摘 要:针对传统车辆检测算法不能自适应地完成复杂道路场景变化下提取车辆特征的问题,结合焦点损失、K-means聚类与mobilenet网络,提出改进的RFB-VGG16与RFB-MobileNet模型进行车辆检测。从开源数据集UA-DETRAC的24个视频中每隔一定帧数抽取8 209张已标注的图片构成数据集,在相同的超参数与训练策略下,改进后RFB-VGG16网络的AP值比原模型提高了3.2%。基于mobilenet网络重新设计RFB骨架网络,使RFB-MobileNet模型在牺牲一定性能的情况下,具有更快的检测速度,能较好地满足监控视频对车辆检测实时性的要求。
关键词:深度学习;车辆检测;焦点损失;RFBNet;K-means
DOI:10. 11907/rjdk. 182835 开放科学(资源服务)标识码(OSID):
中图分类号:TP306文献标识码:A 文章编号:1672-7800(2019)007-0037-04
Real-time Vehicle Detection in Surveillance Video Based on Deep Learning
ZHANG Wen-hui
(School of Automation,Guangdong University of Technology, Guangzhou 510006, China)
Abstract: Aiming at the problem that the traditional vehicle detection algorithm can not adaptively extract the vehicle characteristics under the complex road scene change, this paper combines the focus loss, K-means clustering and mobilenet network, and proposes the improved RFB-VGG16 and RFB-MobileNet models for the vehicle detection. First, 8209 images of the labeled images are extracted from the 24 videos of the open source dataset UA-DETRAC. Second,Under the same hyperparameters and training strategies, the AP value of the improved RFB-VGG16 network is 3.2% higher than the original model. Redesigning the RFB's skeleton network based on the mobilenet network enables the RFB-MobileNet model to have a faster detection speed at the expense of a little performance, thus meeting the real-time requirements of vehicle detection in surveillance video.
