、链接等),有效元素触发生成的动态信息为有价值的动态信息,而无效元素触发生成的动态信息为无效信息,比如触发元素仅改变了网页的字体颜色或其它噪声部分。在动态型网页中,<a>、<div>、<span>等标签代表的元素可能导致页面发生变化<br>[12],从而产生有价值的动态信息,因此本系统将有效元素筛选仅限于<A>、<DIV>、<SPAN>标签。 为进一步缩小有效元素的搜索范围,提高页面信息的获取效率,需要在搜索有效元素之前确定有效元素的标签集合。对于本系统而言,有效元素是可以点击下一页获取下一页正文信息的元素。因此,本文统计了腾讯等8个大型新闻门户网站,从这些新闻门户中随机抽取各100个新闻网页,发现绝大部分有效元素的属性值里都包含有“next”、“right”、“下一张(页)”等字眼。有效元素一般绑定了有效事件,通过用户点击元素执行脚本程序或者网页跳转,以获取更多网页信息,因此其属性值里包含有JavaScript或者一个URL。对于<A>标签,若其子标签里没有<IMG>,则认为其是有效标签。 综上所述,本系统将属性里包含有“next”、“下一张”等字眼的<A>、<DIV>、<SPAN>标签定义为备选有效标签。<br>2.2.2触发元素 动态型网页采用异步加载技术,当用户点击触发有效元素时,会激发有效元素绑定的特定事件,浏览器会执行该事件相应的JavaScript动态脚本程序。因此,需要一个工具来模拟用户点击操作,HtmlUnit恰恰能解决此模拟问题。HtmlUnit是一款开源的Java页面分析工具,采用了Rhinojs引擎,可以模拟浏览器运行,且运行速度很快。本系统采用全探测扫描算法 <!----> </div> </div> <div> [<a href="article.aspx?titleid=rjdk20170403">1</a>] <label> 2 </label> [<a href="article.aspx?titleid=rjdk20170403-2">3</a>] [<a href="article.aspx?titleid=rjdk20170403-3">4</a>] <a href="javascript:OpenFavoriteTitle('rjdk20170403','新闻正文信息在线提取方法研究','王年丰 费潇潇');"> 存入我的阅览室</a> </div> </div> </div> <div> <div> </div> <div> <div> <ul> <li><a target="_blank" href="Mag.aspx?issn=82589D23-32F8-4175-B6A9-49CEFBC68AF0&year=2017&issue=5"> <img src="http://img1.qikan.com/qkimages/rjdk/rjdk201705-m.jpg" alt="《故事会》" style="filter: alpha(opacity=100);" onmousemove="javascript:f_move(this)" onmouseout="javascript:f_out(this)" width="120px" height="158px" /> </a> <p> <b><a target="_blank" href="Mag.aspx?issn=82589D23-32F8-4175-B6A9-49CEFBC68AF0&year=2017&issue=5" title="软件导刊">《软件导刊》</a></b><br /> 2017年05期 </p> </li> </ul> </div> <div> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 软件理论与方法</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170401" title="基于不确定性分析的移动对象轨迹估计技术"> 基于不确定性分析的移动对象轨迹估计技术</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170402" title="领域文本信息抽取中的短语相似度计算方法"> 领域文本信息抽取中的短语相似度计算方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170403" title="新闻正文信息在线提取方法研究"> 新闻正文信息在线提取方法研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170404" title="研讨系统中的发言文本聚类及其可视化"> 研讨系统中的发言文本聚类及其可视化</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170405" title="一种基于单周期控制的改进型功率因数校正方法"> 一种基于单周期控制的改进型功率因数校正方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170406" title="一种基于ARM的异构CPU—GPU集群调度模型"> 一种基于ARM的异构CPU—GPU集群调度模型</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170407" title="基于Bootstrap的响应式网页设计中断点研究"> 基于Bootstrap的响应式网页设计中断点研究</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 算法与语言</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170408" title="基于灰狼优化的模糊C—均值聚类算法"> 基于灰狼优化的模糊C—均值聚类算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170409" title="基于协方差矩阵的压缩感知跟踪算法"> 基于协方差矩阵的压缩感知跟踪算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170410" title="基于Android端的惯性导航算法研究"> 基于Android端的惯性导航算法研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170411" title="基于NAND闪存的安全U盘FTL算法研究"> 基于NAND闪存的安全U盘FTL算法研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170412" title="无线传感器网络加权质心定位算法改进研究"> 无线传感器网络加权质心定位算法改进研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170413" title="基于最低能耗的改进LEACH分簇算法"> 基于最低能耗的改进LEACH分簇算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170414" title="基于AdaBoost算法的在线连续极限学习机集成算法"> 基于AdaBoost算法的在线连续极限学习机集成算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170415" title="协同进化多生境遗传算法"> 