宋文闯 刘亮亮 张再跃
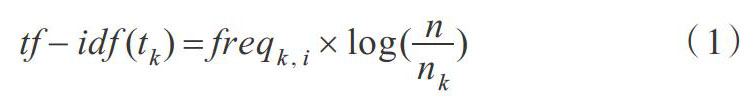


摘 要:百度知道中用户提出问题较短,采用常规基于空间向量的TF-IDF句子相似度计算、基于语义依存关系的句子相似度计算等方法往往很难较好完成其相似度计算。鉴于此,基于长度较短问句的特点,引入问题元和词模思想,对用户问题进行分解,并与传统相似度计算方法相融合,提出新的相似度计算方法。对于长度低于20个词的问句,与传统TF-IDF方法相比,F1值提高了12%。
关键词:问题元;关键字扩展;TF-IDF;句子相似度;问答系统
DOI:10. 11907/rjdk. 191544 开放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2020)007-0148-05
Study on the Similarity of Question Sentences in Question and Answer System
SONG Wen-chuang1, LIU Liang-liang2, ZHANG Zai-yue1
(1. School of Computer Science, Jiangsu University of Science and Technology, Zhenjiang 212003,China;
2. School of Statistics and Information, Shanghai University of International Business and Economics, Shanghai 201620,China)
Abstract:In view of the short length of questions raised by Baidu users, the conventional space vector-based TF-IDF sentence similarity calculation and the semantic similarity-based sentence similarity calculation are often difficult to perform good similarity calculation. To this end, this paper introduces the idea of problem element and lexical model for the characteristics of short-length question, decomposes the users problems and then combines with the traditional similarity calculation method, and proposes a new similarity calculation method. For questions with a length of less than 20 words, the F1 value is increased by 12% compared to the traditional TF-IDF method.
Key Words: question element; keyword expansion; TF-IDF; sentence similarity; question and answer system
0 引言
随着信息技术的快速发展,各行各业的数据开始出现爆发式增长,如何从海量数据中获取有效信息成为当前重要的研究课题。传统搜索引擎依据关键词和关键字的组合进行文档检索,但是这种检索存在諸多弊端。如不能准确反映用户意图,返回结果是网页列表,用户需要筛选才能获取信息[1]。对于某个用户的搜索,在没有获得满意的搜索结果时,用户通常会不断更换关键词进行检索,传统搜索引擎并没有考虑到短时间内用户问题的相关性[2]。针对搜索引擎存在的诸多弊端,问答系统成为当今学术界的一个研究热点。第一批问答系统出现于20世纪60年代,BasaBall能够回答美国篮球联赛相关问题[3]。随着技术的不断发展,出现了各种问答系统,主要分为闲聊对话型问答系统、计算机视觉问答系统以及社区问答系统等。