Key Words:deep learning; vehicle detection; focus loss; RFBNet; K-means
作者简介:张文辉(1992-),男,广东工业大学自动化学院硕士研究生,研究方向为计算机视觉。
0 引言
随着中国经济及城市化的快速发展,城市人口与车辆数量急剧增长,交管部门道路车辆监管压力也与日俱增。目前我国大部分路口已安装了高清监控摄像头,每天会产生大量监控视频,使交管部门在进行车辆违法行为判断、不同时段车流量统计与跨摄像头车辆追踪等工作时面临严峻挑战。通过人工进行視频实时监控处理不仅成本较高,而且费时费力,同时长时间工作容易使人产生疲劳,易出现监控遗漏的情况,所以迫切需要一种自动化方法辅助人工进行视频监控处理。
由于不同路段的交通监控系统建设时间与监控需求不同,导致摄像头的拍摄角度、分辨率与方向具有很大差异,同时视频质量容易受到光照、下雨及雾霾等天气因素的严重影响。传统检测方法对视频质量要求较高,因此在面对复杂道路场景时往往效果较差。随着深度学习在检测、识别等计算机视觉任务中取得重大突破,基于深度学习的目标检测算法凭借卷积神经网络强大的特征提取能力,替代传统机器学习中的人工设计特征,能够应对复杂的道路场景,具有更高的检测准确率与更强的鲁棒性,效果远优于传统检测算法。
目前基于深度学习的目标检测算法主要分为以SSD[1]与YOLO系列[2-4]为代表的“一步法”模型,以及以RCNN系列[5-7]为代表的“两步法”模型。在权衡实时性与性能后,本文引入基于SSD改进的RFBNet(Receptive Field Block Net)[8]模型实现监控视频的车辆检测,并对RFBNe模型结构与参数进行如下优化:①在RFBNet训练阶段引入焦点损失方法[9],以加大难训练样本权重值;②采用K-means聚类查找anchor的最佳数量和大小;③基于MobileNet[10]设计出更轻量化的骨架网络进行特征提取。实验结果显示,经过上述方法改进的RFB-VGG16模型效果优于基础模型,且能保持原有处理速度,而RFB-MobileNet速度虽然快于RFB-VGG16,但准确度有所降低。因此,对于在线监控可以选择速度更快的RFB-MobileNet模型,而离线处理可以选择准确度更高的RFB-VGG16模型。
1 RFBNet整体结构
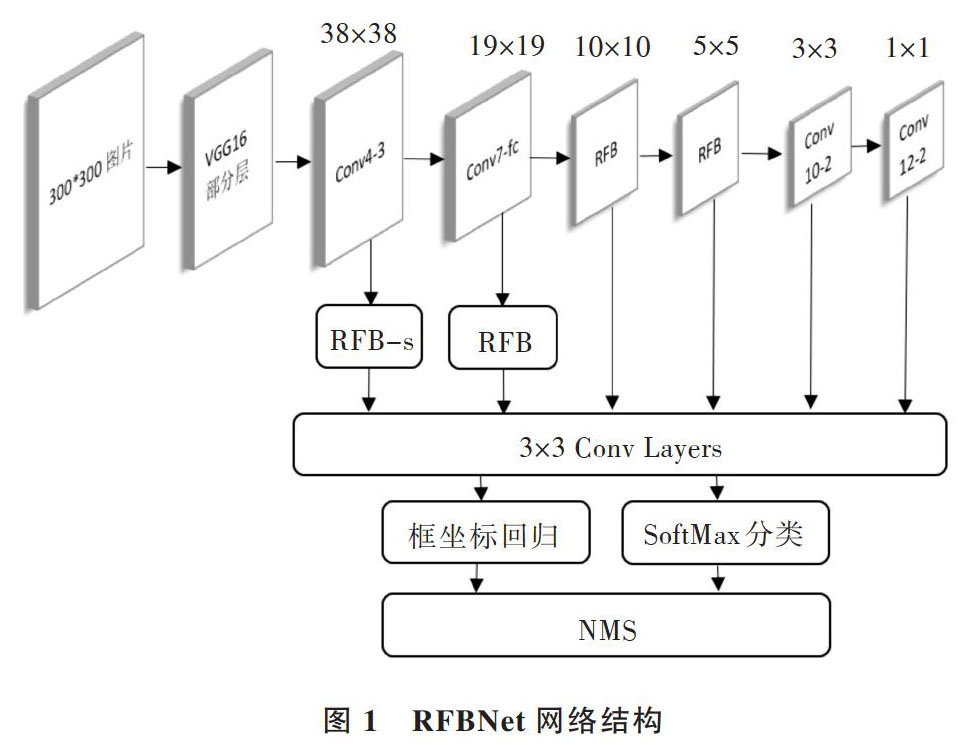
RFBNet整体结构与SSD模型相似,主要由基础网络与多尺度预测层组成,并加入仿人类视觉系统的RF Block(Receptive Field Block)模块,以增强CNN网络的特征提取能力,可同时满足对速度与精度的要求。在车辆检测过程中,首先将图片缩放为300×300大小,然后将其输入到骨干网络VGG16头部的部分层中进行特征提取,接着继续通过卷积与池化形成6个特征图。在不同尺度的特征图上采用3×3卷积进行框回归和类别分类。其中框回归是对包含前景的框位置进行修正,而类别分类采用softmax,类别包括背景和前景的k个类别,共有(k+1)个类别,RFBNet网络结构如图1所示。
图1 RFBNet网络结构
2 改进方法
本文方法是在监控视频中抽取一帧帧图像,再进行车辆检测。以RFB 模型框架为基础,结合K-means、焦点损失与MobileNet进行改进,下面对每部分进行介绍。
2.1 anchor大小优化