协同进化多生境遗传算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170416" title="K—means和人工鱼群结合的聚类算法研究"> K—means和人工鱼群结合的聚类算法研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170417" title="基于Voronoi盲区的差分进化WSN部署算法"> 基于Voronoi盲区的差分进化WSN部署算法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170418" title="算法参数对人工蜂群算法性能的影响"> 算法参数对人工蜂群算法性能的影响</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170419" title="基于卡尔曼预测的轨迹片段关联目标跟踪算法"> 基于卡尔曼预测的轨迹片段关联目标跟踪算法</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 软件设计与开发</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170420" title="基于Express的违章查询REST Web Service设计与实现"> 基于Express的违章查询REST Web Service设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170421" title="基于协同过滤算法的IT书籍推荐系统设计与实现"> 基于协同过滤算法的IT书籍推荐系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170422" title="OpenStack云主机监控系统研究与实现"> OpenStack云主机监控系统研究与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170423" title="面向部门岗位的工作流引擎研究与实现"> 面向部门岗位的工作流引擎研究与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170424" title="基于HALCON的票据字符提取系统设计与实现"> 基于HALCON的票据字符提取系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170425" title="基于ANSYS的竖直型风力发电机叶片建模与仿真"> 基于ANSYS的竖直型风力发电机叶片建模与仿真</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170426" title="基于虚拟现实技术的湖湘文化旅游系统设计与实现"> 基于虚拟现实技术的湖湘文化旅游系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170427" title="一种基于OSG的双旋翼直升机仿真系统与程序实现"> 一种基于OSG的双旋翼直升机仿真系统与程序实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170428" title="基于ESSH框架的高校科研团队信息管理系统设计与实现"> 基于ESSH框架的高校科研团队信息管理系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170429" title="基于SolidWorks二次开发的剪式升降平台快速设计系统"> 基于SolidWorks二次开发的剪式升降平台快速设计系统</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170430" title="基于.NET N层架构和团队开发模式的部队信息化平台构建"> 基于.NET N层架构和团队开发模式的部队信息化平台构建</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170431" title="基于VR技术的虚拟仿真生活体验馆设计与实现"> 基于VR技术的虚拟仿真生活体验馆设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170432" title="基于面部瞳孔识别及数据采集器的电子巡检系统设计"> 基于面部瞳孔识别及数据采集器的电子巡检系统设计</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170433" title="基于微信公众平台与Moodle的移动学习环境构建"> 基于微信公众平台与Moodle的移动学习环境构建</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170434" title="学习资源爬虫系统设计与实现"> 学习资源爬虫系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170435" title="基于参数化的挤压模具敏捷设计系统研究"> 基于参数化的挤压模具敏捷设计系统研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170436" title="一种基于Hadoop平台的分布式数据检索系统"> 一种基于Hadoop平台的分布式数据检索系统</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170437" title="DBaaS自助门户服务平台构建研究"> DBaaS自助门户服务平台构建研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170438" title="基于μCOS嵌入式系统控制的激光打标机设计"> 基于μCOS嵌入式系统控制的激光打标机设计</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170439" title="基于协同过滤算法的移动英语学习平台研究与设计"> 基于协同过滤算法的移动英语学习平台研究与设计</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170440" title="基于MVC模式的毕业论文(设计)管理系统设计与实现"> 基于MVC模式的毕业论文(设计)管理系统设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170441" title="基于VB.NET的圆柱齿轮减速器智能设计系统"> 基于VB.NET的圆柱齿轮减速器智能设计系统</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170442" title="基于AM3359 和WinCE7.0平台的RTC时钟设计与实现"> 基于AM3359 和WinCE7.0平台的RTC时钟设计与实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170443" title="基于Pro/E二次开发的剪板机快速设计系统"> 基于Pro/E二次开发的剪板机快速设计系统</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170444" title="基于单片机的水位监控系统设计"> 