目前,相似度计算大体可以分为3个方面。一是基于词语粒度的相似度计算方法,例如基于词语重叠的方法[4]、空间向量的方法[5]、词语语义的方法[6-7]。其中,基于词语重叠的方法采用共现词的个数占整个句子的比例进行计算;基于空间向量的方法采用传统的TF-IDF或者Word2vec训练出词向量之后计算余弦相似度;基于词语语义的方法,一般需要借助外部知网、同义词词林、本体等技术进行计算。二是以句法为特征的相似度计算,例如,李彬等[8]将汉语的依存关系句法信息融入到问句分析中;Chang等[9]将长句子切分成短句,再进行问句分析。三是融合上述两种方法的混合算法,例如周艳平等[10]提出一种基于同义词词林的句子语义相似度方法,通过对词形、词序、语义依存相似度加权结合获得句子之间的最终相似度。这些方法虽然取得了一定效果,但仍然受到问答系统性能的影响,不能保持较高计算精准度。针对这些问题,结合百度知道问句的特点,本文引入问题和词模的思想,对句子进行分解,进而计算句子相似度,并使用该方法在问答系统中应用,验证了该方法的合理性。
1 相关技术
一个传统的问答系统,包括对问句的基本处理,如问句的分词、词性标注、去停用词等操作。
1.1 中文分词
中文分词是计算机对文本进行后续处理的基础[11]。中文不同于英文,词与词之间没有空格,故对中文问句的分词是有别于英文的普通的字符串分割。目前,针对中文的分词算法大体可以分为3类:第一类是基于字符串匹配的算法,主要包括正向匹配、逆向匹配、最长匹配以及最短匹配[12],为了提升效率,一般以索引表或者Tire树进行存储;第二类是基于统计的方法,其主要思想是根据相邻字的紧密程度进行文本分词,一般可以通过N-gram模型[13]和最大熵模型[14]实现;第三类是基于语义理解的分词,其模拟人对句子的理解过程,此种方法需要大量的语言学知识,鉴于汉语知识的错综复杂,目前很难将各种语言直接组织成机器可以直接读取的形式。
1.2 词性标注
词性是词汇的一个重要属性,是每个词所属的词类。词类是根据词汇意义和语法特点对词进行的分类,如名词、动词、形容词等。词性标注就是确定每个词是名词、动词、形容词或其它词性,并赋予合适的标记,为后续分析提供基本信息。词性标注一般采用序列化标注模型,目前比较常见的算法有最大熵模型、HMM模型、CRF模型等[15]。
1.3 停用词处理
停用词指文档中高频出现但是区分度非常低的词语。停用词的存在不仅占存储空间,也降低了文本中关键词的价值。停用词不仅包括常见的语气词,还包括问答系统中用户提问的客气用语等。
停用词的选择采用基于词频的选择方法[16],其处理过程为统计各词在文档中的词频,然后根据词频和逆文档频率进行降序排列,选择排名较高的若干个词作为停用词。
1.4 中文文本表示模型(空间向量模型)
空间向量模型首先假设文本为一个出现于文本中的词条所组成的集合,所有词两两独立。在建模过程中,通过分词将文本中的每个词条作为特征空间中的一个维度,利用这样形成的特征空间将每篇文本表示为一个向量。具体实现流程如下:
设分词后所有文档中词构成的集合为[T={t1,t2,?tN}],所有文档构成的文档集合为[D={d1,d2,?dM}]。则文档[di∈D]可通过一个[N]维向量表示为[(wi1,wi2,?wiN)]。其中[wik][(1kN)]为词条[tk]在文档[di]中的权值,权值一般表示为某词条在文档集中出现频率的函数,主要计算方法有TF-IDF函数、布尔函数等,最广为人知的当属TF-IDF函数。
TF-IDF中TF为词频,表示某一词条在某一文档中出现的总次数,词条[tk]在文档[di]中的词频表示为[freqk,i]。IDF为文档总数[n]与包含词条[tk]的文章数量[nk]比值的对数。对于文档中的词条[tk],其对应的TF-IDF值[tf-idf(tk)] 如式(1)所示。
其中,[tf-idf(tk)]表示某词条对于这篇文档的重要程度。
1.5 词的分布式表达
词的分布式表达即为词向量,就是用多个分量表达文档中每个词条的意义。其基本思想为:首先获取大规模的语料,通过对语料的训练将语料中的每个词语表示为一个定长向量。常见的词向量工具包括Google的Word2vec和Facebook的FastText。
Word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具,利用深度学习思想,通过训练将对文本内容的处理简化为 K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度[17]。