在车辆检测过程中,RFB网络通过调整anchor大小匹配待检测目标的位置框,从而得到一个准确的预测框。如果一开始设定一组合适的anchor,RFB网络将更容易得到准确的预测框。对于anchor大小设定有以下3种方式:①凭借以往经验人为设定anchor大小;②通过统计手段找到合适的anchor;③采用聚类算法发现合适的anchor。由于前两种方式过度依赖人的调参经验,同时本文研究对象为车辆,该对象相对于其它目标具有特定形状,一般为扁长,因此本文采用K-means聚类算法寻找最佳anchor大小。传统K-means算法的度量函数采用欧几里得距离,具体公式如下:
[d(x,y)=i=1n(xi-yi)] (1)
采用式(1)作为度量函数后,会出现大位置框比小位置框贡献更多损失的情况,即训练过程中大框与小框地位不平等,最终会影响模型对小框的预测结果。为了避免以上情况发生,采用以下改良的度量函数:
[d(box,centroid)=1-IOU(box,centroid)] (2)
[IOU=Area of OverlapArea of Union] (3)
其中式(3)IoU(Intersection over Union)是两个框面积区域的交集除以两个框面积区域的并集。本文采用改进后的K-means对UA-DETRAC数据集中抽取的8 209张数据集进行聚类,如图3所示。
图2 聚类中心与平均IOU分布
在图2中横轴是聚类中心个数,纵轴是平均IOU值。聚类中心个数越多,平均IOU值也越大,但平均IOU值的增幅相应减缓。在RFBNet模型中采用越多的anchor,其检测性能将得到提升,但模型运算时间也相应增加。从图2中可看出,当聚类中心为6时,平均IOU值增幅已逐渐放缓,因此在权衡模型运行时间与准确率两方面后,本文设定RFBnet模型的anchor个数为6。
2.2 anchor数量优化
RFB网络中采用6个不同尺度特征图预测位置框,从而增强模型预测小位置框的能力,其中6个特征图大小分别为38×38、19×19、10×10、5×5、3×3和1×1。从数据集中不放回地随机抽样1 000张照片放入RFB网络中,同时从6个特征图的预测结果中筛选出IOU大于0.5的预测框,接着将满足以上条件的位置框画在一个300*300的图中,其中横轴为位置框长度,纵轴为位置框高度,不同颜色代表其由不同特征图预测得到,如图3所示。
通过统计6个特征图预测结果,得到以下结论:①小目标数量远多于大目标数量,如图3所示,左下角是小目标分布图,右上角是大目标分布图;②车辆检测贡献程度排序如下:P38>P19>P10>P5>P3>P1。从图3中可明显看出,不同特征图负责检测不同大小的车辆,同时大特征图能准确预测出更多车辆位置框。因为anchor数量越多,会相应增大模型复杂度,因此可以通过减少低贡献度特征图的anchor个数以降低模型复杂度,从而降低模型浮点数计算量,加快網络运行速度。本文模型采用的anchor类别个数如表1所示。
2.3 聚焦损失
以SSD为代表的“一步法”摒弃了候选框提取方式,而是直接预测类别与框坐标,以保证算法的实时性,但准确率不如“二步法”。“一步法”准确率低是因类别数量失衡引起的,即负样本个数远多于正样本个数。在模型训练过程中,大量的简单负样本提供了无用信息,从而使模型训练无效。聚焦损失是在交叉熵损失基础上引入α和β因子,以解决类别数量失衡的问题。
交叉熵损失是多分类中最常用的算法函数。假设数据集中有n个样本,类别个数为C,同时背景作为一类,总类别个数为C+1,则交叉熵CE定义如下:
[CE=1ni=1nj=1C+1-y(i)jlog(p(x(i))j)] (4)
其中,y是真实类别概率值,[p(x)]是预测类别概率值。交叉熵损失中正负样本地位平等,因此训练过程中容易使模型出现偏移,从而使模型训练无效。
对于类别不平衡问题,通过加入α以降低大数量类别的影响。
[CE=1ni=1nj=1C+1-?jy(i)jlog(p(x(i))j)] (5)
对于难检测样本,在原有基础上加入[β]因子,公式如下:
[β(i)j=(1-p(x(i))j)γ] (6)
其中[γ]是一个可调节的超参数,[β]因子的作用是减少简单样本的损失权重,从而使模型能专注于对难检测样本的训练,以避免大量简单负样本使模型训练失效的问题。焦点损失FL公式定义如下:
[CE=1ni=1nj=1C+1-?jβ(i)jy(i)jlog(p(x(i))j)] (7)
本文将焦点损失方法应用于RFBnet中,并测试不同[α]与[γ]对模型的影响。
2.4 骨架网络设计
深度学习在图像分类、检测等任务中显示出巨大优势,但是随着模型准确率的提高,也导致计算量与存储空间消耗大幅提升。对于卡口车辆检测,要保证任务的实时性,需要降低模型计算量,以达到去除冗余计算与提高检测模型速度的目标。本文采用谷歌團队推出的mobileNet对RFB基础网络进行改良,从而使模型参数量大大下降。该网络使用depthwise卷积与点卷积代替标准的3D卷积,以减少卷积操作的计算量。RFB-mobilenet骨架网络结构如表2所示。
本文从骨架模型参数量、浮点数计算量与模型大小几方面进行对比,可看出RFB-Mobilenet比RFB-VGG16更节省空间,且计算量更少,如表3所示。
表3 两种骨架网络模型参数与计算量
3 实验
3.1 数据集
本文采用的UA-DETRAC数据集由北京和天津不同地区的24个监控视频组成,总帧数超过14万,图片像素为960×540。由于每帧之间相似度较高,本文每隔一定帧数采集1张图片,共采集图片8 209张,其中70%用于模型训练,即训练集有5 747张,测试集有2 462张。
3.2 模型训练
所有模型采用Pytorch框架实现,在Nvidia1060上训练200个周期,并采用相同的学习率和优化器等训练策略。优化器采用RMSProp,动量因子为0.9,同时初始学习率为0.001,每隔60个eopch乘以0.1。在训练过程中,每一次迭代过程先随机采集32张图片,统一缩放到300*300,然后经过水平翻转、随机裁剪与色彩变化等操作进行数据增强操作。
3.3 实验结果与分析
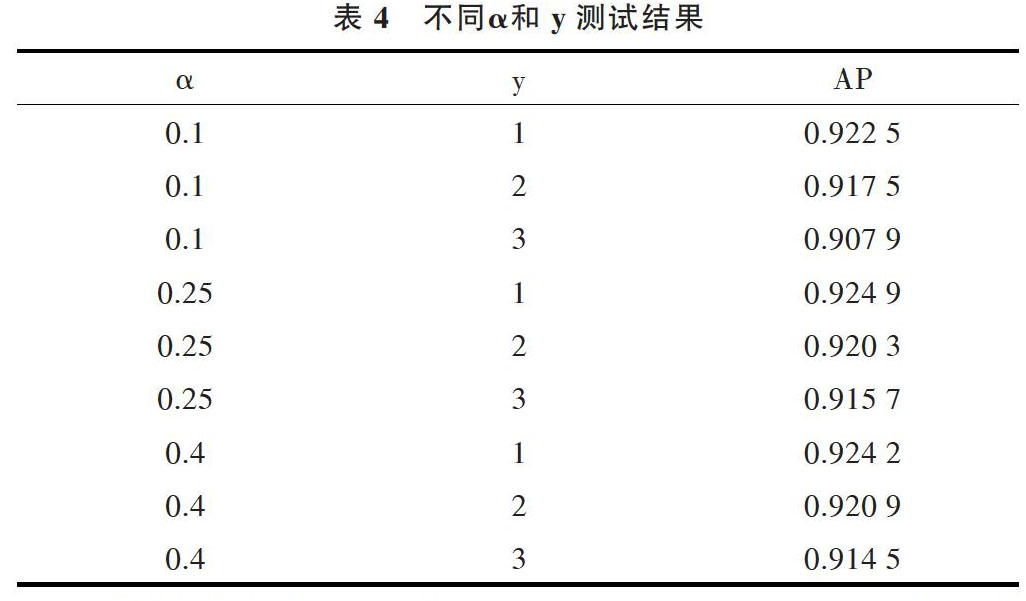
本文采用AP(Average Precision)作为模型预测结果的评价指标,该评价指标综合考虑了召回率和准确率,将预测框与位置框的IOU阈值设定为0.5。在模型训练过程中引入焦点损失方法,并测试不同α与[γ]对模型的影响,如表4所示。当a=0.25,[γ]=1时,AP值最高。
表4 不同α和y测试结果
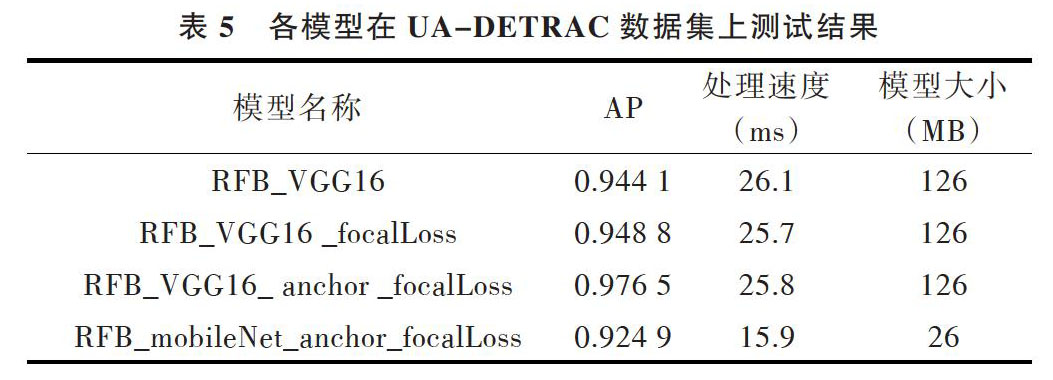
在模型测试时,每次只处理一张图片,将测试集中所有图片处理时间的平均值作为模型处理速度指标。实验结果表明,在不影响监测速度的情况下,模型性能获得了一定提升。采用焦点损失后REBNet的AP值相比原模型提高了0.47%,同时采用焦点损失与改进框后RFBNet的AP值相比原模型提高了3.2%。采用改进骨架网络的RFB_mobileNet模型在牺牲部分性能的情况下,处理速度为RFB_VGG16的1.62倍,能更好地处理需要实时运行的任务。