基于单片机的水位监控系统设计</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 应用技术与研究</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170445" title="BP神经网络在石油项目经济效益综合评价中的应用"> BP神经网络在石油项目经济效益综合评价中的应用</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170446" title="基于密度的空间聚类算法在照明运维中的应用"> 基于密度的空间聚类算法在照明运维中的应用</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170447" title="基于VBA的异构数据源自适应读写技术研究与实践"> 基于VBA的异构数据源自适应读写技术研究与实践</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170448" title="基于泊松过程可分解性的小区开放对道路通行能力的影响"> 基于泊松过程可分解性的小区开放对道路通行能力的影响</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170449" title="基于模块分解的IFPUG功能点分析方法应用研究"> 基于模块分解的IFPUG功能点分析方法应用研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170450" title="基于图像处理的工件加工精度检测系统研究"> 基于图像处理的工件加工精度检测系统研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170451" title="一种基于EA的需求管理实施方案"> 一种基于EA的需求管理实施方案</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170452" title="基于Halcon的食品生产日期针孔光学字符检测"> 基于Halcon的食品生产日期针孔光学字符检测</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170453" title="面向照明终端芯片程序的无线远程升级研究与应用"> 面向照明终端芯片程序的无线远程升级研究与应用</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170454" title="基于ElasticSearch的Angularjs联想框功能实现"> 基于ElasticSearch的Angularjs联想框功能实现</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170455" title="“互联网+”校园一卡通融合路径研究"> “互联网+”校园一卡通融合路径研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170456" title="一种使用经验系数灰度化的中药叶片分割方法"> 一种使用经验系数灰度化的中药叶片分割方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170457" title="基于相似度代价计算的内存数据库集群数据划分"> 基于相似度代价计算的内存数据库集群数据划分</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170458" title="基于K—均值算法的数据挖掘技术研究及应用"> 基于K—均值算法的数据挖掘技术研究及应用</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 信息安全</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170459" title="一种基于压缩感知与混沌系统的比特级图像加密方法"> 一种基于压缩感知与混沌系统的比特级图像加密方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170460" title="铁路车站计算机联锁系统安全性分析"> 铁路车站计算机联锁系统安全性分析</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170461" title="PDF中隐私数据的保护方法"> PDF中隐私数据的保护方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170462" title="基于贝叶斯网络的网络风险评估研究"> 基于贝叶斯网络的网络风险评估研究</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 图像学与辅助设计</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170463" title="桌面遥感图像处理系统并行处理架构选择与实验分析"> 桌面遥感图像处理系统并行处理架构选择与实验分析</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170464" title="SharpGL三维建模技术实现"> SharpGL三维建模技术实现</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 综述</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170465" title="Web服务测试综述"> Web服务测试综述</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170466" title="大数据处理平台比较研究"> 大数据处理平台比较研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170467" title="Java Web应用开发中的常见乱码形式及解决方法"> Java Web应用开发中的常见乱码形式及解决方法</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170468" title="APP应用现状、挑战与展望"> APP应用现状、挑战与展望</a> </dd> </dl> <dl onmouseover="this.className='cc0'" onmouseout="this.className='cc1'"> <dt> 计算机与网络教学</dt> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170469" title="面向工程的计算机专业实践教学体系研究"> 面向工程的计算机专业实践教学体系研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170470" title="《C语言程序设计》课程“三位一体式”教学模式研究"> 《C语言程序设计》课程“三位一体式”教学模式研究</a> </dd> <dd > <a target="_blank" href="Article.aspx?titleid=rjdk20170471" title="ASP.NET课程教学改革研究与实践"> ASP.NET课程教学改革研究与实践</a> </dd> </dl> </div> </div> </div> </div> </div> <div id="menuFooterDiv"></div> <script type="text/javascript"> jQuery("#menuHeaderDiv").html(html); jQuery(function () { jQuery("#morelayer").hover(function () { jQuery("#divmorelayer").fadeIn(300); }) jQuery("#divmorelayer").hover(function () { jQuery("#divmorelayer").fadeIn(300); }, function () { jQuery("#divmorelayer").fadeOut(300); }) }) jQuery("#menuFooterDiv").html(htmlFooter); jQuery(function () { jQuery("#morelayerFooter").hover(function () { jQuery("#divmorelayerFooter").fadeIn(300); }) jQuery("#divmorelayerFooter").hover(function () { jQuery("#divmorelayerFooter").fadeIn(300); }, function () { jQuery("#divmorelayerFooter").fadeOut(300); }) }) if (jQuery('.morelayer_body > a').length == 0) { //页眉/页脚导航“更多”下没有内容,将“更多”隐藏 jQuery('.threeunit').hide(); } </script> <div> 公司地址: 北京市西城区德外大街83号德胜国际中心B-11<br>客服热线:400-656-5456??客服专线:010-56265043??电子邮箱:<a href="mailto:longyuankf@126.com">longyuankf@126.com</a><br>电信与信息服务业务经营许可证:<a href="http://www.miibeian.gov.cn" target="_blank">京icp证060024号</a><br>Dragonsource.com Inc. All Rights Reserved </div><div> <a href="http://www.hd315.gov.cn/beian/view.asp?bianhao=010202006041400015" target="_blank"> <img src="/Content/Images/icp.jpg" alt="icp" /></a></div> </div> </div> </form> <script type="text/javascript" src="/Content/Script/jquery.cookie.js"></script> <script type="text/javascript"> jQuery(document.body).ready(function () { if (jQuery.cookie('enablecookie') == null) { jQuery.cookie('enablecookie', '1'); var ec = jQuery.cookie('enablecookie'); if (ec == null) { location.href = "http://" + domain + "/content/error.aspx?error=nocookie"; } } }); </script> <script type="text/javascript"> var showad = true; var Toppx = jQuery(".headbox").height() + jQuery(".banner").height() + 10; //60; var AdDivW = 100; var AdDivH = 252; var PageWidth = 800; var MinScreenW = 1024; function scall1() { if (!showad) { return; } if (window.screen.width < MinScreenW) { showad = false; // document.getElementById("ctl00_LeftDiv").style.display = "none"; // document.getElementById("ctl00_RightDiv").style.display = "none"; jQuery("#ctl00_LeftDiv").hide(); jQuery("#ctl00_RightDiv").hide(); return; } var Borderpx = 30; //((window.screen.width - PageWidth) / 2 - AdDivW) / 2; // document.getElementById('ctl00_LeftDiv').style.display = ""; // document.getElementById('ctl00_LeftDiv').style.top = document.documentElement.scrollTop + Toppx; // document.getElementById('ctl00_LeftDiv').style.left = document.documentElement.scrollLeft + Borderpx; // document.getElementById('ctl00_RightDiv').style.display = ""; // document.getElementById('ctl00_RightDiv').style.top = document.documentElement.scrollTop + Toppx; // document.getElementById('ctl00_RightDiv').style.left = document.documentElement.scrollLeft + document.body.clientWidth - document.getElementById('ctl00_RightDiv').offsetWidth - Borderpx; jQuery("#ctl00_LeftDiv").show(); var Scrolltoppx = document.documentElement.scrollTop; var Scrollleftpx = document.documentElement.scrollLeft; jQuery("#ctl00_LeftDiv").css("top", Scrolltoppx + Toppx); jQuery("#ctl00_LeftDiv").css("left", Scrollleftpx + Borderpx); jQuery("#ctl00_RightDiv").show(); jQuery("#ctl00_RightDiv").css("top", Scrolltoppx + Toppx); jQuery("#ctl00_RightDiv").css("left", Scrollleftpx + document.body.clientWidth - document.getElementById('ctl00_RightDiv').offsetWidth - Borderpx); } function hidead1() { showad = false; document.getElementById('ctl00_LeftDiv').style.display = "none"; document.getElementById('ctl00_RightDiv').style.display = "none"; } function addLoadEvent1(func) { var oldonload = window.onload; if (typeof window.onload != 'function') { window.onload = func; } else { window.onload = function () { oldonload(); func(); } } } window.onscroll = scall1; window.onresize = scall1; addLoadEvent1(scall1); </script> <script type="text/javascript"> var piao=false; var xPos = 300; var yPos = 200; var step = 1; var delay = 30; var height = 0; var Hoffset = 0; var Woffset = 0; var yon = 0; var xon = 0; var pause = true; var interval; var img1 = document.getElementById("ctl00_PiaoDiv"); img1.style.display = 'block'; img1.style.top = yPos; function changePos() { var Scrolltoppx = document.documentElement.scrollTop; var Scrollleftpx = document.documentElement.scrollLeft; width = document.body.clientWidth - 200; height = document.documentElement.clientHeight; Hoffset = img1.offsetHeight; Woffset = img1.offsetWidth; jQuery(img1).css("left", xPos + document.body.scrollLeft); jQuery(img1).css("top", Scrolltoppx + yPos + document.body.scrollTop); if (yon) { yPos = yPos + step; } else { yPos = yPos - step; } if (yPos < 0) { yon = 1; yPos = 0; } if (yPos >= (height - Hoffset)) { yon = 0; yPos = (height - Hoffset); } if (xon) { xPos = xPos + step; } else { xPos = xPos - step; } if (xPos < 0) { xon = 1; xPos = 0; } if (xPos >= (width - Woffset)) { xon = 0; xPos = (width - Woffset); } } function start() { img1.visibility = "visible"; interval = setInterval('changePos()', delay); } function pause_resume() { if (pause) { clearInterval(interval); pause = false; } else { interval = setInterval('changePos()', delay); pause = true; } } if(piao) { start(); } </script> <fjtignoreurl> <script type="text/javascript"> //为了处理https协议在繁简转换的时候会默认吧链接转换成带有端口号444的链接的问题。 jQuery(function () { $("a[href*=':444']").each(function () { var link = $(this).attr('href'); link = link.replace(/^https://big5.qikan.com:444/i, "http://big5.qikan.com") $(this).attr('href', link); }); });</script></fjtignoreurl> <script type="text/javascript"> jQuery(function () { var link = "https://big5.qikan.com"; }); </script><fjtignoreurl><script type="text/javascript">var _userid = 'locklg006@nlc.com';var _siteid =19;var _istoken = 1;var _model = 'Model03';</script><script src="http://tj.qikan.com/urchin.js" type="text/javascript"> </script><script type="text/javascript">WebPageSpeed =469; UrchinTrack();</script></fjtignoreurl></body></html> <!–nextpage–>
[13],将有效元素集合中的所有元素进行点击操作。2.2.3触发有效性判断 动态型网页在触发有效元素时,会改变DOM树的结构,触发有效性判断也可以表示为DOM树结构的变化,因此可以通过比较DOM树结构相似性作为触发有效性的标识。由于每次获取下一页,网页里只有图片和正文信息变动,其它噪声、链接等部分基本不变,因此在判断DOM树相似性之前,通过正则表达式过滤获取中文文字信息。 何昕等
[14]利用简单树匹配算法来判断DOM树相似性,它是一个受限的匹配算法,采用动态规划来计算两棵树的最大匹配结点个数,得到两棵树结构的相似度;Roest等