FastText是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快[18]。
2 相似度计算
文本相似度计算是实现问答系统的重要一步,通过计算用户输入的问句与知识库中每一条知识所对应问题的相似度,返回相似度排名中较为靠前的知识,从而确保答案更加精准。计算语句相似度的方法有很多,包括基于统计的句子相似度计算、基于语义的句子相似度计算,以及基于依存关系的句子相似度计算。
2.1 基于统计的句子相似度计算
基于统计的句子相似度计算一般采用基于向量空间的TF-IDF句子相似度計算[19]。依据上述空间向量模型,将每个句子表示成一个空间向量,通过计算两个句子之间空间向量的余弦值,判断句子是否相似。
其中,[xi]为句子1中的某个特征词的词向量,[yi]为句子2中某个特征词的词向量。
2.2 基于语义的相似度计算
在问句中,有的词具有同义词或近义词。因此采用基于语义的方法,可以识别出问句中词的同义词或近义词。使用《同义词词林》可以对通用词汇的同义词进行扩展[20]。
词典中的每个词均用8位编码表示。两个词的相似度按照如下规则计算。
如果两个词编码的前k-1(k<7)位相同,但第k位编码不同,则两个词之间的相似度计算如式(3)所示。
如果两个词编码的第8位都是“#”并且前7位编码相同,则两个词的相似度如式(4)所示。
如果两个词编码的第8位为“=”或者“@”,而前7位编码相同,则两个词的相似度如式(5)所示。
计算两个词之间的相似度,便可进一步计算句子间的相似度。假设S是用户提问的句子,[S']是常用问题集中的句子,S中包含的词分别为[W1W2,?,Wm],[S']中包含的词分别为[W1'W2',?,Wn'],则可用[sWi,Wj']表示词[Wi]和[Wj']之间的相似度。句子[S]和[S']的相似度如式(6)所示。
2.3 基于依存句法的句子相似度计算
句法分析是自然语言处理中的关键技术之一,其基本任务是确定句子的句法结构或者句子中词汇之间的依存关系[21]。句子各成分之间的依存关系是使用依存句法计算相似度的要点。在使用词方法时,为确保简单和高效,只需计算有效配对数之间的相似度。有效配对指全句核心词和直接依存于它的有效词组成的搭配对,名词、动词和形容词均为有效词。如式(7)所示。
其中,[i=1nWi]为句子[S1]、[S2]有效配对匹配的总权重,[PairCount1]、[PairCount2]分别为句子[S1]、[S2]有效搭配对总数。
3 基于词模与问题元的问句分析
3.1 概述
通过对爬取的百度知道用户问题进行研究发现,用户提出的问题往往符合特定规范和格式。通过对其进行分析,可以将用户的问句进行分解。
针对长问句,其句子结构比较复杂,复杂原因归于两点:①有描述性现象,回答这种问句需要精确理解这些现象;②有比较复杂的事件,这些事件有前因、后果,以及不同的经过,因此其答案也较为复杂[22]。
用户的长问题还有以下特点:①问句长度较长,包含的信息量较大,采用同义词相似度计算等方法精度会较高;②“现象”和“事件”多种多样,不能穷举,但“现象”和“事件”的类别却是有限并可以总结的,可对这些类型加以识别。
3.2 相关概念
针对用户的短问题,结合本体和问题元,将比较常见的问题进行规范化。为此,引入相关定义及相关解释。
(1)问题元。可以穷举的通用的标准化短问句,一般位于咨询尾部,其含有一定的变元,所有用户问题必与一个问题元相结合,如表1所示。
(2)中心词。一个事物在句子中处于意思中心的位置,中心词所涉事件是一个本体结构,有自己的属性或相关事项,咨询中也常出现中心词的一些属性或相关事项。
(3)中心事件现象关键词。事件是一个复杂的过程,但可以将事件进行细粒度的类别划分,这种事件也是一个本体结构,有发生的原因、所涉及的对象和事情的结果等。
(4)关系属性词。中心词或中心事件的属性或相关事项(如事物的部分、做某事等)。
中心词本体词模:中心词为一个事物,该事物对就一个本体,利用该本体自动产生词模。比较常用的词模形式为:以事物名为必选项,其属性为可性项。
(5)中心事件现象关键词本体词模。将事件或现象划分成不同的细粒度的类后,也要为这些类建立本体。由这些本体生成的词模称为中心事件现象关键词本体词模[23]。