表5 各模型在UA-DETRAC数据集上测试结果
4 结语
本文将深度学习应用于视频监控的车辆检测中,在REBNet检测模型基础上通过聚类算法找到合适的anchor,引入焦点损失方法以减缓样本失衡问题,并基于mobilenet改进骨架网络,从而解决了传统机器学习算法无法实现复杂场景下车辆检测的问题。实验结果表明,改进后的RFB_VGG16模型在不影响监测速度的情况下,其性能得到了一定提升,而RFB_mobileNet在牺牲部分性能的情况下,处理速度得到了显著提升。同时,本文研究也为后续车辆识别(品牌、颜色、类型等)、车辆跟踪与车流分道统计等工作奠定了基础。
参考文献:
[1] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]. European Conference on Computer Vision,2016:21-37.
[2] REDMON J,FARHADI A. YOLO9000: better, faster, stronger[C]. Honolulu:2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016.
[3] REDMON J,FARHADI A. YOLOv3: an incremental improvement[DB/OL]. https://arxiv.org/abs/1804.02767.
[4] REDMON J,DIVVALA S,GIRSHICK R, et al. You only look once: unified, real-time object detection[C]. Computer Vision and Pattern Recognition,2016:779-788.
[5] GIRSHICK R. Fast R-CNN[J]. Computer Science, 2015:1440-1448.
[6] REN S,HE K,GIRSHICK R,et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]. International Conference on Neural Information Processing Systems,2015:91-99.
[7] HE K,GKIOXARI G,DOLLáR P,et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,99:1.
[8] LIU S,HUANG D,WANG Y. Receptive field block net for accurate and fast object detection[C].Computer Vision-ECCV,2018:404-419.
[9] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017, 99: 2999-3007.
[10] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[DB/OL]. https://arxiv.org/abs/1704.04861.