[15]提出了比较页面的方法,该方法比较每个模块首先定位到该模块所针对的DOM树结构的特点部位,若判定其内容相同,则过滤掉该部分信息,将剩余内容传递给下一比较模块,否则便可以直接判定两个DOM树不相似。以上两种方法更多的是从DOM树结构出发,考虑到新闻网页有效信息都在中文文字里,在网页标题的情况下,本系统对比新得到的网页中文信息与触发之前的网页中文信息,若只有极少数发生变化,则认为新得到的网页无效,该触发无效;否则,认为得到的网页有效,将有效元素XPath存入XPath模板库中。2.3新闻普通网页信息抽取模块 新闻普通网页信息抽取模块的目标是抽取新闻普通网页的正文信息。新闻普通网页的正文结构通常比较紧凑,网页内图片较少,正文代码的一行大都是文字,超链接长度所占比率不大。又由于行块分布算法对主题网页有很好的通用性和较高的准确率,因此使用行块分布算法。行块分析算法的思想是哈尔滨工业大学信息检索中心的陈鑫等研究提出的,其网页正文块起始行块号Xstart和结束行块号Xend的确定,必须同时满足以下几个条件,这里定义 Y(X)为以行号 X 为轴的行块长度值。 (1)Ystart> Y(Xt),其中Y(Xt)是行块长度的第一个骤升点,骤升点的行块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧跟在骤升点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),骤降点以及紧跟在骤降点后面行的行块长度为 0,以保证正文提取结束。 本文根据行块分布算法的思想,利用Java中的JFreeChart绘图工具,可得如图4所示的行块分布函数折线图。从图4可看出,有很多内容块[start=743,end=745]、[start=749,end=773]、[start=1160,end=1165]、[start=1198,end=1205],而且内容块中可能还有噪声部分没有清除。因此,根据新闻网页噪声的特点,添加了第4个约束条件。
(4)Ystart3实验测试
3.1实验准备
测试系统的机器环境为:1台台式机(CPU为Intel四核2.93GHz,4G内存,硬盘为7 200r/min,操作系统为Win7,10兆网速)。本系统采用纯Java实现,有效元素路径存储选用MySQL5.5数据库存储。为了使结果更具说服力,本文设计了一个轻量级的主题爬虫,从知名的新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中爬取网页,以此作为实验网页集。实验主要测试新闻正文信息提取的正确率和提取速度,而新闻标题则是由网页采集器提取(一般导航网页里,新闻标题和新闻URL在一起),这里不作处理。对于动态新闻,提取出的正文完全覆盖真正的含义,而且没有过滤干净的噪声占正文的比例不大于5%时才算合格。对于静态网页,本文采用准确率来表示提出正文信息的准确性:准确率=正确过滤的网页数/总网页个数×100%
3.2实验结果 表1给出了系统网页正文抽取准确率以及在线抽取正文信息速率,其中每个网站动态网页和静态网页各100个,总共1 600个网页。表1的试验结果表明:本系统抽取静态型网页的准确率高于93%,对原新闻网页正文内容提取比较完整,但动态型网页的准确率都在80%以上。出现误差的原因是不同专题的设计风格不尽相同,以及人们对于网页中正文的界定差异等因素存在,本文算法的结果或多或少会受到一定影响。对于正文内容为纯文本的网页,本文算法的准确率很高。对于影响本系统正确率的几个主要因素总结如下:①动态型网页和普通新闻网页的区分是根据URL相似度和URL是否含有标识符来判断的;②对于普通新闻网页中正文内容和噪声部分的比例,如果网页内以图片或视频为主要内容,过短的正文内容会被作为噪声,从而降低提取结果的正确率;③普通新闻网页中若嵌入图片,将使正文各部分之间距离相差较大。
4实验结论 本文提出的新闻网页正文抽取系统除了利用行分块算法抽取网页信息以及DOM技术之外,还利用动态型网页结构上的相似性特点,实现了大型新闻网站新闻正文信息的提取。本系统不依靠大量的训练集,能够较准确地抽取新闻正文信息,实验结果验证了其有效性。然而,对英文网页以及结构复杂的网页抽取效果不是很理想,尤其是嵌入图文信息的普通新闻网页。此方法只能抽取文字信息,不能获得网页图片,下一步可以对英文网页优化、复杂网页抽取算法和网页图片获取方法等进行深入研究。
参考文献:
[1]ARIAS J,DESCHACHT K,MOENS M F.Language independent content extraction from web pages[J].University of Twente,2009.
[2]〓開源中国社区.通用网页正文抽取[EB/OL].[20150425].http://code.google.com/p/cxextractor/.
[3]陈钊,张冬梅.Web信息抽取技术综述[J].计算机应用研究,2010,27(12):44014405.
[4]王琦,唐世渭,杨冬青,等.基于DOM的网页主题信息自动提取[C].中国数据库学术会议,2004:17861792.
[5]GUPTA S,KAISER G E,GRIMM P,et al.Automating content extraction of HTML documents[J].World Wide Webinternet & Web Information Systems,2005,8(2):179224.
[6]REIS D C.Automatic web news extraction using tree edit distance[C].International Conference on World Wide Web.ACM,2004:502511.
[7]VIEIRA K,SILVA A S D,PINTO N,et al.A fast and robust method for web page template detection and removal[C].ACM International Conference on Information and Knowledge Management.ACM,2006:258267.
[8]黄文蓓,杨静,顾君忠.基于分块的网页正文信息提取算法研究[J].计算机应用,2007,27(s1):2426.
[9]QI X,NIE L,DAVISON B D.Measuring similarity to detect qualified links[C].Airweb 2007,Third International Workshop on Adversarial Information Retrieval on the Web,CoLocated with the WWW Conference,Banff,Canada,2007:4956.
[10]张佳荣.Java开源项目HtmlUnit在浏览器模拟方面的应用[J].电子制作,2015(8):79.
[11]杨柳青,李晓东,耿光刚.基于布局相似性的网页正文内容提取研究[J].计算机应用研究,2015(9):25812586.
[12]张瑶.面向AJAX脚本网络的网页爬行及解析技术的研究与实现[D].沈阳:东北大学,2012.
[13]MESBAH A,BOZDAG E,DEURSEN A V.Crawling AJAX by inferring user interface state changes[C].Eighth International Conference on Web Engineering,Yorktown Heights,New York,Usa.2008:122134.
[14]何昕,谢志鹏.基于简单树匹配算法的Web页面结构相似性度量[J].计算机研究与发展,2007,44(z3):16.
[15]ROEST D,MESBAH A,DEURSEN A V.Regression testing ajax applications: coping with dynamism[C].International Conference on Software Testing,Verification and Validation,ICST 2010,Paris,France,2010:127136.(責任编辑:杜能钢) |