通过整理归纳百度知道爬取的问题,对句子模式进行归纳,超过80%的用户问句符合如表2所示问句模式。
4 基于词模与问题元的问句算法实现
4.1 问题元识别与扩展
针对上述思想提出了问题元识别方法。问题元特点:①一般位于句子末尾;②含有一定的变元;③是标准化的段语句,也即出现的概率偏大。
算法1:问题元识别和扩展算法
1. 分析每个问句的特点,总结出通用的问题元;
2. 对用户的问句进行分词,词性标注以及依存关系分析;
3. 对分词后的结果,以及依存关系的分析,获取可能存在的搭配对;
4. 通过大量文本,对可能的搭配对,采用Word2Vec工具,得到搭配对的向量化表示;
5. 返回相似的问题元,作为问题元候选;
6. 将候选问题元与用户提问的问题元进行相似度计算,大于一定阈值的问题元作为最终候选问题元。
问答系统中的问句分类一直是一个较复杂的问题,分类粒度的好坏将直接影响对不同类别采取的策略。一般的分类算法仅仅是将问句分为时间、地点、人物、时间、数值、原因、定义、比较等类别,但是这种类别本身其实并没有任何实质性的作用。采用问题元方式,可对细粒度的对语料进行总结归纳。
当用户的问句没有匹配到问题元时,采用算法1进行问题元扩充,进而作后续处理。
4.2 中心词识别
正确识别出中心词,对于确定问句的主体至关重要。通过分析问句可知,中心词与其位置有着密切关系,在中文问题中,中心词的语法结构较灵活。中文问题里中心词的语义角色可能为:①疑问词的修饰语;②当疑问词包含在宾语中时,整个问句的主语是中心词;③当疑问词包含在主语中时,整个问句的宾语是中心词。
中心词的选取准则:①中心词不能是停用词;②中心词不能是疑问词;③高频词优先、名词优先。
算法2:中心词识别算法
输入:用户的问句[Si={x1,x2,?,xN}]
输出:中心词集合
过程:
1. 构建疑问词词典,停用词词典;
2. 用户输入问句,系统将输入问句进行去除标点符号、去除停用词和分词处理;
3. 对问句进行词性标注;
4. 遍历词性为N的词语作为中心语候选;
5. 过滤掉疑问词和停用词;
6. 计算该词语的TF-IDF值,返回上述TF-IDF值较大的候选词作为中心词,如果是比较问题,则返回的是中心词集合。
4.3 中心词扩展
由于汉语语言的复杂性,一个类似的含义往往可以有多种表达,而中心词可以采用《同义词词林》进行中心词扩展,这样可以提高匹配结果[24]。
算法3:中心词扩展
1. 利用《同义词词林》扩展板得到初始查询中心词[Ti]的同义词集合为[Ti(ti1,ti2,?,tin)];
2. 利用基于《知网》词语相似度算法计算出初始查询术语[ti]和集合[Ti]中每个[tij]的词语相似度[Sim(ti,tij)]。选择相似度大于阈值[α]的词语作为[ti]的同义词,小于阈值[α]的词语直接删除,将符合条件的[tij]组成集合[Ti'](0.7<=[α]<-1);
3. 最后得到集合[Ti'={t'i1,t'i2,?,t'im}], [Ti']即为选取的中心词[ti]的同义扩展词的集合。
4.4 改进后的相似度计算
最后对上述算法进行整合,提出与传统相似度算法相结合的算法。
算法4:多相似度计算算法融合
1. 首先对问句进行问题元识别,如果识别到问题元,则转向3;
2. 采用算法1,对问题元进行扩展;
3. 采用算法2,对中心詞进行识别;
4. 采用算法4,对中心词进行扩展;
5.相似度计算,[Sim(S1,S2)=λ1*Sim1(S1,S2)+λ2*Sim2(S1,][S2)+λ3*Sim3(S1,S2)]
其中,[λ1+λ2+λ3=1],[Sim1(S1,S2)]是采用基于向量空间的TF-IDF句子相似度计算,[Sim2(S1,S2)]是采用词向量计算问题元之间的相似度,[Sim3(S1,S2)]采用同义词词林计算句子相似度。
5 实验
本文采用的数据集为百度问答公开的数据集以及通过爬取百度知道扩展的问题答案对,共包括16 843个问题答案对。
5.1 知识库建立
网络爬虫是按照一定规则,自动抓取万维网信息的程序或脚本。实现原理为:深度遍历网站资源,分析网站的URL并提交Http请求,然后将网页抓取到本地,生成本地文件及相应的日志信息等。常用的开源网络爬虫有Nutch、Larbin和Heritrix。将文档进行xPath解析,得到问题答案对,存入知识库中。
5.2 知识库解析
对上述爬取的问题答案对,在保留问题答案对的同时,将问题依据上文词模方法进行解析,分解成问题元、中心词、关系词等。