[11] FU C Y,LIU W,RANGA A,et al. DSSD: deconvolutional single shot detector[DB/OL]. https://arxiv.org/abs/1701.06659.
[12] ZHANG S,WEN L,BIAN X,et al. Single-shot refinement neural network for object detection[DB/OL]. https://arxiv.org/abs/1711.06897.
[13] 劉操,郑宏,黎曦,等. 基于多通道融合HOG特征的全天候运动车辆检测方法[J]. 武汉大学学报:信息科学版,2015, 40(8): 1048-1053.
[14] 宋晓琳,邬紫阳,张伟伟. 基于阴影和类Haar特征的动态车辆检测[J]. 电子测量与仪器学报,2015,29(9): 1340-1347.
[15] LI Z,ZHOU F. FSSD: feature fusion single shot multibox detector[DB/OL]. https://arxiv.org/abs/1712.00960v1.
[16] IANDOLA F, MOSKEWICZ M, KARAYEV S, et al. DenseNet: implementing efficient ConvNet descriptor pyramids[J]. Eprint Arxiv,2014.
[17] SZEGEDY C,LIU W, JIA Y, et al. Going deeper with convolutions[DB/OL]. http://arxiv.org/abs/1409.4842.
[18] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[DB/OL]. https://arxiv.org/abs/1502.03167.
[19] SZEGEDY C,VANHOUCKE V,IOFFE S,et al. Rethinking the inception architecture for computer vision[C]. In:Computer Vision and Pattern Recognition,2016:2818-2826.
[20] SZEGEDY C,IOFFE S,VANHOUCKE V. Inception-v4, inception-ResNet and the impact of residual connections on learning[DB/OL]. https://arxiv.org/abs/1602.07261.
(责任编辑:黄 健)
- 重新审视网络社会
- 以质量强党引领全面从严治党在基层落地生根
- 乡村振兴视野下对壮大农村集体经济的再认识
- 美好生活追求的历史演进及内在逻辑
- 新时代掌握网络意识形态领导权应警惕的错误论调
- 自媒体传播与公平正义演化
- 网络政治传播专题研究
- 构建新型信任关系:“人类命运共同体”的重要价值之维
- 人类命运共同体专题研究
- 基于中国场景的“积极政府”
- 当代中国政治发展的动力机制探析
- 基层公务员的政策执行:结构脉胳中的策略性选择
- 从“自治”到“治理”
- 当代霍查主义力量国际联合的重要平台
- 高放教授科学社会主义思想体系的意蕴和结构
- 论党的领导与国家治理现代化之间的内在关联
- 观察世界复杂现象的指导性线索
- 租界、自治与治理
- 驻村帮扶干部何以异化?
- 老年协会“类科层制”的组织结构及其生成逻辑
- 深度贫困地区健康扶贫政策执行偏差及其矫正
- 论社会治理走向德治的进路
- 新时代党建引领城市社区治理的逻辑契合和路径选择
- 一个值得关注的重要调整
- 乡村振兴背景下四川省农村居民消费结构的动态分析
- acclimatised
- acclimatises
- acclimatising
- acclimatizable, acclimatisable
- acclimatization
- acclimatizations
- acclimatize
- acclimatize/become acclimatized
- acclimatized
- acclimatizers
- acclimatizes
- acclimatizing
- accolade
- accoladed
- accolades
- accolading
- accommodable
- accommodate
- accommodated
- accommodates
- accommodate-with
- accommodating
- accommodatingly
- accommodation
- accommodational
- 椎牛发冢
- 椎牛酾酒
- 椎牛飨士
- 椎破
- 椎秦
- 椎秦报韩
- 椎肤剥髓
- 椎胸泣血
- 椎胸跌足
- 椎胸顿足
- 椎膺顿足
- 椎讷
- 椎轮
- 椎轮大辂
- 椎钝
- 椎锋陷阵
- 椎锋陷陈
- 椎间盘
- 椎间盘突出症
- 椎陋
- 椎飞博浪
- 椎骨
- 椎髻
- 椎髻左袵椎结左袵
- 椎髻布衣