例如:{‘A_问题:‘钛精矿含量可不可能达到72%,求解答?,
--中心词:钛精矿 关系词:含量 问题元:是否能达到比例(*%)
{‘A_问题:‘我的手机是波导i800的,又个java还有个至尊宝3g平台,不是安卓的,可以刷机吗?,
--中心词:手机{波导i800、java、3g、非安卓系统} 问题元:是否可以(手机,刷机)
{‘A_问题:‘求几本好的武侠小说,要类似金庸的,
--中心词:武侠小说{类似金庸} 问题元:请求介绍
5.3 数据查询
对上述问题模式及其构成进行识别后,查询相关知识库,如表3所示。
5.4 评估标准
5.4.1 查询率(Precision)
[S]表示知识问答对,[TN(S)]表示问答系统返回知识中正确答案的个数,[RN(S)]表示问答系统返回所有答案的个数。问答系统查准率如式(8)所示。
5.4.2 查全率(Recall)
[S]表示知识库问答对,[TN(S)]表示问答系统返回知识中正确答案的个数,[AN(S)]表示问答系统中所有正确答案的个数。问答系统查全率如式(9)所示。
5.4.3 F1-Measure
[P(S)]表示问答系统的查准率,[R(S)]表示问答系统的查全率。问答系统F1-Measure如式(10)所示。
用户在系统内输入所要搜索的问题,问答系统将用户输入的问句与知识库中的问句进行相似度计算,并将相似度大于阈值的知识库问句对应的答案返回给用户,由用户判断返回答案中正确答案的个数,匹配相似度最高的3个问句。
5.5 实验结果及分析
通过对比表4实验结果发现,对于短文本的用户问题,本文方法相对于传统TF-IDF空间向量模型有一定提升。但是随着问句长度的增加,问句中包含的信息量越来越大,在性能上差距会越来越小。
本文通过爬取“百度知道”真实的问题和答案对,构建数据集,并对其中的问题模式进行研究,引入问题元和本体相关概念。一个短的问题往往是中心词加上问题元,一个长的问题往往是一个复杂的事件加上中心词和问题元,通过对问句进行分解,对问句的相似度算法进行改进,有效提高了问答系统返回结果的F1值。但该方法存在一大不足,即前期需要使用大量人力去归纳总结问句模式以及常见问题元,这有待后续研究解决。
参考文献:
[1] 于甜甜. 基于语义树的语句相似度和相关度在问答系统中的研究[D]. 济南:山东财经大学,2014.
[2] 刘里,曾庆田. 自动问答系统研究综述[J]. 山东科技大学学报(自然科学版),2007(4):73-76.
[3] 郑实福,刘挺,秦兵,等. 自动问答综述[J]. 中文信息学报,2002(6):46-52.
[4] 钟敏娟,万常选,刘爱红,等. 基于词共现模型的常问问题集的自动问答系统研究[J]. 情报学报, 2009,28(2):242-247.
[5] LEGRAND J,COLLOBERT R. Joint RNN-based greedy parsing and word composition[J]. Computer Science,2014.
[6] 郜强. 基于语义词语相似度计算模型的研究与实现[D]. 西安:西安电子科技大学,2011.
[7] 张新旭. 基于本体相似度的语义Web服务匹配算法研究[D]. 成都:电子科技大学,2013.
[8] 李彬,刘挺,秦兵,等. 基于语义依存的汉语句子相似度计算[J]. 计算机应用研究,2003, 20(12):15-17.
[9] CHANG J W, LEE M C, WANG T I, et al. Using grammar patterns to evaluate semantic similarity for short texts[C]. 2012 8th International Conference on Computing Technology and Information Management (NCM and ICNIT),2012.
[10] 周艳平,李金鹏,蔡素. 基于同义词词林的句子語义相似度方法及其在问答系统中的应用[J]. 计算机应用与软件,2019,36(8):65-68,81.
[11] 黄昌宁,赵海. 中文分词十年回顾[J]. 中文信息学报,2007(3):8-19.
[12] 常建秋,沈炜. 基于字符串匹配的中文分词算法的研究[J]. 工业控制计算机,2016,29(2):115-116,119.
[13] 秦健.? N-gram技术在中文词法分析中的应用研究[D]. 青岛:中国海洋大学,2009.
[14] 于江德,王希杰,樊孝忠. 基于最大熵模型的词位标注汉语分词[J]. 郑州大学学报(理学版),2011,43(1):70-74.
[15] 苏勇. 基于理解的汉语分词系统的设计与实现[D]. 成都:电子科技大学,2011.
[16] 梁喜涛,顾磊. 中文分词与词性标注研究[J]. 计算机技术与发展,2015,25(2):175-180.
[17] 化柏林. 知識抽取中的停用词处理技术[J]. 现代图书情报技术,2007(8):48-51.
[18] 李晓,解辉,李立杰. 基于Word2vec的句子语义相似度计算研究[J]. 计算机科学,2017,44(9):256-260.
[19] 代令令. 基于fastText的问答系统用户意图识别与关键词抽取研究[D]. 南宁:广西大学,2018.
[20] 武永亮,赵书良,李长镜,等. 基于TF-IDF和余弦相似度的文本分类方法[J]. 中文信息学报,2017,31(5):138-145.
[21] 赵蔚. 基于同义词词林的词语相似度计算方法[J]. 吉林大学学报(信息科学版),2010,28(6):602-608.
[22] 吴佐衍,王宇. 基于HNC理论和依存句法的句子相似度计算[J]. 计算机工程与应用,2014,50(3):97-102
[23] 刘小明,樊孝忠,刘里. 融合事件信息的复杂问句分析方法[J]. 华南理工大学学报(自然科学版), 2011,39(7):140-145.
[24] 张克亮,李伟刚,王慧兰. 基于本体的航空领域问答系统[J]. 中文信息学报,2015, 29(4):192-198.
[25] 刘茂福,周斌,胡慧君,等. 问答系统中基于维基百科的问题扩展技术研究[J]. 工业控制计算机, 2012,25(9):101-103.
(责任编辑:孙 娟)
- 关于银行综合通用APP应用研究
- 国有企业授权单位资产评估管理实践思考
- 基于区块链技术的电子商务企业供应链成本控制研究
- 新形势下行政事业单位内部控制优化措施研究
- 区块链视角下内部控制边界再讨论
- “互联网+”环境下物流企业风险控制研究
- 城乡一体化背景下农民合作社主导的农产品物流模式研究
- 高职市场营销专业毕业生就业情况分析
- “一带一路”视域下甘肃高职旅游人才培养质量优化路径与对策
- 财会专业VBSE实训存在的问题及对策
- 高职院校旅游管理专业构建“双主体”育人的实践教学模式
- 基于Malmquist指数的“一带一路”沿线省市高校科技创新效率研究
- 全民健身战略下黑龙江省体育产业政策分析
- 黑龙江省装备制造业产业关联效应分析
- 黑龙江省养老服务业可持续发展对策研究
- “互联网+”行动对黑龙江省智慧城市建设与运营主体的影响
- 技术创新的就业效应研究
- 浅析判例法系下澳大利亚合同法
- 加快政府创新友好型法律规制建设研究
- 突发事件应急物资跟踪审计探析
- 商业分析预测模式解析
- 高新技术企业中对赌协议的估值方法
- 企业IPO造假动因及治理的博弈分析
- 加大创新金融力度 切实服务实体经济
- 互联网金融法律风险的分析与思考
- repentant
- repentantly
- repented
- repenter
- repenters
- repenter's
- repenting
- repentingly
- repents
- repeopled
- repeoples
- repeopling
- reperceive
- reperceived
- reperceives
- reperceiving
- reperception
- reperceptions
- repercussion
- repercussions
- repercussion's
- repercussive
- repercussively
- repercussiveness
- re-perform
- 强使
- 强使服从
- 强保
- 强健
- 强健勇猛
- 强健有力
- 强健有精神
- 强健的人
- 强健的小牛
- 强健的狗
- 强健结实
- 强光
- 强光底下没毒虫
- 强兵
- 强兵壮马
- 强凌弱,富欺贫
- 强凫变鹤
- 强出头
- 强击机
- 强制
- 强制休假
- 强制保险
- 强制勒逼
- 强制命令
- 强制式